【AAAI 2022】一种样本高效的基于模型的保守 actor-critic 算法

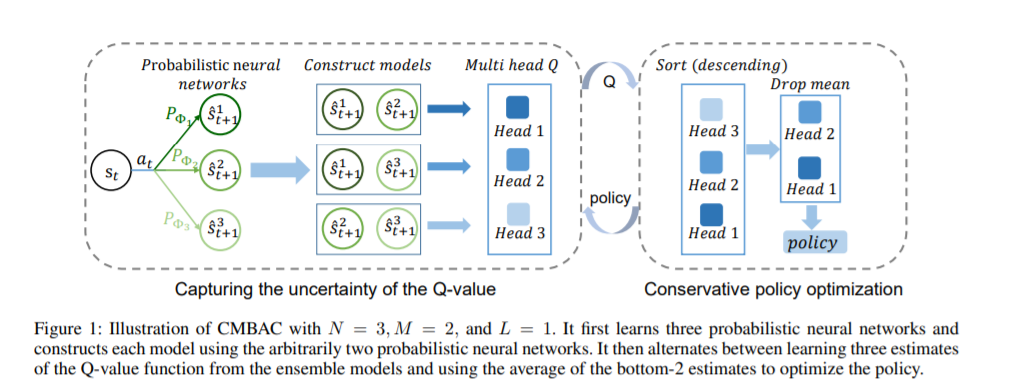
基于模型的强化学习算法旨在学习环境模型,并通过环境模型做决策,其样本效率高于无模型算法。基于模型的方法的样本效率取决于模型能否很好地近似环境。然而,学习一个精确的模型是具有挑战性的,特别是在复杂和嘈杂的环境中。为了解决这个问题,MIRA Lab 提出了基于模型的保守 actor-critic 方法(conservative model-based actor-critic---CMBAC)。这是一种在不依赖精确学习模型的情况下实现了高样本效率的新方法。具体而言,CMBAC从一组不准确的模型中学习Q值函数的多个估计值,并使用其最小的k个估计值的均值(即保守估计值)来优化策略。CMBAC的保守估计能够有效地鼓励智能体避免不可靠的“有前景的动作”,即那些仅在一小部分模型中估计价值高的动作。实验结果表明,CMBAC方法在多个具有挑战性的控制任务上的样本效率明显优于现有的方法,并且该方法在噪声环境下比现有的方法更具鲁棒性。原论文标题为《Sample-Efficient Reinforcement Learning via Conservative Model-Based Actor-Critic》,由王杰教授指导MIRA Lab 的王治海、周祺等人发表于AAAI 2022。
http://arxiv.org/abs/2112.10504
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DCLF” 就可以获取《【AAAI2022】对偶对比学习在人脸伪造检测中的应用》专知下载链接



登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文