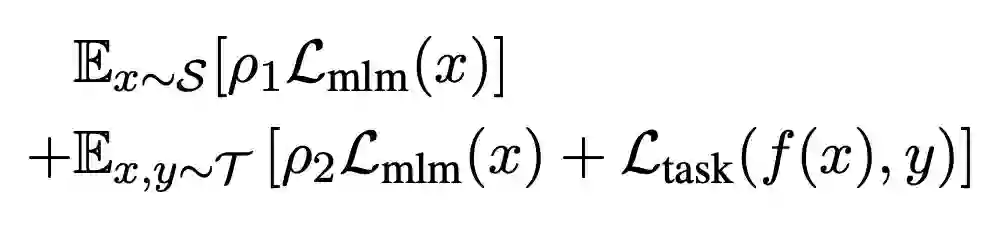机器之心 & ArXiv Weekly Radiostation
本周论文主要包括 MIT CSAIL 的研究摘得了本届 CoRL 大会的最佳论文奖;哥伦比亚大学计算机科学系 Huy Ha、Shuran Song 的研究获得了最佳系统论文奖。
A System for General In-Hand Object Re-Orientation
FlingBot: The Unreasonable Effectiveness of Dynamic Manipulation for Cloth Unfolding
NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework
Masked Autoencoders Are Scalable Vision Learners
NON-DEEP NETWORKS
A PSEUDODIFFERENTIAL PROOF OF THE RIEMANN HYPOTHESIS
EditGAN: High-Precision Semantic Image Editing
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:A System for General In-Hand Object Re-Orientation
作者:Tao Chen, Jie Xu, Pulkit Agrawal
论文链接:https://arxiv.org/abs/2111.03043
摘要:
由于高维驱动空间以及手指与物体之间接触状态的频繁变化,手持物体的重定向一直是机器人技术中一个具有挑战性的问题。该研究提出了一个简单的无模型框架,该框架可以在机器手向上和向下的情况下学会对物体重定向。该研究展示了在这两种情况下重定向 2000 多个几何形状不同的物体的能力。学得的策略在新物体对象上显示出强大的零样本迁移性能。该研究表明可以使用在现实世界中易获得的观察结果来提炼这些策略,使其适应实际生活中的日常操作。
![]()
研究者试图寻求让机器复制人类能力的方法,他们创建了一个更大的框架:一个可以用机械手重定向 2000 多个不同物体的系统,包括手掌心朝上和朝下的情况。这种从杯子、金枪鱼罐头、Cheez-It 盒子到任何东西的操纵能力,可以帮助机械手以特定的方式和位置快速拾取和放置物体,甚至可以推广到看不见的物体。
![]()
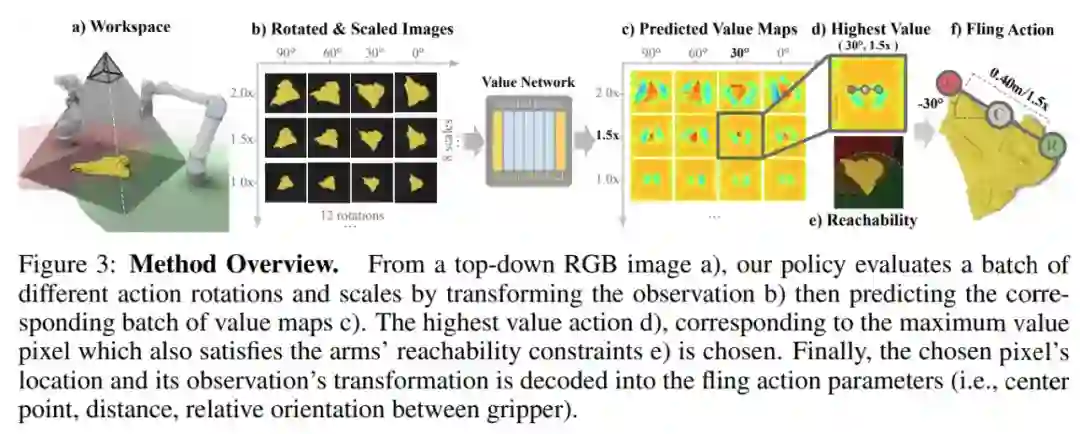
论文 2:FlingBot: The Unreasonable Effectiveness of Dynamic Manipulation for Cloth Unfolding
摘要:
高速动态动作(例如投掷)通过提高运动效率并有效扩大物理触及范围,在人们与可变形物体的日常互动中发挥着至关重要的作用。先前大多数工作都使用专门的单臂准静态(quasi-static)动作来处理布料操作(例如铺床单、叠衣服),这需要大量交互来初始化布料的配置,并严格限制了机器人可操纵的最大布料尺寸。在这项工作中,研究者提出了一种自监督学习框架 FlingBot,证明了动态甩动动作对布料展开的有效性。该方法从视觉观察结果中学习了如何使用拾取、拉伸和甩动几个原型动作,使得机器人能够通过控制双臂的设置从任意初始配置展开一块织物。最终系统在新型布料上的 3 个动作内实现了超过 80% 的覆盖率,可以展开比系统覆盖范围更大的布料。尽管该研究仅在矩形布料上训练了模型,但这种方法仍然可以泛化到 T 恤,继而用于展开叠取衣物。该研究还在真实世界的双臂机器人平台上对 FlingBot 进行了微调,使得它比准静态基线增加了 4 倍以上的布料覆盖率。FlingBot 展示出超越准静态基线的卓越性能,并表明了动态动作对可变形物体操作的有效性。
![]()
论文 3:NLP From Scratch Without Large-Scale Pretraining: A Simple and Efficient Framework
摘要:
来自清华大学的研究者们提出了一种简单高效的 NLP 学习框架。不同于当下 NLP 社区主流的大规模预训练 + 下游任务微调(pretraining-finetuning)的范式,这一框架无需进行大规模预训练。相较于传统的预训练语言模型,该框架将训练效率 (Training FLOPs) 提升了两个数量级,并且在多个 NLP 任务上实现了比肩甚至超出预训练模型的性能。
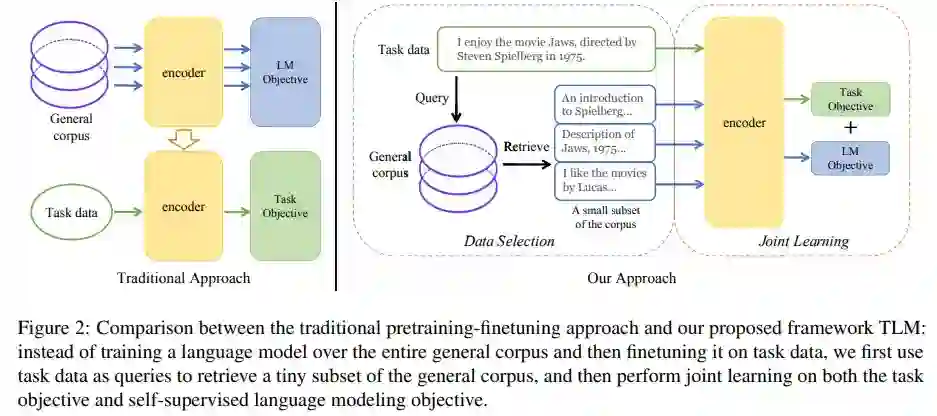
研究者们称之为 TLM (Task-driven Language Modeling)。相较于传统的预训练模型(例如 RoBERTa),TLM 仅需要约 1% 的训练时间与 1% 的语料,即可在众多 NLP 任务上比肩甚至超出预训练模型的性能 (如图 1 所示)。研究者们希望 TLM 的提出能够引发更多对现有预训练微调范式的思考,并推动 NLP 民主化的进程。
![]()
为了从大规模通用语料中抽取关键数据,TLM 首先以任务数据作为查询,对通用语料库进行相似数据的召回。这里作者选用基于稀疏特征的 BM25 算法 [2] 作为召回算法。之后,TLM 基于任务数据和召回数据,同时优化任务目标和语言建模目标 (如下图公式所示),从零开始进行联合训练。
![]()
论文 4:
Masked Autoencoders Are Scalable Vision Learners
摘要:
研究者提出了一种简单、有效且可扩展的掩蔽自编码器(MAE)用于视觉表征学习。
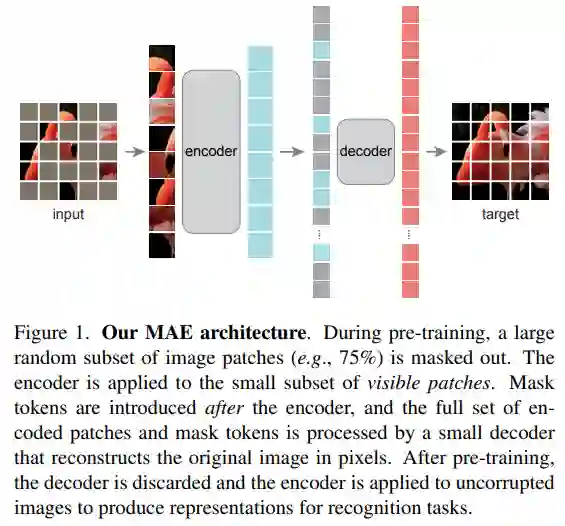
该 MAE 从输入图像中掩蔽了随机 patch 并重建像素空间中缺失的 patch。
它具有非对称的编码器 - 解码器设计。
其中,编码器仅对 patch 的可见子集(没有掩码 token)进行操作,解码器则是轻量级的,可以从潜在表征和掩码 token 中重建输入(图 1)。
在这个非对称编码器 - 解码器中,将掩码 token 转移到小型解码器会导致计算量大幅减少。在这种设计下,非常高的掩蔽率(例如 75%)可以实现双赢:它优化了准确性,同时允许编码器仅处理一小部分(例如 25%)的 patch。这可以将整体预训练时间减少至原来的 1/3 或更低,同时减少内存消耗,使我们能够轻松地将 MAE 扩展到大型模型。
![]()
MAE 可以学习非常大容量的模型,而且泛化性能良好。通过 MAE 预训练,研究者可以在 ImageNet-1K 上训练 ViT-Large/-Huge 等需要大量数据的模型,提高泛化性能。例如,在 ImageNet-1K 数据集上,原始 ViT-Huge 模型经过微调后可以实现 87.8% 的准确率。这比以前所有仅使用 ImageNet-1K 数据的模型效果都要好。
推荐:
Masked Autoencoders让计算机视觉通向大模型。
摘要:
深度是深度神经网络的关键,但更多的深度意味着更多的序列计算和更多的延迟。这就引出了一个问题——是否有可能构建高性能的「非深度」神经网络?近日,普林斯顿大学和英特尔实验室的一项研究证明了这一观点的可行性。该研究使用并行子网络而不是一层又一层地堆叠,这有助于在保持高性能的同时有效地减少深度。
通过利用并行子结构,该研究首次表明深度仅为 12 的网络可在 ImageNet 上实现超过 80%、在 CIFAR10 上实现超过 96%、在 CIFAR100 上实现 81% 的 top-1 准确率。该研究还表明,具有低深度主干网络的模型可以在 MS-COCO 上达到 48% 的 AP 指标。研究者分析了该设计的扩展规则,并展示了如何在不改变网络深度的情况下提高性能。最后,研究者提供了关于如何使用非深度网络来构建低延迟识别系统的概念证明。
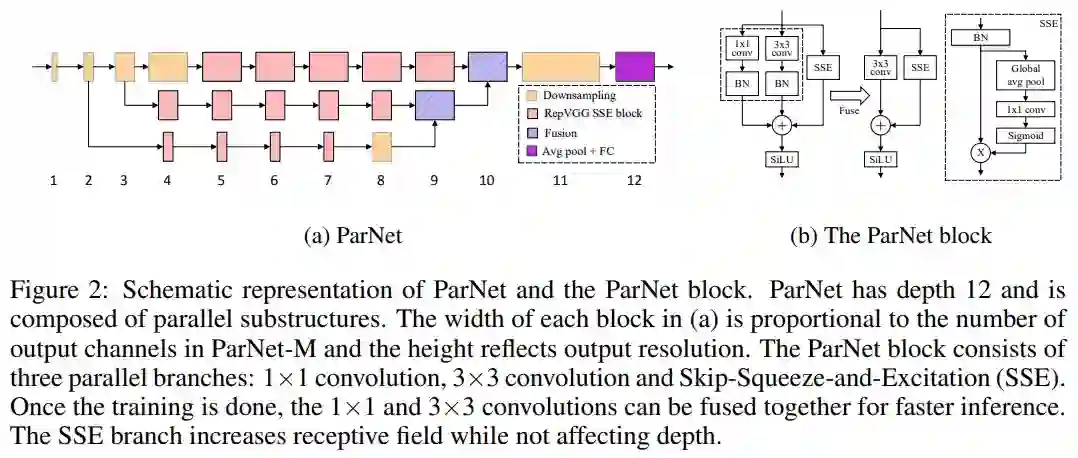
该研究提出了一种深度较低但仍能在多项基准上实现高性能的网络架构 ParNet,ParNet 由处理不同分辨率特征的并行子结构组成。这些并行子结构称为流(stream),来自不同流的特征在网络的后期融合,融合的特征用于下游任务。图 2a 提供了 ParNet 的示意图。
![]()
图 2a 展示了用于 ImageNet 数据集的 ParNet 模型示意图。初始层由一系列降采样块组成,降采样 block 2、3 和 4 的输出分别馈送到流 1、2 和 3。研究者发现 3 是给定参数预算的最佳流数(如表 10 所示)。每个流由一系列不同分辨率处理特征的 RepVGG-SSE block 组成。然后来自不同流的特征由融合 block 使用串联进行融合。最后,输出被传递到深度为 11 的降采样 block。与 RepVGG(Ding 等, 2021)类似,该研究对最后一个降采样层使用更大的宽度。
推荐:
普林斯顿、英特尔提出 ParNet,速度和准确性显著优于 ResNet。
论文 6:A PSEUDODIFFERENTIAL PROOF OF THE RIEMANN HYPOTHESIS
摘要:
拥有 160 多年历史的黎曼猜想,是数学王冠上的明珠,让无数人为之辗转。试图证明这一猜想的人很多,但被公认的方法至今还没出现。阿蒂亚爵士在演讲之后也公布了自己证明黎曼猜想的预印本,仍未被众人认可。
近日兰斯大学的 Andre Unterberger 在 arXiv 上传论文《A pseudodifferential proof of the Riemann hypothesis》,对黎曼猜想涉及到的厄米特形式(hermitian form)的分析和算术部分进行了详尽的比较,从而证明了该猜想。
![]()
这篇论文的参考来源也是 Andre Unterberger 自己在 2018 年出版的一本关于数论的书籍《Pseudodifferential methods in number theory》。书籍介绍中就提到了「探索一种证明黎曼猜想的新方法」。
推荐:
法国学者 29 页预印本论文「证明」黎曼猜想。
论文 7:EditGAN: High-Precision Semantic Image Editing
摘要:
近日,英伟达、多伦多大学等机构研究者提出了一个全新的基于 GAN 的图像编辑框架 EditGAN——通过允许用户修改对象部件(object part)分割实现高精度的语义图像编辑。相关研究已被 NeurIPS 2021 会议接收,代码和交互式编辑工具之后也会开源。
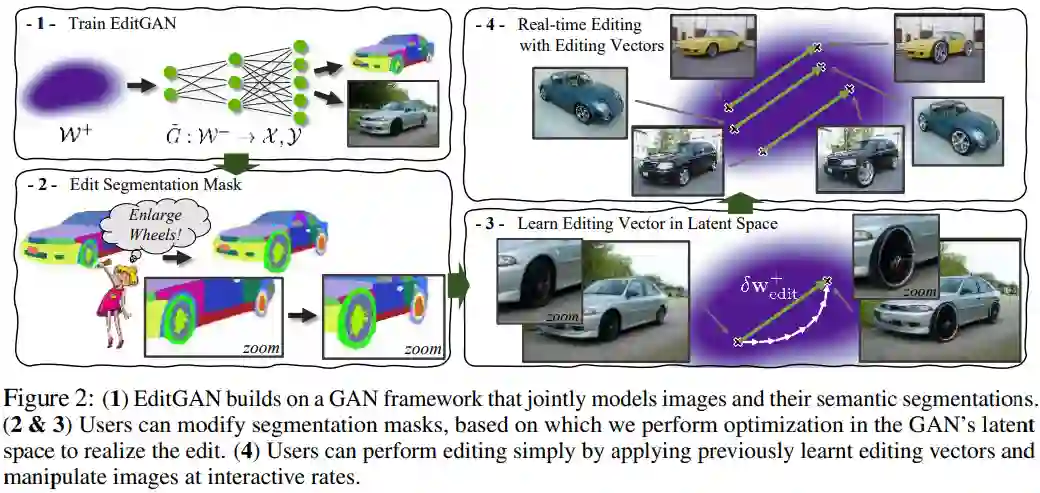
EditGAN 在最近提出的 GAN 模型基础上构建,不仅能够基于相同的潜在隐编码来共同地建模图像及其语义分割,而且仅需要 16 个标注示例,从而可以扩展至很多目标类和部件标签。研究者根据预期编辑结果来修改分割掩码,并优化隐编码以与新的分割保持一致,这样就可以高效地改变 RGB 图像。此外,为了实现效率,他们通过学习隐空间中的编辑向量(editing vector)来实现编辑,并在无需或仅需少量额外优化步骤的情况下直接在其他图像上应用。因此,研究者预训练了一个感兴趣编辑的库以使得用户可以在交互工具中直接使用。
下图 2(1)为训练 EditGAN 的流程;图 2(2&3)分别为编辑分割掩码和利用编辑向量的实时编辑,其中用户可以修改分割掩码,并由此在 GAN 的隐空间中进行优化以实现编辑;图 2(4)为在隐空间中学习编辑向量,用户通过应用以往学得的编辑向量进行编辑,并可以交互式地操纵图像。
![]()
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. MotifClass: Weakly Supervised Text Classification with Higher-order Metadata Information. (from Jiawei Han)
2. Reason first, then respond: Modular Generation for Knowledge-infused Dialogue. (from Jason Weston)
3. Self-Normalized Importance Sampling for Neural Language Modeling. (from Hermann Ney)
4. Conformer-based Hybrid ASR System for Switchboard Dataset. (from Hermann Ney)
5. Scaling ASR Improves Zero and Few Shot Learning. (from Abdelrahman Mohamed)
6. Cascaded Multilingual Audio-Visual Learning from Videos. (from Brian Kingsbury)
7. Towards Robust Knowledge Graph Embedding via Multi-task Reinforcement Learning. (from Hui Xiong)
8. Learning to Generalize Compositionally by Transferring Across Semantic Parsing Tasks. (from Fei Sha)
9. Kronecker Factorization for Preventing Catastrophic Forgetting in Large-scale Medical Entity Linking. (from Denis Jered McInerney)
10. TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning. (from Nigel Collier)
本周 10 篇 CV 精选论文是:
1. BBC-Oxford British Sign Language Dataset. (from Andrew Zisserman)
2. Masked Autoencoders Are Scalable Vision Learners. (from Kaiming He, Piotr Dollár, Ross Girshick)
3. EditGAN: High-Precision Semantic Image Editing. (from Antonio Torralba)
4. Direct Multi-view Multi-person 3D Pose Estimation. (from Shuicheng Yan)
5. Fine-Grained Image Analysis with Deep Learning: A Survey. (from Jinhui Tang, Jian Yang, Serge Belongie)
6. Are Transformers More Robust Than CNNs?. (from Alan Yuille)
7. A Study of the Human Perception of Synthetic Faces. (from Kevin Bowyer)
8. A-PixelHop: A Green, Robust and Explainable Fake-Image Detector. (from C.-C. Jay Kuo)
9. Leveraging Geometry for Shape Estimation from a Single RGB Image. (from Roberto Cipolla)
10. Unsupervised Part Discovery from Contrastive Reconstruction. (from Andrea Vedaldi)
本周 10 篇 ML 精选论文是:
1. An Instance-Dependent Analysis for the Cooperative Multi-Player Multi-Armed Bandit. (from Peter Bartlett, Michael I. Jordan)
2. Benefit-aware Early Prediction of Health Outcomes on Multivariate EEG Time Series. (from Christos Faloutsos)
3. Reducing Data Complexity using Autoencoders with Class-informed Loss Functions. (from Francisco Herrera)
4. PowerGridworld: A Framework for Multi-Agent Reinforcement Learning in Power Systems. (from Xiangyu Zhang)
5. Learning Signal-Agnostic Manifolds of Neural Fields. (from Joshua B. Tenenbaum)
6. DistIR: An Intermediate Representation and Simulator for Efficient Neural Network Distribution. (from Matei Zaharia)
7. Towards Theoretical Understanding of Flexible Transmitter Networks via Approximation and Local Minima. (from Zhi-Hua Zhou)
8. An Interactive Visualization Tool for Understanding Active Learning. (from Martin Ester)
9. Dealing with the Unknown: Pessimistic Offline Reinforcement Learning. (from Masayoshi Tomizuka)
10. Efficient Neural Network Training via Forward and Backward Propagation Sparsification. (from Tong Zhang)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com