机器之心 & ArXiv Weekly Radiostation
本周论文包括OpenAI 文本生成图像新模型 GLIDE 用 35 亿参数媲美 DALL-E;黑客帝国「缸中之脑」有眉目了?培养皿中百万人脑细胞学会打乒乓球,仅用了 5 分钟。
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Plenoxels: Radiance Fields without Neural Networks
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
Quantifying the Effect of Public Activity Intervention Policies on COVID-19 Pandemic Containment Using Epidemiologic Data From 145 Countries
Boosting the Transferability of Video Adversarial Examples via Temporal Translation
In Vitro Neurons Learn and Exhibit Sentience when Embodied in a Simulated Game-world
Learning to Compose Visual Relations
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
摘要:
从年初 OpenAI 刷屏社区的 DALL-E 到英伟达生成逼真摄影的 GauGAN2,文本生成图像可谓是今年大火的一个研究方向。现在 OpenAI 又有了新的进展——35 亿参数的新模型 GLIDE。除了从文本生成图像,GLIDE 还有图像编辑功能——使用文本 prompt 修改现有图像,在必要时插入新对象、阴影和反射。GLIDE 的零样本生成和修复复杂场景的能力也很强。GLIDE 还能够将草图转换为逼真的图像编辑。
上述功能是怎样实现的呢?在新模型 GLIDE 中,OpenAI 将指导扩散(guided diffusion)应用于文本生成图像的问题。首先该研究训练了一个 35 亿参数的扩散模型,使用文本编码器以自然语言描述为条件,然后比较了两种指导扩散模型至文本 prompt 的方法:CLIP 指导和无分类器指导。通过人工和自动评估,该研究发现无分类器指导能够产生更高质量的图像。
![]()
![]()
一只戴着领结和生日帽的柯基犬从涂鸦草图转换成了逼真的图像。
推荐:
缩小规模,OpenAI 文本生成图像新模型 GLIDE 用 35 亿参数媲美 DALL-E
论文 2:Plenoxels: Radiance Fields without Neural Networks
摘要:
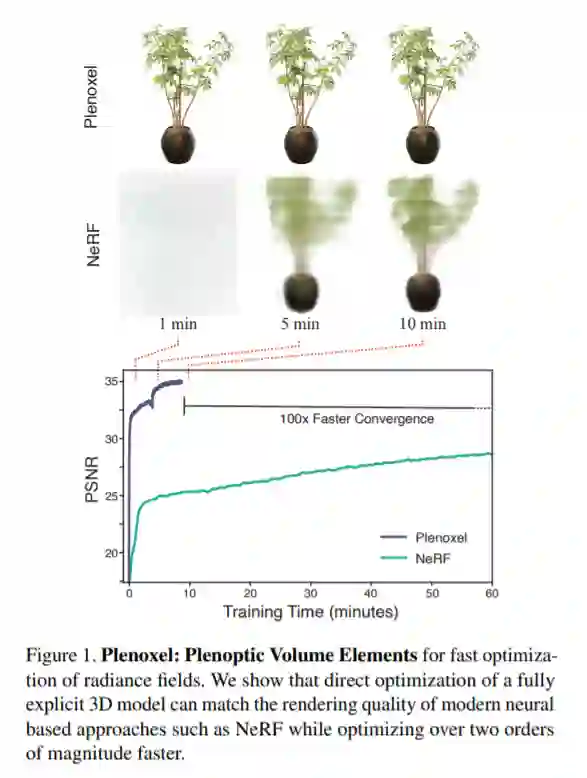
在本文中,来自加州大学伯克利分校的研究者瞄准了这一问题,提出了一种名为 Plenoxels 的新方法。这项新研究表明,即使没有神经网络,从头训练一个辐射场(radiance field)也能达到 NeRF 的生成质量,而且优化速度提升了两个数量级。
他们提供了一个定制的 CUDA 实现,利用模型的简单性来达到可观的加速。在有界场景中,Plenoxels 在单个 Titan RTX GPU 上的典型优化时间是 11 分钟,NeRF 大约是一天,前者实现了 100 多倍的加速;在无界场景中,Plenoxels 的优化时间大约为 27 分钟,NeRF++ 大约是四天,前者实现了 200 多倍的加速。虽然 Plenoxels 的实现没有针对快速渲染进行优化,但它能以 15 帧 / 秒的交互速率渲染新视点。如果想要更快的渲染速度,优化后的 Plenoxel 模型可以被转换为 PlenOctree。
![]()
![]()
推荐:
神经辐射场去掉「神经」,训练速度提升 100 多倍,3D 效果质量不减
论文 3:BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
摘要:
日前,在自动驾驶权威评测集 nuScenes 上,鉴智机器人凭借提出的纯视觉自动驾驶 3D 感知新范式 BEVDet,以绝对优势获得纯视觉 3D 目标检测世界第一的成绩。BEVDet 是首个公开的同时兼具高性能、扩展性和实用性的 BEV 空间 3D 感知范式,以 BEVDet 为核心的系列技术将有希望解决视觉为主自动驾驶解决方案中视觉雷达、4D 感知、实时局部地图等关键问题,未来将应用于鉴智机器人以视觉雷达为核心的高级别自动驾驶等产品和解决方案中,为自动驾驶的大规模量产发挥关键的作用。
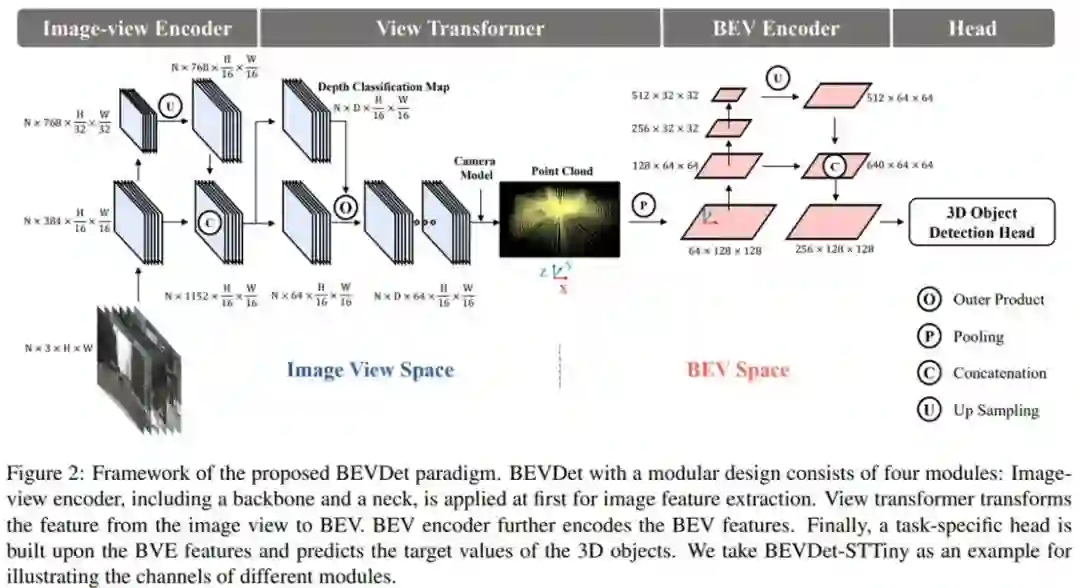
鉴智机器人提出了下一代纯视觉自动驾驶 3D 目标检测框架 BEVDet。BEVDet 遵循模块化设计的理念,包含以下四个分工明确的模块:图像编码模块用于在二维图像空间提取高纬度的特征;视角变换模块用于把图像空间的特征转换到鸟瞰视角空间(Bird-Eye-View, BEV)的特征;鸟瞰视角的编码模块用于在鸟瞰视角下进一步提取特征;以及一个三维目标预测模块(Head)用于在鸟瞰视角空间对三维目标的定位、尺度、朝向、速度和类别的预测。BEVDet 通过上述的四个模块简洁的解决纯视觉自动驾驶 3D 目标检测的问题。
![]()
![]()
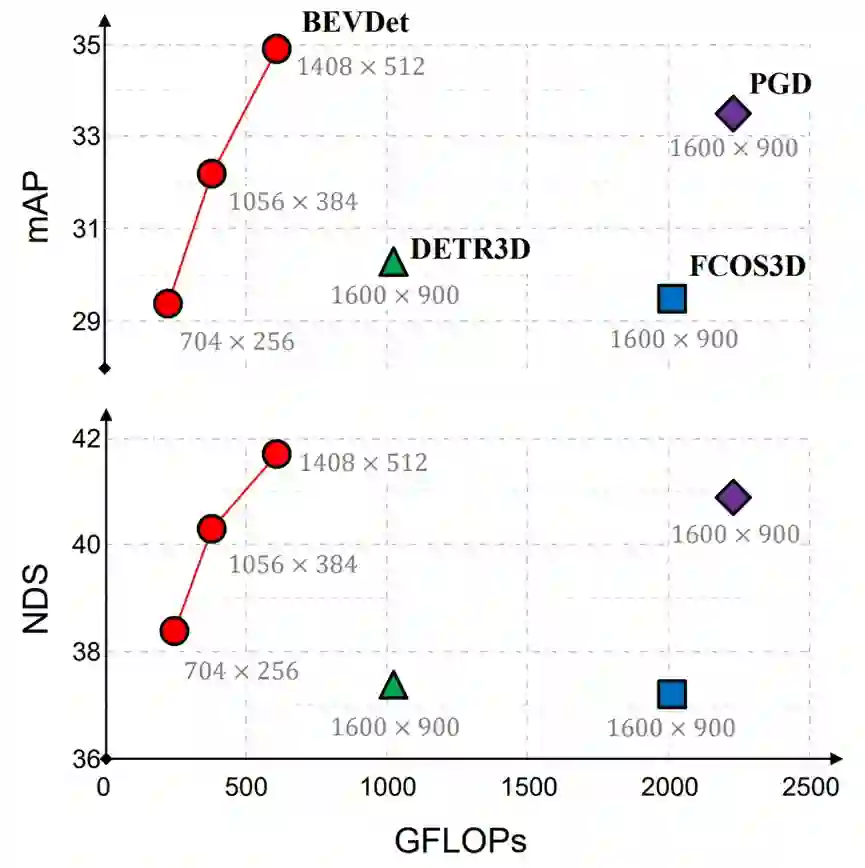
BEVDet 在纯视觉 3D 目标检测公开测试集上同时具备高性能和低算力要求的特点
推荐:
自动驾驶权威评测世界第一,鉴智机器人推出纯视觉 3D 感知新范式
论文 4:Quantifying the Effect of Public Activity Intervention Policies on COVID-19 Pandemic Containment Using Epidemiologic Data From 145 Countries
摘要:
日前,钟南山院士团队与腾讯公司披露了一项利用大数据与人工智能技术,定量评估不同公共防控政策对新冠疫情控制效果的研究。研究团队开发了一种新的反事实推理模型框架,通过引入隐含交互因子项,最大程度排除了随时间变化的混杂因素的影响,对包含 145 个国家和地区、8 种公共防控政策的动态数据,进行更加准确,且符合真实世界运转的量化分析。研究结果表明,更快、更精准地实施疫情防控,才能有效遏制新冠肺炎疫情的发展。这也是新冠防控领域首次引入该技术进行研究。这项研究成果已在国际著名医学期刊 Value in Health(《健康价值》)刊出。
![]()
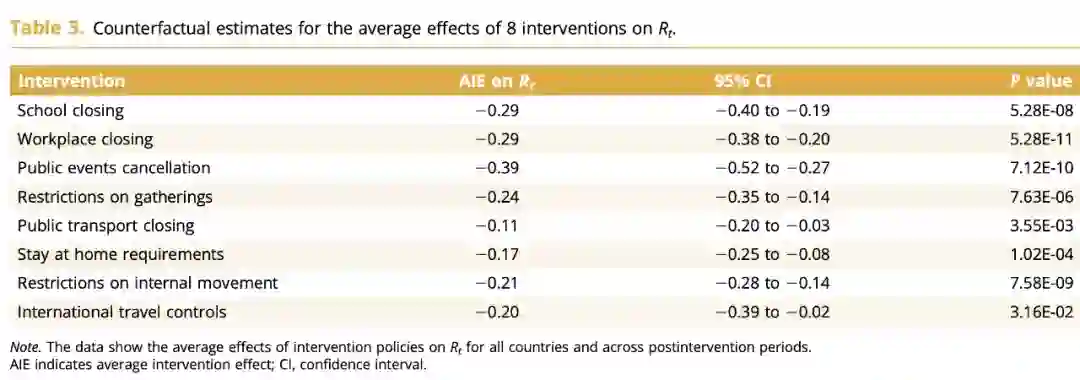
反事实推理模型计算出 8 项防控措施实施后不同时间段对 Rt (有效传播数)的抑制效应。
![]()
反事实推理模型对 8 项管控措施效果的定量评估结果。
推荐:
钟南山团队、腾讯联合研究:AI 模型评估这三项措施最有助于防控疫情
论文 5:Boosting the Transferability of Video Adversarial Examples via Temporal Translation
摘要:
近年来,深度学习在一系列任务中(例如:图像识别、目标识别、语义分割、视频识别等)取得了巨大成功。因此,基于深度学习的智能模型正逐渐广泛地应用于安防监控、无人驾驶等行业中。但最近的研究表明,深度学习本身非常脆弱,容易受到来自对抗样本的攻击。对抗样本指的是由在干净样本上增加对抗扰动而生成可以使模型发生错误分类的样本。对抗样本的存在为深度学习的应用发展带来严重威胁,尤其是最近发现的对抗样本在不同模型间的可迁移性,使得针对智能模型的黑盒攻击成为可能。具体地,攻击者利用可完全访问的模型(又称白盒模型)生成对抗样本,来攻击可能部署于线上的只能获取模型输出结果的模型(又称黑盒模型)。此外,目前的相关研究主要集中在图像模型中,而对于视频模型的研究较少。因此,亟需开展针对视频模型中对抗样本迁移性的研究,以促进视频模型的安全发展。
与图片数据相比,视频数据具有额外的时序信息,该类信息能够描述视频中的动态变化。目前已有多种不同的模型结构(例如:Non-local,SlowFast,TPN)被提出,以捕获丰富的时序信息。然而多样化的模型结构可能会导致不同模型对于同一视频输入的高响应区域不同,也会导致在攻击过程中所生成的对抗样本针对白盒模型产生过拟合而难以迁移攻击其他模型。为了进一步剖析上述观点,来自复旦大学姜育刚团队的研究人员首先针对多个常用视频识别模型(video recognition model)的时序判别模式间的相似性展开研究,发现不同结构的视频识别模型往往具有不同的时序判别模式。基于此,研究人员提出了基于时序平移的高迁移性视频对抗样本生成方法。
![]()
![]()
推荐:
首个基于时序平移的视频迁移攻击算法,复旦大学研究入选 AAAI 2022
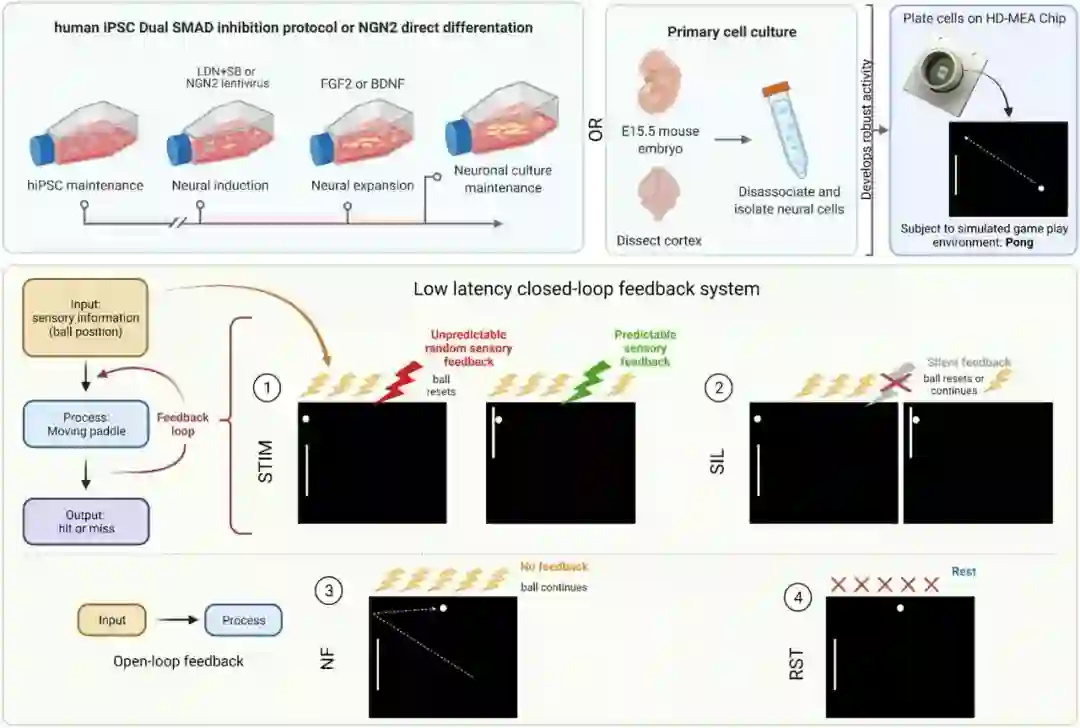
论文 6:In Vitro Neurons Learn and Exhibit Sentience when Embodied in a Simulated Game-world
摘要:
计算机再厉害,在很多方面仍然比不上人类神经元,比如能耗、学习效率等方面。于是就有研究者提出:既然人类神经元那么高效,为什么不拿来用呢?澳大利亚生物科技初创公司 Cortical Labs 一直都持有这种想法。早在两年前就有媒体报道称,这家公司正致力于把真正的生物神经元嵌入到一个特殊的计算机芯片中,构成一个微型的体外大脑。
他们希望这些合成迷你大脑能够在消耗较少能量的同时,完成很多人工智能软件可以执行的任务。他们使用两种方法来制造硬件:或从胚胎中提取小鼠神经元,或使用某种技术将人类的皮肤细胞逆向转化为干细胞,然后诱导它发育成人类神经元。当时,该公司的联合创始人兼首席执行官钟宏文(Hon Weng Chong)说,开发人员正尝试教迷你大脑玩雅达利经典乒乓游戏 Pong。两年过去,他们果然做到了:在该公司实验室的培养皿里,上百万个人类大脑细胞组成的「迷你大脑」正乐此不疲地玩乒乓。
![]()
Brett Kagan 等人还给这个系统取了个名字——「DishBrain(碟脑)」。这使人联想到了《黑客帝国》等电影中描述的缸中之脑。
![]()
推荐:
黑客帝国「缸中之脑」有眉目了?培养皿中百万人脑细胞学会打乒乓球,仅用了 5 分钟
论文 7:Learning to Compose Visual Relations
摘要:
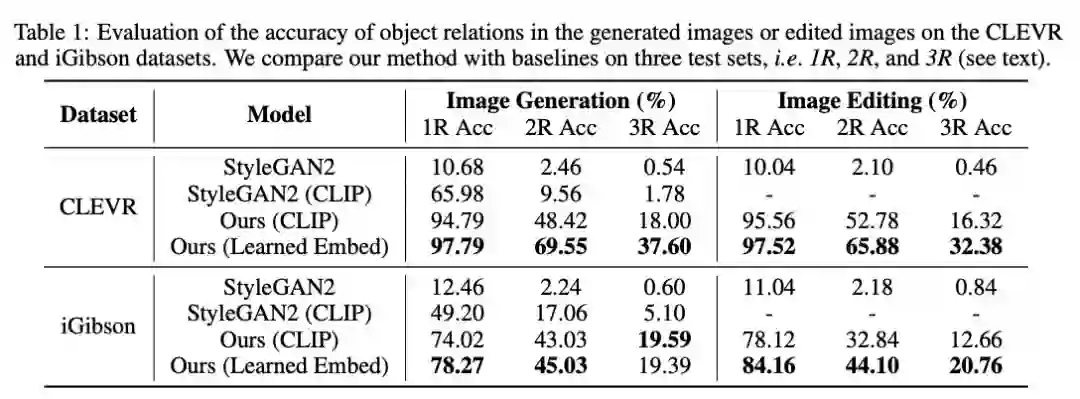
人们观察场景通常是观察场景中的物体和物体之间的关系。比如我们经常这样描述一个场景:桌面上有一台笔记本电脑,笔记本电脑的右边是一个手机。但这种观察方式对深度学习模型来说很难实现,因为这些模型不了解每个对象之间的关系。如果不了解这些关系,功能型机器人就很难完成它们的任务,例如一个厨房机器人将很难执行这样的命令:「拿起炒锅左侧的水果刀并将其放在砧板上」。
为了解决这个问题,在一篇 NeurIPS 2021 Spotlight 论文中,来自 MIT 的研究者开发了一种可以理解场景中对象之间潜在关系的模型。该模型一次表征一种个体关系,然后结合这些表征来描述整个场景,使得模型能够从文本描述中生成更准确的图像。现实生活中人们并不是靠坐标定位物体,而是依赖于物体之间的相对位置关系。这项研究的成果将应用于工业机器人必须执行复杂的多步骤操作任务的情况,例如在仓库中堆叠物品、组装电器。此外,该研究还有助于让机器能够像人类一样从环境中学习并与之交互。
![]()
![]()
CLEVR 和 iGibson 数据集上生成图像或编辑图像中物体关系的准确率评估。
推荐:
理解物体之间潜在关系,MIT 新研究让 AI 像人一样「看」世界
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. How Should Pre-Trained Language Models Be Fine-Tuned Towards Adversarial Robustness?. (from Shuicheng Yan)
2. Adapting BERT for Continual Learning of a Sequence of Aspect Sentiment Classification Tasks. (from Bing Liu)
3. Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning. (from Bing Liu)
4. CLASSIC: Continual and Contrastive Learning of Aspect Sentiment Classification Tasks. (from Bing Liu)
5. Continual Learning with Knowledge Transfer for Sentiment Classification. (from Bing Liu)
6. ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation. (from Yu Sun, Wen Gao)
7. Explain, Edit, and Understand: Rethinking User Study Design for Evaluating Model Explanations. (from Norman Sadeh, William W. Cohen)
8. Improving scripts with a memory of natural feedback. (from Yiming Yang)
9. Mixed Precision Low-bit Quantization of Neural Network Language Models for Speech Recognition. (from Xunying Liu)
10. Mixed Precision of Quantization of Transformer Language Models for Speech Recognition. (from Xunying Liu)
1. Translational Concept Embedding for Generalized Compositional Zero-shot Learning. (from Philip S. Yu)
2. Watch Those Words: Video Falsification Detection Using Word-Conditioned Facial Motion. (from Trevor Darrell)
3. Meta-Learning and Self-Supervised Pretraining for Real World Image Translation. (from Marin Soljačić)
4. EyePAD++: A Distillation-based approach for joint Eye Authentication and Presentation Attack Detection using Periocular Images. (from Rama Chellappa)
5. Distill and De-bias: Mitigating Bias in Face Recognition using Knowledge Distillation. (from P. Jonathon Phillips, Rama Chellappa)
6. Robust and Precise Facial Landmark Detection by Self-Calibrated Pose Attention Network. (from Witold Pedrycz)
7. Point2Cyl: Reverse Engineering 3D Objects from Point Clouds to Extrusion Cylinders. (from Leonidas Guibas)
8. Domain Adaptation on Point Clouds via Geometry-Aware Implicits. (from Leonidas Guibas)
9. On Efficient Transformer and Image Pre-training for Low-level Vision. (from Xiangyu Zhang, Jiaya Jia)
10. RepMLPNet: Hierarchical Vision MLP with Re-parameterized Locality. (from Xiangyu Zhang)
本周 10 篇 ML 精选论文是:
1. On the Adversarial Robustness of Causal Algorithmic Recourse. (from Bernhard Schölkopf)
2. Toward Explainable AI for Regression Models. (from Klaus-Robert Müller)
3. Sublinear Time Approximation of Text Similarity Matrices. (from Andrew McCallum)
4. Max-Margin Contrastive Learning. (from Rama Chellappa)
5. Distributionally Robust Group Backwards Compatibility. (from Guillermo Sapiro)
6. Continual Learning of a Mixed Sequence of Similar and Dissimilar Tasks. (from Bing Liu)
7. Estimating Causal Effects of Multi-Aspect Online Reviews with Multi-Modal Proxies. (from Huan Liu)
8. SkipNode: On Alleviating Over-smoothing for Deep Graph Convolutional Networks. (from Dacheng Tao)
9. A Robust Optimization Approach to Deep Learning. (from Dimitris Bertsimas)
10. KGBoost: A Classification-based Knowledge Base Completion Method with Negative Sampling. (from C.-C. Jay Kuo)
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com