横扫6个SOTA,吊打强化学习!谷歌最强行为克隆算法登CoRL顶会,机器人干活10倍速

新智元报道
新智元报道
编辑:小咸鱼 David
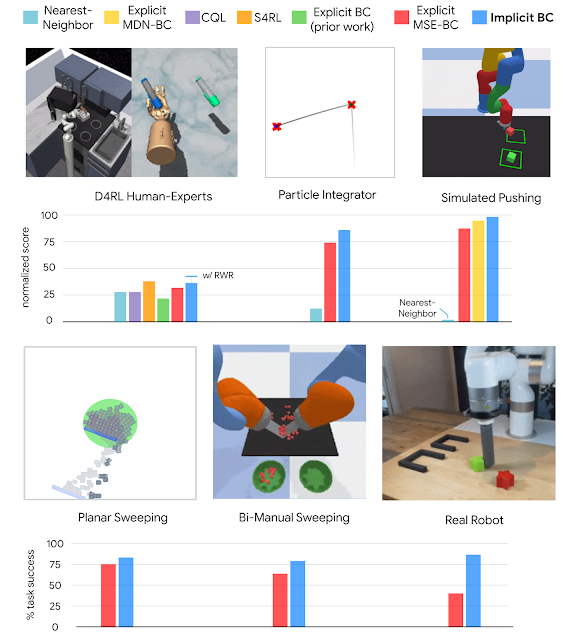
【新智元导读】谷歌团队在CoRL 2021上提出了一种隐式行为克隆 (Implicit BC) 算法,该方法在7项测试任务中的6项上优于此前最佳的离线强化学习方法(Conservative Q Learning)。Implicit BC在现实世界中表现也得特别好,比基线的显式行为克隆(explicit BC)模型好10倍


精度有限。
因计算维度导致成本过高,许多离散化不同的维度会显著增加内存和计算需求。在 3D 计算机视觉任务中,近期的许多重要模型都是由连续,而非离散表示来驱动的。
隐式行为克隆(Implicit BC)
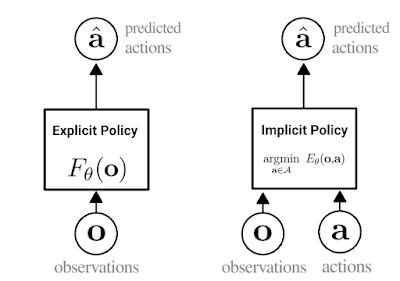
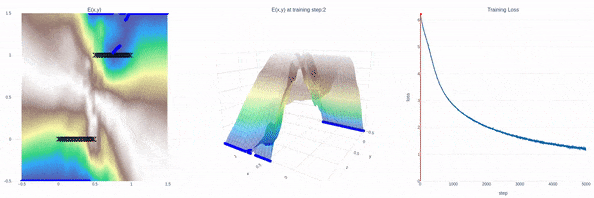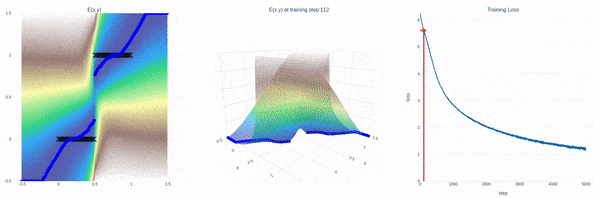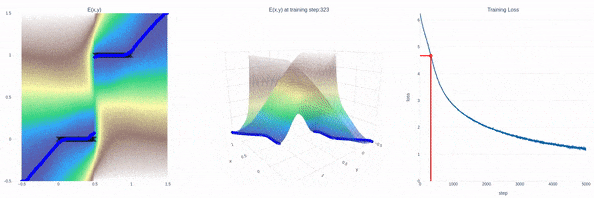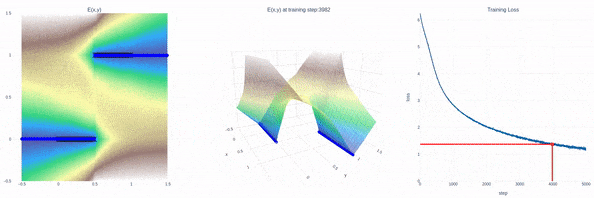

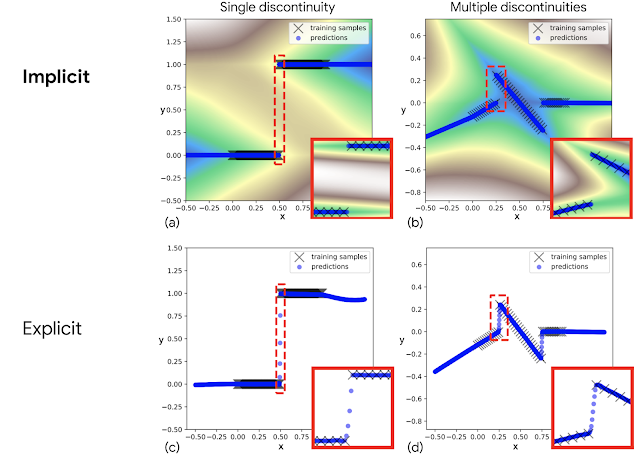
全新SOTA


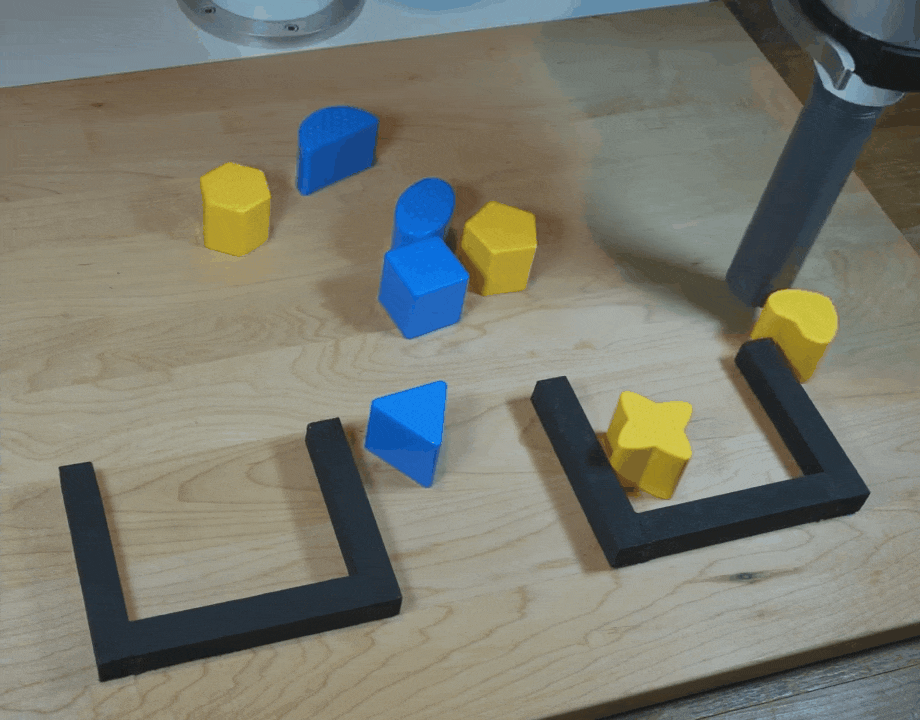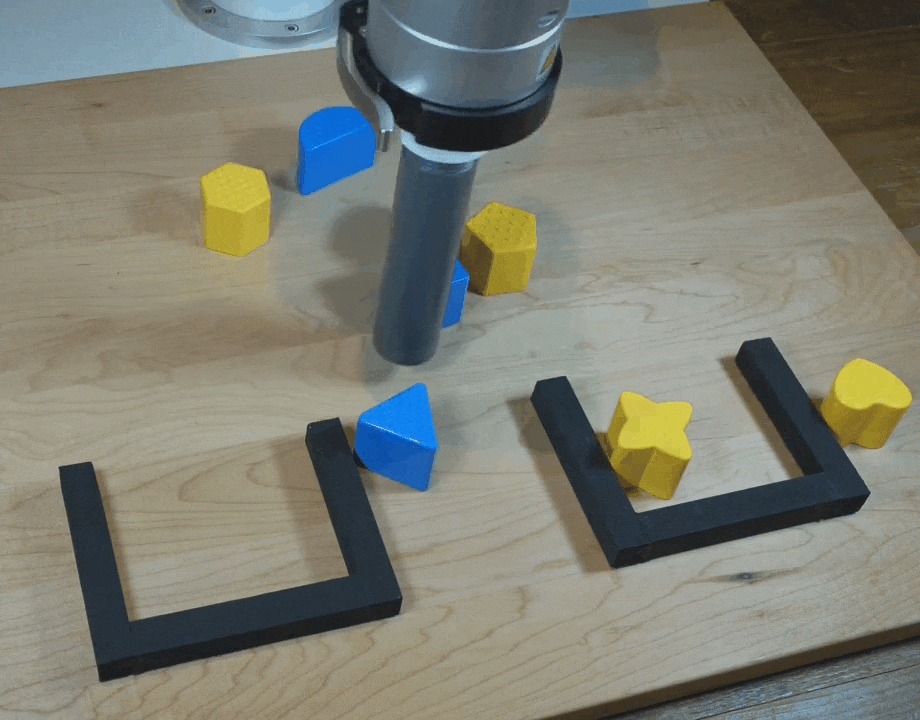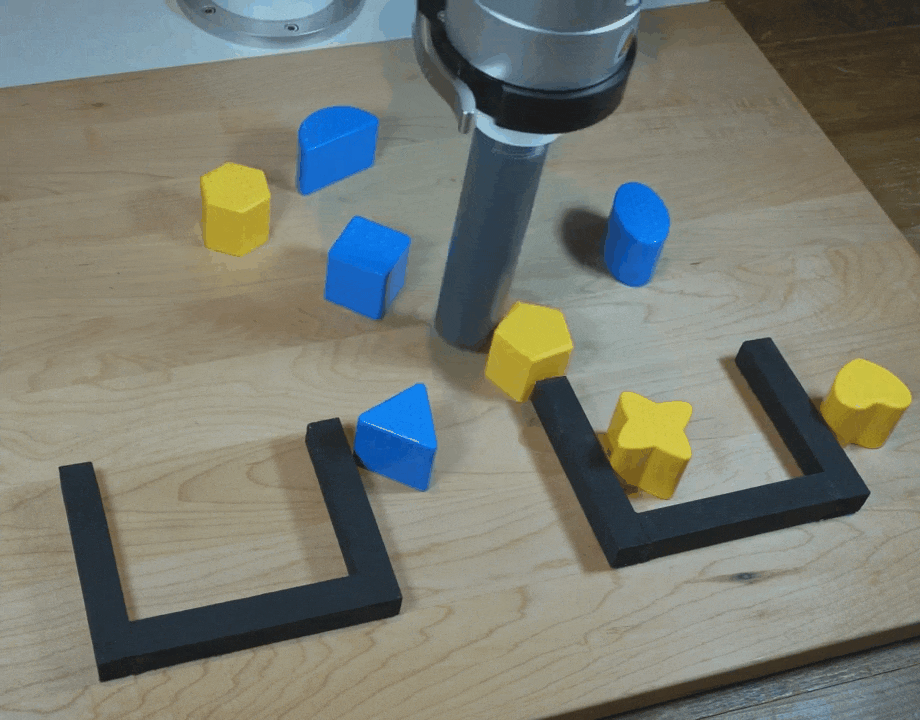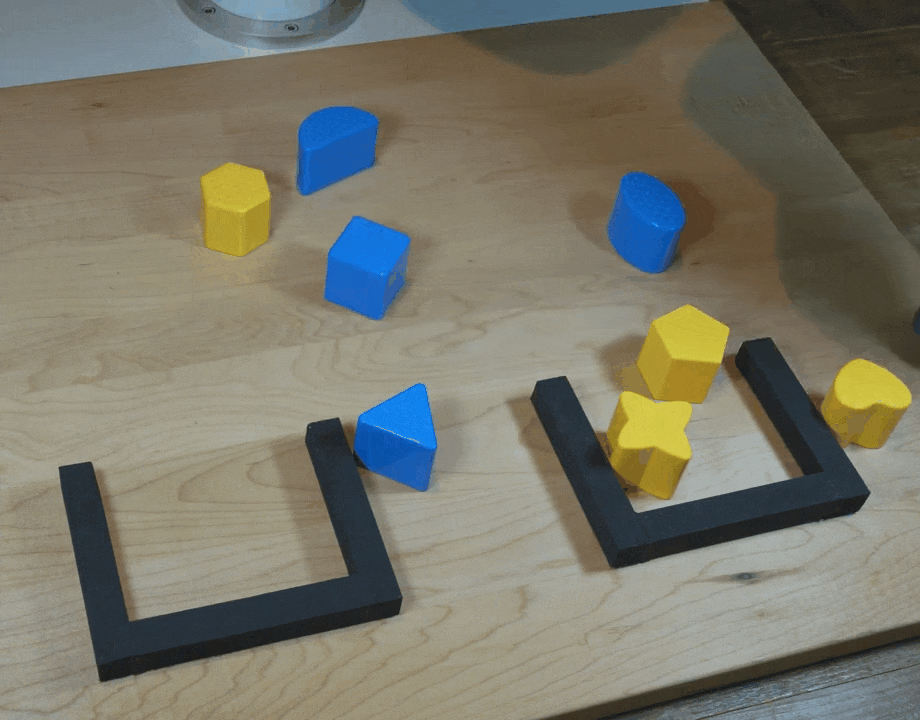
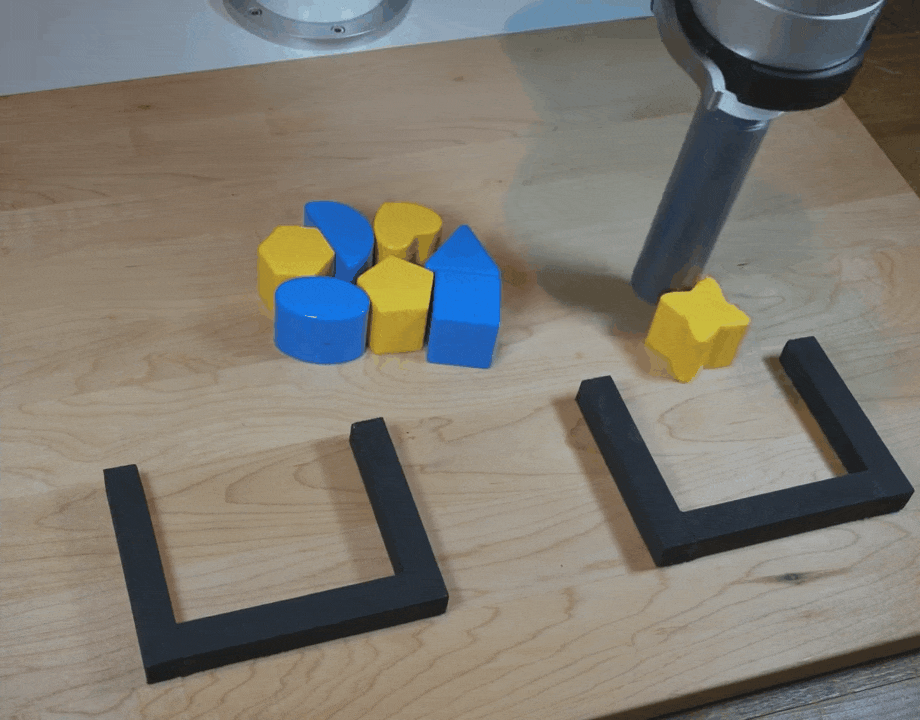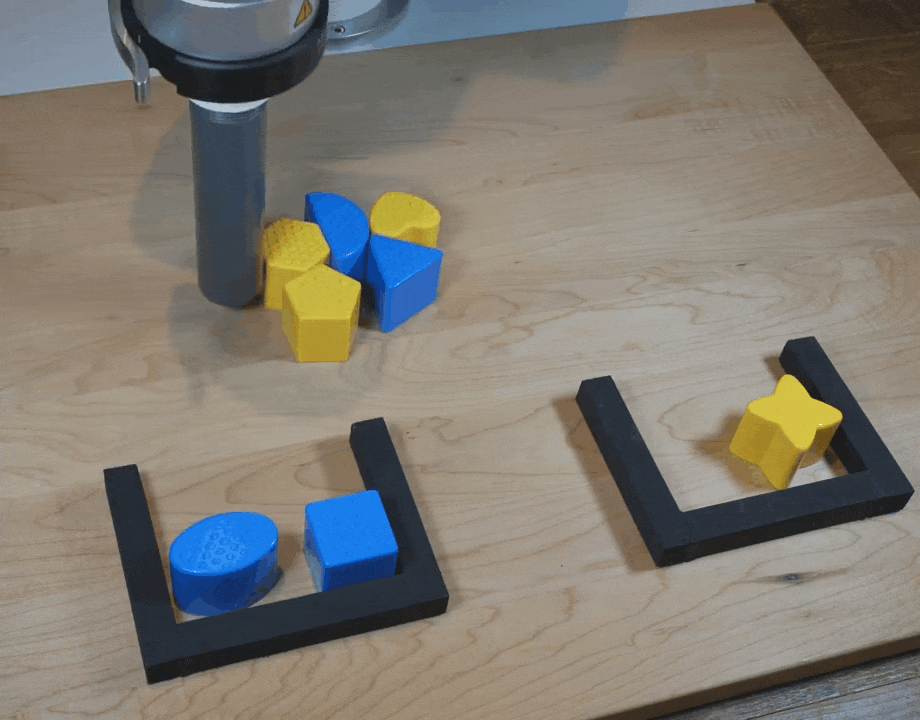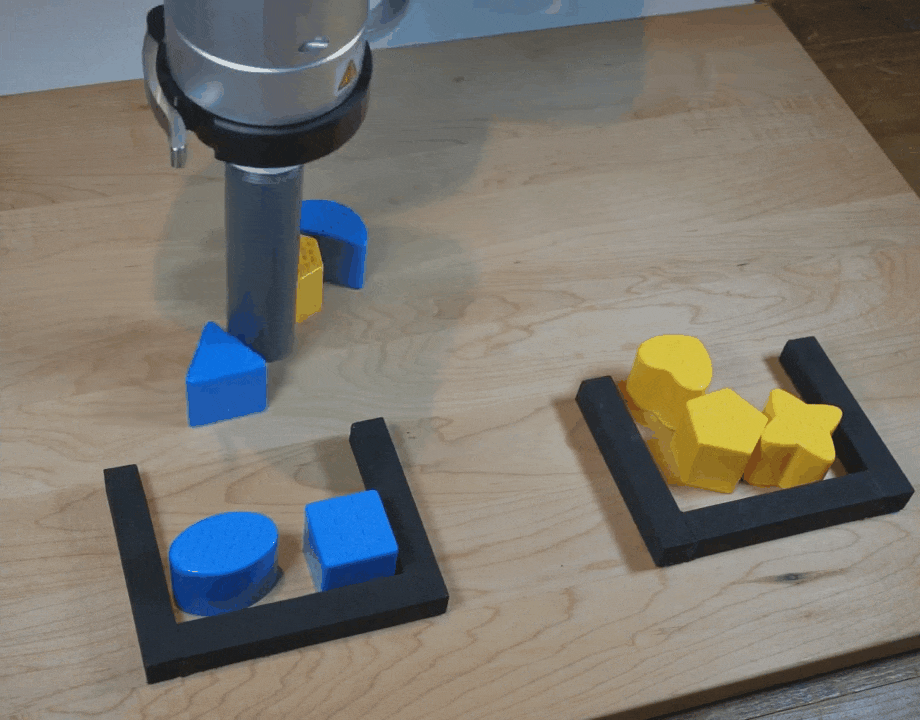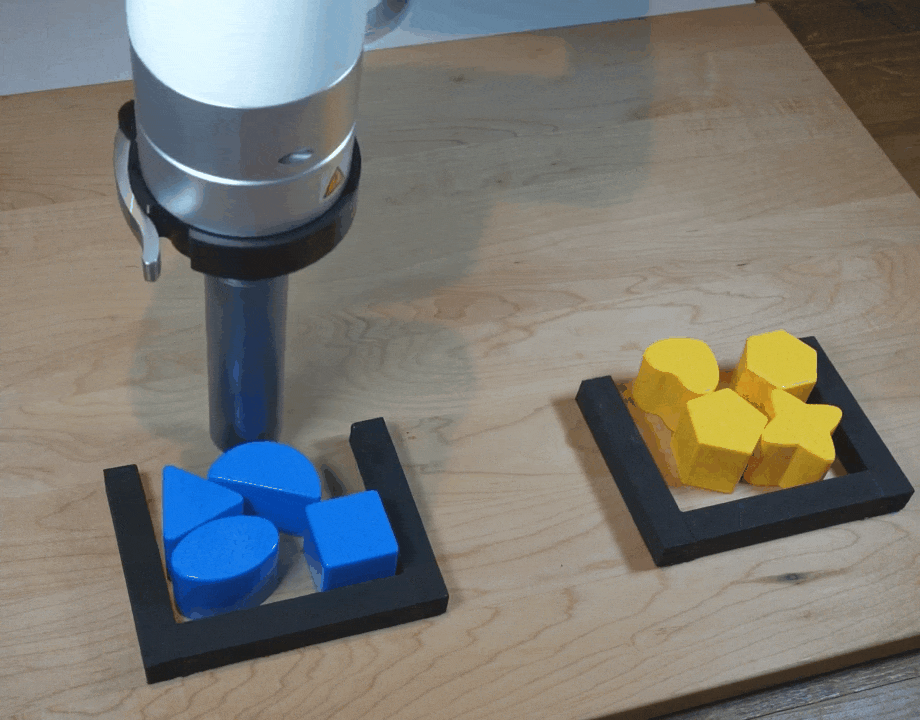

https://ai.googleblog.com/2021/11/decisiveness-in-imitation-learning-for.html

登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月16日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月16日