7 Papers & Radios | 谷歌用Pathways训练5400亿参数大模型;费米实验室研究登《科学》封面
本周论文包括费米实验室发现,一种被称为 W 玻色子的基本粒子似乎比标准模型预测得要重 0.1%,这一研究登上《科学》封面;谷歌用 Pathways 系统训练了一个 5400 亿参数的大型语言模型——PaLM(Pathways Language Model)等研究。
Training Compute-Optimal Large Language Models
PaLM: Scaling Language Modeling with Pathways
Continuous flattening of all polyhedral manifolds using countably infinite creases
High-precision measurement of the W boson mass with the CDF II detector
Hierarchical Text-Conditional Image Generation with CLIP Latents
Rethinking Document-level Neural Machine Translation
StyTr^2 :Image Style Transfer with Transformers
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Training Compute-Optimal Large Language Models
作者:Jordan Hoffmann 、 Sebastian Borgeaud 等
论文链接:https://arxiv.org/pdf/2203.15556.pdf
摘要:Kaplan 等人研究 (2020) 表明,自回归语言模型 (LM) 中的参数数量与其性能之间存在幂律关系。结果是该领域一直在训练越来越大的模型,期望性能得到改善。Kaplan 等人 (2020) 得出的一个值得注意的结论是,不应该将大型模型训练到其可能的最低损失,以获得计算的最佳化。
来自 DeepMind 的研究者得出了相同的结论,但他们估计大型模型可以训练的 token 数应该比作者推荐的更多。具体来说,假设计算预算增加 10 倍,其他研究者建议模型的大小应该增加 5.5 倍,而训练 token 的数量应该只增加 1.8 倍。相反,DeepMind 发现模型大小和训练 token 的数量应该以相等的比例扩展。
DeepMind 根据 400 多个模型的损失估计了这些函数,参数范围从 70M 到 16B 以上,并在 5B 到 400B 多个 token 上进行训练——每个模型配置都针对几个不同的训练范围进行训练。结果表明 DeepMind 方法得出的结果与 Kaplan 等人的结果大不相同,如下图 1 所示:
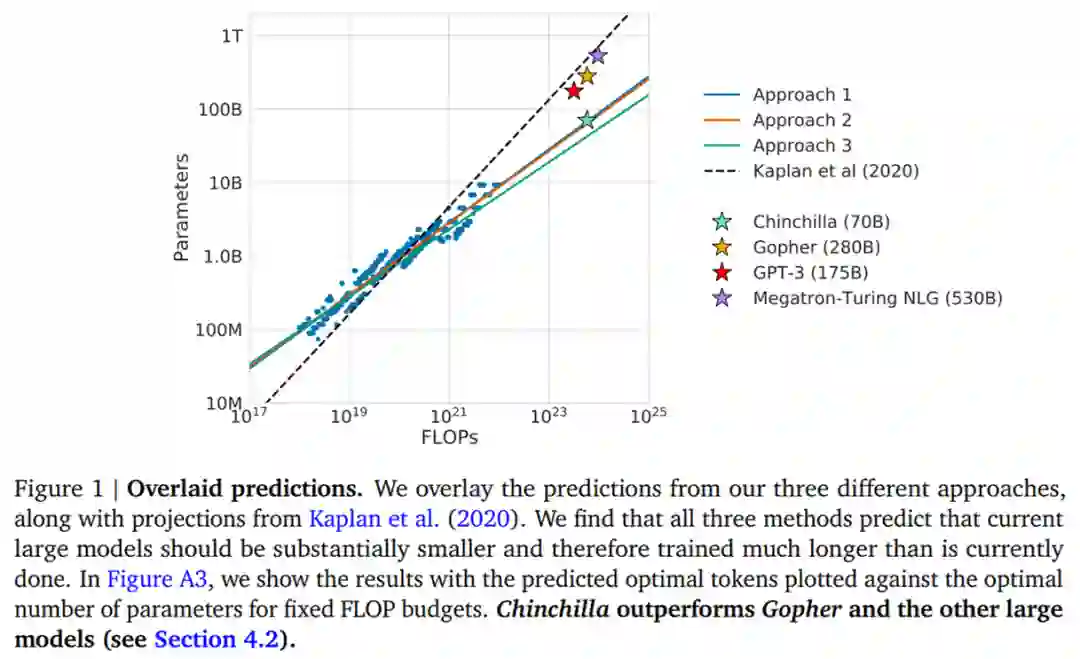
基于 DeepMind 估计的计算最优边界,他们预测用于训练 Gopher 的计算预算,一个最优模型应该是模型大小比之前小 4 倍,而训练的 token 应该是之前的 4 倍多。
为了证明这一点,DeepMind 训练了一个更优计算的 70B 模型 Chinchilla,具有 1.4 万亿个 token。Chinchilla 不仅性能优于模型更大的 Gopher,而且其减小的模型尺寸大大降低了推理成本,并极大地促进了在较小硬件上的下游使用。大型语言模型的能源成本通过其用于推理和微调的用途来摊销。因此,经过更优化训练的较小模型的好处,超出了其性能改善的直接好处。

推荐:DeepMind 用 700 亿打败自家 2800 亿,训练优化出「小」模型。
论文 2:PaLM: Scaling Language Modeling with Pathways
作者:Aakanksha Chowdhery 、 Sharan Narang 等
论文链接:https://storage.googleapis.com/pathways-language-model/PaLM-paper.pdf
摘要:在「PaLM: Scaling Language Modeling with Pathways」中,谷歌宣布,他们用 Pathways 系统训练了一个 5400 亿参数的大型语言模型——PaLM(Pathways Language Model)。
这是一个只有解码器的密集 Transformer 模型。为了训练这个模型,谷歌动用了 6144 块 TPU,让 Pathways 在两个 Cloud TPU v4 Pods 上训练 PaLM。
强大的系统和算力投入带来了惊艳的结果。研究者在数百个语言理解和生成任务上评估了 PaLM,发现它在大多数任务上实现了 SOTA 少样本学习性能,可以出色地完成笑话解读、bug 修复、从表情符号中猜电影等语言、代码任务。
PaLM 只包含解码器(每个时间步只能关注自身和过去的时间步),对一种标准的 Transformer 架构((Vaswani et al., 2017))做出了如下更改:
SwiGLU 激活
研究者使用 SwiGLU 激活 (Swish(xW) · xV) 用于 MLP 中间激活,因为研究表明,与标准 ReLU、GeLU 或 Swish 激活相比,SwiGLU 激活能显著提高质量。注意,在 MLP 中,这确实需要三个矩阵乘法,而不是两个,但 Shazeer (2020) 在计算等效实验中证明了质量的提升。
并行层
研究者在每个 Transformer 模块中使用「并行」方法,而不是标准的「串行」方法。具体来说,标准方法可以写成:
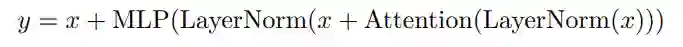
并行方法可以写成
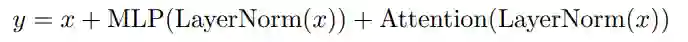
由于 MLP 和注意力输入矩阵乘法可以融合,这里的并行方法可以让大规模训练速度提升 15%。消融实验显示,在 8B 的规模下,质量下降很小,但在 62B 规模下,质量没有下降,因此研究者推断,并行层的影响会在 540B 规模下达到 quality neutral。
PaLM 是谷歌首次大规模使用 Pathways 系统将训练扩展到 6144 块芯片,这是迄今为止用于训练的基于 TPU 的最大系统配置。研究者在 Pod 级别上跨两个 Cloud TPU v4 Pods 使用数据并行对训练进行扩展,同时在每个 Pod 中使用标准数据和模型并行。与以前的大多数 LLM 相比,这是一个显著的规模增长。
PaLM 实现了 57.8% 的硬件 FLOPs 利用率的训练效率,这是 LLM 在这个规模上实现的最高效率。为了达到这一水平,研究者将并行策略和 Transformer 块的重新设计结果相结合,这使得注意力层和前馈层并行计算成为可能,从而实现了 TPU 编译器优化带来的加速。
PaLM 使用英语和多语言数据集进行训练,包括高质量的 web 文档、书籍、维基百科、对话和 GitHub 代码。研究者还创建了一个「无损(lossless)」词汇表,它保留了所有空格(对于代码来说尤其重要),将词汇表之外的 Unicode 字符拆分成字节,并将数字拆分成单独的 token,每个 token 对应一个数字。
推荐:6144 块 TPU,5400 亿参数,会改 bug、解读笑话,谷歌刚刚用 Pathways 训练了一个大模型。
论文 3:Continuous flattening of all polyhedral manifolds using countably infinite creases
作者:ZacharyAbel、Erik D.Demaine 等
论文链接:https://www.sciencedirect.com/science/article/abs/pii/S0925772121000298
摘要:计算机科学家 Erik Demaine 和他的艺术家兼计算机科学家父亲 Martin Demaine 多年来一直在挑战折纸的极限。
在这篇题为《使用可数无限折痕对所有多面体流形进行连续展平》的论文中,Erik 等人表示,他们证明了,如果扩展标准折叠模型以允许可数无限折痕出现,则可以将 3D 中的任何有限多面体流形连续平展为 2D,同时保留固有距离并避免交叉。
这一结果回答了 Demaine 父子和 Erik 博导 Anna Lubiw 2001 年提出的一个问题。他们想知道是否有可能取任何有限多面体(或 flat-sided)形状(比如立方体,而不是球体或无限大的平面),然后用折痕将其折平。
当然,你不能将形状剪开或撕裂。此外,形状的固有距离还要保持不变,「也就是说,『你不能拉伸或收缩这个材料』,」Erik 说。而且他指出,这种类型的折叠还必须避免交叉,这意味着「我们不希望纸张穿过自己」,因为这在现实世界中不会发生。「当所有东西都在 3D 中连续移动时,满足这些限制将非常具有挑战性」。综上所述,这些约束意味着简单地挤压形状是行不通的。Erik 父子等人的研究表明,你可以完成这种折叠,但前提是使用无限折叠策略。不过在此之前,几位作者在 2015 年发表的一篇论文中也提出了另一项实用技术。
在这篇论文中,他们研究了一类更简单的形状的折叠问题:正交多面体,其面以直角相交,并且垂直于 x、y 和 z 坐标轴中的至少一个。满足这些条件会强制形状的面为矩形,这使得折叠更简单,就像折叠冰箱盒一样。
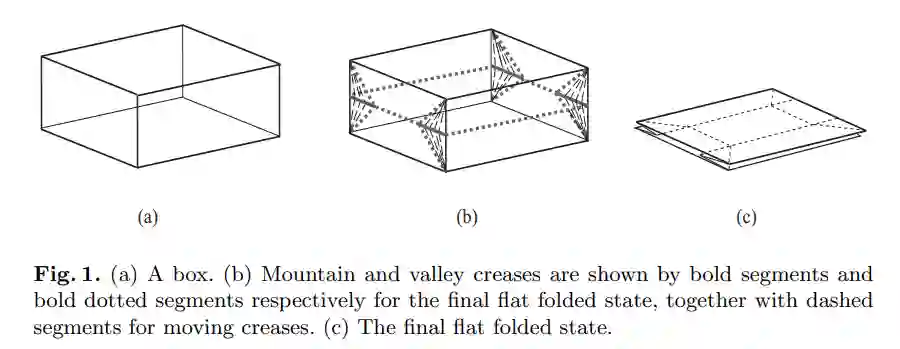
推荐:折纸中的「降维」:这对父子解出了困扰学界十多年的几何难题。
论文 4:High-precision measurement of the W boson mass with the CDF II detector
作者:CDF COLLABORATION、T. AALTONEN 等
论文链接:https://www.science.org/doi/10.1126/science.abk1781
摘要:物理学家发现,一种被称为 W 玻色子的基本粒子似乎比标准模型预测得要重 0.1%,这一微小的差异可能预示着基础物理学将迎来重大转变,相关结果登上了新一期的《科学》杂志封面。
这一测量结果来自美国费米国家加速器实验室的一台老式粒子对撞机——Tevatron,它在十年前粉碎了最后一批质子。在此之后,由 400 多位成员组成的 CDF(Collider Detector at Fermilab)小组继续分析对撞机产生的 W 玻色子,追踪无数的误差源,以达到无与伦比的精确度。

这一发现正值物理学界渴望发现粒子物理学标准模型的缺陷之际。标准模型是一套长期统治物理学界的方程,它涵盖了所有已知的粒子和力。已知标准模型是不完整的,很多问题借助标准模型都很难解释,例如暗物质的性质。CDF 小组的良好记录使得他们的新结果对标准模型构成了可信的威胁。
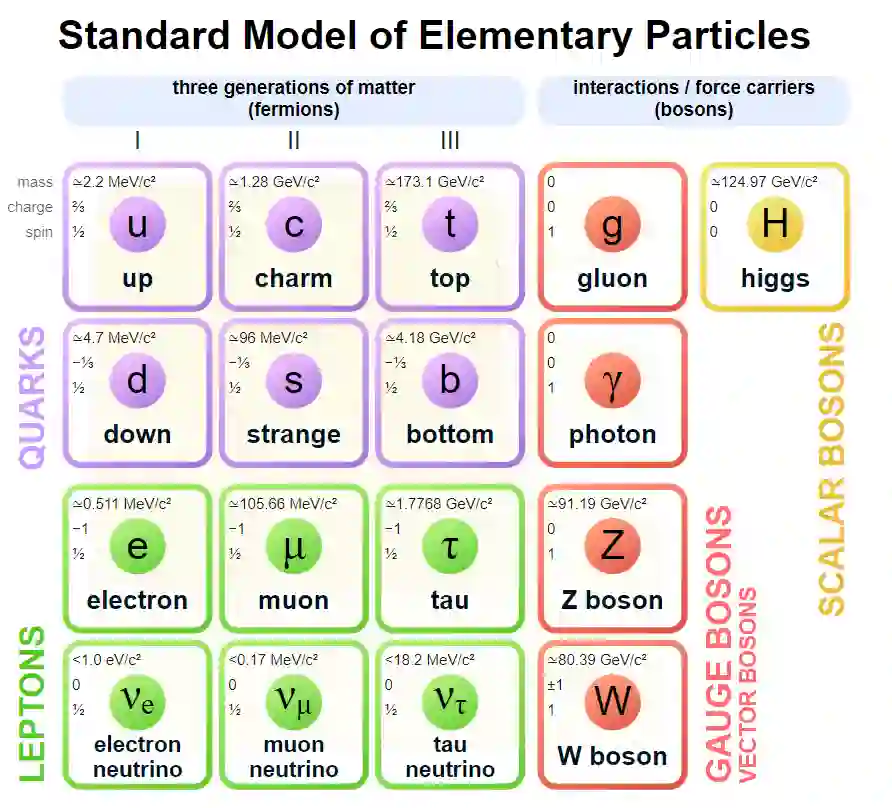
在粒子物理学里,标准模型(英语:Standard Model, SM)是一套描述强力、弱力及电磁力这三种基本力及组成所有物质的基本粒子的理论。它隶属量子场论的范畴,并与量子力学及狭义相对论相容。几乎所有对以上三种力的实验的结果都合乎这套理论的预测。但是标准模型还不是一套万有理论,主要是因为它并没有描述到引力。标准模型共 61 种基本粒子,包含费米子及玻色子——费米子为拥有半奇数的自旋并遵守泡利不相容原理(这原理指出没有相同的费米子能占有同样的量子态)的粒子;玻色子则拥有整数自旋而并不遵守泡利不相容原理。
在 2020 年 11 月的一次 Zoom 会议上,杜克大学的物理学家、CDF 背后的推动者 Ashutosh Kotwal 解密了团队的最新结果。在座的物理学家在消化答案的同时陷入了沉默。他们发现 W 玻色子的重量为 804.33 亿电子伏特 (MeV),误差在 9 MeV 左右。这使得它比标准模型预测的重 76 MeV,这个差异大约是测量或预测的误差范围的七倍。
推荐:基础物理面临冲击:费米实验室 W 玻色子质量实验与理论矛盾,登《科学》封面。
论文 5:Hierarchical Text-Conditional Image Generation with CLIP Latents
作者:Aditya Ramesh 、 Prafulla Dhariwal 等
论文链接:https://cdn.openai.com/papers/dall-e-2.pdf
摘要:去年 1 月 6 日,OpenAI 发布了新模型 DALL·E,不用跨界也能从文本生成图像,打破了自然语言与视觉次元壁,引起了 AI 圈的一阵欢呼。
时隔一年多后,DALL·E 迎来了升级版本——DALL·E 2。
与 DALL·E 相比,DALL·E 2 在生成用户描述的图像时具有更高的分辨率和更低的延迟。并且,新版本还增添了一些新的功能,比如对原始图像进行编辑。
OpenAI 还公布了 DALL·E 2 的研究论文《Hierarchical Text-Conditional Image Generation with CLIP Latents》,OpenAI 研究科学家、共同一作 Prafulla Dhariwal 表示,「这个神经网络真是太神奇了,根据文本描述就能生成对应图像。」
首先,DALL·E 2 可以从文本描述中创建原始、逼真的图像和艺术,它可以组合概念、属性和风格进行图像生成。例如一位骑着马的宇航员:

DALL·E 2 比一代模型到底好在哪?简单来说 DALL·E 2 以 4 倍的分辨率生成更逼真、更准确的图像。例如下图生成一幅「日出时坐在田野里的狐狸,生成的图像为莫奈风格。」DALL·E 2 生成的图像更准确。

看完上述展示,我们可以将 DALL·E 2 的特点归结如下:DALL·E 2 的一项新功能是修复,在 DALL·E 1 的基础上,将文本到图像生成应用在图像更细粒度的级别上。用户可以从现有的图片开始,选择一个区域,让模型对图像进行编辑,例如,你可以在客厅的墙上画一幅画,然后用另一幅画代替它,又或者在咖啡桌上放一瓶花。该模型可以填充 (或删除) 对象,同时考虑房间中阴影的方向等细节。
DALL·E 2 的另一个功能是生成图像不同变体,用户上传一张图像,然后模型创建出一系列类似的变体。此外,DALL·E 2 还可以混合两张图片,生成包含这两种元素的图片。其生成的图像为 1024 x 1024 像素,大大超过了 256 x 256 像素。
DALL·E 2 建立在 CLIP 之上,CLIP 旨在以人类的方式查看图像并总结其内容,OpenAI 迭代创建了一个 CLIP 的倒置版本——「unCLIP」,它能从描述生成图像,而 DALL·E 2 使用称为扩散(diffusion)的过程生成图像。
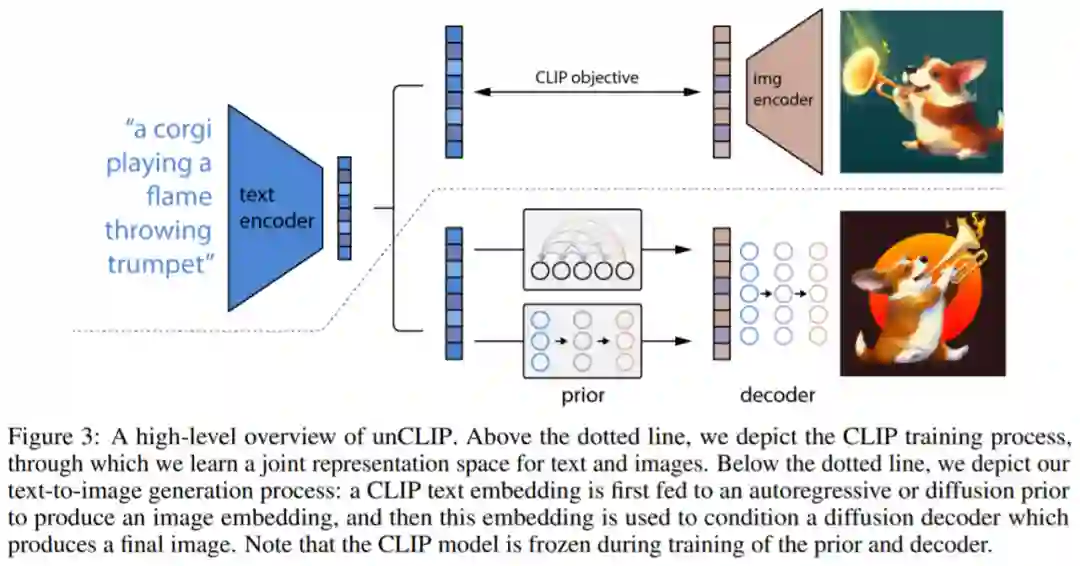
推荐:OpenAI 的 DALL·E 迎来升级,不止文本生成图像,还可二次创作。
论文 6:Rethinking Document-level Neural Machine Translation
作者:Zewei Sun 、 Mingxuan Wang 等
论文链接:https://arxiv.org/abs/2010.08961
摘要:一篇由字节跳动 AI-Lab 火山翻译团队、南京大学与加州圣塔芭芭拉分校共同发表在 ACL 2022 的长文 —— Rethinking Document-level Neural Machine Translation。
这篇论文重新审视了篇章机器翻译领域的过往工作,针对当下流行的研究趋势进行了反思,并提出回归到经典简洁的 Transformer 模型解决篇章翻译问题,通过多分解度的训练方案取得了 SOTA 的效果。最后,这篇文章也贡献了一份新的数据集,旨在推动整个领域的发展。
本文介绍了一种新的篇章级别神经机器翻译的方法:「篇章到篇章」(Doc2Doc)的翻译。
首先,我们需要定义这个任务:令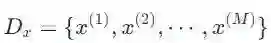
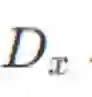
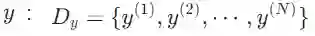
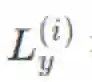
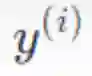
区别于「篇章到句子」的翻译,字节 AI Lab 的研究者提出了一项新的训练方式——「篇章到篇章」的翻译。将整篇文档作为一个完整的序列送入模型中:
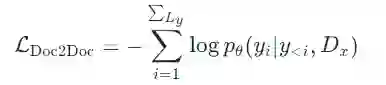
其中 D_x 是源端的完整序列信息,y<i 是目标端的历史信息。
推荐:字节 AI Lab 提出篇章到篇章的机器翻译新思路。
论文 7:StyTr^2 :Image Style Transfer with Transformers
作者:Yingying Deng 、 Fan Tang 等
论文链接:https://arxiv.org/abs/2105.14576
摘要:图像风格化是一个有趣且实用的课题,它可以使用参考的风格图像来呈现内容图像,多年以来在学术界被广泛研究,并已在包括短视频领域在内的业界得到大规模的落地应用。例如,移动互联网用户可以通过快手主站、极速版、一甜相机和快影等一系列 APP,体验包括手绘、水彩、油画和 Q 版萌系风格在内的各种人像风格化特效。
本文针对基于 CNN 的风格化方法存在的内容表达存在偏差的问题,提出了一种新颖的图像风格化算法,即 StyTr^2。
为了利用 Transformer 捕获长期依赖关系的能力来实现图像风格化,本文设计了图 2 中结构,模型主要包括三部分:内容 Transformer 编码器,风格 Transformer 编码器和 Transformer 解码器。内容 Transformer 编码器和风格 Transformer 编码器分别用来编码内容域和风格域的图片的长程信息,这种编码方式可以有效避免细节丢失问题。Transformer 解码器用来将内容特征转换为带有风格图片特征的风格化结果。
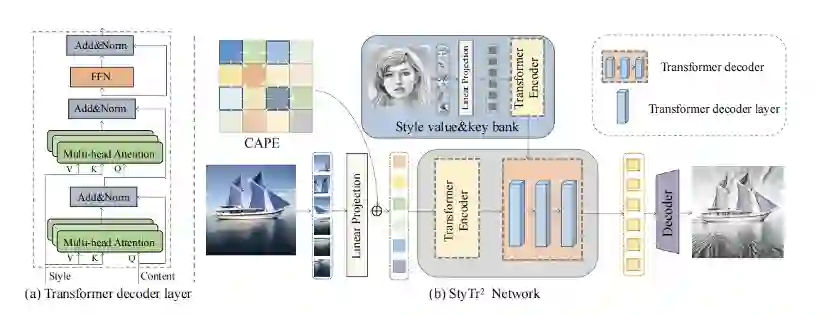
图 2 网络结构
此外,本文针对传统位置编码提出两个重要问题。第一,对于图像生成任务,在计算 PE(位置编码)时,是否应该考虑图像语义? 传统的 PE 是根据按照逻辑排序的句子来设计的,而图像序列是根据图像内容语义来组织的。假设两个图像补丁之间的距离为 d(.,.) 。如图 3(a) 右边部分所示,d((0 , 3 ), (1 , 3 )) (红色和绿色块) 之间的差异与 d(( 0 , 3 ), (3 , 3 )) (红色和青色 块) 之间的差异应该是相似的,因为风格化任务要求相似的内容补丁有相似的风格化结果。第二,当输入图像尺寸呈指数级增大时,传统的正弦位置编码是否仍然适用于视觉任务? 如 3(a) 所示,当图像大小发生变化时,相同语义位置的补丁 (用蓝色小矩形表示) 之间的相对距离会发生显著变化,这不适合视觉任务中的多尺度输入要求。
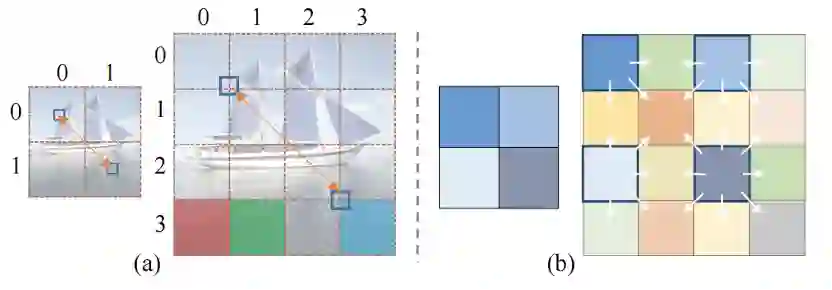
图 3 CAPE 计算示意图
为此,本文提出了内容感知的位置编码 (Content-Aware Positional Encoding,CAPE),它具有尺度不变且与内容语义相关的特点,更适合于风格化任务。
推荐:快手联合中科院自动化所提出基于 Transformer 的图像风格化方法。
本周 10 篇 NLP 精选论文是:
1. Pareto-optimal clustering with the primal deterministic information bottleneck. (from Max Tegmark)
2. Simplicial Embeddings in Self-Supervised Learning and Downstream Classification. (from Aaron Courville)
3. Bridging the Gap of AutoGraph between Academia and Industry: Analysing AutoGraph Challenge at KDD Cup 2020. (from Isabelle Guyon)
4. Discovering and forecasting extreme events via active learning in neural operators. (from George Em Karniadakis)
5. Energy-Efficient Adaptive Machine Learning on IoT End-Nodes With Class-Dependent Confidence. (from Luca Benini)
6. Chordal Sparsity for Lipschitz Constant Estimation of Deep Neural Networks. (from George J. Pappas, Rajeev Alur)
7. Imitating, Fast and Slow: Robust learning from demonstrations via decision-time planning. (from Pieter Abbeel)
8. Distributed Statistical Min-Max Learning in the Presence of Byzantine Agents. (from George J. Pappas)
9. Long-tailed Extreme Multi-label Text Classification with Generated Pseudo Label Descriptions. (from Yiming Yang)
10. Complex-Valued Autoencoders for Object Discovery. (from Max Welling)
本周 10 篇 CV 精选论文是:
1. AdaFace: Quality Adaptive Margin for Face Recognition. (from Anil K. Jain)
2. Temporal Alignment Networks for Long-term Video. (from Andrew Zisserman)
3. Learning Audio-Video Modalities from Image Captions. (from Cordelia Schmid)
4. ObjectFolder 2.0: A Multisensory Object Dataset for Sim2Real Transfer. (from Li Fei-Fei)
5. Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language. (from Vikas Sindhwani, Vincent Vanhoucke)
6. Improving Vision Transformers by Revisiting High-frequency Components. (from Shuicheng Yan, Wei Liu)
7. TransGeo: Transformer Is All You Need for Cross-view Image Geo-localization. (from Mubarak Shah)
8. PSTR: End-to-End One-Step Person Search With Transformers. (from Mubarak Shah)
9. Animatable Neural Radiance Fields from Monocular RGB-D. (from Ming-Hsuan Yang)
10. Autoregressive 3D Shape Generation via Canonical Mapping. (from Ming-Hsuan Yang)
1. Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators. (from Jiawei Han)
2. Multifaceted Improvements for Conversational Open-Domain Question Answering. (from Philip S. Yu)
3. The Moral Integrity Corpus: A Benchmark for Ethical Dialogue Systems. (from Alon Halevy)
4. A sequence-to-sequence approach for document-level relation extraction. (from Gary D. Bader)
5. Exploiting Local and Global Features in Transformer-based Extreme Multi-label Text Classification. (from Yiming Yang)
6. CTRLEval: An Unsupervised Reference-Free Metric for Evaluating Controlled Text Generation. (from Minlie Huang)
7. Parameter-Efficient Abstractive Question Answering over Tables or Text. (from Maarten de Rijke)
8. Metaphorical User Simulators for Evaluating Task-oriented Dialogue Systems. (from Maarten de Rijke)
9. Evaluating the Text-to-SQL Capabilities of Large Language Models. (from Dzmitry Bahdanau)
10. Data Augmentation for Intent Classification with Off-the-shelf Large Language Models. (from Dzmitry Bahdanau)
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


