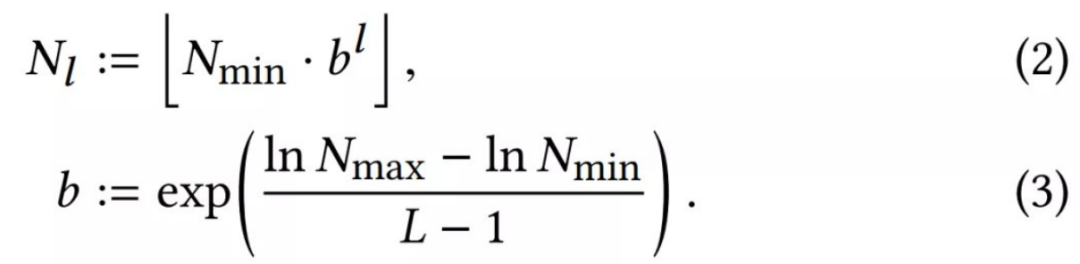机器之心 & ArXiv Weekly Radiostation
本周论文包括Meta AI提出了一种名为 data2vec 的自监督学习新架构,在多种模态的基准测试中超越了现有 SOTA 方法;谷歌、MIT 等提出分类器可视化解释方法 StylEx等。
data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
An Introduction to Autoencoders
Vision Transformer with Deformable Attention
Pushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
摘要:
Meta AI(原 Facebook AI)提出了一种名为 data2vec 的自监督学习新架构,在多种模态的基准测试中超越了现有 SOTA 方法。
data2vec 是首个适用于多模态的高性能自监督算法。Meta AI 将 data2vec 分别应用于语音、图像和文本,在计算机视觉、语音任务上优于最佳单一用途算法,并且在 NLP 任务也能取得具有竞争力的结果。此外,data2vec 还代表了一种新的、全面的自监督学习范式,其提高了多种模态的进步,而不仅仅是一种模态。data2vec 不依赖对比学习或重建输入示例,除了帮助加速 AI 的进步,data2vec 让我们更接近于制造能够无缝地了解周围世界不同方面的机器。data2vec 使研究者能够开发出适应性更强的 AI,Meta AI 相信其能够在多种任务上超越已有系统。
data2vec 训练方式是通过在给定输入的部分视图的情况下预测完整输入模型表示(如下动图所示):首先 data2vec 对训练样本的掩码版本(学生模型)进行编码,然后通过使用相同模型参数化为模型权重的指数移动平均值(教师模型)对输入样本的未掩码版本进行编码来构建训练目标表示。目标表示对训练样本中的所有信息进行编码,学习任务是让学生在给定输入部分视图的情况下预测这些表示。
![]()
Meta AI 使用标准的 Transformer 架构(Vaswani 等人,2017):对于计算机视觉,Meta AI 使用 ViT 策略将图像编码为一系列 patch,每个 patch 跨越 16x16 像素,然后输入到线性变换(Dosovitskiy 等人, 2020;Bao 等人,2021)。语音数据使用多层 1-D 卷积神经网络进行编码,该网络将 16 kHz 波形映射到 50 Hz 表示(Baevski 等人,2020b)。对文本进行预处理以获得子词(sub-word)单元(Sennrich 等人,2016;Devlin 等人,2019),然后通过学习的嵌入向量将其嵌入到分布空间中。
推荐:
首个多模态高性能自监督算法,语音、图像文本全部 SOTA。
论文 2:Explaining in Style: Training a GAN to explain a classifier in StyleSpace
摘要:
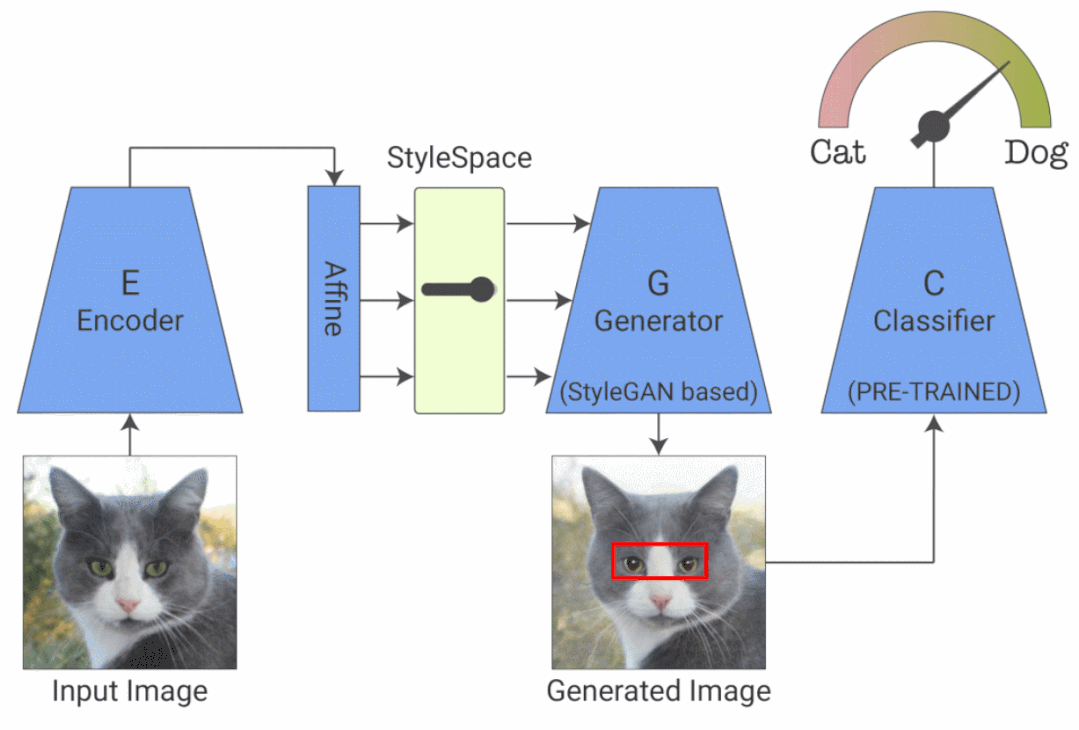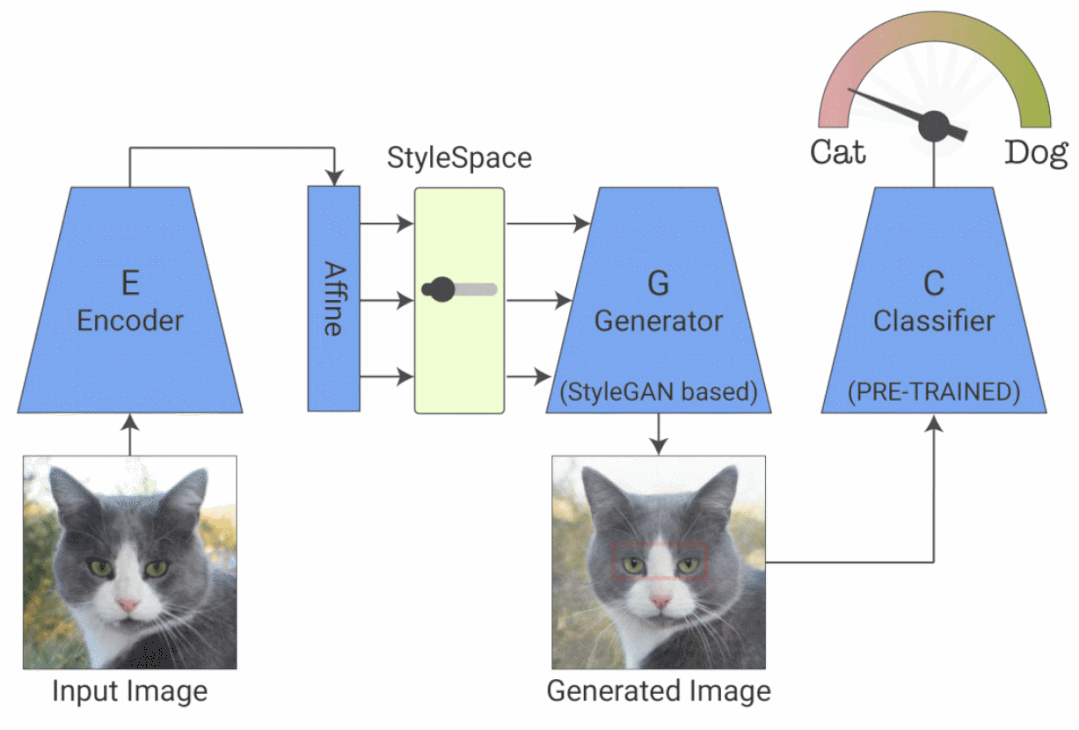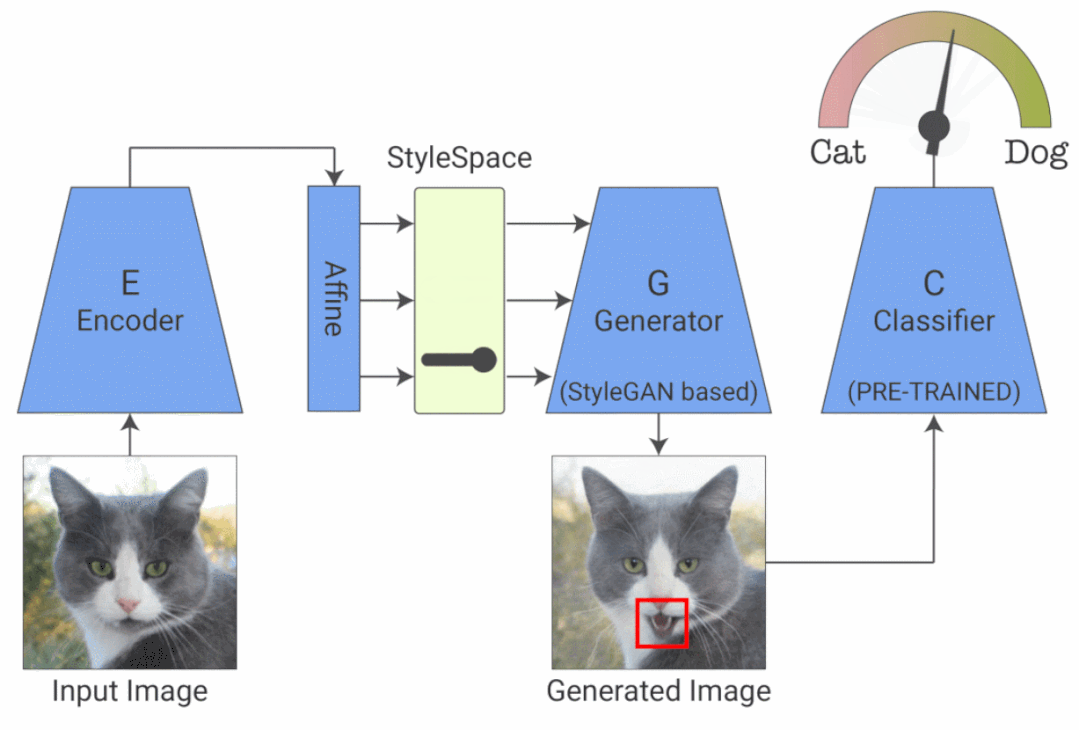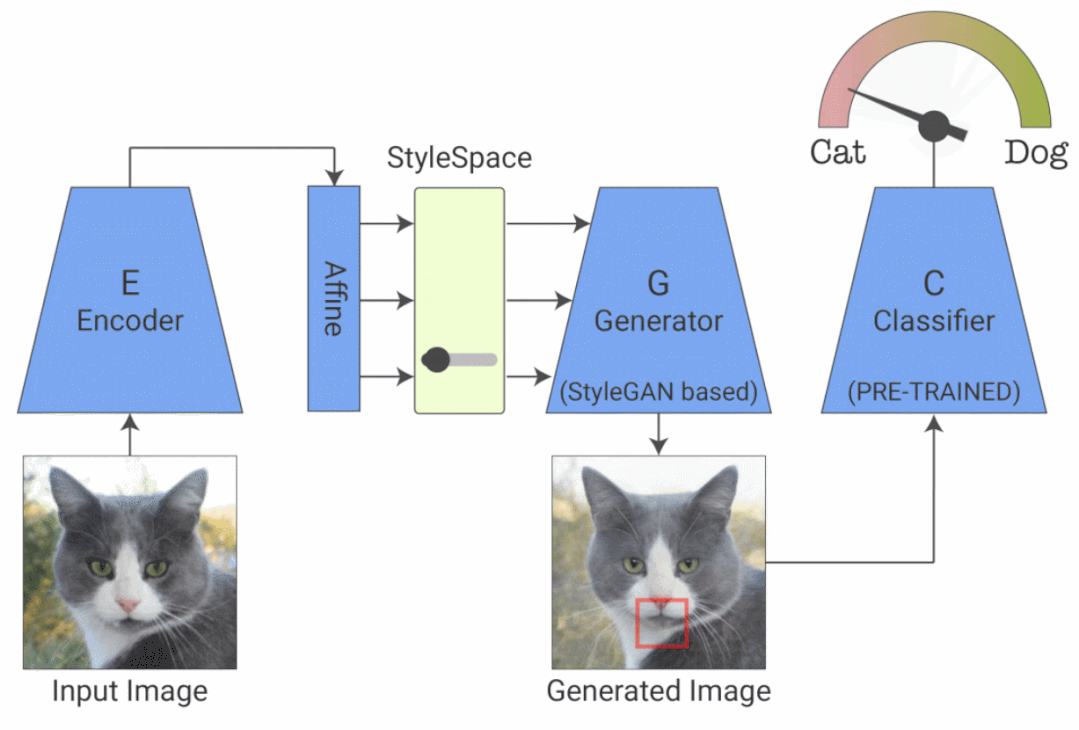
来自谷歌、 希伯来大学、 MIT 等机构的研究者提出了一种新的分类器可视化解释方法,相关论文被 ICCV 2021 接收。他们提出了 StylEx ,可以自动发现和可视化影响分类器的解耦属性(disentangled attributes)。StylEx 允许通过单独操作这些属性来探索单个属性的影响(也就是说,更改一个属性不会影响其他属性)。StylEx 适用于广泛的领域,包括动物、树叶、面部和视网膜图像。该研究结果表明,StylEx 找到的属性与语义属性非常吻合,可以生成有意义的特定于图像的解释,并且在用户研究中可以被人们所解释。
![]()
给定一个分类器和一个输入图像,该研究希望找到并可视化影响其分类的各个属性。研究人员采用了可以生成高质量图像的 StyleGAN2 架构,整个过程包括两个阶段:
第一阶段训练 StylEx:StylEx 通过使用两个附加组件训练 StyleGAN 生成器来实现。第一个是编码器,它与具有 reconstruction-loss 的 GAN 一起训练,并强制生成的输出图像在视觉上与输入相似,从而允许生成器应用于任何给定的输入图像。然而,仅仅只有图像的视觉相似性是不够的,因为它可能不一定捕获对特定分类器(例如医学病理学)重要的细微视觉细节。
![]()
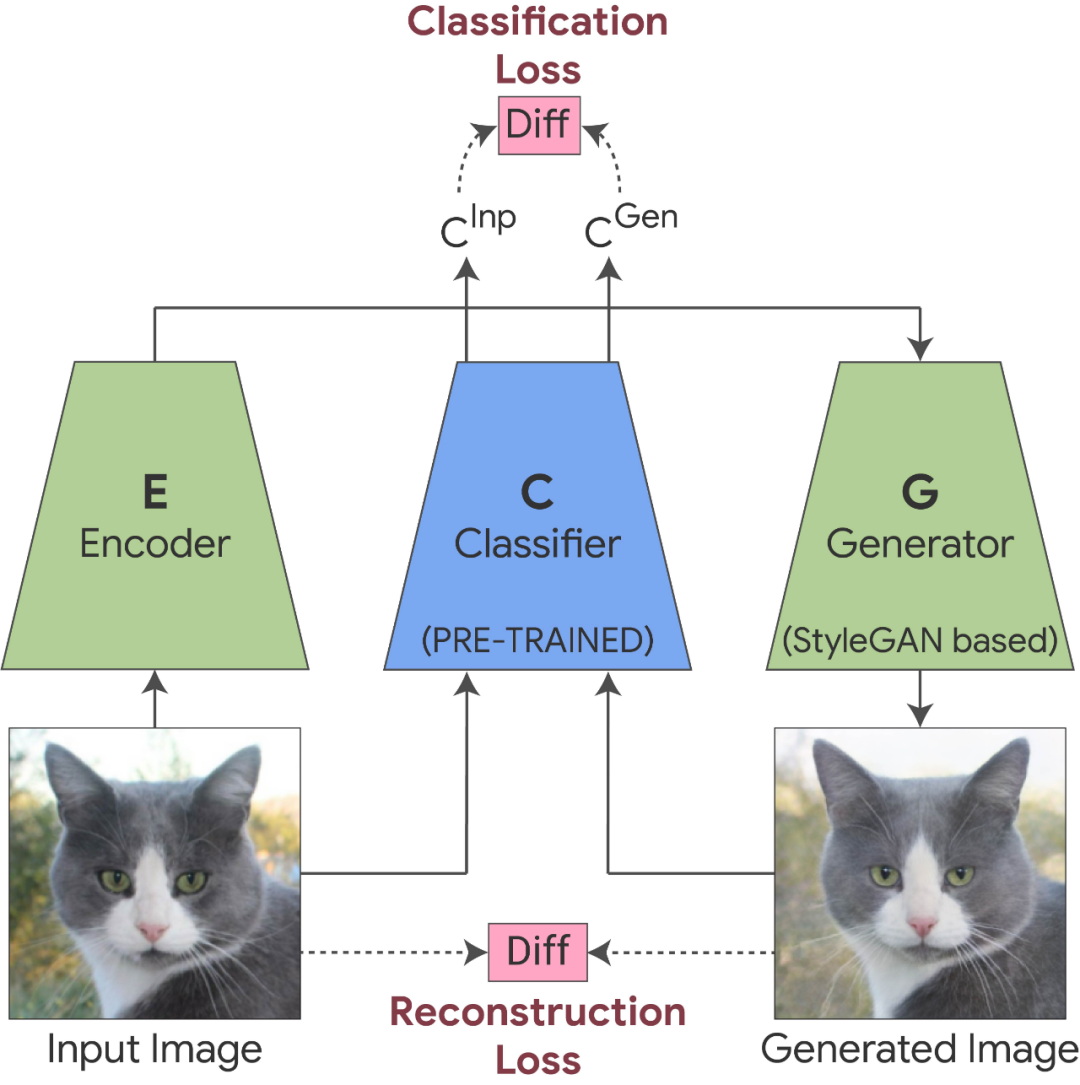
第二阶段提取解耦属性:训练完成之后,研究者在经过训练的分类器的 StyleSpace 中搜索显著影响分类器的属性,他们对每个 StyleSpace 进行操作并测量其对分类概率的影响。对于给定的图像,研究者寻找对图像分类影响最大的属性。这一过程可以找到 top-K 个特定图像属性。对每个类的图像重复这个过程,可以进一步发现特定类的 top-K 属性,这个端到端的系统被命名为 StylEx。
![]()
推荐:
谷歌、MIT 等提出分类器可视化解释方法 StylEx。
论文 3:Automated Reinforcement Learning (AutoRL): A Survey and Open Problems
摘要:
强化学习 (RL) 与深度学习的结合带来了一系列令人印象深刻的成果,许多人认为(深度)强化学习提供了通向通用智能体的途径。然而,RL 智能体的成功通常对训练过程中的设计选择高度敏感,可能需要繁琐且容易出错的手动调整。这使得将 RL 用于新问题具有挑战性,同时也限制了 RL 的全部潜力。
在机器学习的许多其他领域,AutoML 已经表明可以自动化此类设计选择,并且在应用于 RL 时也产生了有希望的初步结果。然而,自动强化学习 (AutoRL) 不仅涉及 AutoML 的标准应用,还包括 RL 独有的额外挑战,这使得研究者自然而然地产生了一些不同的方法。
AutoRL 已成为 RL 研究的一个重要领域,为从 RNA 设计到围棋等游戏的各种应用提供了希望。由于 RL 中考虑的方法和环境具有多样性,因此许多研究都是在不同的子领域进行的。来自牛津大学、弗莱堡大学、谷歌研究院等机构的十余位研究者撰文试图统一 AutoRL 领域,并提供了通用分类法,该研究详细讨论了每个领域并提出未来研究人员可能感兴趣的问题。
![]()
如下表 3 所示,该研究按照大类总结了 AutoRL 方法的分类,方法分类将体现在第四章的每一小节:
![]()
推荐:
牛津大学、谷歌等十余位学者撰文综述 AutoRL。
论文 4:An Introduction to Autoencoders
摘要:
TOELT LLC 联合创始人兼首席 AI 科学家 Umberto Michelucci 对自编码器进行了全面、深入的介绍。
神经网络通常用于监督环境,这意味着对于每个训练观测值 x_i,都将有一个标签或期望值 y_i。在训练过程中,神经网络模型将学习输入数据和期望标签之间的关系。
现在,假设只有未标记的观测数据,这意味着只有由 i = 1,... ,M 的 M 观测数据组成的训练数据集 S_T。
![]()
1986 年,Rumelhart,Hinton 和 Williams 首次提出了自动编码器(Autoencoder),旨在是学习以尽可能低的误差重建输入观测值 x_i。
如果你很难想象这意味着什么,想象一下由图片组成的数据集。自编码器是一个让输出图像尽可能类似输入之一的算法。也许你会感到困惑,因为似乎没有理由这样做。为了更好地理解为什么自编码器是有用的,我们需要一个更加翔实 (虽然还没有明确) 的定义。
![]()
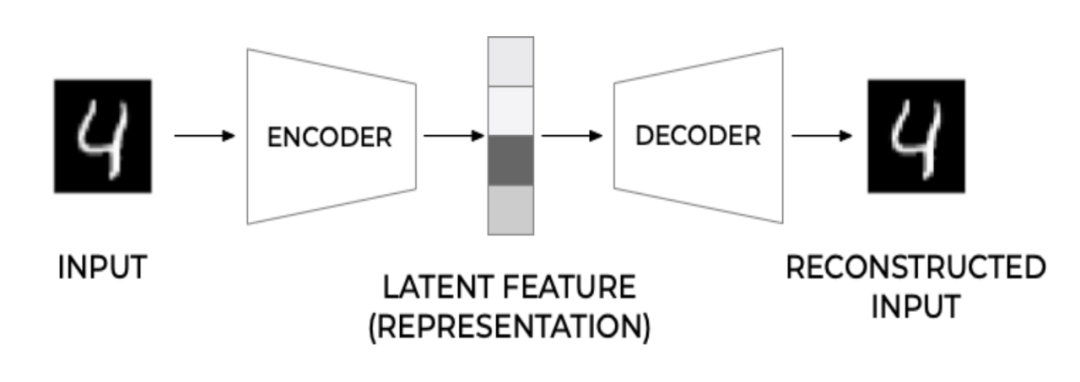
为了更好地理解自编码器,我们需要了解它的经典架构。如图 1 所示。自编码器的主要组成部分有三个:编码器、潜在特征表示和解码器。
![]()
推荐:
自编码器 26 页综述论文:概念、图解和应用。
论文 5:Vision Transformer with Deformable Attention
摘要:
清华大学、AWS AI 和北京智源人工智能研究院的研究者提出了一种新型可变形自注意力模块,其中以数据相关的方式选择自注意力中键值对的位置。这种灵活的方案使自注意力模块能够专注于相关区域并捕获更多信息特征。
可变形注意力 Transformer(Deformable Attention Transformer,DAT),是一种具有可变形注意力的通用主干网络模型,适用于图像分类和密集预测任务。该研究通过大量基准测试实验证明了该模型的性能提升。
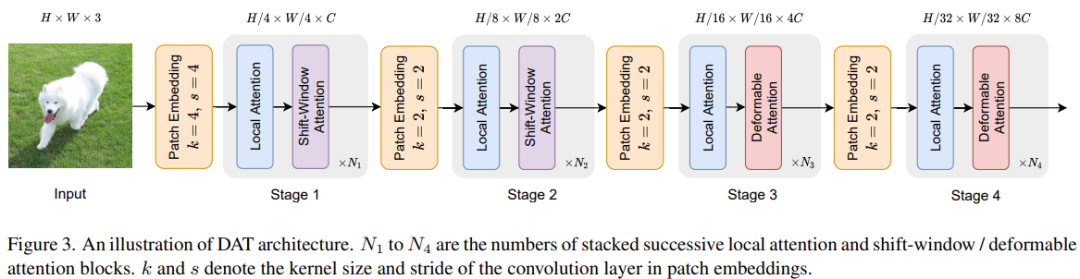
该研究在 Transformer(等式 (4))中的可变形注意力替换了 vanilla MHSA,并将其与 MLP(等式 (5))相结合,以构建一个可变形的视觉 transformer 块。在网络架构方面, DAT 与[7, 26, 31, 36] 共享类似的金字塔结构,广泛适用于需要多尺度特征图的各种视觉任务。如下图 3 所示,形状为 H × W × 3 的输入图像首先被步长为 4 的 4 × 4 非重叠卷积嵌入,然后一个归一化层获得
![]() 补丁嵌入。
补丁嵌入。
![]()
为了构建分层特征金字塔,主干包括 4 个阶段,步幅逐渐增加。在两个连续的阶段之间,有一个步长为 2 的非重叠 2×2 卷积,对特征图进行下采样,将空间大小减半并将特征维度加倍。
在分类任务中,该研究首先对最后阶段输出的特征图进行归一化,然后采用具有池化特征的线性分类器来预测对数;在对象检测、实例分割和语义分割任务中,DAT 在集成视觉模型中扮演主干的角色,以提取多尺度特征。该研究为每个阶段的特征添加一个归一化层,然后将它们输入到以下模块中,例如对象检测中的 FPN [23] 或语义分割中的解码器。
推荐:
清华可变形注意力 Transformer 模型优于多数 ViT。
论文 6:Pushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?
摘要:
尽管自监督方法最近在残差网络表示学习方面取得了进展,但它们在 ImageNet 分类基准上的表现仍然低于监督学习,这限制了它们在性能关键设置中的适用性。基于先前的理论见解(Mitrovic 等人,2021 年),DeepMind、牛津大学、图灵研究院联合推出了 RELICv2,它结合了明确的不变性损失和对比目标,该研究证明在 ImageNet 中使用相同网络架构进行同等条件下的对比,无标注训练数据集的效果可以超过有监督学习。
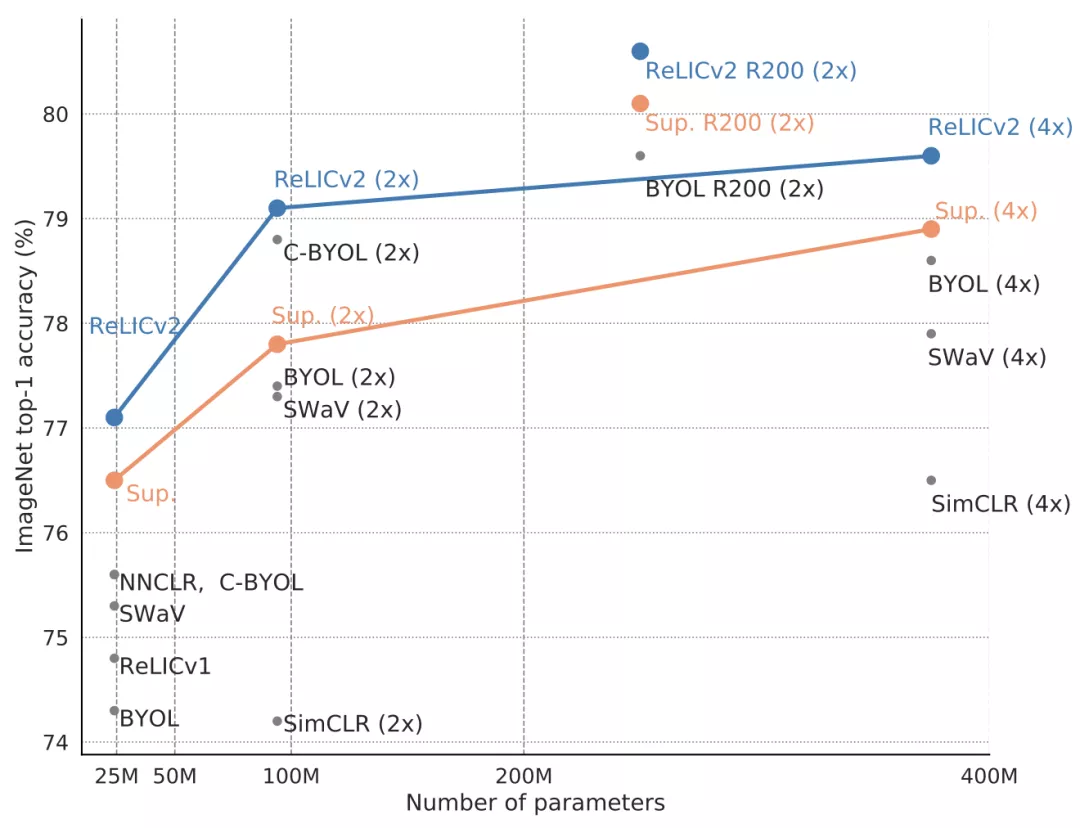
具体而言,RELICv2 使用 ResNet50 架构的线性评估在 ImageNet 上实现了 77.1% 的 top-1 分类准确率,使用更大的 ResNet 模型实现了 80.6% 的准确率,大大超过了 SOTA 自监督方法。
![]()
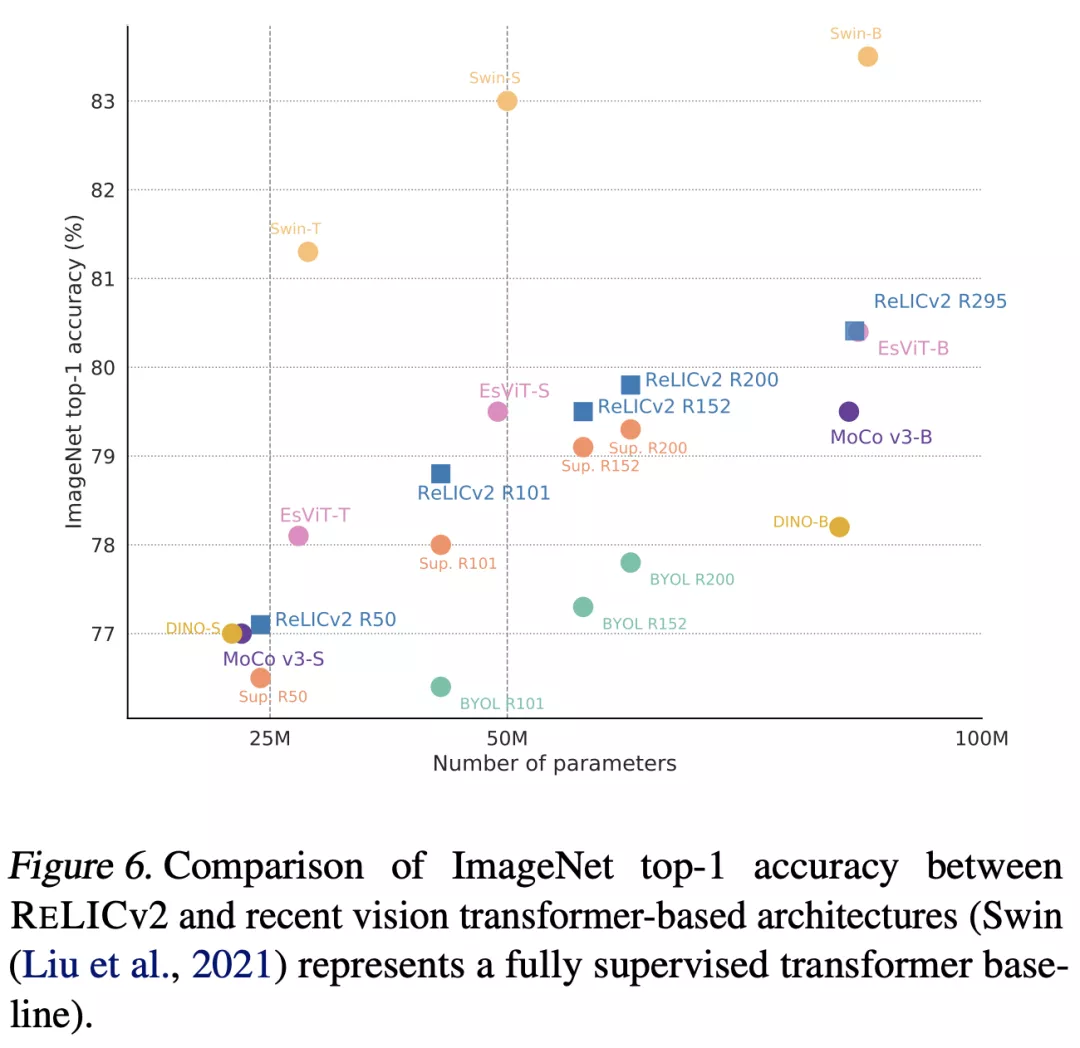
值得注意的是,RELICv2 是第一个使用一系列标准 ResNet 架构(ResNet101、ResNet152、ResNet200)在同类比较中始终优于监督基线的表示学习方法。最后,该研究表明,尽管使用了 ResNet 编码器,RELICv2 仍可与 SOTA 自监督视觉 transformer 相媲美。
![]()
推荐:
DeepMind 新作 RELICv2 。
论文 7:Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
摘要:
英伟达训练 NeRF,最快只需 5 秒(例如训练狐狸的 NeRF 模型)!实现的关键在于一种多分辨率哈希编码技术,英伟达在论文《 Instant Neural Graphics Primitives with a Multiresolution Hash Encoding》进行了详细解读。
英伟达在 4 个代表性任务中对多分辨率哈希编码技术进行验证,它们分别是神经辐射场(NeRF)、十亿(Gigapixel)像素图像近似、神经符号距离函数(SDF)和神经辐射缓存(NRC)。每个场景都使用了 tiny-cuda-nn 框架训练和渲染具有多分辨率哈希输入编码的 MLP。
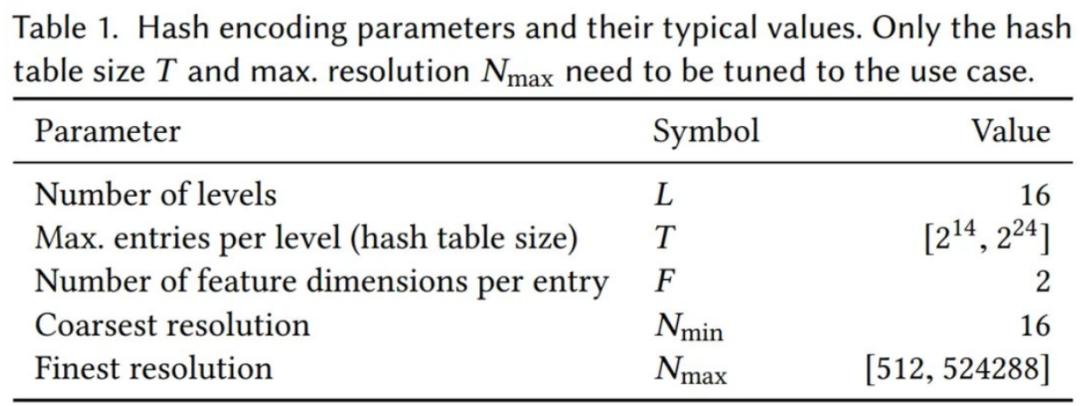
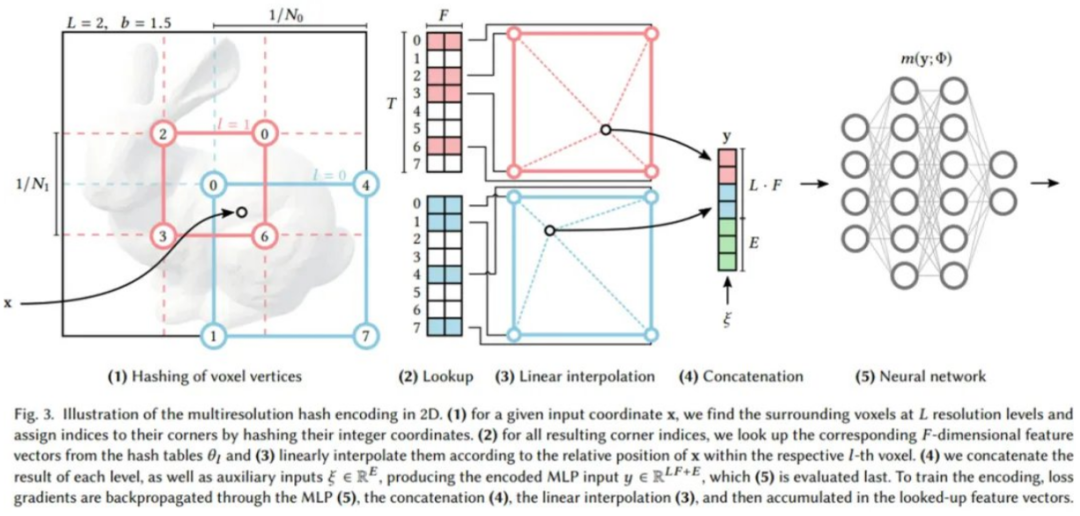
英伟达的神经网络不仅有可训练的权重参数 Φ,还有可训练的编码参数 θ。这些被排列成 L 个级别(level),每个级别包含多达 T 个 F 维 的特征向量。这些超参数的典型值如下表 1 所示:
![]()
多分辨率哈希编码的显著特征在于独立于任务的自适应性和高效性。首先来看自适应性。英伟达将一串网格映射到相应的固定大小的特征向量阵列。低分辨率下,网格点与阵列条目呈现 1:1 映射;高分辨率下,阵列被当作哈希表,并使用空间哈希函数进行索引,其中多个网格点为每个阵列条目提供别名。这类哈希碰撞导致碰撞训练梯度平均化,意味着与损失函数最相关的最大梯度将占据支配地位。因此,哈希表自动地优先考虑那些具有最重要精细尺度细节的稀疏区域。与以往工作不同的是,训练过程中数据结构在任何点都不需要结构更新。
然后是高效性。英伟达的哈希表查找是,不需要控制流。这可以很好地映射到现代 GPU 上,避免了执行分歧和树遍历中固有的指针雕镂(pointer-chasing)。所有分辨率下的哈希表都可以并行地查询。下图 3 展示了多分辨率哈希编码中的执行步骤:
![]()
如上图所示,每个级别(其中两个分别显示为红色和蓝色)都是独立的,并在概念上将特征向量存储在网格顶点处,其中最低和最高分辨率之间的几何级数 [N_min, N_max] 表示为:
![]()
推荐:
英伟达新技术训练 NeRF 模型最快只需 5 秒,单张 RTX 3090 实时渲染。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
本周 10 篇 NLP 精选论文是:
1. Improving Neural Machine Translation by Denoising Training. (from Dacheng Tao)
2. Memory-assisted prompt editing to improve GPT-3 after deployment. (from Yiming Yang)
3. COLD: A Benchmark for Chinese Offensive Language Detection. (from Minlie Huang)
4. Prompt Learning for Few-Shot Dialogue State Tracking. (from Tat-Seng Chua)
5. A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases. (from Salim Roukos)
6. LaMDA: Language Models for Dialog Applications. (from Zhifeng Chen, Adam Roberts)
7. WANLI: Worker and AI Collaboration for Natural Language Inference Dataset Creation. (from Noah A. Smith)
8. UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models. (from Dragomir Radev, Noah A. Smith)
9. A Survey of Pretrained Language Models Based Text Generation. (from Ji-Rong Wen)
10. Polarity and Subjectivity Detection with Multitask Learning and BERT Embedding. (from Erik Cambria)
本周 10 篇 CV 精选论文是:
1. MeMViT: Memory-Augmented Multiscale Vision Transformer for Efficient Long-Term Video Recognition. (from Jitendra Malik)
2. End-to-end Generative Pretraining for Multimodal Video Captioning. (from Cordelia Schmid)
3. Revisiting Weakly Supervised Pre-Training of Visual Perception Models. (from Ross Girshick, Piotr Dollár, Laurens van der Maaten)
4. ConDor: Self-Supervised Canonicalization of 3D Pose for Partial Shapes. (from Leonidas J. Guibas)
5. CLIP-TD: CLIP Targeted Distillation for Vision-Language Tasks. (from Shih-Fu Chang)
6. Semi-automatic 3D Object Keypoint Annotation and Detection for the Masses. (from Roland Siegwart)
7. What can we learn from misclassified ImageNet images?. (from Laurent Itti)
8. Learning Pixel Trajectories with Multiscale Contrastive Random Walks. (from Alexei A. Efros)
9. AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation. (from Michael J. Black)
10. Stitch it in Time: GAN-Based Facial Editing of Real Videos. (from Daniel Cohen-Or)
本周 9 篇 ML 精选论文是:
1. Dual Space Graph Contrastive Learning. (from Philip S. Yu)
2. Minimax Demographic Group Fairness in Federated Learning. (from Guillermo Sapiro)
3. The Enforcers: Consistent Sparse-Discrete Methods for Constraining Informative Emergent Communication. (from Katia Sycara)
4. Uncertainty Quantification in Scientific Machine Learning: Methods, Metrics, and Comparisons. (from George Em Karniadakis)
5. GradTail: Learning Long-Tailed Data Using Gradient-based Sample Weighting. (from Dragomir Anguelov)
6. IDEA: Interpretable Dynamic Ensemble Architecture for Time Series Prediction. (from Tong Zhang)
7. Training Free Graph Neural Networks for Graph Matching. (from Tat-Seng Chua)
8. Domain-shift adaptation via linear transformations. (from Russell Greiner)
9. Decoupling the Depth and Scope of Graph Neural Networks. (from Viktor Prasanna)
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



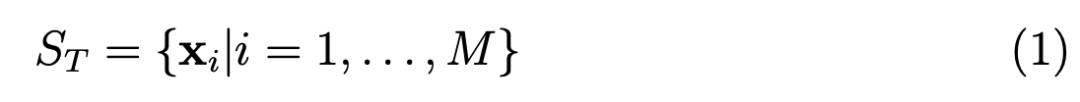

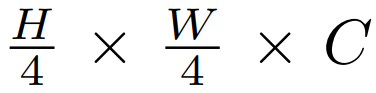 补丁嵌入。
补丁嵌入。