机器人学习最前沿:一眼模仿学习(One-Shot Imitation Learning)的三级跳
转自 https://zhuanlan.zhihu.com/p/33789604
Flood Sung
备注:本文过于偏学术分析,可能需要一定相关知识基础。
1 前言
几天前,也就是2月5号,UCB的Chelsea Finn又发了新文章:
这篇文章的发布,使得OpenAI及UCB(也就是Pieter Abbeel组)实现了机器人One Shot Imitation Learning的三级跳,达到了这个问题研究的新高度。
前两篇文章分别是:
可以说,最新Chelsea Finn这篇One-Shot Imitation Learning文章把机器人学习推到了更高的高度,进一步让我们看到了深度学习的无穷潜力。
那么,我们下面就来好好再分析一下这三篇paper,也让大家对One-Shot Imitation Learning有一个更清楚的了解。
2 什么是One-Shot Imitation Learning?
One-Shot Imitation Learning一眼模仿学习,可以说是机器人学习的一个比较终极的问题,最理想的情况就是我们人教机器人一个任务,我们稍微演示一下,机器人就能学会!一旦机器人具备这样的模仿学习能力,机器人就具备了非常强大的通用性,也非常类似我们人类的学习过程,可以说是机器人智能的一大进步。
但是这个问题一开始看起来是非常难的,机器人要如何才能理解人类的动作呢?不但理解人类的动作,还要理解动作的意图,然后还要能直接映射到机器人自身的机械控制输出上。而且,最最关键的是,我们还希望只用视觉输入,不对视觉做特定的人为处理。那么这就太难了,传统机器人控制理论可以说完全束手无策呀。
但是现在我们希望通过深度学习的方式来实现。即使这样,仍然是非常困难的。就如上一段所说的,要完成多种量的映射,怎么学是个很大的问题。
因此呢,Pieter Abbeel组还是采用非常循序渐进的方式来研究:
Step 1:我们让机器人自己给自己演示,也就是通过机器人本身采集输入输出样本,甚至我们的输入不使用视频,而是使用标记的数据,比如每一个方块的位置信息。这大概是最简单的实验方式了,先看看这样能不能work。
Step 2:在Step 1能work的情况下,我们再进一步增加难度,把输入变成视觉输入,看能做到怎样的效果。
Step 3:在Step 2能work的情况下,我们进入最初希望的One-Shot Imitation Learning设定,让机器人看的演示是人来演示,只有视频,没有对应机器人的控制输出。
显然他们这样的步步推进的研究方式是非常合理的,并且竟然仅用一年时间就取得了如此重要进展,一切都展现在他们这三篇paper上。
3 如何解决?Meta Learning是关键
在我们之前的很多blog中,已经为大家介绍了Meta Learning的相关知识。那么,非常直接的,One-Shot Imitation Learning问题本身就是一个Meta Learning的问题。要使One-Shot Imitation Learning能够成功,实际上就是要求神经网络能够通过one-shot demo去学习一种Meta Knowledge能够理解demo的意图并直接映射到控制输出。简单的讲,我们就希望学习这样一个神经网络f,满足:
其中,s是输入状态,a是输出动作,demo则是给出的演示信息,在step 1和2的研究中,demo包含了机器人对应的state和action。而在step 3的研究中,demo则仅仅包含人演示的state(视频帧),而没有action信息。
有了这样基本的认识,我们就可以一步一步的来看上面列举的三篇文章了。
4 One-Shot Imitation Learning
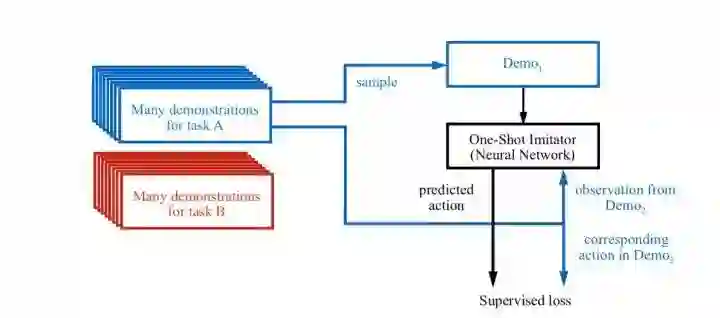
这篇文章作为One-Shot Imitation Learning的开山之作,用了最简单的方式,就是构造一个单一的神经网络,把demo数据都放进神经网络训练,即上一节提到的基本公式:
那么,怎么输入这些数据是个问题。一开始最基本的考虑就是使用LSTM,把demo数据作为sequence data输入。但是LSTM本身存在记忆信息损失的问题,并不能完整的保存整个demo的信息。因此,现在更流行的做法就是使用Temporal Convolution,一维卷积。因此,在本文的改进版中,就改用了TCNN,并且加了Attention机制:

不管网络结构如何,本质是没有变的。实际上这个处理办法也可以直接看成是一种conditional neural network。
小结一下:作为开山之作,这篇文章使用了最简单粗暴的做法,取得了一定效果。
5 One-Shot Visual Imitation Learning via Meta-Learning

那么在上一篇paper刚放出来的时候,他的实验里是仅使用方块位置信息作为state,并没有使用视觉输入。也因此,在Chelsea Finn的这篇文章中,她的文章名字里就加了一个visual,表示直接使用视觉信息。然后,直接指出使用Meta-Learning的做法。本质上上一篇文章的做法也是Meta-Learning了,只是当时还没有特定提起这个概念。
OK,那么这篇文章的做法是直接使用Chelsea Finn自己提出的MAML算法。
什么是 MAML?
MAML是一个面向监督学习和增强学习的Meta-Learning算法。对于监督学习,主要面向Few-Shot Learning少样本学习,这和One-Shot Imitation Learning的目的是一样的,因此将其直接应用到这上面非常自然。
MAML的基本思想非常简单,就是先用给予的样本比如这里的Demo对神经网络做一次反向传播更新,然后在已更新参数的基础上再做监督学习。也就是,MAML是要学习训练一个这样的函数f:
其中g使用当前参数和demo对参数进行更新。很自然的,g可以是一个梯度下降过程:
既然demo本身包含了(state,action),因此可以通过state输入到当前神经网络,得到预测action,从而与真实action比较得到loss。
采用MAML有一个非常直接的优点,就是保持了神经网络参数的不变性,虽然增加了demo的输入,但是网络参数保持不变。
通过MAML,本文做出的效果和上一篇比较略有提高。
6 One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
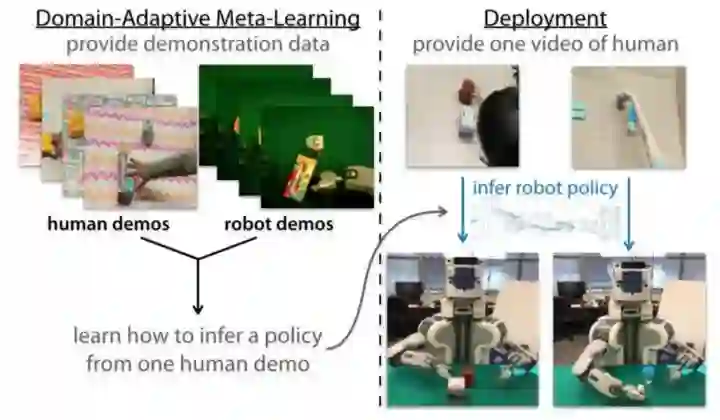
现在到最新这一篇paper的分析。这篇paper最关键的就是问题的设定变了,demo变成了人类演示,只有视频,没有动作信息。那么,问题来了,如果要用MAML来实现,怎么做?
如何通过Loss进行梯度下降更新网络参数呢?
但是没有action,只有state,哪来的Loss?
但本文跳出了这样的思维局限。由于我们是使用Meta-Train进行训练,因此,没有Loss,我们就构造一个Loss呗。
用一个神经网络来g表示Loss,我们也不知道Loss到底是什么,但是我们可以通过
来得到loss,这就够了,整个神经网络可以在Meta-Train中进行更新。
因此,有了这样的网络结构:
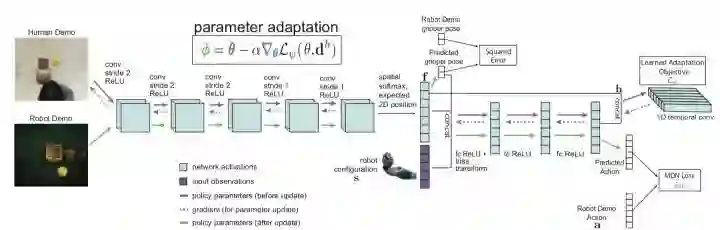
并且,作者采用Temporal Convolution来构造这个Loss Network:

小结一下:这篇文章巧妙的利用MAML算法对这个更难的One-Shot Imitation Learning进行处理,确实Work了,取得了让人意想不到的效果,可以说是眼前一亮!
7 总结
One-Shot Imitation Learning如此迅速的发展,Meta-Learning可以说功不可没。未来,非常显然的,需要进一步加大问题的复杂度,比如改成第三视角(Third Person One-Shot Imitation Learning),比如进一步增加task的复杂度,要更长的动作序列才能完成,再比如多任务同时Handle。我们可以想象,未来一两年,一种完全端到端,完全通过学习而得到的具备较强模仿学习能力的机器人将可以出现,这种机器人具备非常强的适应能力,可以在不同场景中保持工作能力。
智能机器人,正在一步步的走向它应该有的智能的样子!




