
题目: Learning by Cheating
摘要:
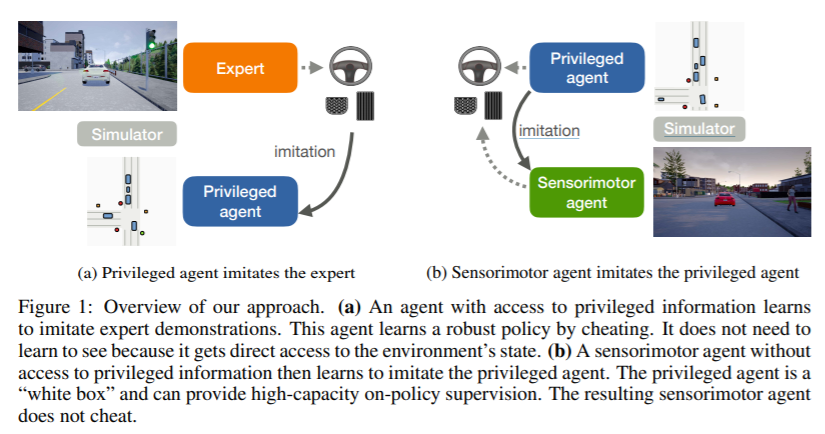
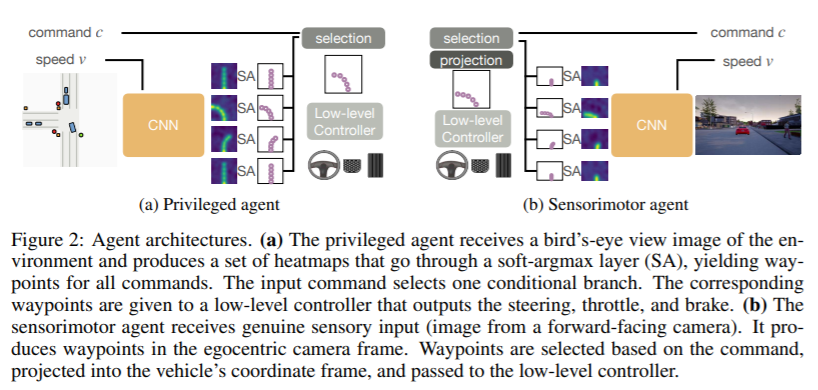
基于视觉的城市驾驶是困难的。自主系统需要学会感知世界并在其中行动。我们证明这个具有挑战性的学习问题可以通过把它分解成两个阶段来简化。我们首先训练一个可以访问特权信息的智能体。这个特权智能体通过观察环境的真实布局和所有交通参与者的位置来作弊。在第二阶段,有特权的智能体充当老师,训练一个纯粹基于视觉的感觉运动智能体。产生的感知运动智能体不能访问任何特权信息,也不会欺骗。这个两阶段的训练程序一开始是反直觉的,但是我们分析和实证证明了它有许多重要的优势。我们使用所提出的方法来训练一个基于视觉的自动驾驶系统,该系统在卡拉基准测试和最近的NoCrash基准测试上的表现远远超过现有水平。我们的方法首次实现了原始CARLA基准测试中所有任务的100%成功率,在NoCrash基准测试中创下了新记录,并将违规的频率与现有技术相比降低了一个数量级。
作者:
Dian Chen是得克萨斯大学奥斯汀分校CS专业的二年级博士生,之前在加州大学伯克利分校学习计算机科学和应用数学专业,在伯克利人工智能研究(BAIR)实验室担任研究助理。研究兴趣是机器人,计算机视觉和机器学习,包括强化学习。个人官网:http://www.cs.utexas.edu/~dchen/
成为VIP会员查看完整内容

相关内容

Arxiv
4+阅读 · 2018年1月29日
Arxiv
4+阅读 · 2017年10月26日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年1月29日
Arxiv
4+阅读 · 2017年10月26日