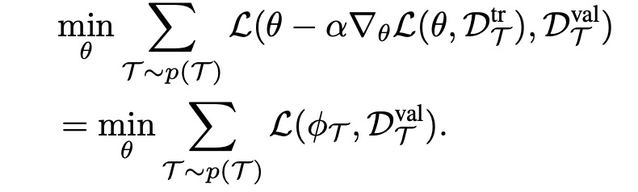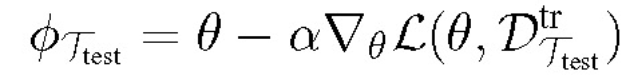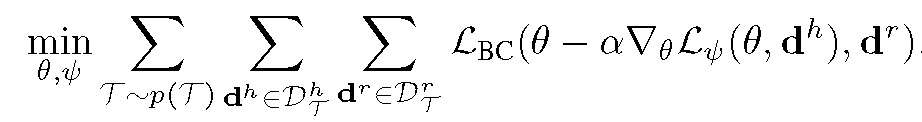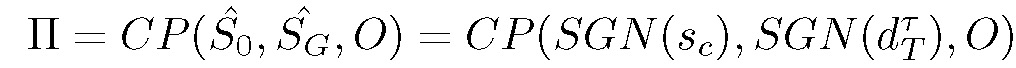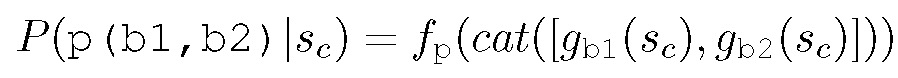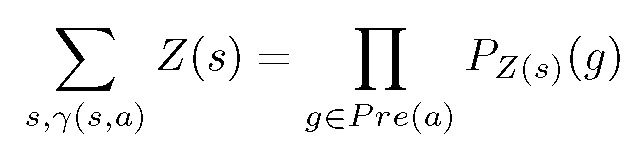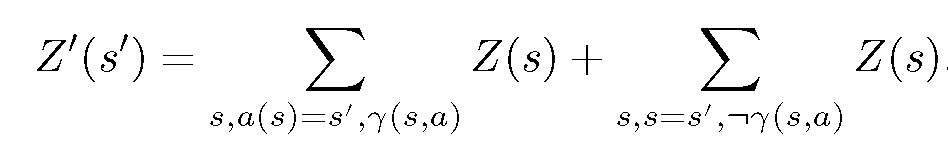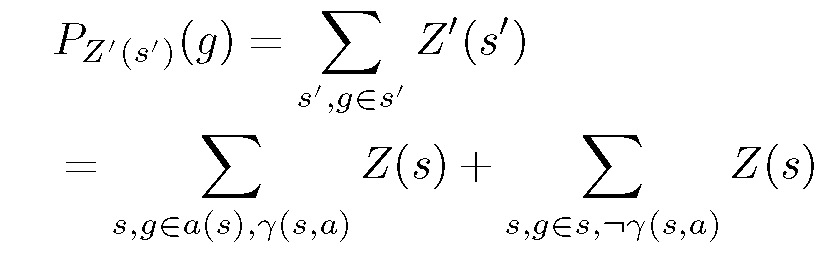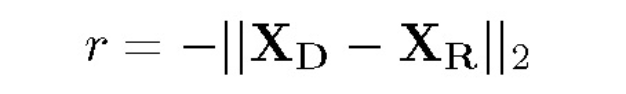本文是一篇关于机器人模仿学习的文章,通过综述这一领域的进展,读者可以了解最新的少样本模仿学习领域研究成果。
在机器人的动作学习,传统的方法基于任务训练强化学习(reinforcement learning)的策略,即针对每一个成功完成的任务的动作序列,训练得到一条策略。或者在该基础上,当奖励讯号稀疏出现时,利用各种技术完成各项模仿学习 (imitation learning)。但模仿学习的问题是,它的各种任务是独立的。例如,通过训练一个模仿学习算法(神经网络)能够得到一个关于如何将块堆叠到高度为 3 的塔中的策略。但当希望机器人完成将块堆叠到高度为 2 的塔中的动作时,则需要重新训练神经网络,从而得到另外一个策略。
单样本模仿学习(One-Shot Imitation Learning)最先是伯克利大学著名的 Pieter Abbeel 教授以及他的学生在 2017 年提出来的 [1]。是指通过一次演示(可能包含一个或多个任务),告诉机器人当前有哪些任务以及如何完成这项任务。此时,不再是基于特定任务的神经网络学习,而是一种「演示模仿」学习。从有监督学习的角度讨论,给定包含几个训练任务的演示,单样本模仿学习能够根据当前样本推广到未知但相关联的任务中,从而做到一眼就能模仿。至于如何制定「相关联」,就是各位研究者所要探讨的内容。
单样本模仿学习的经典方法是元学习(Meta-Learning)。在训练阶段,通过给定已知域中的一组任务及对应的动作完成模型学习;测试阶段,利用模型通过一段演示推广并具备完成未知任务的能力。基于元学习的单样本模仿学习方法存在的主要问题是需要大量的数据(演示视频)完成模型训练。最近,李飞飞组提出将单样本模仿学习定义为一个符号规划问题(Symbolic Planning),利用符号域定义的结构将策略执行与任务间的泛化处理分离开来,从而大大减少元学习方法在训练阶段所需的任务数量,提高了方法的效率。
元学习和符号规划问题的方法思路都是以第一人的角度观看并学习演示(视频),因此演示的情况直接影响方法的效果。Leo Pauly 等提出了观察学习(Observation Learning)的概念,即从第三人的角度观看演示,同时利用深度网络将演示视频片段转化为活动的抽象表示(活动特征)。基于活动特征的不可变性,该方法可以在不同的观察视角、对象属性、场景背景和机械手形态下,跟随演示中学习任务。
本文主要介绍了 3 篇有关 one-shot imitation learning 的代表作,分别针对元学习、符号规划问题和观察学习的单样本模仿学习进行分析:
-
Yu, Tianhe, et al. "One-shot hierarchical imitation learning of compound visuomotor tasks." arXiv preprint arXiv:1810.11043(2018). https://arxiv.org/pdf/1810.11043.pdf,基于元学习的单样本模仿学习。
-
De-An Huang, et al.「Continuous Relaxation of Symbolic Planner for One-Shot Imitation Learning.」arXiv preprint arXiv:1908.06769 (https://arxiv.org/abs/1908.06769) (2019). https://arxiv.org/pdf/1908.06769.pdf,利用符号规划问题的单样本模仿学习。
-
Leo Pauly, et al.「One-Shot Observation Learning Using Visual Activity Features .」arXiv:1810.07483(V2. 2019). https://arxiv.org/pdf/1810.07483.pdf,基于视觉活动特征的单样本观察学习。
One-shot hierarchical imitation learning of compound visuomotor tasks
本文是 Abbeel 和他的老搭档 Sergey Levine 教授利用他们学生 Finn 提出的 MAML 添了自己的坑。相比起 One-shot imitation learning 的开山之作的概念性模型 [1],这里实际中利用了视觉像素输入,解决了单样本模仿学习中处理多阶段复杂视觉任务的问题。即针对一条原始演示视频(没有经过任何预标记处理的执行整个任务的未剪辑原始视频),通过有效利用子任务的演示数据和其他对象信息等,完成模仿学习。本文使用元学习方法,同时为了解决原始视频中存在的未标记、多任务问题,本文提出的方法同时完成动作学习和动作合成两项任务。本文的主要贡献是提出了一种没有预标注的人类演示动态学习和组合策略序列的方法。由实验分析可知,这种方法可以用来动态地学习和排序用户在测试时提供的单个视频演示的技巧。
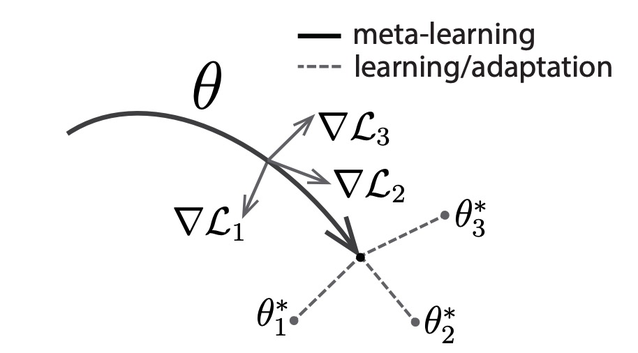
文章首先解决教会机器人通过模仿人类演示来学习原始动作技能的问题。本文使用领域自适应元学习(Domain-adaptive meta learning,DAML)方法从单个演示推断策略。DAML 是模型不可知元学习算法(Model-agnostic meta-learning algorithm,MAML)的扩展。Finn 中首次提出了 MAML 的概念 [2],其目标是通过二重循环 1. 分别学习不同任务的深度网络的参数 ($\theta_1,\theta_2,\theta_3$),2. 找到不同任务间的共同次优解($\theta$),从而通过一步或几步梯度下降实现有效的泛化处理。图 1 中给出 MAML 原理示意图,找到这样的模型参数,对于任一任务产生的参数微小变化,能够使得损失函数具有很大的改进,因此通过优化表示$\theta$,能够快速完成新任务的适应性学习。
Fig. 1. Diagram of MAML, which optimizes for a representation θ that can quickly adapt to new tasks.
首先介绍 MAML 在机器人视觉演示这个任务里的目标函数。令θ表示初始模型参数,L(θ,D) 表示有监督学习的损失函数,D_t 表示任务 t 的标记数据。在元训练阶段,MAML 选定任务 T 并抽取数据 D_T,将 D_T 随机分为两组(tr, val),MAML 对模型参数θ进行优化,目标函数为:
将内部损失定义为适应目标,外部损失定义为元目标。在测试阶段,MAML 使用从 T_test 中提取的 K 个示例运行关于θ的梯度下降:
基于 MAML,这篇文章中设计的 DAML 直接学习演示视频。与有监督元学习问题不同,人类演示视频的学习是一种弱监督的形式——它包含足够的信息来传达任务,但不包含直接的已标注数据。为了让机器能够学习人类视频,同时解决人类和机器人动作之间存在的域移动,在 MAML 目标函数的基础上,DAML 的学习过程包含了自适应目标 L_Ψ,以及元目标 L_BC(表示为均方误差行为克隆损失)。给定初始参数θ,DAML 的元学习目标函数定义为:
其中 d^h 和 d^r 分别表示人类和机器人的演示。在目标函数的学习过程中,利用参数θ和人类演示 d^h,在与机器人演示动作 d^r 比较的基础上,训练和调整整个网络,更新参数θ。
在元学习的训练阶段,对于具有特定对象集的每个子任务 P_k,提供多组人类演示 {(d_i).^h}_k 以及多组机器人演示 {(d_j).^r}_k。将人类 (d_k)^h 执行的演示定义为人类执行 P_k 的图像序列,将机器人演示 (d_k)^r 定义为机器人执行相同动作基元的图像和动作序列。其中人类和机器人的演示可能具有不同的时间范围,因此需要将人类和机器人的演示基于所使用的对象和执行的原始对象进行对应,但不需要以任何方式对齐,例如执行速度、对象位置等。
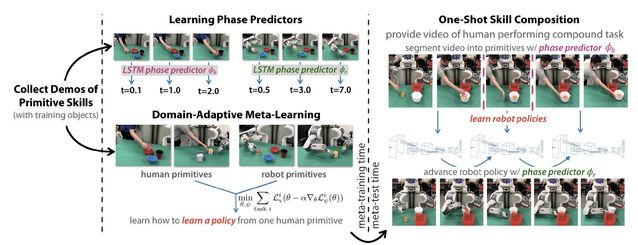
在本文的方法中,不但需要基于复杂任务序列完成机器人子任务学习,同时还希望机器人能够学习到如何区分和组合学习到的基元,从而具有完成多阶段组合任务的能力。因此,本文训练两个模型,分别识别任何人类或机器人基元的时间进程或阶段,这两个模型可用于分割人类演示和终止机器人正在执行的基元从而转移到下一个子任务。该方法的完整过程见图 2。
Fig. 2. After learning a phase predictor and meta-learning with human and robot demonstration primitives, the robot temporally segments a human demonstration (just a video) of individual primitives and learns to perform each segmented primitive sequentially.
在元学习的测试阶段,提供给机器人的是一段人类完成多阶段任务的视频。测试阶段的完整算法如下:
至此,本文所提出的解决复杂学习任务的元学习方法介绍完毕。
本文的机器人动作实验设置包括拾取和放置、推和接触,本文提出的方法能够以多种方式组合这些动作基元,从而完成不同的复合任务。本文将所提出的方法与一些简化处理后的方法进行实验对比,从而证明阶段预测和 DAML 的重要性。为了验证阶段预测的作用,本文将其与使用阶段预测的简单替代方法进行了比较:对人类演示视频进行固定长度的片段化处理,基于这些片段学习策略,并在每个时间步长内升级策略。这种「滑动窗口」方法仍然利用单样本模拟,但作出了两个简化假设:(a)固定长度窗口是针对动作基元的适当表示,(b)人类演示时间和机器人执行相同任务的时间相等。为了验证使用 DAML 的作用,本文将其与使用基于 LSTM 的元学习方法进行了比较。
1. 模拟订单执行:机器人须学会挑选并将一组特定的新对象放入一个箱子,并将箱子推到指定的位置。
本文基于 MuJoCo 物理引擎中的 Sawyer 机械臂对一系列模拟订单执行任务的方法进行评估,使用一个对象和两个对象订单完成任务来评估每个方法。实验结果见图 3。
Fig. 3. Qualitative results of the experiments on the physical PR2 (top) and simulated Sawyer (bottom).
结果如表 1 所示,基于梯度的元学习和阶段预测都改进了方法的效果。作者指出,几乎所有的失败案例都是由单样本模仿学习者引起的,主要与抓取有关,这说明本文提出的方法在解决视觉对象精确定位和精确控制的要求方面还存在一些问题。
![]()
TABLE I . One-shot success rate of simulated Sawyer robot performing order fulfillment from a single demonstration with comparisons
2.
PR2 厨房服务:PR2 须抓住一个物体,将其放入正确的碗或盘子中,并将其中一个盘子或碗推到机器人的左侧。
在本节实验中,使用了 10 个碗和其它容器,包含 5 个「服务」项目。对于每个任务,收集一个人类演示并评估两个机器人任务执行的效果,具体见图 2。实验结论见表 2。PR2 厨房服务是一项具有挑战性的任务,机器人需要完成一系列的控制基元,在模拟过程中的任何微小的位移都可能导致失败。因此,使用本文方法将物体放入目标容器中并推送相应的控制基元时,只能成功地完成 20 次实验中的 10 次。而在没有放置物品的情况下推另一个容器时,20 次实验中有 7 次成功。而使用简单的「滑动窗口」方法则一次都没有成功。与之前一样,在本组实验中本文提出的方法大多数失败案例都是由于单样本模拟学习未能在分段视频中执行动作基元,这说明改进从人类视频中进行单样本模拟的过程将能够进一步提高性能。
![]()
TABLE II . Success rate of PR2 robot performing pick & place then push task from a video of a human. Evaluated using novel, unseen objects.
在后续工作中,为了进一步改进复杂任务中的单样本模仿学习性能、解决处理复杂任务时的复合性错误,可引入强化学习或其他形式的在线反馈方法。另外,可以考虑处理更复杂的非结构化演示数据,例如临时扩展的不同来源的人类和机器人演示。传统的工作主要聚焦于将复合任务演示切割为动作基元,而非结构化演示数据的学习则还需要进一步处理人类和机器人完成任务的动作之间的大致一致性。最后,进一步可将本文提出的方法应用于大型未标记数据集中,这样将不再需要专家在训练过程中标注构成动作基元的技能集。
Continuous Relaxation of Symbolic Planner for one-shot Imitation Learning
基于元学习的单样本模仿学习在机器人学习领域获得了很好的效果,然而该方法需要几百个元训练任务,这就限制了方法的可扩展性。本文将单样本模仿学习定义为一个符号规划问题(symbolic planning problem),本文的主要贡献是:
将单样本模仿学习定义为规划问题,有效将策略执行与任务间的泛化处理分开;
提出连续规划方法,允许直接处理符号状态分布,解决无效状态问题;
将模块化思想引入符号接地 (grounding) 神经网络,进一步提高任务间的泛化能力。
上一篇文章中, 单样本模仿学习的过程是给定一个任务的演示,目标模型能够输出指导完成任务实例的策略。模仿学习的建模过程要同时实现演示理解和任务执行,因此对于数据效率具有很大挑战。
而第二篇介绍的文章, 用了另外的思路, 将单样本模仿学习定义为一个经典的符号规划问题。规划问题 (So,Sg,O) 包含初始状态 So、目标 Sg 和一组运算符 O={o}。每个运算符由以下项定义:O=(name(o),precondition(o),effect(o)),其中 name(o) 包括运算符名称和参数列表,precondition(o) 指定应用运算符需要满足的条件,effect(o) 定义运算后如何更新状态。状态 State 定义为所有真实的 ground atom 的集合(例如,{On(A,B),Clear(A)})。本文使用规划域定义语言(Planning Domain Definition Language,PDDL)来解决规划问题。在 PDDL 中,规划问题被分为一个域文件和一个问题文件。其中,域文件包含 O={g} 运算符集和谓词集,问题文件包含初始状态 So 和目标状态 Sg。
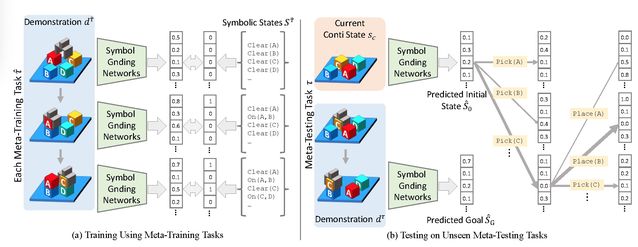
本文将复合任务的建模分解为符号接地网络学习(Symbol Grounding Networks,SGN)和连续规划执行(Continuous Planning,CP)。其中 SGN 完成任务间的泛化处理,CP 执行策略。这样的分离大大降低了将任务推导至不可见任务的复杂性。方法的训练和测试过程见图 1。
Fig. 1. Overview of the training and testing of our framework
利用规划问题解决单样本模仿学习的过程可简述为:将演示映射到一个符号目标 Sg,将当前观察到的连续状态 Sc 映射到相应的符号状态 So,则可以使用规划来解决基于域文件中定义的运算符 O 的任务。So 和 Sg 都可以通过解决将连续状态 s 映射到相应符号状态 s 的符号接地问题来求解。以 Sg 为例,给定一项任务,通过符号接地 (grounding) 将一段演示表示为 d = [ d_1 ,... , d_T ],其中最终状态 d_T 能够满足任务要求。使用 SGN 解决符号接地问题,通过预测当前和目标的符号状态,能够得到下式:
2. 符号接地网络(Symbol Grounding Networks,SGN)
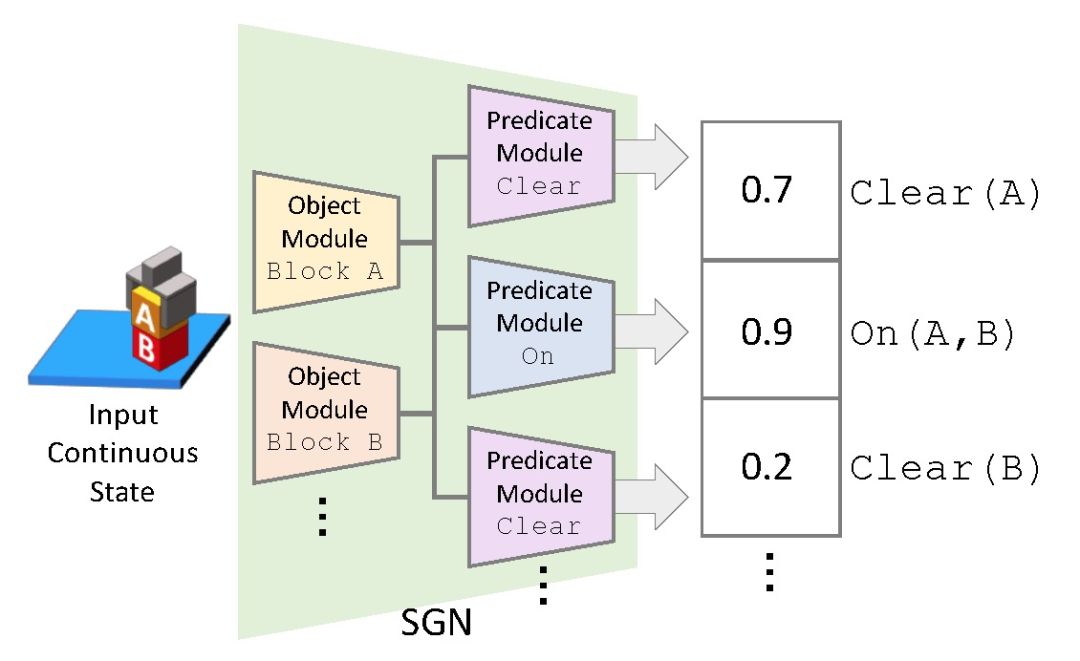
本文利用模块化神经网络结构来泛化学习任务和动作(谓语)的表示,从而完成对应任务的元学习(Meta-Learning)。给定一个未知任务的演示,SGN 能够识别对应的目标 Sg,同时能够将当前的连续状态 Sc 从任何任务映射到相应的符号状态, 完成符号接地。由于实现了在相似域内共享符号接地,与传统的复合问题相比,SGN 更易优化。
对于每个谓词 p,给定一个谓词模块 f_p,对于每个对象 b,给定一个对象模块 g_b。通过多层感知器参数化处理后,ground atom p(b1,b2) 的分类如下:
其中对象模块 g_b 从当前连续状态 Sc 中提取嵌入值,使用 cat 函数连接全部目标模块的嵌入值后输入预测模块 f_p 中。这一操作使我们可以共享域中每个 ground atom 的符号接地参数,从而提高 SGN 的数据效率。图 2 给出 SGN 处理 2 个 ground atom 的示例。Clear(A) 和 Clear(B) 共享同一谓词模块 f_clear。两个 ground atom 与 On(a,b) 共享所有目标模块。
Fig. 2. Example of three ground atoms with our modular Symbol Grounding Networks (SGN)
由于符号规划器的输入为离散的符号状态,因此其输出为离散化的概率输出。在单样本模仿学习问题中,离散化的输出不能确保合理化的符号状态。本文通过引入符号规划的持续性松弛来解决这一问题,允许持续性松弛的结果作为规划等式的概率输出。本文使用概率符号代替确定性规划中的集合论表示,从而使得 CP 输出一个基于 SGN 输出的操作列表。与经典符号规划问题类似,本文的 CP 也包含 5 个过程:
为了解决 SGN 输出的不确定性,本文采用概率符号状态进行表示,当 SGN 输出如下概率
这些概率值可以被看作是在所有 8 个可能的符号状态上指定一个分布,本文使用这个概率分布而不是一组 ground atom 作为 CP 的状态表示,从而实现了利用连续值进行符号规划。使用 Z(s) 表示符号状态的分布,它将符号状态 s 映射到相应的概率。假设已知所有 ground atom 的集合,并且 atom 之间是条件独立性分布的,使用 P_z(s)(g)表示 Z(s),P_z(s)(g)为给定所有 g 的分布 Z(s) 后 ground atom g 为真的概率。
其中 r(s,a) 表示 s 满足 a 的前置条件集 Pre(a)。由于满足条件独立分布,该求和可用前置条件集中 ground atom 的概率表示。
在连续条件下,对操作的选择问题改为对操作适用性的排序问题。
本文使用行动的尝试(attempt)来描述状态分布的改变。给定当前状态的分布,当尝试执行一个操作时分布会发生改变。同时,也有可能因为不满足先决条件而导致行动失败。执行动作 a 则状态 Z(s) 改变为 Z'(s'):
其中第一项表征尝试成功的转换,第二项表征操作失败。根据这一定义,新分布 Z'(s') 中特定 ground atom 的概率为:
由于连续状态下当前的状态和目标都不再由符号来表征,目标满足条件不再由符号状态中 ground atom 的存在来定义,相对应的,我们具有符号状态的当前分布以及目标状态的分布。因此,当前情况下的搜索目标是匹配这两个分布。
本文提出的 CP 是符号规划的连续性松弛,因此不需要训练。我们仅需要对 SGN 进行反向传播的训练,具体过程见算法 1。
总体来说,本文模型可以作为一个以 d^T 为条件的闭环策略,具体见算法 2。
由于预测值 S^g 和 S^o 只是状态上的分布,因此执行算法 2 的处理后模型可能无法达到目标。在这种情况下,我们更新初始符号状态 S^o=SGN(Sc) 并重新规划。
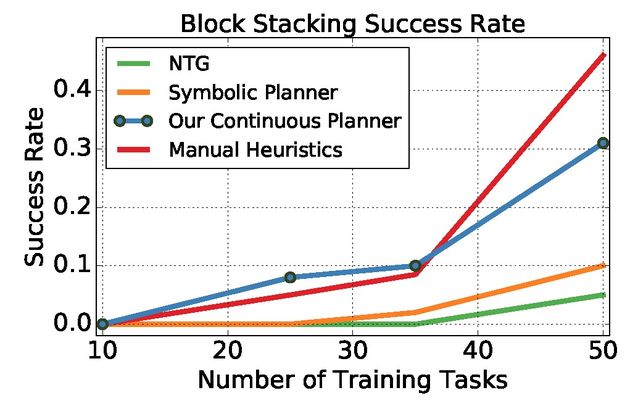
作者把该算法与下列算法对比:神经任务图网络(Neural Task Graph Networks,NTG)、符号规划+离散 SGN(Symbolic Planner)、SP+手工启发法*(Manul Heuristics)
该任务目标是将 8 个方块集合堆放到目标配置中。方块大小为 5 厘米见方,演示的最终块配置作为目标状态。实验结果见图 3。由图 3 可知,集中基于规划的方法都优于 NTG 策略网络。更重要的是,本文提出的方法通过操作状态上的分布,显著优于基线方法,这也体现了本文采用的连续松弛处理的优势。
Fig. 3. Block Stacking Results
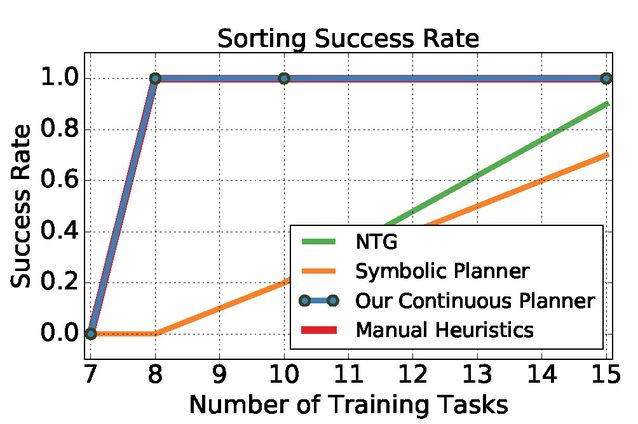
对象排序任务的目标是将散布在桌面上的对象移动到演示中显示的相应容器中。实验结果见图 4。图 4 中实验的主要难点是模型需要提出不同于演示的替代解决方案。本文提出的方法能够有效找到任务的替代解决方案,在仅有 8 个训练任务的情况下能够快速学习在不可见的配置上完成任务。
Fig. 4. Object Sorting Results
不同于传统的基于元学习的单样本模仿学习,本文提出了一种连续松弛的符号规划方法,在模拟实验条件下该方法效果优于最先进的单样本模仿学习,为机器人模仿学习提供了一个新的研究思路。然而值得注意的是,本文给出的实验结果是在模拟器中运作的,其中堆箱子任务中 block 的颜色非常容易辨认,本文提出的基于感知器的 SGN 在这种条件下非常容易进行泛化,从而保证了符号规划方法的有效性。在实际应用场景中符号规划问题的适用性还有待进一步研究和论证。
One-Shot Observation Learning Using Visual Activity Features
![]()
基于元学习的单样本利用神经网络通过 one-shot demo 去学习一种元知识从而理解 demo 的意图并直接映射到控制输出,这种方法是从第一人称的角度出发「模仿」学习。本文提出了一种应用于机器人操作任务的仅需一次演示的单样本观察学习方法(One-shot observation learning),该方法的核心思想是从第三人的角度观看演示,将演示编码到一个活动空间中作为活动分类器的一部分。给定一个奖励函数,用于测量展示编码与执行相同任务的机器人实验等效编码之间的距离,通过迭代学习完成机器人机械手任务。本文将强化学习用于模拟机械手的实验中,将随机轨迹优化用于实际机械手的实验。实验结果表明,该方法可以在不同的观察视角、对象属性、场景背景和机械手形态下,从单个演示中成功学习任务。
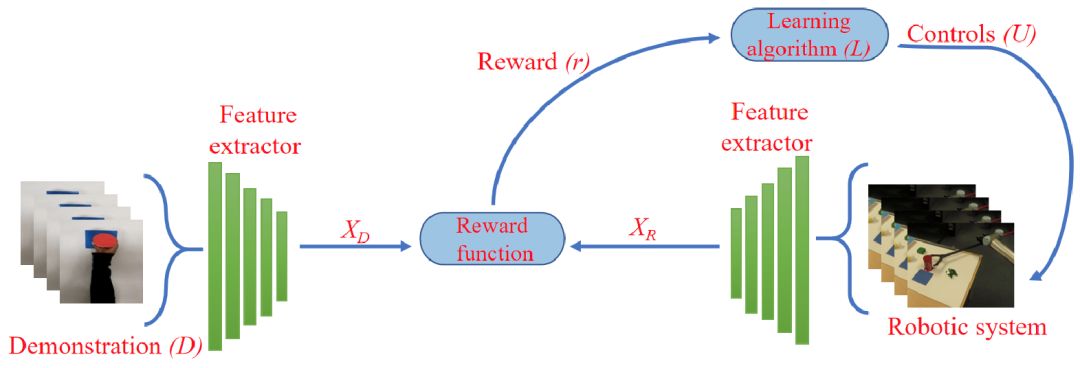
图 1 给出本文提出的观察学习方法。第一,使用基于 3D-CNN 的特征提取器分别从演示和机器人动作中提取活动特征 X_D 和 X_R。第二,使用奖励函数比较活动特征空间中的 X_D 和 X_R,根据它们的相似度生成奖励信号。第三,学习算法控制机器人的动作,最大化奖励信号从而使机器人学会完成演示动作。
Fig. 1: Proposed one-shot observation learning method.
这篇文章介绍的两个步骤是:首先,使用深度学习算法基于活动特征创建活动特征空间,将演示任务和机器人动作映射到该空间中。第二,学习机器人系统的控制,以便它执行演示的动作。学习算法基于演示的特征表示与活动特征空间中的机器人动作之间的距离完成。给定活动特征空间 A,D 为任务的演示视频(共 t 帧)。X_D 表示从演示视频 D 中提取的 n 维活动特征,X_R 为从机器人动作视频中提取的 n 维环境不变活动特征。使用强化学习算法 L 学习 U,U 表示机器人系统的扭矩、关节位置或速度的序列。奖励函数通过衡量特征空间中 X_D 和 X_R 的距离来计算。
使用活动分类器的卷积特征编码生成活动特征,使用一个大型活动数据集执行预训练,活动分类器对从一系列视角观察到的活动进行训练,参与者具有不同的体形、不同的视角、不同形态的操纵者、不同物理性质的对象以及不同的背景。预训练结束后,特征提取程序可从未训练的视频中提取活动特征,即从未见的演示中学习活动特征。活动特征能够有效学习合适的机器人控制动作,不是通过盲复制,而是通过参考已演示任务的「语义」表示进行有效学习。
本文使用了基于 C3D 的活动识别网络和 UCF101 活动数据集。图 2 给出 C3D 神经网络的结构示意图 [3]。C3D 网络包含了 8 个卷积层、5 个池化层和 2 个全连接层,然后是一个 softmax 输出层。所有三维卷积核都是 3x3x3 核,步长为 1。每个框中表示过滤器的数量。3D 池化层表示为 Pool1 到 Pool5。除 Pool1 是 1×2×2 外,所有池内核都是 2×2×2。每个全连接层有 4096 个输出单元。UCF101 为动作识别数据集,从 YouTube 收集,共包含 13320 个真实动作视频以及划分为 101 个动作类别。视频在摄像机运动、物体外观和姿态、物体尺度、视点、场景背景和照明条件等方面都有很大的变化,因此为适合于本文所提出问题的数据集。
奖赏函数通过直接比较从第三人视角观看的演示任务视频和从第一人视角观看的机器人执行动作视频获得。奖励 r 是从演示和机器人动作中提取的活动特征之间的欧式距离的负数:
学习算法利用学习到机器人系统的控制信号(U)的映射,在保证奖励最大化的情况下使机器人的运动接近演示的动作。在仿真实验和实际机器人实验中,分别采用强化学习和随机轨迹优化作为学习算法。
本文使用 DDPG 强化学习算法。强化学习中的状态是环境的瞬时视觉观察(由机器人系统观察)。本文利用在 ImageNet 上预训练的 VGGNet 将原始 RGB 图像转换为视觉状态特征。从 VGG-16 网络的最后一个卷积层获得的 4608 长特征向量用作状态表示。
本文将随机轨迹优化作为实际机器人实验的学习算法来生成最优的控制序列。将最优控制问题定义为 Hamilton-Jacobi-Bellman 偏微分方程(PDE)。然后,找到控制 U 的最优序列使机器人能够通过对轨迹的前向采样来执行演示任务。本文定义成本函数 C,将其最小化为:C=-r.^2。
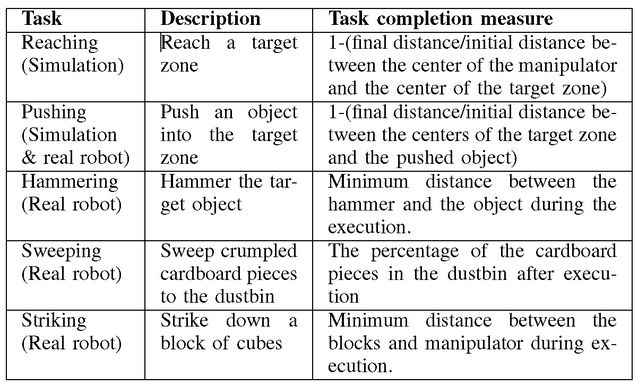
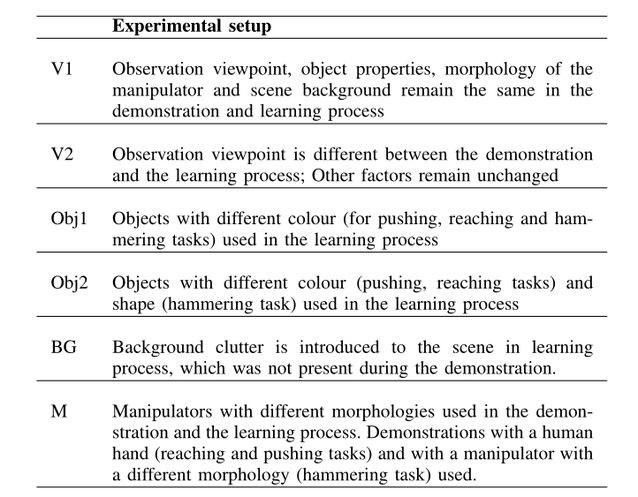
本文通过仿真和实际机器人实验验证方法的有效性。实验所考虑的任务是在真实的机器人实验中实现和推进模拟、锤击、扫射和打击。任务及其定义和任务完成措施见表 1。为了探索该方法的恢复能力,通过改变观察视角、对象属性、场景背景和机械手的形态,对六种不同的设置进行了实验,见表 2。
![]()
TABLE I: Tasks with description and task completion measures
TABLE II: Experimental setups
C3D、UCF101。训练阶段,视频首先下采样为 16 帧,并且帧的数目不大于 16。在从演示和机器人动作的视频中提取特征时,也执行此下采样。然后在 UCF101 数据集上训练 C3D 网络以执行活动识别。训练后,去除全连接层,并将最后一个卷积层(8192 长的特征向量)的输出用作活动特征。
本文使用 OpenAI Gym 和 MuJuCo 物理引擎搭建仿真环境,任务包括伸手和推。仿真机器控制使用 3DOF 控制器,在真实环境中收集一个演示用于人物学习。在每个实验中,分别以每次 20 集、每集 60 步和 160 步的速度运行 DDPG 强化学习算法 10 次。对于每次运行,该算法都返回一个对应最大奖励值的控制策略。训练结束后,选择奖励最高的两个控制策略。图 3 显示了所选实验的演示和执行快照以及相应的学习策略。
Fig. 3: Snapshots of demonstrations and the execution of corresponding learned policies
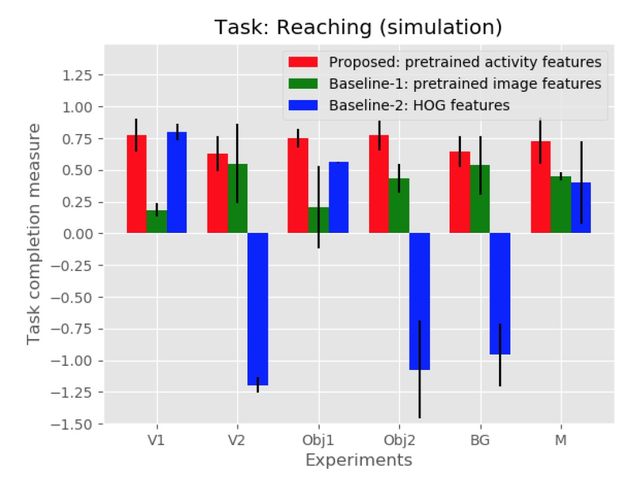
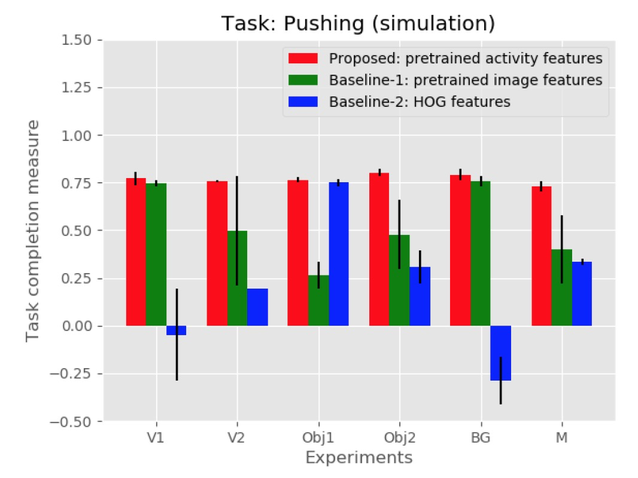
为了证明视频内容的有效帧表示,本文与两个基线方法进行了比较,每个基线基于不同的活动特征提取方法生成奖励。在基线-1 中,从在 ImageNet 上训练的 VGG-16 网络的最后一个卷积层的输出中提取特征,从视频的每一帧中提取的特征被平均并用作活动特征。在基线-2 中,从每个帧中提取 HOG 特征,并对每个视频进行平均化处理以创建活动特征。图 4 和图 5 显示了所提出的方法和基线方法的测试运行的平均任务完成度量。实验结果表明,在不同的实验条件下,本文所提出的方法所学习的策略均能成功地完成演示任务,且任务完成率较高。
Fig. 4: Task completion rates for the task of reaching (simulation)
Fig. 5: Task completion rates for the task of pushing (simulation)
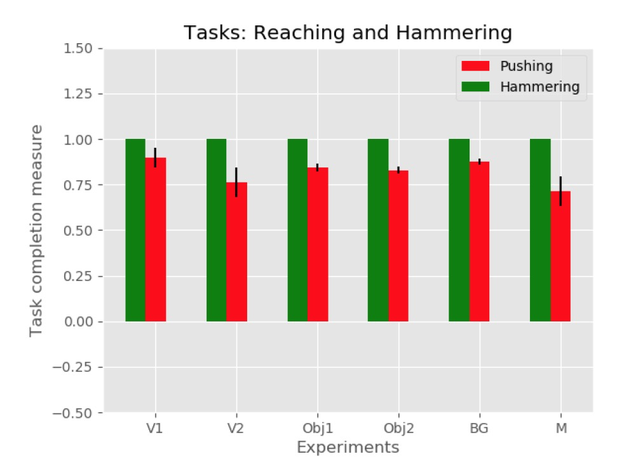
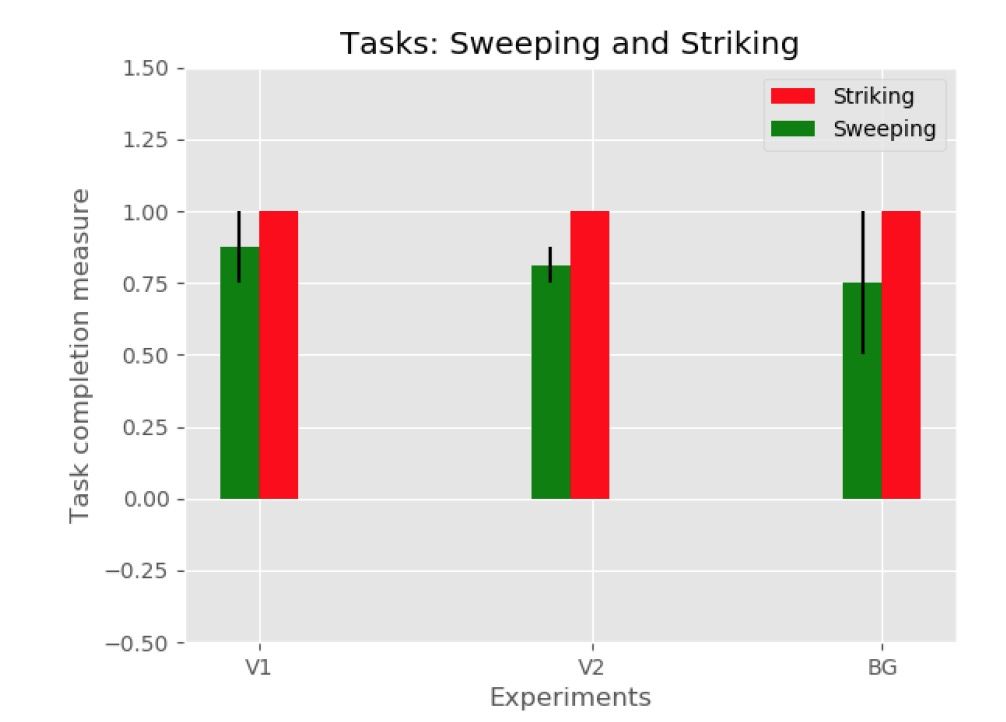
在所有真实的机器人实验中,使用一个 6 自由度的 UR5 机械臂,该机械臂具有适合每个任务的不同末端执行器和 10 次迭代的轨迹优化。所有 6 个实验装置均用于推压和锤击任务。其中三个设置(V1、V2 和 M)用于扫荡和打击任务。每个实验运行 2 次,平均任务完成结果如图 6 和图 7 所示。由实验可知,本文方法能够在不考虑观察视角、目标特性、场景背景和机械手形态变化的情况下较好的完成任务。此外,实验还证明了控制动作的学习可以概括目标对象的颜色和形状,在背景杂波存在的情况下,对象的标识可以保持不变。
Fig. 6: Task completion rates for the tasks reaching and hammering (real robot experiments)
Fig.7 : Task completion rates for the task of sweeping and striking (real robot experiments)
本文提出了一种应用于机器人系统的单样本观察学习方法,该方法从第三人的角度观察单个演示学习任务。通过使用深度神经网络提取演示视频中的环境不变活动特征,将这些活动特征用于生成感知奖励信号,从而用于控制机械手动作的算法学习。活动特征的提取效果对该方法的影响较大,当活动特征空间不能很好地表征机械手形态时,本文的方法可能不再适用。在今后的工作中,我们将更深入地研究机械手的外观和自由度的变化对其性能的影响。
三篇文章从不同的角度完成机器人单样本模仿学习方法。第一篇文章利用经典的元学习 (meta-learning) 方法通过给定域内的一条演示(具体包含一组任务及对应的动作)训练模型参数,将不同任务作为元学习的「数据」,从而使模型具备学习未知演示完成任务的能力。元学习方法在不同场景中的泛化较好,但是比较依赖于训练的样本演示数据。当训练数据不足、演示任务复杂的情况下,会影响元学习的效果。第二篇文章将单样本模仿学习表示为一个符号规划问题,能够有效解决训练数据的问题。同时利用 SGN 的模块化实现符号(物品和谓语动词)的接地 (grounding) 问题,再加上连续规划方法,从而间接实现任务间的泛化处理,大大降低了将训练任务推导至测试任务的复杂度。不过,目前只给出了模拟器中的实验结果,符号规划问题在真实环境中的效果还有待验证。第三篇文章以观察学习方法利用深度网络将演示视频片段转化为活动的抽象表示(活动特征)。该方法舍弃了不同任务间的训练和泛化等过程,直接(暴力)提取特征,因此特征的提取效果直接影响了方法的整体效果。本文使用的是 C3D 神经网络,在给定的实验条件和动作中取得了较好的效果。但该文的实验设置对物品的操作比前两篇文章简单,只是简单的对单个物品的触碰和运作,缺少物品之间的交互。所以对于复杂环境和复杂动作的学习效果,有待进一步分析和研究。
[1] Duan, Yan, et al. "One-shot imitation learning." Advances in neural information processing systems. 2017.
[2] Chelsea Finn (https://arxiv.org/search/cs?searchtype=author&query=Finn%2C+C), et al.「Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (https://arxiv.org/abs/1703.03400).「ICML 2017.
[3] Du Tran (https://arxiv.org/search/cs?searchtype=author&query=Tran%2C+D), et al.「Learning Spatiotemporal Features with 3D Convolutional Networks.」arXiv:1412.0767.
作者介绍:
仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。
主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com