笔记 | 吴恩达Coursera Deep Learning学习笔记
向AI转型的程序员都关注了这个号☝☝☝

作者:Lisa Song
微软总部云智能高级数据科学家,现居西雅图。具有多年机器学习和深度学习的应用经验,熟悉各种业务场景下机器学习和人工智能产品的需求分析、架构设计、算法开发和集成部署。
吴恩达Coursera Deep Learning学习笔记 1 (上)
【学习心得】
Coursera和deeplearning.ai合作的Deep Learning Specialization出得真是慢啊……现在只出了Course 1:Neural Networks and Deep Learning,之后还有4个courses。虽然在我和大多数深度学习从业人员看来是非常基(jian)础(dan)的,但是有时候习题居然还会做错。鄙人资质平平,看来还是得时不时重温一下这种基础课程。虚心求学切忌自空自大。
【学习笔记】
Andrew第一堂课一共四周,每周的课业量都在增加。可以看到Coursera逐渐增加了练习题的比例,这一进步我个人很喜欢,建议大家也都去做一下课后的练习题,特别Python部分的。
前三周每周最后有个对deep learning heroes的采访,除了第一周的Geoffrey Hinton我看了之外,后面的Pieter Abbeel和Ian Goodfellow我都没看,时间太长了。主要是因为教材对于学员过于基础的话,学习时本身就容易走神,所以我就不想再花费有限的注意力了,以后有兴趣还会回来看一下的。
我按照理论知识+Python实践两大模块来总结一下。注意这里只是我个人对课程的总结,侧重于我薄弱的环节,建议感兴趣的读者还是去Coursera上购买教材,这样学习得才更全面。经费紧张的读者也不用担心,前7天是免费的。
Deep Neural Networks
什么是神经网络?
神经网络 (Neural Network) 并不是一个新鲜的名词,但是随着数据、计算力、理论三方面的突破,近些年来才迎来了寒冬后的春天。神经网络主要是由神经元 (neuron) 构成的,一个neuron通常是多个输入的线性组合+一个激活函数,其中激活函数往往是非线性函数。像人类的大脑一样,许多个神经元由多种链接组合起来之后,就具有了强大的能力。Andrew一开始就给了两个最简单的例子。
单神经元网络 (single neural network)
如果我们的输入里只有一个变量,在它之上应用一个ReLU函数就构成了一个单神经元的网络。ReLU函数全称是Rectified Linear Unit,不要被这个名称吓唬到了,其实深度学习完全是纸老虎,ReLU其实就是一个max函数,有点类似于MARS。它的形状是这样的:
单神经网络(ReLU函数)

sigmoid函数
上图是传统的sigmoid函数,不仅常用在logistic regression中,深度学习中也会使用到的。当你比较ReLU函数和sigmoid函数时就会发现:ReLU将一部分的数据舍弃替换为0,这使得计算大规模的数据时比sigmoid更快(试想如果每一层ReLU舍弃了50%的无用数据,那么4层之后数据量就是原来的6%,当然真实的情况没有这么简单),而ReLU另一部分的导数为1,在反向传播时计算梯度很方便;sigmoid函数则处处可导,但是在绝大多数的值域上导数非常小,这使得它没有过滤掉不需要的数据的能力、大幅降低了梯度下降的学习速度,并且在反向传播时可能会有梯度消失的问题。
多神经元网络 (multiple neural network)

多神经元网络
深度学习不仅可以应用于传统的结构化数据,也应用在声音、图像、文字等非结构化的数据上。前一段时间讲课的时候,提到了深度学习的应用。我想表达深度学习与传统方法相比,更方便处理非结构化的数据。结果居然一时把structured这个词给忘记了,卡了半天最后忽悠了一个二维vs.多维——其实我的本意是structured vs. unstructured。还好那只是一语带过,不是知识点,估计也没人注意到。可见尽信书则不如无书,尤其是在deep learning这样新兴、鱼龙混杂的行业。

结构化数据和非结构化数据
以神经网络的结构看逻辑回归 (Logistic Regression)
大家所熟悉的逻辑回归可以看做一个最简单的神经网络,其中z是输入特征的线性组合,而sigmoid函数是对z的非线性转换。因此,Andrew以Logistic regression为切入口、以矢量化后的图片为输入,构建了一个最基础的神经网络。图片的输入本来是三维的(二维的像素点再加上RGB三种颜色),通过image2vector将每一张图片转化为一个宽为1的矩阵——一个将(a,b,c,d)维度的张量flatten为(b*c*d, a)的小技巧:X_flatten = X.reshape(X.shape[0], -1).T,其中X.T是X的转置,而a代表的是样本数。
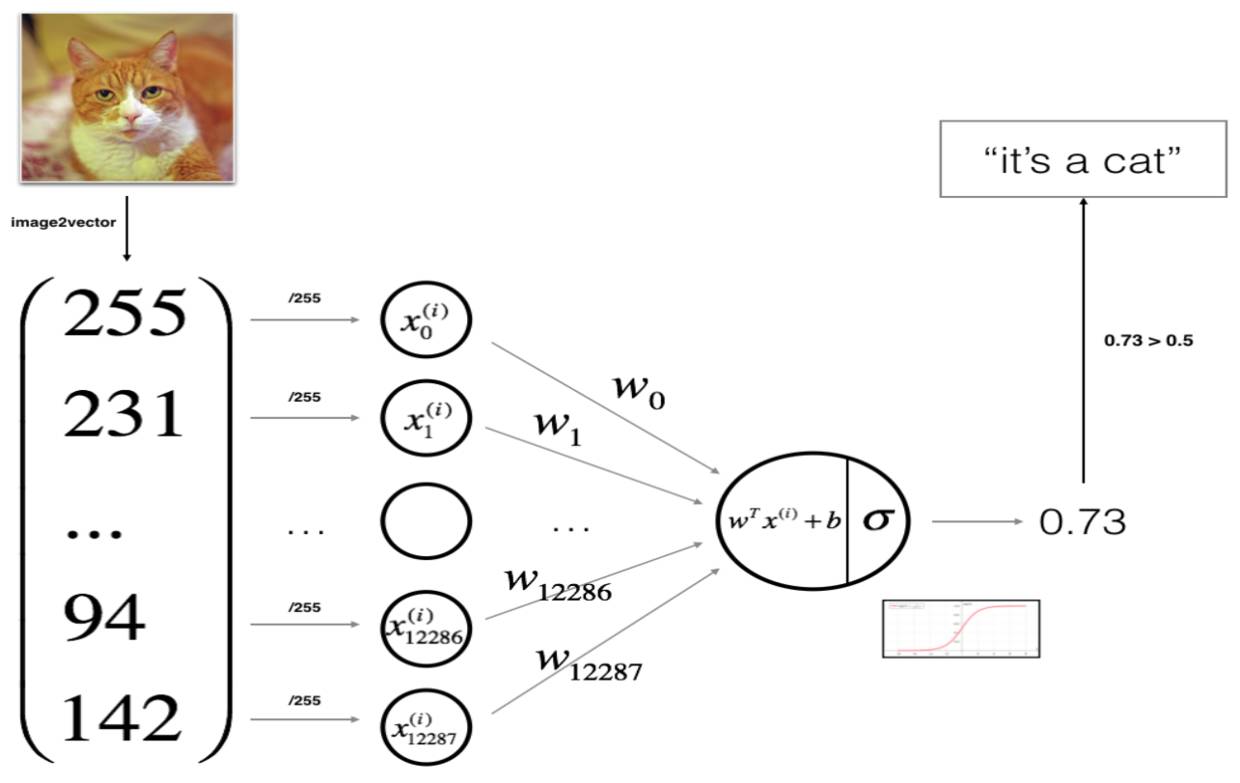
以神经网络的结果表示逻辑回归:识别图片是否是猫
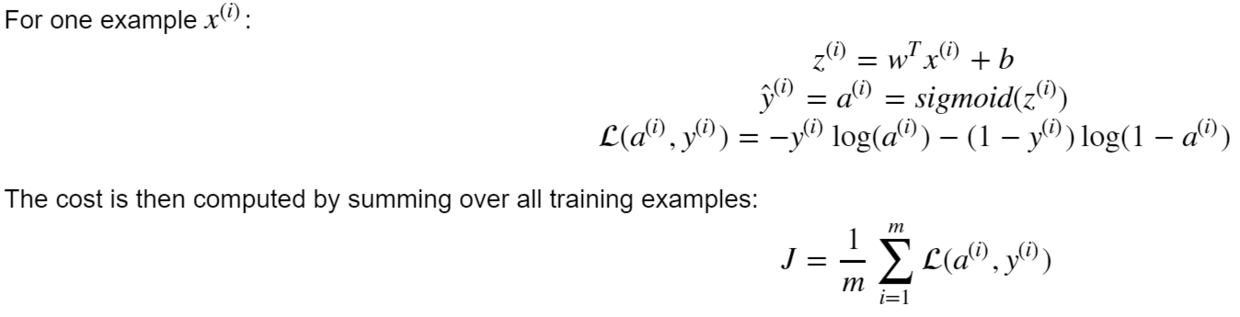
Logistic regression的loss function(损失函数,一个样本的损失)与cost function(代价函数,训练数据所有样本损失的和)
概括来讲,神经网络的建模主要包括以下几个主要步骤:
定义模型结构,比如多少层、什么激活函数、多少输入特征,等等;
初始化模型参数,在logistic regression这个例子中,只需初始化W和b为0就可以了,并且不需要加入一些抖动;
进行num_iterations次循环:
3.1 前向传播:计算当前的代价
3.2 反向传播:计算当前的梯度
3.3 梯度下降:更新参数,更新后的参数为θ_updated=θ−αdθ,其中α是学习率,dθ其实就是dJ/dθ。
直到iteration结束,或者梯度近似为零、参数不再变化为止。
其中sigmoid函数的导数要牢记:sigmoid_derivative(x)=σ′(x)=σ(x)(1−σ(x)),还有两个导数公式:
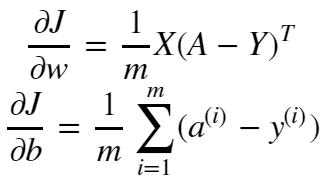
逻辑回归的梯度下降中dw和db的公式
其代码在前向传播的函数中实现如下:
m = X.shape[1]
A = sigmoid(np.dot(w.T, X) + b)
cost = -np.sum(Y*np.log(A) + (1-Y)*np.log(1-A))/m
dw = np.dot(X, (A-Y).T)/m
db = np.sum(A-Y)/m
为了保证在矩阵计算和broadcasting中不出错,进行如下的断言:
assert(dw.shape == w.shape)
assert(db.dtype == float)
cost = np.squeeze(cost) # 降低cost的维度使其成为一个数
assert(cost.shape == ())
Python
Python Broadcasting
我觉得这一块非常精彩,因为很多tutorial里面只是数语带过,Andrew讲得比较多。在矩阵运算中,如果不注意到broadcasting,出现了bug也不太好调。所以我在这里着重整理一下:
Broadcasting是指在对不同形状的矩阵进行四则运算时,numpy对小矩阵的传播处理(其实就是ctrl-C + ctrl-V,使得小矩阵“长大”成能和大矩阵和谐运算的方法)。具体的说明在这里:矩阵的传播运算(https://docs.scipy.org/doc/numpy/user/basics.broadcasting.html)。
这个功能很便捷,比如在计算np.dot(w.T, X) + b的时候,因为有时候b只是个标量 (scalar),而第一项可能是个矩阵,broadcasting使得这一步计算变得很方便。
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = 2.0
>>> a * b # 在乘法计算时,numpy的矩阵传播机制将b这个标量自动拓展为np.array([2.0, 2.0, 2.0]),使其能与a的每一个元素相乘。
array([ 2., 4., 6.])
比如矩阵的normalization by row,是矩阵除以每一行的norm:

normalizing rows
上图的实现方法为:
>>> x_norm = np.linalg.norm(x, ord=2, axis=1, keepdims=True)
>>> x = x/x_norm
其中ord=2表示norm 2,axis=1表示horizontally即每一行 (by row) 的计算,axis=0表示vertically即每一列 (by column) 的计算。keepdims=True是为了防止numpy输出rank 1 array——shape为(n,),使用了keepdims=True后输出的shape是(n,1),这两者之间的不同会在下文中展示。
另一个体现broadcasting高效之处是softmax函数,通常用于标准化多类别分类问题的输出,使得各类别输出的总概率加起来为1。由下图softmax的函数表达可知,分母和原矩阵是不同形状的。分母比原矩阵少一维,即当原矩阵是1*n时,分母是这n个数的和,所以是一个标量;当原矩阵是m*n时,分母是每行n个数的和,所以是一个m*1的矩阵(数组)。broadcasting使得分子直接除以分母就可以得到原矩阵每个数标准化的结果。

softmax函数
softmax的代码为:
>>> x_exp = np.exp(x) # 用numpy的exp而不是math中的exp是因为math包的函数通常只接受实数的输入,而numpy可以接受张量输入,因此在深度学习中,我们很少用math,而多用numpy的方法,前面的log也是同理。
>>> x_sum = np.sum(x_exp, axis=1, keepdims=True)
>>> s = x_exp/x_sum
>>> return s
有了传播机制,当两个矩阵维度相同、或者其中有一个矩阵的一个维度为1的情况下,两个矩阵就可以进行逐个元素的加减乘除运算了。但与此同时,为了减少出bug的可能性,建议多使用assert + shape来检查矩阵的形状,或者用reshape方法。
numpy中的dot、element-wise和outer product(点积、元素积和外积)
dot product (点积)
np.dot(A, B)就是普通的线性代数中的矩阵乘法,是按照矩阵乘法的规则来运算的,要求两个矩阵的维度附和线性代数乘法的运算规律。
element-wise product (元素积)
np.multiply()和*都是元素积,是数组元素逐个计算。请注意,broadcasting适用于元素积(*)的情况而不是点积。如:
a = np.random.randn(4, 3) # a.shape = (4, 3)
b = np.random.randn(3, 2) # b.shape = (3, 2)
c = a*b会报错,因为b需要是4*1或者3*1的情况才能broadcasting。
c = np.dot(a,b)会得到一个4*2的矩阵。
outer product (外积)
numpy的outer product中out[i, j] = a[i] * b[j],即两个一维矩阵a = [a0, a1, ..., aM]和b = [b0, b1, ..., bN]的outer product是:
[[a0*b0 a0*b1 ... a0*bN ]
[a1*b0 .
[ ... .
[aM*b0 aM*bN ]]
>>> import numpy as np
>>> x1 = [9, 2, 5, 0, 0, 7, 5, 0, 0, 0, 9, 2, 5, 0, 0]
>>> x2 = [9, 2, 2, 9, 0, 9, 2, 5, 0, 0, 9, 2, 5, 0, 0]
>>> np.dot(x1,x2)
278
>>> np.outer(x1,x2)
[[81 18 18 81 0 81 18 45 0 0 81 18 45 0 0]
[18 4 4 18 0 18 4 10 0 0 18 4 10 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[63 14 14 63 0 63 14 35 0 0 63 14 35 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[81 18 18 81 0 81 18 45 0 0 81 18 45 0 0]
[18 4 4 18 0 18 4 10 0 0 18 4 10 0 0]
[45 10 10 45 0 45 10 25 0 0 45 10 25 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
>>> np.multiply(x1,x2) # 或者x1*x2
[81 4 10 0 0 63 10 0 0 0 81 4 25 0 0]
Vectorization
这一部分就是说尽量用矩阵运算而不是for loop。比如在反向传播 (back propagation) 时,计算每一个样本loss function并加成cost function时,以及对每一个参数进行更新时,都用矩阵运算。只不过iteration时得用for loop,这估计是无法避免的了。
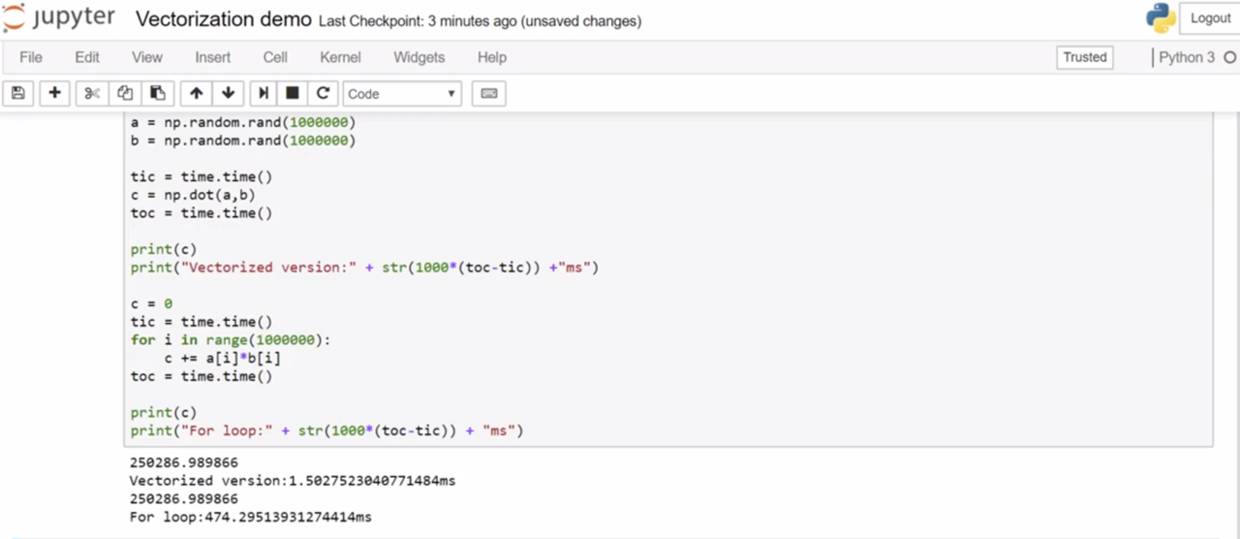
Andrew展示使用for loop和vectorization的运算时间相差300倍(百万数量)
* 其中numpy.random.randn(d0, d1, ... dn) 返回的是从标准平均分布中抽样的n维数组。
Numpy应用技巧
要避免用类似于(5,)这样的rank 1 array,这样的array乍看是一个5*1的matrix,但是在计算中会导致与5*1矩阵完全不同的结果。避免的方法是在定义时设定好维度或reshape方法,或者在计算时用多assert + shape的检查。
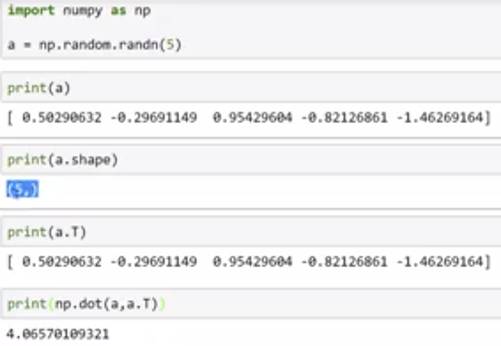
a为rank 1 array时的结果
如果输入是np.random.randn(5, 1) 的时候,输出的结果就完全不同,尽管a.T上去是一样的。
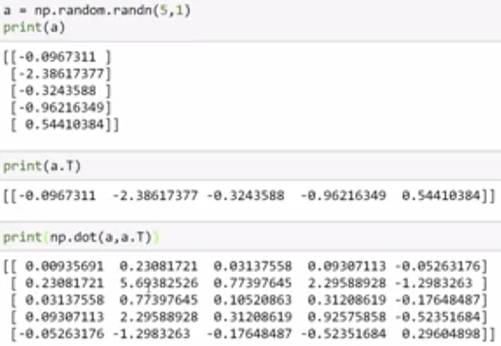
a为5*1矩阵时结果
吴恩达Coursera Deep Learning学习笔记 1 (下)
【学习笔记】
之前我们以逻辑回归 (logistic regression) 为例介绍了神经网络(),但它并没有隐藏层,所以并不算严格意义上的神经网络。在本文中,让我们随着Andrew一起深化神经网络,在sigmoid之前再增加一些ReLU神经元。最后我们会以疯狂收到AI科学家迷恋的可爱猫咪图案为例,用深度学习建立一个猫咪图案的识别模型。不过在这之前,让我们来看一下除了上次说到的sigmoid和ReLU之外,还有什么激活函数、他们之间又各有什么优劣——
激活函数 Activation Functions
sigmoid:除了在输出层(当输出是{0,1}的binary classification时)可能会用到之外,隐藏层中很少用到sigmoid,因为它的mean是0.5,同等情况下用均值为0的tanh函数取代。
tanh:其实就是sigmoid的shifted版本,但输出从(0, 1)变为(-1, 1),所以下一层的输入是centered,更受欢迎。
ReLU (Rectified Linear Unit):在吴恩达Coursera Deep Learning学习笔记 1 (上)中提到过ReLU激活函数,它在深度学习中比sigmoid和tanh更常用。这是因为当激活函数的输入z的值很大或很小的时候,sigmoid和tanh的梯度非常小,这会大大减缓梯度下降的学习速度。所以与sigmoid和tanh相比,ReLU的训练速度要快很多。
Leaky ReLU:Leaky ReLU比ReLU要表现得稍微好一丢丢但是实践中大家往往都用ReLU。
从浅神经网络到深神经网络
最开始的逻辑回归的例子中,并没有隐藏层。在接下来的课程中,Andrew分别介绍了1个隐藏层、2个隐藏层和L个隐藏层的神经网络。但是只要把前向传播和反向传播搞明白了,再加上之后会讲述的一些小撇步,就会发现其实都是换汤不换药。大家准备好了吗?和我一起深呼吸再一头扎进深度学习的海洋吧~
一般输入层是不计入神经网络的层数的,如果一个神经网络有L层,那么就意味着它有L-1个隐藏层和1个输出层。我们可以观察到输入层和输出层,但是不容易观察到中间数据是怎么变化的,因此在输入和输出层之间的部分叫隐藏层。
训练一个深神经网络大致分为以下步骤(吴恩达Coursera Deep Learning学习笔记 1 (上)也有详细说明):
1. 定义神经网络的结构(超参数)
2. 初始化参数
3. 循环迭代
3.1 在前向传播中,分为linear forward和activation forward。在linear forward中,Z[l]=W[l]A[l−1]+b[l],其中A[0]=X;在activation forward中,A[l]=g(Z[l])。期间要储存W、b、Z的值。最后算出当前的Loss。
3.2 在反向传播中,分为activation backward和linear backward。
3.3 更新参数。
下图展现了一个L层的深度神经网络、其中L-1个隐藏层都用的是ReLU激活函数的训练步骤和过程。

一个L-1个ReLU隐藏层的训练过程
标注声明 Notations:
随着神经网络的模型越来越深,我们会有L-1个隐藏层,每一层都用小写的L即[l]标注为上标。z是上一层的输出(即这一层的输入)的线性组合,a是这一层通过激活函数对z的非线性变化,也叫激活值 (activation values)。训练数据中有m个样本,每一个样本都用(i)来标注为上标。每一个隐藏层l里都有n[l](上标内是小写的L不是1)个神经元,每一个神经元都用i标注为下标。

每一层、样本、单元的标注
超参数
随着我们的深度学习模型越来越复杂,我们要学习区分普通参数 (Parameters) 和超参数 (Hyperparameters)。 在上图的标注声明中出现的W和b是普通的参数,而超参数是指:
学习速率 (learning rate) alpha、循环次数 (# iterations)、隐藏层层数 (# hidden layers) L、每隐藏层中的神经元数量 (size of the hidden layers) n[l] ——上标内是小写的L不是1、激活函数 (choice of activation functions) g[l] ——上标内是小写的L不是1。除了这些超参数之外,之后还会学习到以下超参数:动量 (momentum)、小批量更新的样本数 (minibatch size)、正则化系数 (regularization weight),等等。
随机初始化 Random Initialization
吴恩达Coursera Deep Learning学习笔记 1 (上)中的逻辑回归 (logistic regression) 中没有隐藏层,所以将W直接初始化为0并无大碍。但是在初始化隐藏层的W时如果将每个神经元的权重都初始化为0,那么在之后的梯度下降中,每一个神经元的权重都会有相同的梯度和更新,这样的对称在梯度下降中永远无法打破,如此就算隐藏层中有一千一万个神经元,也只同于一个神经元。所以,为了打破这种对称的魔咒,在初始化参数时往往会加入一些微小的抖动,即用较小的随机数来初始化W,偏置项b可以初始化为0或者同样是较小的随机数。在Python中,可以用np.random.randn(a,b) * 0.01来随机地初始化a*b的W矩阵,并用np.zeros((a, 1))来初始化a*1的b矩阵。
为什么是0.01呢?同sigmoid和tanh中所说,数据科学家通常会从将W initialize为很小的随机数,防止训练的速度过缓。但是如果神经网络很深的话,0.01这样小的数字未必最理想。但是总体来说,人们还是倾向于从较小的参数开始训练。
承接上面的超参数,对于每个隐藏层中的神经元数量,我们可以将这几个超参数设定为layer_dims的array,如layer_dims = [n_x, 4,3,2,1] 说明输入的X有n_x个特征,第一层有4个神经元,第二层有3个神经元,第三层有2个,最后一个输出单元。有一个容易搞错的地方,就是W[l]是n[l]*n[l-1]的矩阵,b[l]是n[l]*1的矩阵。所以初始化W和b就可以写成:
for l in range(1, L):
parameters["W"+str(l)] = np.random.randn(layer_dims[l],layer_dims[l-1])*0.01
parameters["b"+str(l)] =np.zeros((layer_dims[l],1))
详见例2中的initialize_parameters_deep函数。
并不是很复杂有没有!那么,下面我们一起跟着Andrew来看几个神经网络的例子:
【例 1】用单个隐藏层的神经网络来分类平面数据
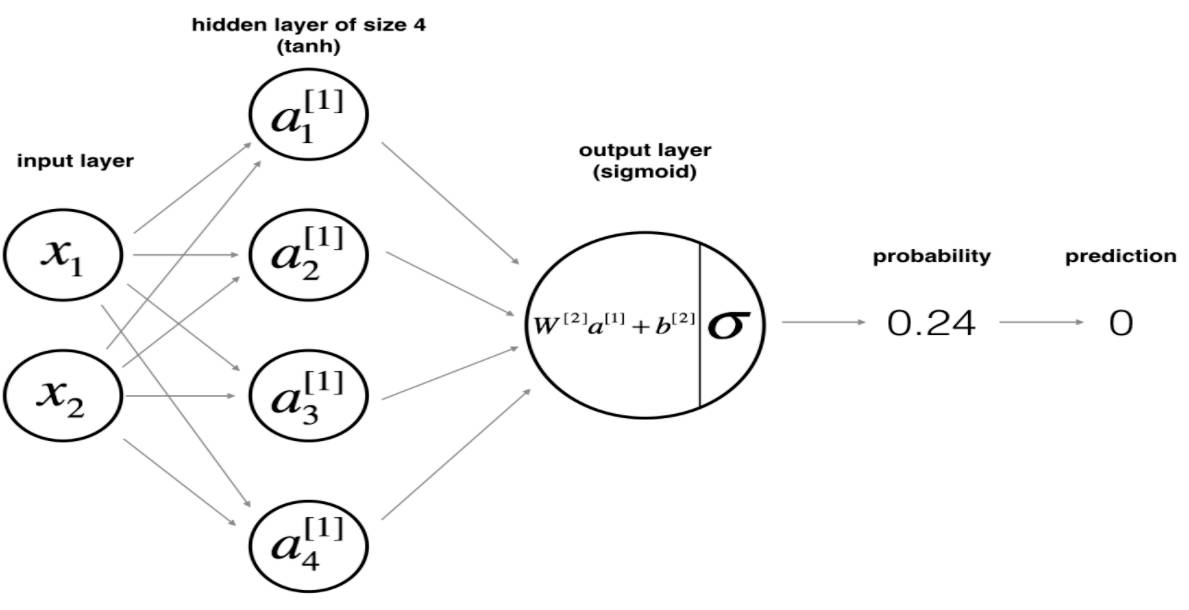
本例:4个神经元的隐藏层 (tanh) 加一个sigmoid的输出层
第三课的例子是Planar data classification with one hidden layer,即帮助大家搭建一个上图所示的浅神经网络(Shallow Neural Networks):一个4个单元的隐藏层 (tanh) 加一个sigmoid的输出层。

本例反向传播中各个梯度的计算(左为一个样本的情况,右为矢量化运算)
最后一步的prediction是用了0.5的cutoff,很简单:
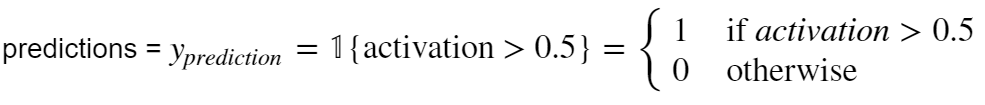
将A2转化为Y-hat
最后的决策边界如下图,在训练数据上的精确度为90%,是不是比logistic regression表现强多啦?可见logistic regression不能学习到数据中的非线性关系,而神经网络可以(哪怕是本例中一个非常浅的神经网络)。
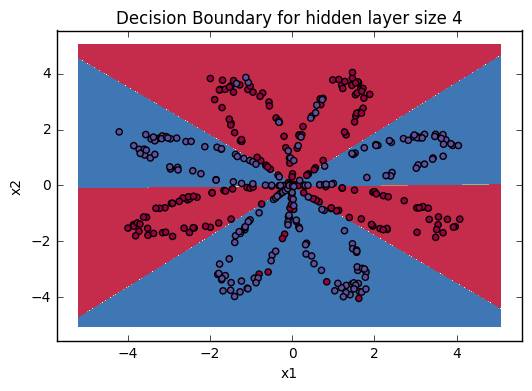
决策边界:一个有四个神经元的隐藏层的神经网络
其实本例中的模型也很简单,如果再复杂些可以做到更精确,但是可能会overfit,毕竟从上图中可以看出现有的模型已经抓住了数据中的大趋势。下面尝试了在隐藏层中设置不同个数的神经元,来看模型的精确度和决策边界是如何变化的:
Accuracy for 1 hidden units: 67.5 %
Accuracy for 2 hidden units: 67.25 %
Accuracy for 3 hidden units: 90.75 %
Accuracy for 4 hidden units: 90.5 %
Accuracy for 5 hidden units: 91.25 %
Accuracy for 20 hidden units: 90.0 %
Accuracy for 50 hidden units: 90.25 %
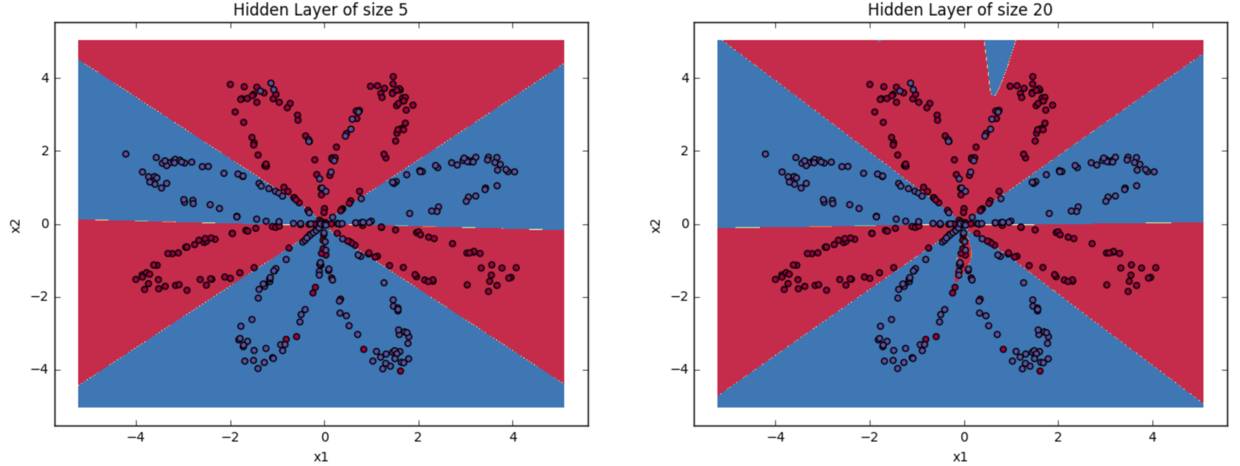
隐藏层有5个神经元vs.20个神经元的决策边界
可以看到,在训练数据上,5个神经元的精确度是最高的,而当神经元数超过20时,决策边界就显示有overfitting的情况了。不过没事,之后会学习正则化 (regularization),能使很复杂的神经网络都不会出现overfitting。
这个例子的代码很简单,就不贴了。
【例 2】L层深度神经网络
第四节课的例子有三个:第一是一个ReLU+sigmoid的浅层神经网络,是为了后面的例子做铺垫;第二个将其深化,用了L-1个ReLU层,输出层也是sigmoid;第三个例子就是用前两个神经网络训练猫咪识别模型[吐血]。我将L层的模型和其猫咪识别器的训练过程精简地说一下。
设计神经网络与随机初始化参数
下图就是我们要搭建的L层神经网络,不过在这之前,让我们先挑个lucky number方便以后重复训练结果^_^
np.random.seed(1)
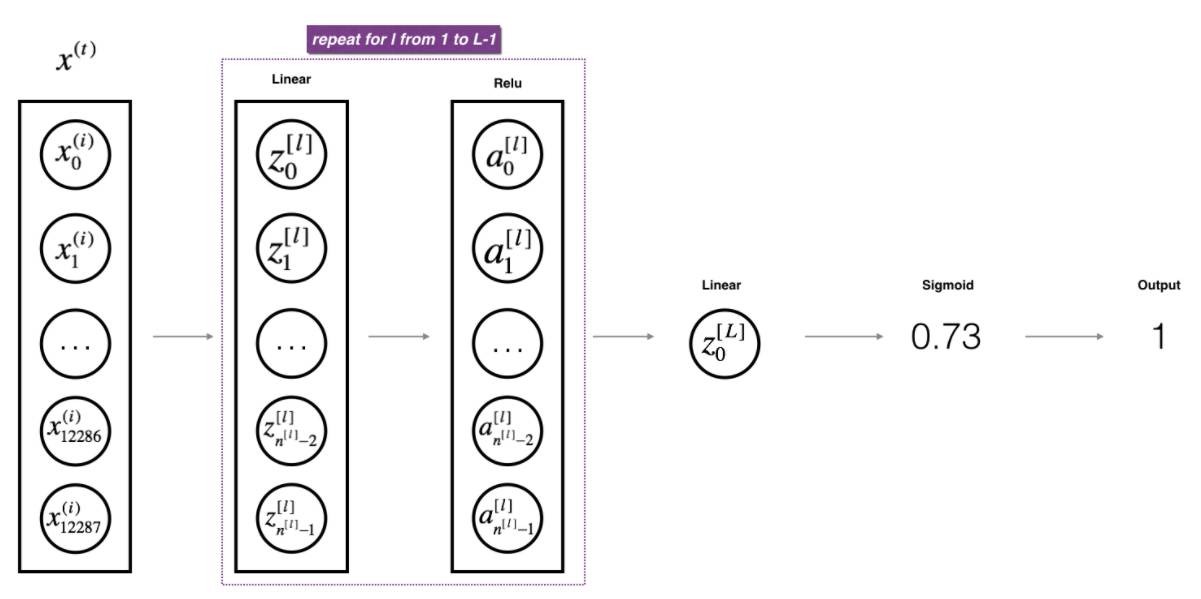
本例:[线性组合 -> ReLU激活] * L-1次 -> 线性组合 -> sigmoid输出
其次,让我们设计一下我们的神经网络。因为激活函数已经确定用ReLU了,所以在本例中我们只需设计layer_dims,就能确定输入的维度、层数和每层的神经元数。
def initialize_parameters_deep(layer_dims):
parameters = {}
L = len(layer_dims) # 根据我们一开始设计的模型超参数,读取L(其实是L+1)
for l in range(1, L): # 设定W1到W(L-1)和b1和b(L-1),一共有L-1层(其实是L)
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) * 0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))
assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters
和具体的数据结合,就知道了输入的维度和样本的数量。假设我们的训练数据中有209张图片,每张都是64*64像素,那么输入特征数n_x就是64*64*3 = 12288,m就是209,如下图:

每一层参数的维度
如果我们将W和b参数设为parameters,每一个初始化的W和b都是parameters这个list中的一个元素,那么L-1个循环隐藏层其实就是len(parameters)//2。下图是一个ReLU层加一个sigmoid层的一个loop,怎么将同样的计算复制到我们的L层深度神经网络中呢?

线性组合->ReLU->线性组合->sigmoid的前向与反向传播的例子
前向传播
前向传播分为linear forward和activation forward,前者计算Z,后者计算A=g(Z),g视激活函数的不同而不同。因为activation forward这步中包括了linear的值,所以名为linear_activation_forward函数。由于反向传播的梯度计算中会用到W、b、A的值,所以我们将每一个iteration中将每个神经元的这些值暂时储存在caches这个大列表中,再在下一轮循环中覆盖掉。代码如下:
def linear_forward(A, W, b):
Z = np.dot(W, A) + b
assert(Z.shape == (W.shape[0], A.shape[1]))
cache = (A, W, b)
return Z, cachedef linear_activation_forward(A_prev, W, b, activation):
if activation == "sigmoid":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation == "relu":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
assert (A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cache
在定义了每一个神经单元的linear-activation forward之后,我们来定义这个L层神经网络的前向传播:
def L_model_forward(X, parameters):
caches = []
A = X
L = len(parameters) // 2 # 因为之前设定的parameters包含了每一层W和b的初始值,所以层数是这个列表长度的一半
for l in range(1, L): # L-1个隐藏层用ReLU激活函数
A_prev = A
A, cache = linear_activation_forward(A_prev, parameters['W' + str(l)], parameters['b' + str(l)], activation = "relu")
caches.append(cache)
AL, cache = linear_activation_forward(A, parameters['W' + str(L)], parameters['b' + str(L)], activation = "sigmoid") # 第L个层用sigmoid函数
caches.append(cache)
assert(AL.shape == (1,X.shape[1]))
return AL, caches
前向传播的尽头是计算当前参数下的损失~不过正如在后面L_model_backward函数中看到的,我们这里直接计算dL/dAL,并不计算L,这里计算cost是为了在训练过程检查代价是不是在稳定下降,以确保我们使用了合适的学习率。
def compute_cost(AL, Y):
m = Y.shape[1]
cost = -np.sum(Y*np.log(AL) + (1-Y)*np.log(1-AL))/m
cost = np.squeeze(cost) # 将类似于 [[17]] 的cost变成 17
assert(cost.shape == ())
return cost
反向传播
反向传播和前向传播的函数设计是对称的,但是会比前向传播复杂一丢丢,需要小心各种线性代数中的运算规则——这也是为什么在前向传播中我们都在return前加入了维度检查(assert + shape)。下图显示了每一个神经元在反向传播中的输入和输出。现在我们看到之前在前向传播中缓存的用处了。如果我不储存W和Z的值,我就没有办法在反向线性传播中计算dW,db同理。
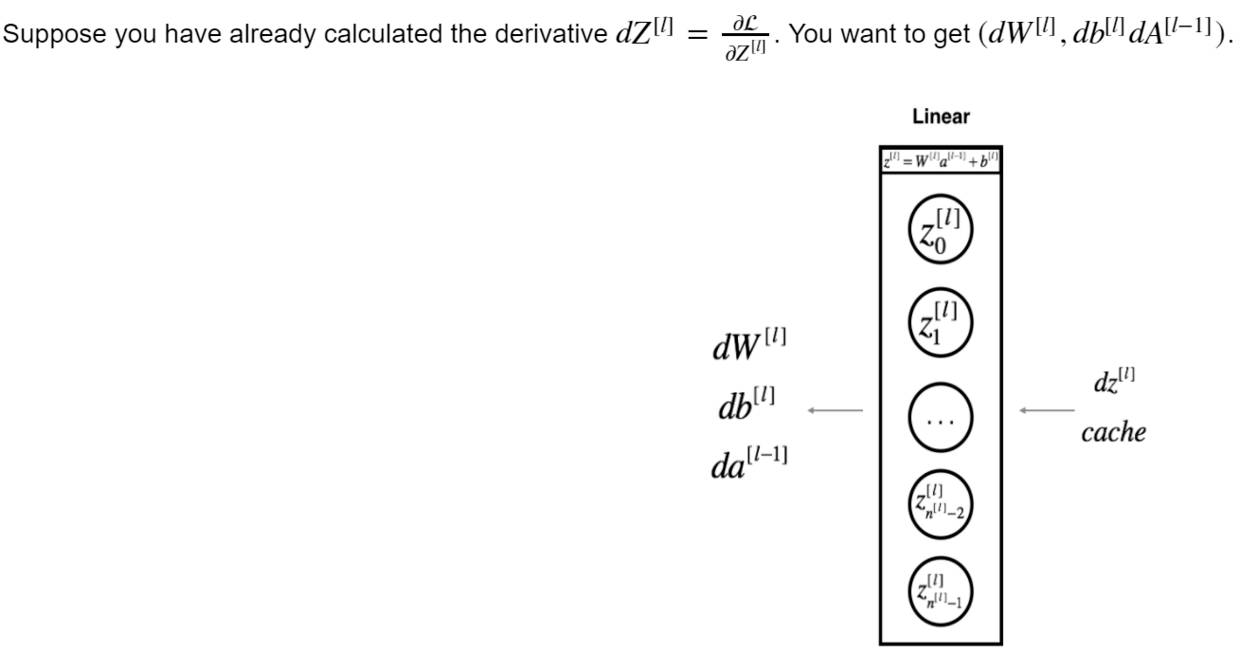
反向线性传播中的输入和输出
def linear_backward(dZ, cache):
A_prev, W, b = cache
m = A_prev.shape[1]
dW = np.dot(dZ, A_prev.T)/m
db = np.sum(dZ, axis=1, keepdims=True)/m
dA_prev = np.dot(W.T, dZ)
assert (dA_prev.shape == A_prev.shape)
assert (dW.shape == W.shape)
assert (db.shape == b.shape)
return dA_prev, dW, db
上述的公式用线性代数表示为下图:

反向传播中参数梯度的计算
Andrew贴心地为大家提供了写好的函数:relu_backward和sigmoid_backward,如果我们自己写的话,需要在前向传播中储存A的值,否则在很多反向传播中就不知道dA/dZ,因为有些激活函数的导数是A的函数,比如sigmoid函数和tanh函数。
def linear_activation_backward(dA, cache, activation):
linear_cache, activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, db
同前向传播一样,我们将dL/dAL反向传播,通过每一层的linear-activation backward构建整个完整的反向传播体系:
def L_model_backward(AL, Y, caches):
grads = {}
L = len(caches) # 层数
m = AL.shape[1]
Y = Y.reshape(AL.shape) # 改变Y的维度,确保其与AL的维度统一
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) # 代价函数对输出层输出AL的导数,就不计算具体的cost了
current_cache = caches[L-1]
grads["dA" + str(L)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, activation = "sigmoid")
for l in reversed(range(L-1)):
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA"+str(l+2)], current_cache, activation = "relu")
grads["dA" + str(l + 1)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return grads
一般现实工作中不会用线性代数如此折磨你,就算要自己一步一步这么写,也可以加入梯度检查等等来为你增添信心,具体以后再分享~
参数更新
至此我们已经在一个循环中计算出了当前W和b的梯度,最后就是用梯度下降的定义更新参数。在下一个例子中我们会看到如何用我们已经写好的每一步的函数,使用for loop执行梯度下降,最后得到训练好的模型。
def update_parameters(parameters, grads, learning_rate):
L = len(parameters) // 2
for l in range(L):
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate*grads["dW" + str(l + 1)]
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate*grads["db" + str(l + 1)]
return parameters
【例 3】继续AI科学家对猫的执念……
下面我们用例2中的L层深度神经网络来识别一张图是不是猫咪[捂脸],因为代码有点多所以分成了2和3的两个例子。
假设train_x_orig是我们原始的输入,已经将图片像素数据提取并flatten为适合训练的数据,这里我们将每一个样本从64*64*3的输入变成一个12288*1的矢量,然后将值标准化到0-1之间:
train_x_flatten = train_x_orig.reshape(train_x_orig.shape[0], -1).T
train_x = train_x_flatten/255.

image2vector conversion
设计一个神经网络:layers_dims = [12288, 20, 7, 5, 1],即每个样本有12288个像素输入,第一层20个ReLU神经元,第二层7个,第三层5个,最后一个sigmoid。
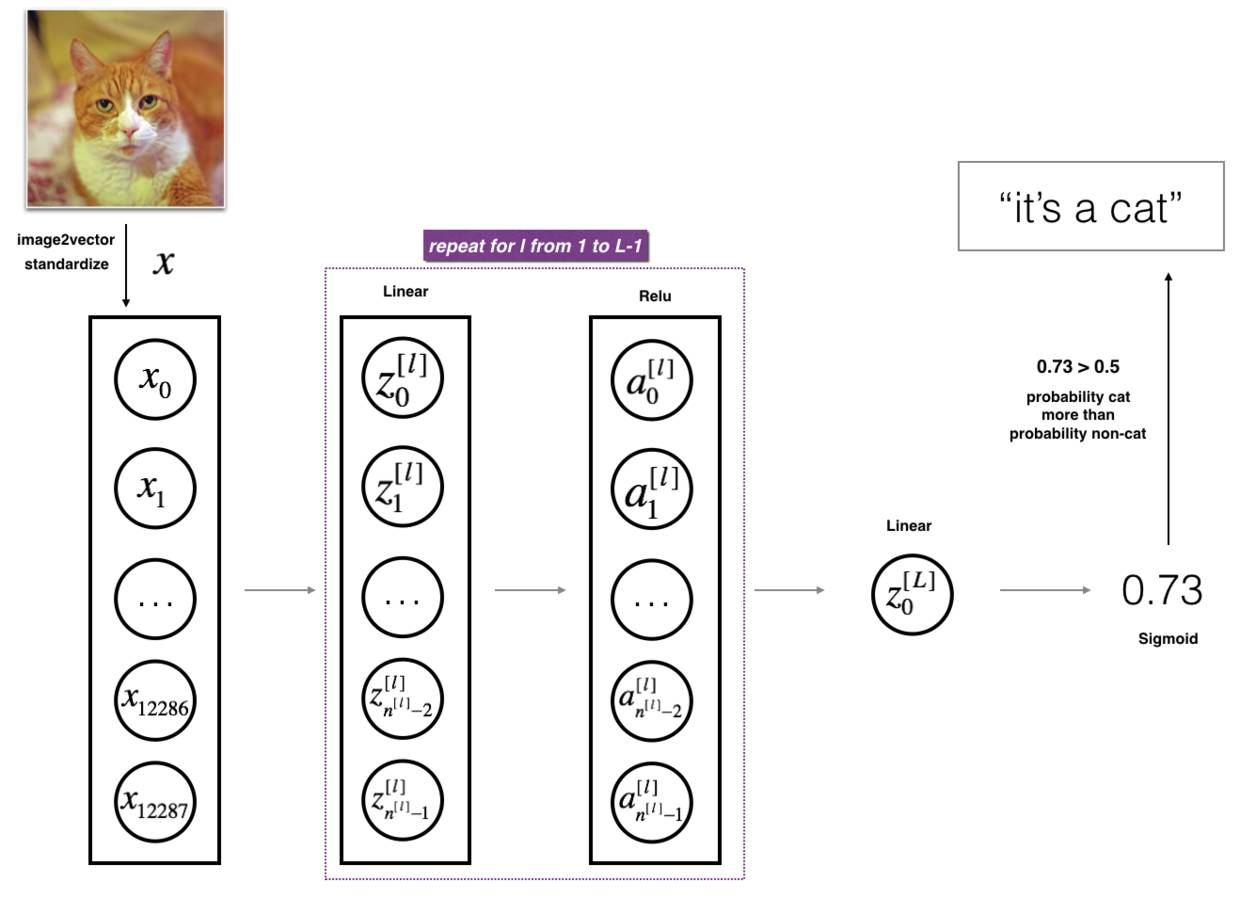
L层的神经网络来识别图像中的喵喵
终于可以调用我们之前辛辛苦苦写好的函数啦!之前写的函数都是每一个iteration中的每一步骤,现在我们将每一个loop循环num_iterations次。
parameters = initialize_parameters_deep(layers_dims)
for i in range(0, num_iterations):
AL, caches = L_model_forward(X, parameters)
cost = compute_cost(AL, Y)
grads = L_model_backward(AL, Y, caches)
parameters = update_parameters(parameters, grads, learning_rate)
这里的parameters就是训练好的参数,我们就可以用它来预测新的萌萌哒猫猫啦。
读取一张num_px*num_px图片的像素再将其RGB转换为num_px*num_px*3的方法,请注意这里的图片尺寸需和训练数据中的一样:
fname = "images/" + my_image
np.array(ndimage.imread(fname, flatten=False))
scipy.misc.imresize(image, size=(num_px,num_px)).reshape((num_px*num_px*3,1))
最后我们的模型在训练数据上的精确度为98.6%。然后我们就可以用类似于predict(test_x, test_y, parameters)这样的方法就能预测这个图片是不是一个喵喵啦!最后得到在训练数据上的精确度为80%,但是让我们来看看剩下20%没有正确预测的样本是什么样子的……

基础模型没有正确预测的样本例子
除了第五张姿势扭捏的猫猫外,2和4中的猫猫我们也没有很好地识别出来。不过不用担心,卷积神经网络 (Convolutional Neural Networks) 会比image2vector更适合于处理图片数据,所以敬请期待以后的更新!
因为篇幅限制今天就先写到这里,感兴趣的朋友们可以关注我的简书。在这里引用萌萌哒Andrew的话与君共勉:
In the CS world, all of us are used to needing to jump every ~5 years onto new technologies and paradigms of thinking (internet->cloud->mobile->AI/machine learning), because new technologies get invented at that pace that obsolete parts of what we were previously doing. So CS people are used to learning new things all the time.
在 CS 世界中,我们所有人都习惯于每 5 年就要跳到新技术和思维模式(互联网→云→移动→AI/机器学习),因为新技术以这样的速度发明。所以,CS 人也一直习惯于不断学习新的事物。
原文地址:
1)http://www.jianshu.com/p/fd49e6e35a21
2)http://www.jianshu.com/p/51a5ff911c41
热文推荐
名校排行榜:上海交大位居内地CS排名第一,清华包揽AI综合实力及毕业生竞争力第一
硬货 | 一文了解深度学习在NLP中的最佳实践经验和技巧
深度学习哪家强?吴恩达、Udacity和Fast.ai的课程我们替你分析好了
重磅 | 128篇论文,21大领域,深度学习最值得看的资源全在这了(附一键下载)
CCAI 2017 | 香港科技大学计算机系主任杨强:论深度学习的迁移模型
“GANs 之父”Goodfellow亲身传授:深度学习未来的8大方向和入门AI必备的三大技能
牛!他本科没毕业就进入Google Brain,还发表了最火的深度学习顶级论文... 你呢?
Chatbot大牛推荐:AI、机器学习、深度学习必看9大入门视频
五个案例,三大心得,Meratix创始人带你进阶深度学习的实践应用之路

☞ 点赞和分享是一种积极的学习态度


