前沿 | CNN取代RNN?当序列建模不再需要循环网络
选自offconvex
作者:John Miller
机器之心编译
参与:乾树、张倩、思源
在过去几年中,虽然循环神经网络曾经一枝独秀,但现在自回归 Wavenet 或 Transformer 等模型在各种序列建模任务中正取代 RNN。机器之心在 GitHub 项目中曾介绍用于序列建模的 RNN 与 CNN,也介绍过不使用这两种网络的 Transformer。而本文主要关注循环网络与前馈网络在序列建模中有什么差别,以及到底什么时候选择卷积网络替代循环网络比较好。
在这篇博文中,我们来探讨循环网络模型和前馈模型之间的取舍。前馈模型可以提高训练稳定性和速度,而循环模型表达能力更胜一筹。有趣的是,额外的表现力似乎并没有提高循环模型的性能。
一些研究团队已经证明,前馈网络可以达到最佳循环模型在基准序列任务上取得的结果。这种现象为理论研究提供了一个有趣的问题:
为什么前馈网络能够在不降低性能的前提下取代循环神经网络?什么时候可以取代?
我们讨论了几个可能的答案,并强调了我们最近的研究《When Recurrent Models Don't Need To Be Recurrent》,这项研究从基本稳定性的角度给出了解释。
两个序列模型的故事
循环神经网络
循环模型的众多变体都具有类似的形式。该模型凭借状态 h_t 梳理过去的输入序列。在每个时间步 t,根据以下等式更新状态:
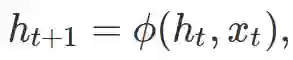
其中 x_t 是时刻 t 的输入,φ 是可微分映射,h_0 是初始状态。在一个最原始循环神经网络中,该模型由矩阵 W 和 U 参数化,并根据下式更新状态:

实践中,长短期记忆网络(LSTM)更常用。不管哪种情况,进行预测时,都将状态传递给函数 f,模型预测 y_t = f(h_t)。由于状态 h_t 是包含所有过去输入 x_0,...,x_t 的函数,因此预测 y_t 也取决于整个历史输入 x_0,...,x_t。
循环模型可用图形表示如下。
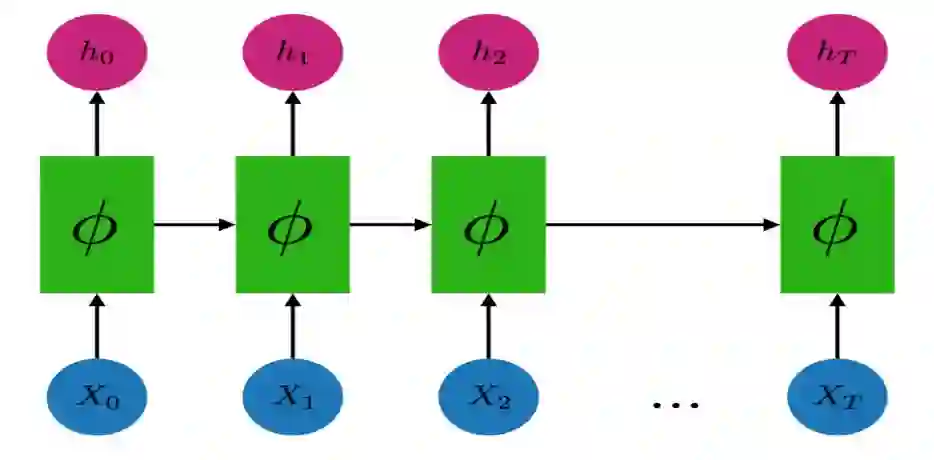
循环模型可以使用反向传播拟合数据。然而,从时间步 T 到时间步 0 反向传播的梯度通常需要大量难以满足的内存,因此,事实上每个循环模型的代码实现都会进行截断处理,并且只反向传播 k 个时间步的梯度。
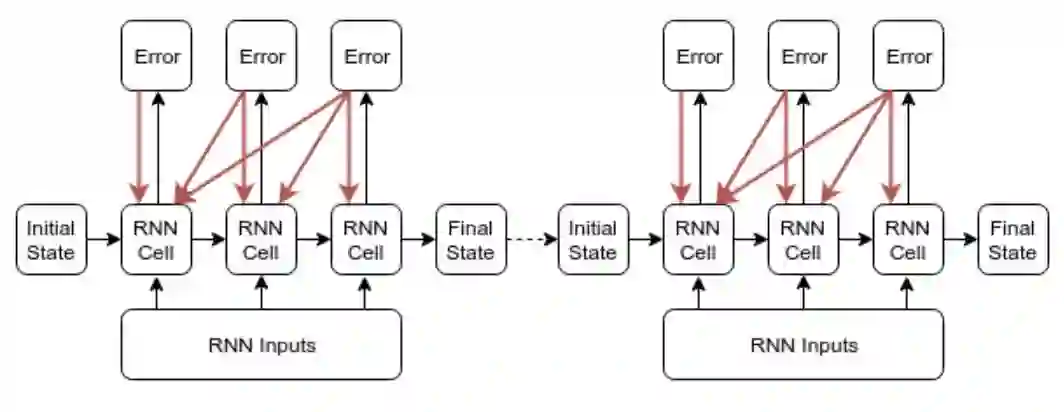
按照这个配置,循环模型的预测仍然依赖于整个历史输入 x_0,…,x_T。然而,目前尚不清楚这种训练过程对模型学习长期模式的能力有何影响,特别是那些需要 k 步以上的模式。
自回归、前馈模型
自回归(autoregressive)模型仅使用最近的 k 个输入,即 x_t-k + 1,...,x_t 来预测 y_t,而不是依赖整个历史状态进行预测。这对应于强条件独立性假设。特别是,前馈模型假定目标仅取决于 k 个最近的输入。谷歌的 WaveNet 很好地说明了这个通用原则。

与 RNN 相比,前馈模型的有限上下文意味着它无法捕获超过 k 个时间步的模式。但是,使用空洞卷积等技术,可以使 k 非常大。
为何关注前馈模型?
一开始,循环模型似乎是比前馈模型更灵活、更具表现力的模型。毕竟,前馈网络提出了强条件独立性假设,而循环模型并没有加上这样的限制。不过即使前馈模型的表现力较差,仍有几个原因使得研究者可能更倾向于使用前馈网络。
并行化:卷积前馈模型在训练时更容易并行化,不需要更新和保留隐藏状态,因此输出之间没有顺序依赖关系。这使得我们可以在现代硬件上非常高效地实现训练过程。
可训练性:训练深度卷积神经网络是深度学习的基本过程,而循环模型往往更难以训练与优化。此外,为了有效并可靠地训练深度前馈网络,开发人员在设计架构和软件开发上已经付出了巨大的努力。
推理速度:在某些情况下,前馈模型可以更轻量,并且比类似的循环系统更快地执行推理。在其他情况下,特别是对于长序列问题,自回归推理是一个很大的瓶颈,需要大量的工程工作或聪明才智去克服。
前馈模型可以比循环模型表现更好
虽然看起来前馈模型的可训练性和并行化是以降低模型准确度为代价的,但是最近有一些例子表明,前馈网络在基准任务上实际上可以达到与循环网络相同的精度。
语言建模。在语言建模中,目的是在给定所有当前单词的情况下预测下一个单词。前馈模型仅使用 k 个最近的单词进行预测,而循环模型可能会使用整个文档。门控卷积语言模型是一种可与大型 LSTM 基准模型竞争的前馈自回归模型。尽管截断长度 k = 25,但该模型在 Wikitext-103 的基准测试上表现优于大型 LSTM 模型,该基准测试用于测试善于捕获长期依赖关系的模型。在 Billion Word Benchmark 上,该模型比最大的 LSTM 略差,但训练速度更快,占用的资源也更少。
机器翻译。机器翻译的目标是将英语句子映射到其它语种句子,例如英语转法语。前馈模型仅使用句子的 k 个单词进行翻译,而循环模型可以利用整个句子。在深度学习中,谷歌神经机器翻译等模型最开始基于 LSTM 与注意力机制进行序列建模,后来大家使用全卷积网络进行序列建模、使用 Transformer 构建大型翻译系统。

语音合成。在语音合成领域,研究者试图产生逼真的人类语音。前馈模型仅限于过去的 k 个样本,而循环模型可以使用所有历史样本。截止本稿发布,前馈自回归 WaveNet 是对 LSTM-RNN 模型的重大改进。
延伸阅读。最近,Bai 等人提出了一种利用空洞卷积的通用前馈模型,并表明它在从合成复制任务到音乐生成的任务中优于循环基准模型。机器之心在《从循环到卷积,探索序列建模的奥秘》这一篇文章中就解析过这一模型。
前馈模型怎么能超越循环模型?
在上面的示例中,前馈网络能实现与循环网络相同或更好的结果。这很令人困惑,因为循环模型似乎更先进。Dauphin 等人对这种现象给出了一种解释:
对于语言建模而言,循环模型提供的无限长的上下文信息并非绝对必要。
换句话说,你可能不需要大量的上下文信息求平均来完成预测任务。最近的理论工作提供了一些支持这种观点的证据。
Bai 等人给出了另一种解释:
RNN 的「无限记忆」优势在实践中基本上不存在。
正如 Bai 等人的报告中说的一样,即使在明确需要长期上下文的实验中,RNN 及其变体也无法学习长序列。在 Billion Word Benchmark 上,一篇精彩的 Google 学术报告表明,记忆 n = 13 字上下文的 LSTM n-gram 模型与记忆任意长上下文的 LSTM 表现无异。
这一证据使我们猜想:在实践中训练的循环模型实际上是前馈模型。这可能发生,因为截断的沿时间反向传播不能学习比 k 步更长的模式,因为通过梯度下降训练的模型没有长期记忆。
在我们最近的论文中,我们研究了使用梯度下降训练的循环模型和前馈模型之间的差距。我们表示如果循环模型是稳定的(意味着没有梯度爆炸),那么循环模型的训练或推断过程都可以通过前馈网络很好地逼近。换句话说,我们证明了通过梯度下降训练的前馈和稳定循环模型在测试上是等价的。当然,并非所有实践中训练的模型都是稳定的。我们还给出了经验证据,可以在不损失性能的情况下对某些循环模型施加稳定性条件。
总结
尽管已经进行了一些初步的尝试,但要理解为什么前馈模型可以与循环模型竞争,并阐明序列模型之间如何权衡,仍有许多工作要做。在通用序列基准测试中到底需要多少内存?截断 RNN(可以看做是前馈模型)和流行的卷积模型之间的表现力权衡是什么?为什么前馈网络在实践中的性能和不稳定的 RNN 一样好?
回答这些问题是尝试建立一个既可以解释我们当前方法的优势和局限性,也可以指导如何在具体环境中如何选择不同模型的理论。

原文链接:http://www.offconvex.org/2018/07/27/approximating-recurrent/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




