
题目: oLMpics - On what Language Model Pre-training Captures
摘要:
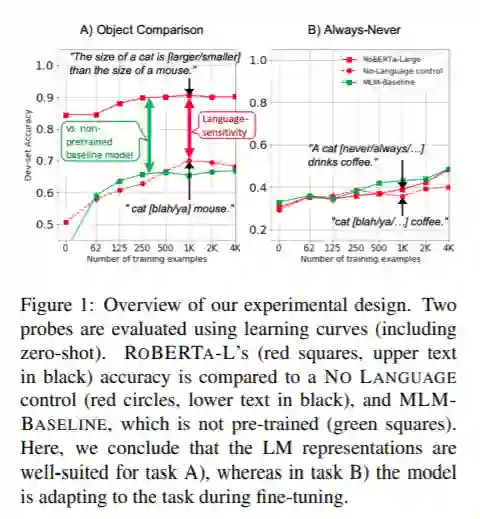
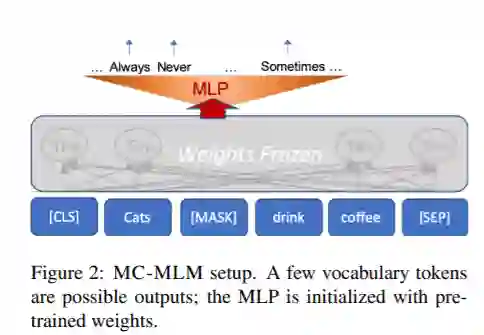
最近,预训练语言模型(LMs)的成功引起了人们对其语言能力的广泛兴趣。然而,了解LM表示对于符号推理任务是否有用的努力是有限和分散的。在这项工作中,我们提出了八个推理任务,这些任务在概念上需要进行比较、连接和组合等操作。一个基本的挑战是理解LM在任务上的性能应该归因于预先训练的表示还是任务数据的微调过程。为了解决这个问题,我们提出了一个评估协议,其中包括了零次评估(没有微调),以及将微调LM的学习曲线与多个控件的学习曲线进行比较,从而描绘出LM功能的丰富画面。我们的主要发现是:(a)不同的LMs表现出不同的定性推理能力,例如,RoBERTa成功地完成了BERT完全失败的推理任务;(b) LMs不以抽象的方式推理,而是依赖于上下文,例如,罗伯塔可以比较年龄,但它只能在年龄处于人类年龄的典型范围内时才能这样做;(c)在一半的推理任务中,所有的模型都完全失败了。我们的发现和基础设施可以帮助未来的工作设计新的数据集,模型和目标函数的培训。
作者:
Alon Talmor是特拉维夫大学自然语言处理的博士生,由Jonathan Berant博士指导,主要研究方向是自然语言处理和问答系统。个人官网:https://www.alontalmor.com/
Jonathan Berant是特拉维夫大学布拉瓦特尼克计算机科学学院助理教授,研究领域是自然语言处理,研究自然语言理解问题,如语义分析、问题回答、释义、阅读理解和文本蕴涵。最感兴趣的是能从需要多步骤推理或处理语言构成的弱监督中学习。个人官网:http://www.cs.tau.ac.il/~joberant/
成为VIP会员查看完整内容


相关内容

专知会员服务
32+阅读 · 2020年2月21日
Arxiv
5+阅读 · 2019年5月20日
Arxiv
4+阅读 · 2017年11月27日




相关VIP内容
专知会员服务
32+阅读 · 2020年2月21日
相关资讯