
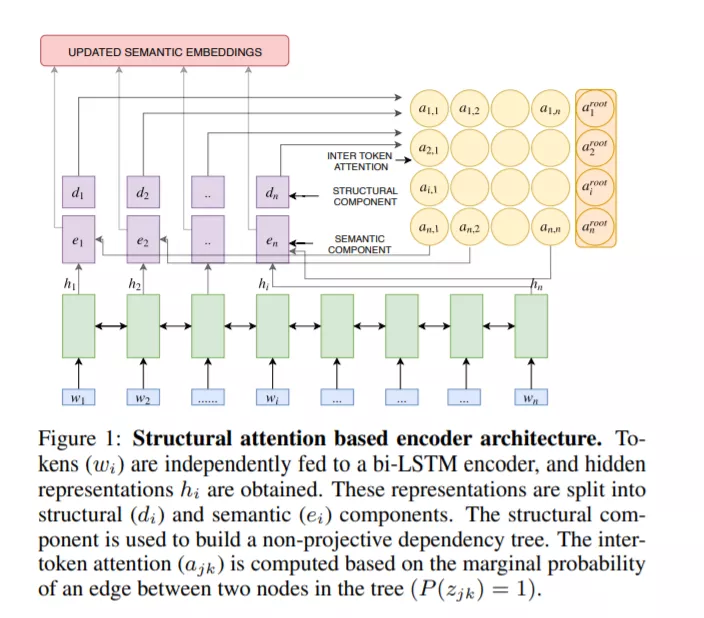
基于注意力的、基于RNN的编解码器体系结构在对新闻文章进行抽象摘要方面取得了令人瞩目的成绩。然而,这些方法不能解释文档句子中的长期依赖关系。这个问题在多文档摘要任务中更加严重,例如在社区问答(CQA)网站(如Yahoo!答案,Quora。这些线索包含的答案往往相互重叠或相互矛盾。在这项工作中,我们提出了一种基于结构注意力建模这种句子间和文档间依赖关系的层次编码器。我们将流行的指针-生成器体系结构及其派生的一些体系结构设置为基线,并说明它们无法在多文档设置中生成良好的摘要。我们进一步证明,我们提出的模型在单文档和多文档摘要设置方面都比基线有了显著的改进——在前一种设置中,它分别比CNN和CQA数据集上的最佳基线提高了1.31和7.8个ROUGE-1点;在后一种设置中,CQA数据集的性能进一步提高了1.6个ROUGE-1点。
成为VIP会员查看完整内容
相关内容
专知会员服务
33+阅读 · 2020年4月24日
Arxiv
5+阅读 · 2018年2月3日
相关VIP内容
专知会员服务
33+阅读 · 2020年4月24日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年2月3日