ICLR 2018 | CMU&谷歌大脑提出新型问答模型QANet:仅使用卷积和自注意力,性能大大优于RNN
选自arXiv
作者:Adams Wei Yu等
机器之心编译
参与:Geek AI、路
近日,来自卡内基梅隆大学和谷歌大脑的研究者在 arXiv 上发布论文,提出一种新型问答模型 QANet,该模型去除了该领域此前常用的循环神经网络部分,仅使用卷积和自注意力机制,性能大大优于此前最优的模型。
1 引言
人们对机器阅读理解和自动问答任务的兴趣与日俱增。在过去的几年中,端到端的模型在许多具有挑战性的数据集上显示出非常好的结果,取得了显著的进步。最成功的模型通常会利用两个关键的组成部分:(1)处理序列化输入的循环模型,(2)处理长期交互的注意力组件。Seo 等人(2016)提出的 Bidirectional Attention Flow(BiDAF)模型是这两部分的一个成功组合,该模型在 SQuAD 数据集(Rajpurkar 等人在 2016 年发布)上获得了很好的效果。这些模型有一个缺点,即由于它们的循环性质导致训练和推断都十分缓慢,特别是对于长文本来说。高昂的训练开销不仅导致了很长的实验周期,限制了研究者进行迅速的迭代,还妨碍了模型被用于大型数据集。与此同时,缓慢的推断阻碍了机器阅读理解系统在实时应用中的部署。
本论文中,为了使机器更迅速地进行理解,研究者提出去除这些模型的循环特性,仅使用卷积和自注意力机制作为构建编码器的模块,它们分别编码查询(query)和语境(context)。接着研究者通过标准的注意力机制来学习语境和问题之间的交互(Xiong et al., 2016; Seo et al., 2016; Bahdanau et al., 2015)。在最终解码出每个点作为答案区间的起始点和终点的概率之前,得到的数据表征被再一次用研究者提出的无循环特性(recurrency-free)的编码器进行编码。本论文研究者将这个架构称为 QANet,如图 1 所示。
该模型设计背后的关键动机是:卷积能够捕获文本的局部结构,而自注意力机制能够学习到每一对词语之间的全局相互作用。额外的「语境-查询」注意力机制是一个用于为上下文段落中的每一个位置构建 query-aware 语境向量的标准模块,这些向量将在随后的建模层中使用。该架构的前馈特性大大加快了模型的速度。在 SQuAD 数据集上进行的实验中,本论文提出的模型训练速度提升到相应 RNN 模型的 3 到 13 倍,推断速度提升到 4 到 9 倍。如果进行一个简单的对比,该模型可以在 3 小时训练时间内达到和 BiDAF 模型(Seo 等人在 2016 年提出)同样的准确率(77.0 F1 值),而后者则需要花费 15 小时。模型的加速还让研究者通过更多的迭代来训练模型,从而得到比其它有竞争力的模型更好的结果。例如,如果使本文提出的模型训练 18 个小时,则它会在开发集上获得 82.7 的 F1 值,这比 Seo 等人在 2016 年提出的模型好得多,并且与目前公布的最好结果达到了同等水平。
由于该模型运行速度很快,因此相较于其他模型,我们可以用多得多的数据训练它。为了进一步改进模型,研究者提出了一种补充性数据增强技术来改善训练数据。这种技术通过将原始的英文句子翻译成另一种语言然后再翻译回英语来改写例句,这不仅增加了训练实例的数量,还增强了措辞的多样性。
在 SQuAD 数据集上,用增强数据训练的 QANet 在测试集上获得了 84.6 的 F1 值,这相比 Hu 等人(2017)公布的最佳结果——81.8 有了很大提升。研究者还进行了模型简化测试(ablation test),来证明该模型中每一个组件的有效性。本论文的贡献如下:
提出了一种高效的阅读理解模型,它完全建立在卷积和自注意力机制之上。据了解,本论文作者是这项研究的开创者。这个组合(卷积和自注意力机制)保持了良好的准确率,同时与相应的 RNN 模型相比,在每一轮迭代中,该模型的训练速度最高达到前者的 13 倍,推断速度最高达到前者的 9 倍。速度提升使得该模型成为扩展到更大数据集的最佳候选方案。
为了在 SQuAD 数据集上提升训练结果,研究者提出了一种新的数据增强技术,通过改写句子来丰富训练数据。这使得 QANet 模型获得了比目前的最佳模型更高的准确率。
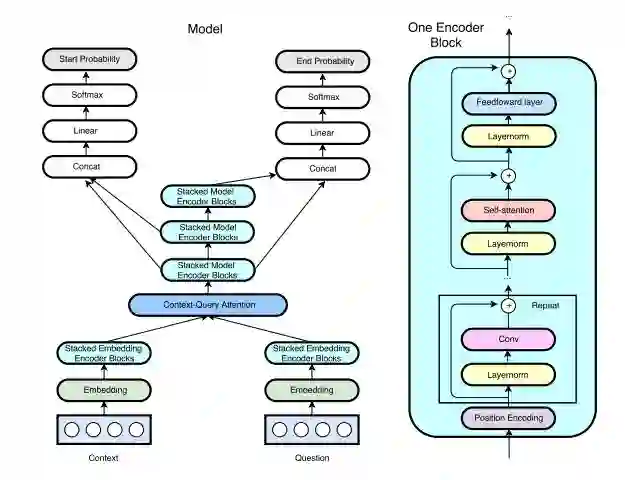
图 1:QANet 架构概览(左图),包含多个编码器模块。研究者在整个模型中使用相同的编码器模块(右图),仅仅在每个模块中改变卷积层的数量。研究者在编码器模块的每一层之间使用了层归一化和残差连接技术,还在语境和问题编码器以及三个输出编码器之间共享权重。研究者在每一个编码器层的起始处加入一个位置编码,正如 Vaswani 等人在 2017 年定义的那样,它是由波长不同的正弦函数和余弦函数组成的。编码器结构内部的位置编码后面的每一个子层(卷积、自注意力机制或前馈网络其中之一)都被包装在一个残差模块中。
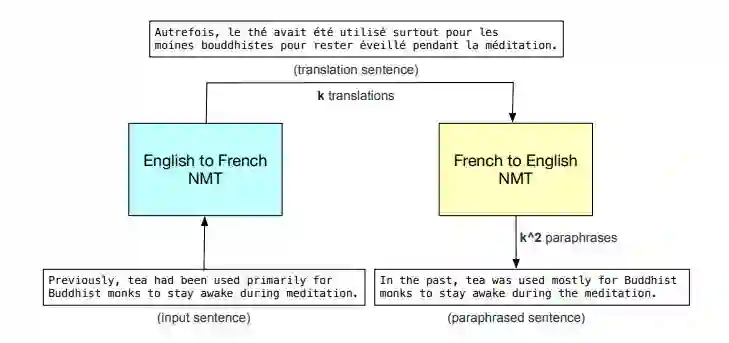
图 2:以法语作为中间语言(以 English-French-English 形式改写)的数据增强过程图示。其中,k 是集束宽度,即 NMT 系统生成的译文数量。

表 1:原句和改写后的句子中的答案对比。
4 实验
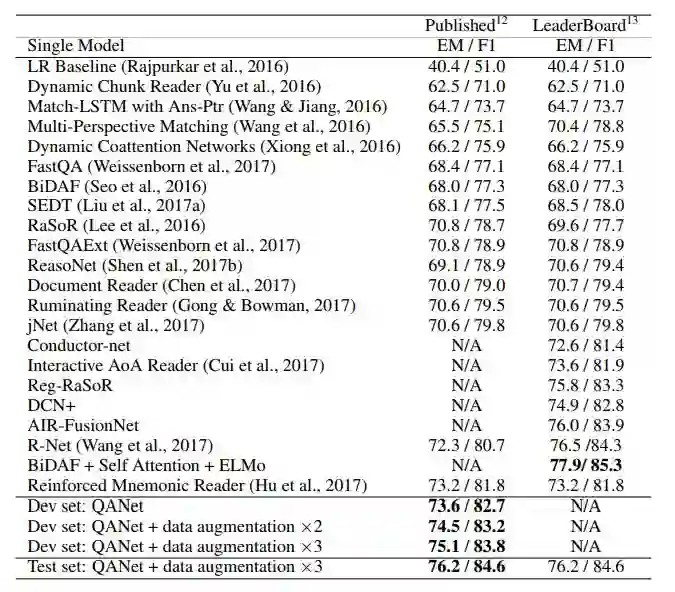
表 2:在 SQuAD 数据集上不同模型的性能。

表 3:QANet 模型和基于 RNN 的模型在 SQuAD 数据集上的运行速度对比,所有模型的批大小都是 32。「RNN-x-y」表示一个有 x 个层、每层包含 y 个隐藏单元的 RNN 网络。这里使用的 RNN 模型是双向 LSTM 模型。运行速度使用「批/秒」(batches/second)这个单位来衡量,值越高,速度越快。

表 4:QANet 模型和 BiDAF 模型(Seo et al., 2016)在 SQuAD 数据集上的速度对比。
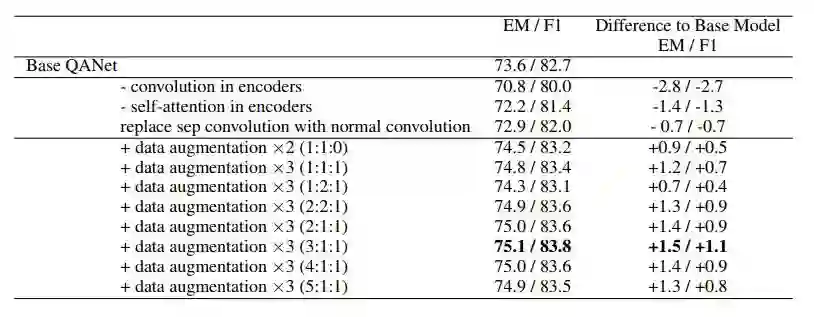
表 5:对数据增强和 QANet 模型中其它部分的模型简化测试。这里所展示的结果是在开发集上取得的。对于包含「data augmentation」条目的行,「×N」表示数据被增大到原始规模的 N 倍,而括号中的比率表示采样率,即原始数据、「英语-法语-英语」和「英语-德语-英语」数据的采样比例。
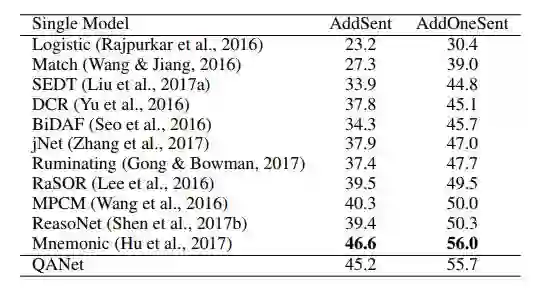
表 6:在 SQuAD 对抗样本测试集上的 F1 值。
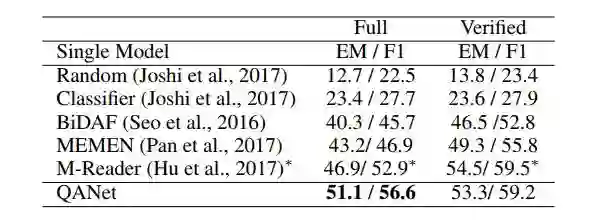
表 7:在 TriviaQA 数据集的 Wikipedia domain 上,不同的单段阅读模型在开发集上的性能。注:*表示测试集的结果。

表 8:QANet 模型和基于 RNN 的模型在 TriviaQA 维基百科数据集上的运行速度对比,所有的批大小都是 32。「RNN-x-y」表示一个有 x 个层、每层包含 y 个隐藏单元的 RNN 网络。这里使用的 RNN 是双向 LSTM。处理的速度以「批/秒」这个单位衡量,值越高,速度越快。
论文:QANET: COMBINING LOCAL CONVOLUTION WITH GLOBAL SELF-ATTENTION FOR READING COMPREHENSION

论文链接:https://openreview.net/pdf?id=B14TlG-RW
项目地址:https://github.com/hengruo/QANet-pytorch
摘要:目前的端到端机器阅读和问答(Q&A)模型主要基于带注意力机制的循环神经网络(RNN)。尽管它们取得了一定程度的成功,但由于 RNN 的序列特性,这些模型的训练速度和推断速度通常较慢。我们提出了一个名为 QANet 的新型问答系统框架,它不再需要循环网络:其编码器仅仅由卷积和自注意力机制构成,卷积可以对局部相互作用建模,而自注意力机制可以对全局相互作用建模。在 SQuAD 数据集上,QANet 模型的训练速度提升到对应的 RNN 模型的 3 到 13 倍、推断速度提升到 4 到 9 倍,并且取得了和循环模型同等的准确率。速度提升使得我们能够使用更多的数据训练模型。因此,我们将 QANet 模型和使用神经机器翻译模型回译得到的数据结合了起来。在 SQuAD 数据集上,我们使用增强的数据训练的模型在测试集上获得了 84.6 的 F1 值,这远远优于目前公开的最佳模型 81.8 的 F1 值。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




