谷歌全新神经网络架构Transformer:基于自注意力机制,擅长自然语言理解
选自Google Research Blog
近日,继论文《Attention Is All You Need》之后,谷歌在研究博客撰文对 Transformer 作了更详细的介绍。Transformer 是一个基于自注意力机制的全新神经网络架构,擅长处理语言理解任务,所需算力更少,进而把训练速度提升了一个数量级。此外,谷歌认为 Transformer 潜力巨大,它已被用于自然语言处理之外的图像和视频处理任务。
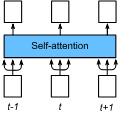
神经网络,尤其是循环神经网络(RNN),目前是处理自然语言理解任务(比如语言建模、机器翻译、问答)的核心方法。我们在论文《Attention Is All You Need》中介绍了 Transformer,一个基于自注意力机制的全新神经网络架构,我们相信它非常适合自然语言理解。
我们的论文表明,在学术性的英语转德语与英语转法语翻译基准方面,Transformer 性能优于循环与卷积神经网络。除却更高的翻译质量,Transformer 需要更少的训练算力,更适合现代机器学习硬件,并且把训练速度提升了一个数量级。

标准 WMT newstest2014 英语转德语翻译基准上单个模型的 BLEU 分值(越高越好)。

标准 WMT newstest2014 英语转法语翻译基准上单个模型的 BLEU 分值(越高越好)
自然语言理解的准确度与效率
神经网络通常通过生成固定或可变长度的向量空间表征来处理自然语言。从单个词汇或者甚至是词块表征开始,然后,集合周边字词的信息以确定语境中给定语言的意义。比如,确定语句「I arrived at the bank after crossing the…」中单词「bank」的最可能的意义与适当的表征,需要知道该语句的结尾是「... road.」还是「... river.」。
近年来,RNN 在翻译、从左到右或从右到左形式的序列性语言处理方面已上升为经典网络架构。一次读取一个单词迫使 RNN 执行多步操作以做出决策,这些决策依赖于彼此相距很远的单词。在上述的实例处理中,RNN 只能在读取完「bank」与「river」之间的每个单词之后,确定「bank」有可能是指河岸「the bank of a river」。先前的研究已表明,粗略来讲,这些决策需要的步骤越多,RNN 学习如何做出这些决策的困难就越大。
RNN 的序列性同样也使其全面利用现代快速的计算设备变的更加困难,比如 TPU 和 GPU(擅长并行计算而不是串行计算)。卷积神经网络(CNN)相较于 RNN 序列性更低,但是在 CNN 架构比如 ByteNet 或 ConvS2S 中,集合输入中较远部分的信息所需的步骤数量依然随着距离的增加而增加。
Transformer
相比之下,Transformer 仅执行固定数量的少量步骤(根据经验选择)。每一步里,Transformer 使用一个自注意力机制,该机制可对句子中所有单词之间的关系直接进行建模,而无需考虑各自的位置。在上述示例「I arrived at the bank after crossing the river」中,为了确定单词「bank」指的是河岸,不是银行,Transformer 需要学习立刻注意单词「river」,并在一步中作出决策。实际上,在我们的英法翻译模型中,我们明确地观察到了这一行为。
更具体来说,要计算给定单词(比如「bank」)的下一个表征,Transformer 要把该单词与句子中的其他单词一一对比。对比结果就是句子中其他单词的注意力分数。这些注意力分数决定其他单词对」bank」的新表征作出多少贡献。在该示例中,计算」bank」的新表征时,消歧单词」river」能够得到较高的注意力分数。之后,注意力分数用作所有单词表征的平均权重,这些表征输入全连接网络,以生成」bank」的新表征,该表征能够反映出这句话说的是河岸。
下面的动图展示了我们如何将 Transformer 应用到机器翻译中。机器翻译神经网络通常包括一个读取输入句子和生成句子表征的编码器。之后,解码器参考编码器生成的表征,逐词生成输出句子。Transformer 最初生成每个词的初始表征或嵌入,由空心圆表示。然后,Transformer 使用自注意力机制从其他单词处聚合信息,根据上下文的每一个单词生成新的表征,由实心圆表示。之后,这一步并行重复多次,连续生成所有单词的新表征。

解码器的操作与此类似,但是每次只按照从左到右的顺序生成一个单词。它不仅注意之前生成的单词,还会注意编码器生成的最终表征。
信息流
除了计算性能和更高的准确度,Transformer 另一个有意思的方面是我们能可视化网络关注句子的哪些其他部分,尤其是在处理或翻译一个给定词时,因此我们可以深入了解信息是如何通过网络传播的。
为了说明这一点,我们选择了一个对机器翻译系统来说十分具有挑战的任务,即指代消解(coreference resolution)。我们首先观察下面的英文句子及其法语译文:

很明显第一个语句中「it」指代的是动物,第二句中的「it」指代的是街道。当我们将该句子翻译为法语或德语时,「it」的翻译取决于它所指代名词的词性,而法语中「动物」和「街道」的词性是不同的。与目前谷歌翻译模型不同,Transformer 能将这些句子正确地翻译为法语。在计算单词「it」最后的表征时,可视化编码器注意的单词将有助于理解网络是如何做出决定的。在其中一个步骤中,Transformer 清楚地识别「it」可能指代的名词是什么,并且不同的注意力反映了系统在不同语境中的选择。

在英语到法语翻译训练中,单词「it」在 Transformer 第 5 层到第 6 层的编码器自注意力分布。
鉴于这种发现,Transformer 对经典语言分析任务也有十分优秀的性能,比如句法成分分析(syntactic constituency parsing)任务,这一在自然语言处理社区一直以高度专业化著称的任务。
实际上,只需要一点修改,相同的网络就可以应用于英语到德语的翻译,并且要胜过几乎所有前面提出的成分分析方法。
后续发展
我们对 Transformer 未来的潜力十分自信,并且已经开始将它应用于其它在自然语言处理之外的任务,如图像和视频处理等。Tensor2Tensor 库(谷歌最近的开源库)为我们的实验提供了极大的加速。实际上使用该软件库,我们通过少量命令迅速构建 Transformer 网络。
Tensor2Tensor 库 GitHub 地址:https://github.com/tensorflow/tensor2tensor/
原文链接:https://research.googleblog.com/2017/08/transformer-novel-neural-network.html