机器之心 & ArXiv Weekly Radiostation
参与:杜伟
本周的重要论文包括Yoshua Bengio 参与的两篇关于 Transformer 和神经模块结合共享工作区的研究论文,以及华为诺亚实验室提出的 Transformer-in-Transformer (TIN) 模型。
Self-Supervised Learning of Graph Neural Networks: A Unified Review
M6: A Chinese Multimodal PretrainerM6: A Chinese Multimodal Pretrainer
M6: A Chinese Multimodal Pretrainer
Coordination Among Neural Modules Through a Shared Global Workspace
Do Transformer Modifications Transfer Across Implementations and Applications?
Transformer in Transformer
Self-supervised Pretraining of Visual Features in the Wild
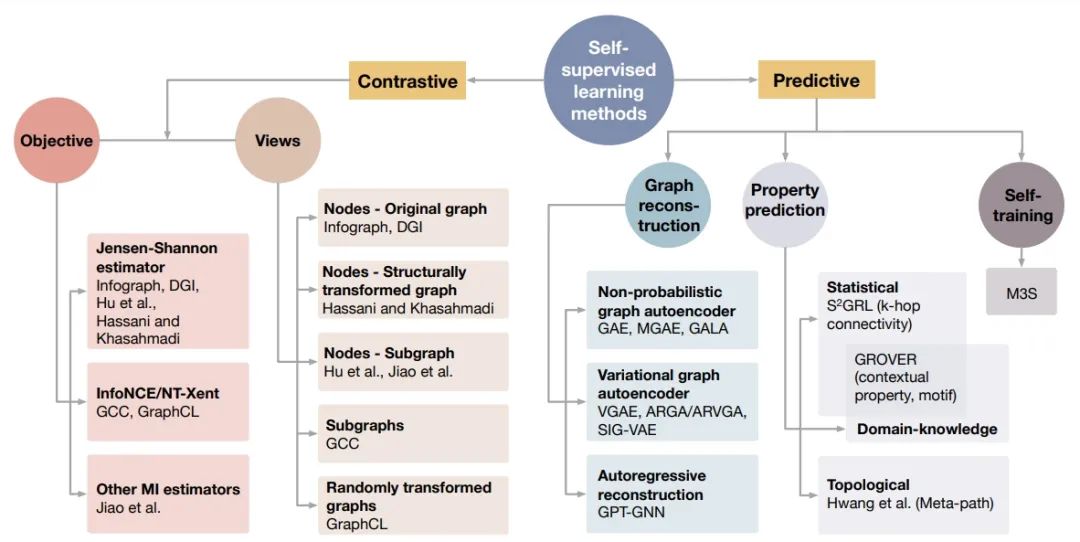
论文 1:Self-Supervised Learning of Graph Neural Networks: A Unified Review
摘要:
监督模式下训练的深度模型在多种多样的任务上已经取得了显著的成功。当标签样本有限时,自监督学习( SSL)能够成为利用大量标签样本的新范式。SSL 在自然语言和图像学习任务上实现了非常不错的性能。最近出现了一种研究趋势,将这一成功扩展至了使用图神经网络(GNN)的图数据上。
在本文中,来自
德州农工大学和亚马逊的几位研究者对使用 SSL 来训练 GNN 的不同方法进行了回顾
。具体而言,他们将 SSL 方法分类为对比和预测模型。在每个类别中,研究者为所有方法提供了统一的框架,以及该框架下这些方法在每个组件中的不同之处。这种对 GNN 的自监督学习方法的统一性处理揭示了各种方法的异同,为开发新方法和新算法奠定了基础。此外,研究者还总结了不同的 SSL 设置以及每个设置下使用的数据集。最后,为了促进方法学进展和实证比较,他们为 GNN 中的 SSL 开发了一个标准化测试平台,包括常见基线方法、数据集和评估指标的实现。
![]()
![]()
![]()
推荐:
德州农工大学副教授姬水旺(Shuiwang Ji)等学者撰写的一篇非常详尽的 GNN 中自监督学习的研究综述。
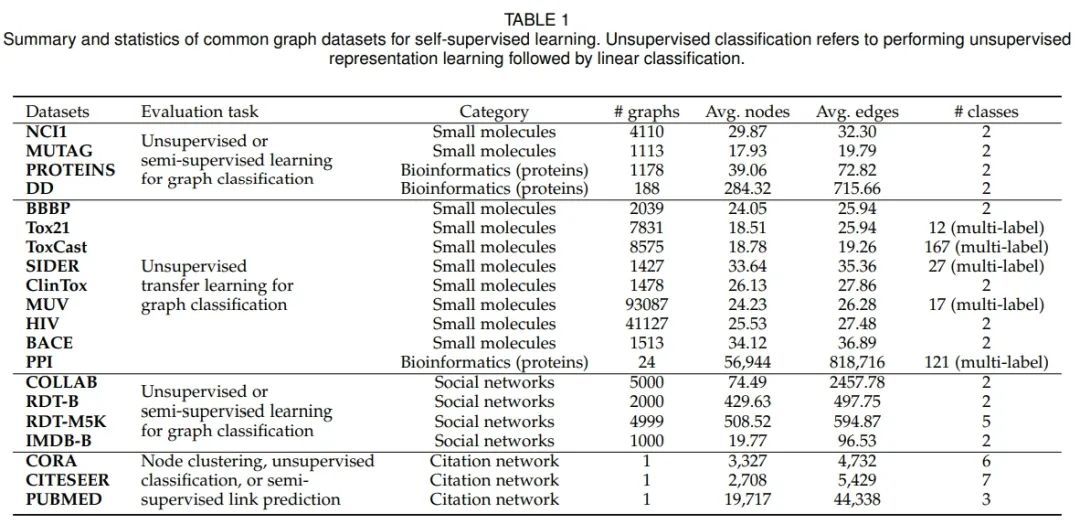
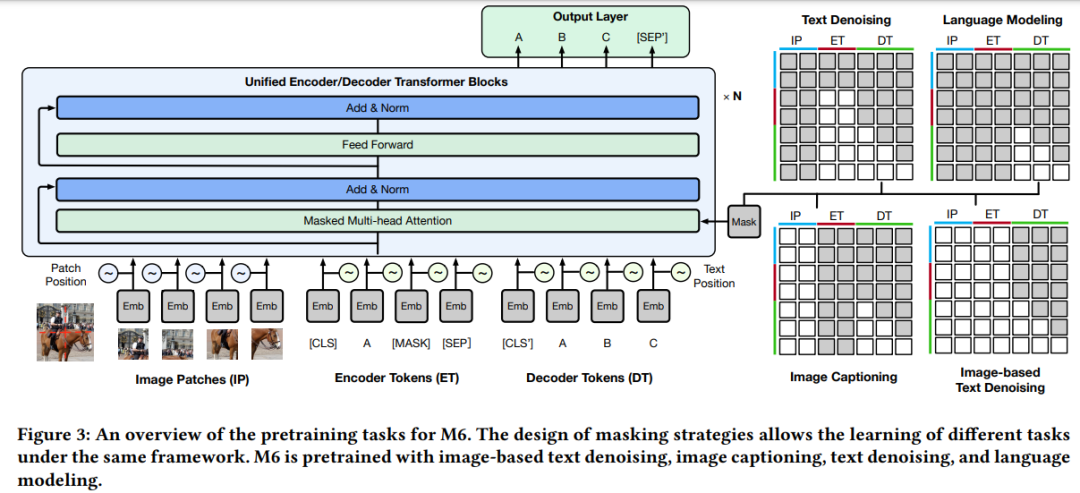
论文 2:M6: A Chinese Multimodal Pretrainer
摘要:
在这篇论文中,
来自阿里巴巴和清华大学的 25 位研究者构建了规模最大的中文多模态预训练数据集,其中包含众多领域的超过 1.9 TB 图像和 292 GB 文本
。具体而言,他们提出了一种被称为 M6 的跨模态预训练方法,将多模态转换为多模态多任务 Mega-transformer,以便对单模态和多模态的数据进行统一的预训练。研究者将模型的大小扩展到 100 亿和 1000 亿个参数,并建立了规模最大的中文预训练模型。他们将该模型应用于一系列下游应用,并展示了其与强基准相比的出色性能。此外,研究者还专门设计了文本引导(text-guided)图像生成的下游任务,并展示了经过微调的 M6 方法可以创建具有高分辨率和丰富细节的高质量图像。
![]()
![]()
![]()
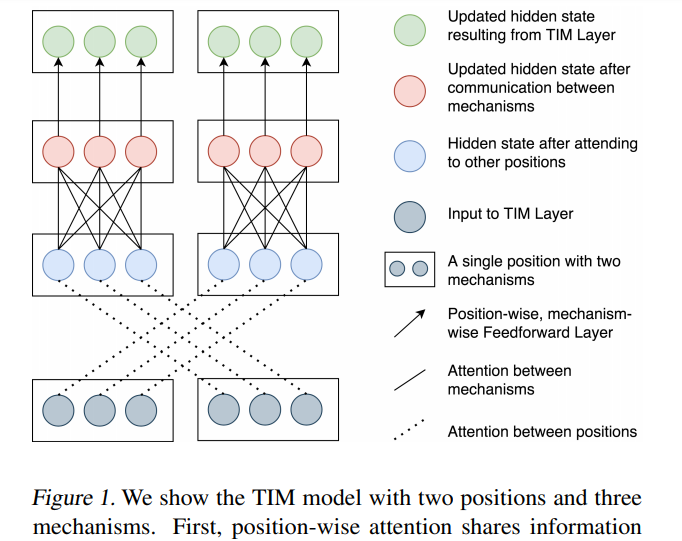
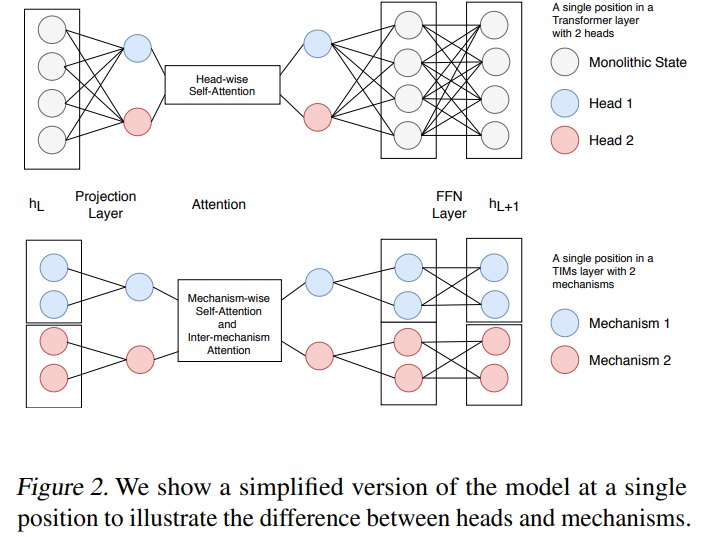
论文 3:Transformers with Competitive Ensembles of Independent Mechanisms
摘要:
在这篇论文中,来自加拿大蒙特利尔学习算法研究所(Mila)和微软亚研等机构的学者发现 Transformer 架构有时会表现出缺陷:它利用大型全集成隐藏表征和适用于整体隐藏表征的单个参数集合来表征每个位置。这种做法有可能将不相关的信息源结合在一起,并限制 Transformer 捕捉独立机制的能力。
为了解决这一问题,研究者提出了
Transformers with Independent Mechanism (TIM)
。这种新的 Transformer 层将隐藏表征和参数分割成多个机制,这些机制仅通过注意力交换信息。此外,研究者还提出了一种
竞争机制
,可以激励上述分割而成的机制随着时间步的推移更加专门化,并因而更加独立。研究者在大型 BERT 模型、Image Transformer 和语音增强上研究了 TIM,结果发现这种新的 Transformer 层可以实现语义上有意义的专业化和性能的提升。
![]()
该研究提出的具有 2 个位置(position)和 3 个机制(mechanism)的 TIM 模型。
![]()
![]()
研究者在 Image Transformer 上训练了 TIM 模型。
推荐:
Yoshua Bengio 等提出的 TIM 模型通过将隐藏表征和层分割成多个机制,有可能实现更加动态化的 Transformer。
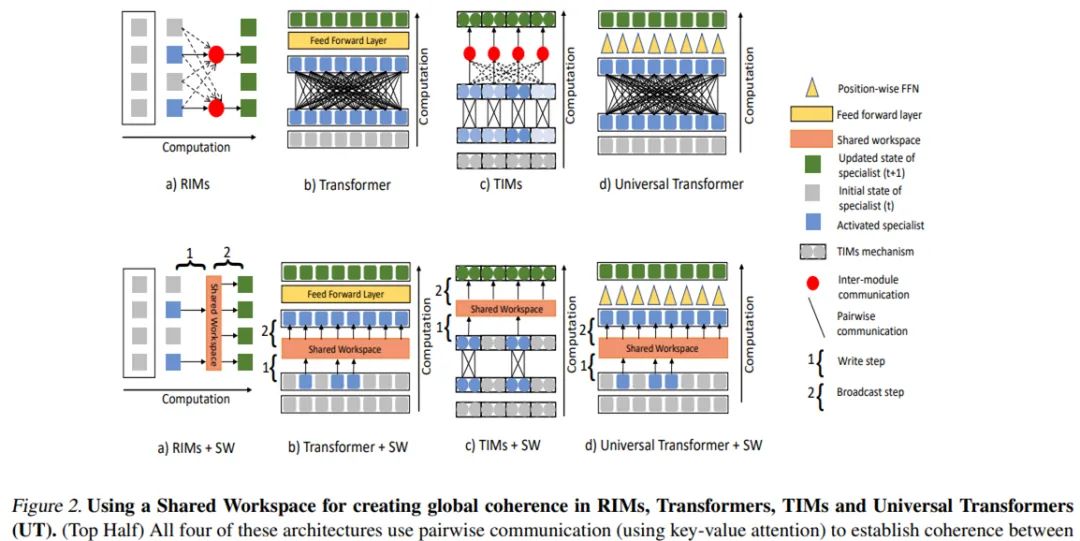
论文 4:Coordination Among Neural Modules Through a Shared Global Workspace
摘要:
深度学习已经从利用全集成隐藏状态表征示例向丰富的结构化状态转变。举例而言,基于位置的 Transformer 分割以及以目标为中心的架构将图像解耦成实体。在这些架构中,不同要素之间的交互通过配对交互进行建模:Transformer 使用自注意力集成其他位置的信息;以目标为中心的架构使用图神经网络建模实体之间的交互。然而,配对交互可能无法实现全局协调或者可用于下游任务的连贯完整表征。认知科学领域已经提出了全局工作区结构,其中功能专门化的组件通过一个常见的限制带宽的通信信道来共享信息。
在本文中,来自加拿大 Mila、DeepMind 和谷歌大脑的研究者探索了这类通信信道在深度学习场景中建模复杂环境结构的应用。他们提出了
一种共享工作区(Shared Workspace, SW)模型,借此可以实现不同专用模块之间的通信
。在预测和视觉推理任务上的实验表明了模块化与共享工作区的结合能够带来益处。
![]()
使用共享工作区在 RIM (Recurrent Independent Mechamism)、Transformer 和 Universal Transformer (UT) 中创建全局一致性。
![]()
![]()
利用 TIM (Transformers with Independent Mechanism) 的共享工作区集成算法。
推荐:
神经模块与共享全局工作区的跨领域协同研究。
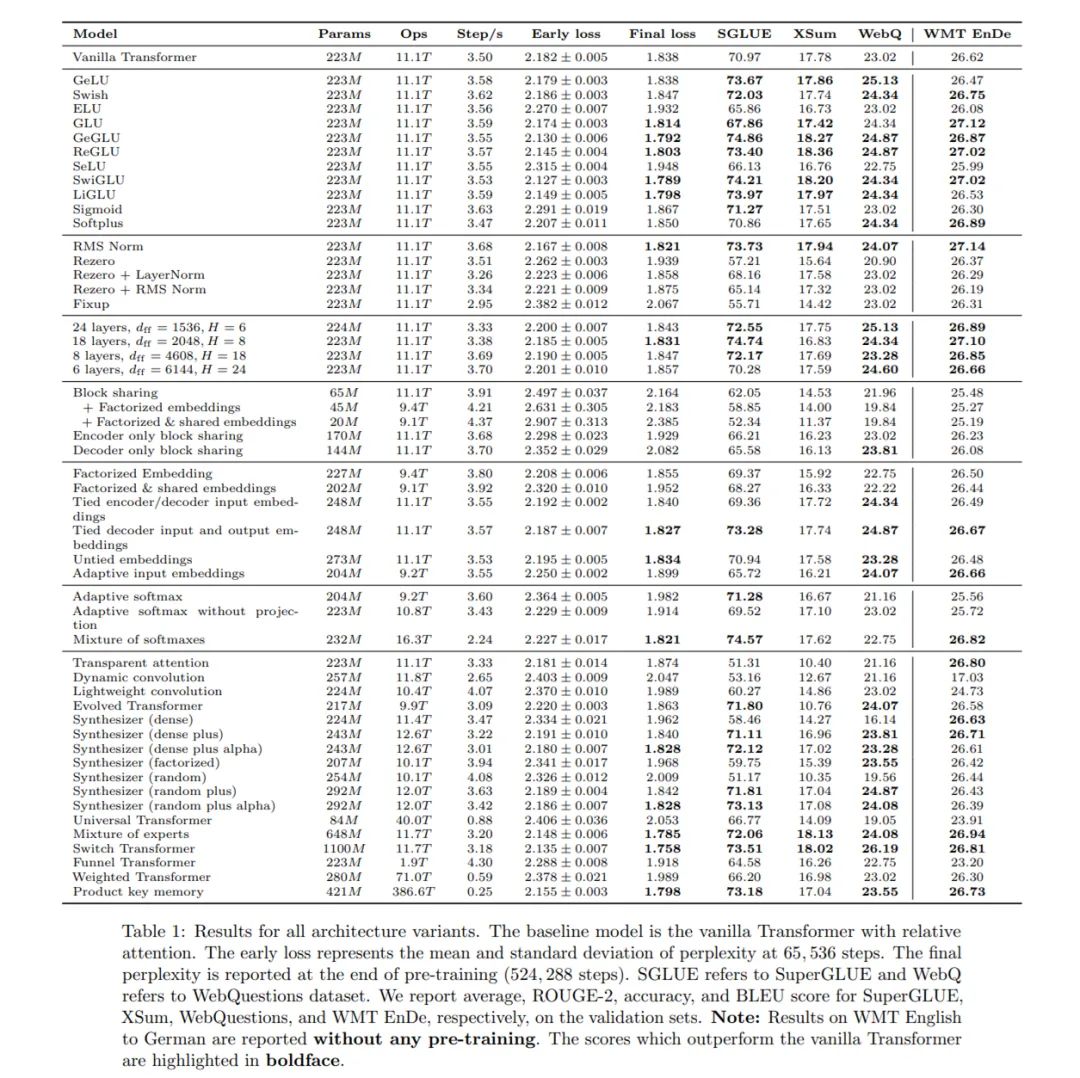
论文 5:Do Transformer Modifications Transfer Across Implementations and Applications?
摘要:
自 2017 年 Transformer 问世以来,研究社区已经该架构提出了大量的修改,但得到广泛采用的却很少。在这篇论文中,来自谷歌研究院的十数位研究者在包含 NLP 领域大多数常见 Transformer 用例的共享实验设置下对很多修改进行了全面评估。实验结果发现,大多数修改无法有效地提升性能。此外,他们还发现,大多数有益的 Transformer 变体要么是在相同的代码库中开发,要么变化很小。研究者推测,
性能的提升可能在很大程度上依赖实现细节,并相应地提出了一些提升实验结果通用性的建议
。
![]()
所有基于原始 Transformer 架构的变体模型结果。
推荐:
对原始 Transformer 架构进行修改就能提升性能吗?这篇论文的结论是,未必
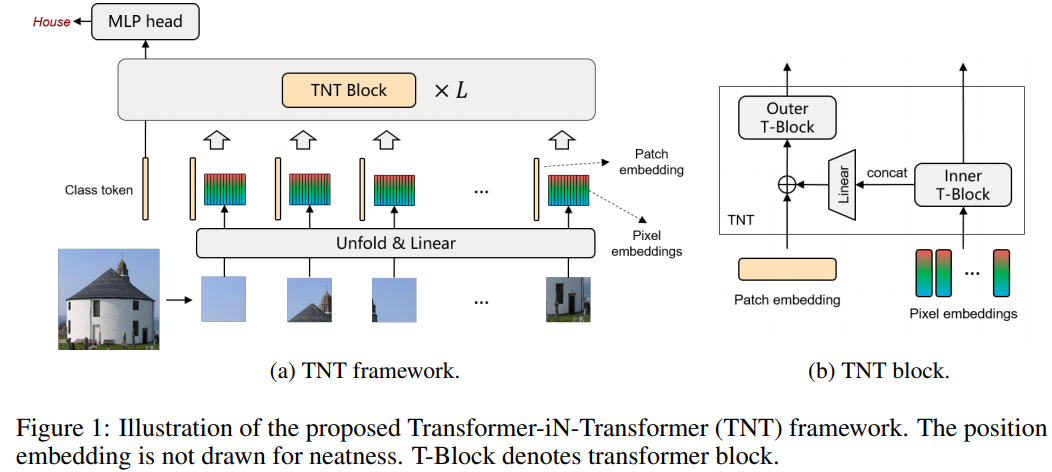
论文 6:Transformer in Transformer
摘要:
在这篇论文中,来自华为诺亚实验室的研究者提出
一种用于基于结构嵌套的 Transformer 结构,被称为 Transformer-iN-Transformer (TNT) 架构
。同样地,TNT 将图像切块,构成 Patch 序列。不过,TNT 不把 Patch 拉直为向量,而是将 Patch 看作像素(组)的序列。
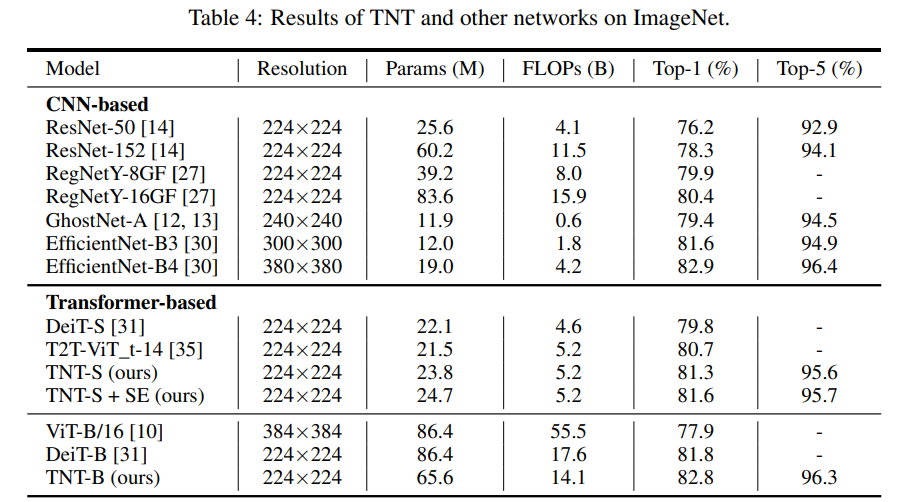
具体而言,新提出的 TNT block 使用一个外 Transformer block 来对 patch 之间的关系进行建模,用一个内 Transformer block 来对像素之间的关系进行建模。通过 TNT 结构,研究者既保留了 patch 层面的信息提取,又做到了像素层面的信息提取,从而能够显著提升模型对局部结构的建模能力,提升模型的识别效果。在 ImageNet 基准测试和下游任务上的实验均表明了该方法在精度和计算复杂度方面的优越性。例如, TNT-S 仅用 5.2B FLOPs 就达到了 81.3% 的 ImageNet top-1 正确率,这比计算量相近的 DeiT 高出了 1.5%。
![]()
![]()
![]()
ImageNet 数据集上 TNT 与其他网络的对比结果。
推荐:
表现优于 ViT 和 DeiT,华为利用内外 Transformer 块构建新型视觉骨干模型 TNT。
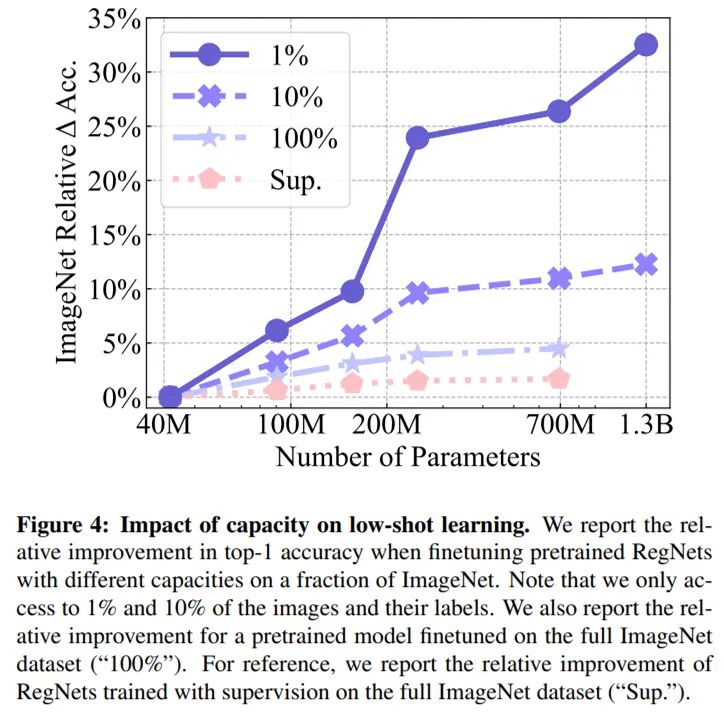
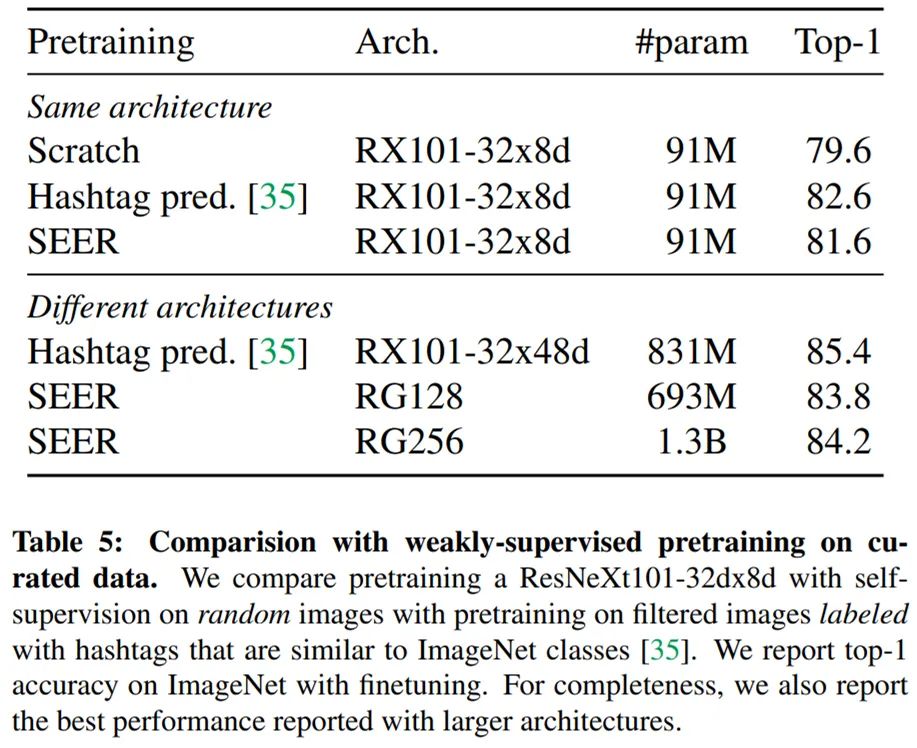
论文 7:Self-supervised Pretraining of Visual Features in the Wild
摘要:
最近,MoCo、SimCLR、BYOL 和 SwAV 等自监督学习方法已经缩小了与监督学习方法的差距。这些结果在可控制环境中实现,即精心制作的 ImageNet 数据集。然而,自监督学习的前提是它可以从任何随机图像和任何无边界数据集中学习。在本文中,来自 FAIR 的研究者在无监督情况下,通过在随机、未精心制作图像上训练大型模型来探索自监督是否能够达到预期效果。他们提出的
SElf-supERvised (SEER) 模型拥有 13 亿参数,并使用 512 块 GPU 在 10 亿张随机图像上进行训练,最终实现了 84.2% 的 top-1 准确率,较当前 SOTA 自监督预训练模型提升了 1%
,并证实自监督学习可以在实际设置下运行。此外, 有趣的一点是,研究者发现,自监督模型是很好的少样本学习器,实现了 77.9 的 top-1 准确率。
![]()
ImageNet 数据集上,SEER 与 SwAV、SimCLRv2、ViT 等大型预训练模型的性能曲线。
![]()
性能对小样本学习(low-shot learning)的影响。
![]()
推荐:
FacebookAI 最新视觉自监督 SOTA 模型,参数量达 13 亿
![]()