GLUE排行榜上全面超越BERT的模型近日公布了!
选自arXiv
作者:Xiaodong Liu
机器之心编译
参与:贾伟
在通用语言理解评估(GLUE)基准中,自 BERT 打破所有 11 项 NLP 的记录后,可应用于广泛任务的 NLP 预训练模型得到了大量关注。2018 年底,机器之心介绍了微软提交的综合性多任务 NLU 模型,它在 11 项 NLP 任务中有 9 项超越了 BERT,近日微软公布论文介绍了这种名为 MT-DNN 的多任务模型。
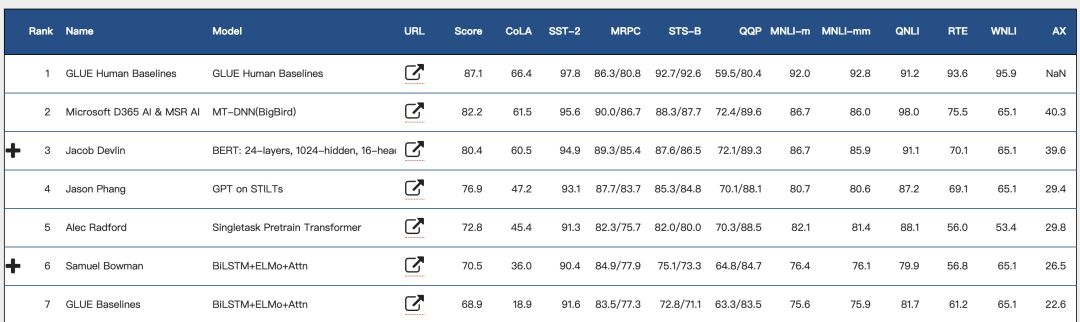
当前 GLUE 排行榜(2019.02.12)
GLUE 榜单链接:https://gluebenchmark.com/leaderboard
学习文本(例如单词和句子)的向量空间表示是许多自然语言理解(NLU)任务的基础。目前有两种流行的方法,分别是多任务学习和语言模型预训练。
人类学习活动中经常用先前任务中学习到的知识来帮助学习新的任务,多任务学习(MTL)正是有这样的优点。最近人们越来越关注将 MTL 应用到使用深度神经网络(DNN)的表示学习中,其原因是:首先,DNN 的监督学习需要大量特定任务的标记数据,但这些数据并不总是可用的,MTL 提供了一种有效的方法利用来自其他相关任务的监督数据;其次,使用 MTL 可以减轻对特定任务的过拟合,从而能够使得学习到的表示在不同的任务中通用。
而另一方面,最近以 BERT 为代表的预训练方法对模型性能的提升已经有目共睹。来自微软的数位研究人员认为 MTL 和语言模型预训练是互补的技术,因此可以结合起来改进文本表示的学习,从而提高各种 NLU 任务的性能。
他们将 2015 年做的一项多任务深度神经网络(MT-DNN)模型加以拓展,将 BERT 合并到模型的共享文本编码层。
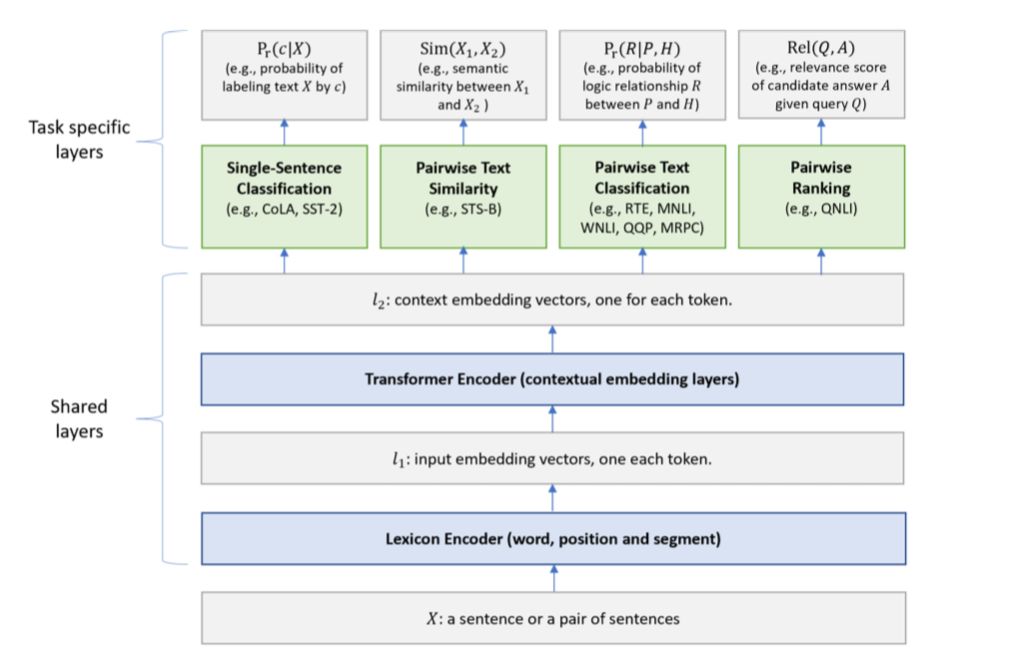
如图所示,较低层(即文本编码层)在所有任务中共享,而顶层是任务特定的,组合不同类型的 NLU 任务,如单句分类、成对文本分类、文本相似性和相关性排序。与 BERT 模型类似,MT-DNN 分两个阶段进行训练:预训练和微调。与 BERT 不同的是,MT-DNN 在微调阶段使用 MTL,在其模型架构中具有多个任务特定层。
作者将其改进后的 MT-DNN 模型在通用语言理解模型(GLUE)基准测试中使用的 9 个 NLU 任务中,其中的 8 个获得了最好的结果,将 GLUE 的基线分数推至 82.2%(超过 BERT 1.8%)。此外,作者还进一步将改进的模型应用于 SNLI 和 SciTail 任务中,在前一个任务中获得了 91.1% 的准确率,在后者准确率则达到 94.1%,分别优于先前的最先进性能 1.0%和 5.8%,尽管使用的训练数据只有 0.1% 和 1.0%。这些都足以说明 MT-DNN 结合预训练后其泛化能力得到了大大的提升。

论文链接:https://arxiv.org/pdf/1901.11504.pdf
摘要:在此论文中,我们提出了在多种自然语言理解任务上学习表征的多任务深度神经网络(MT-DNN)。MT-DNN 不仅能利用大量跨任务数据,同时还能利用正则化的优势构建更一般的表征,使得它能够适用于新的任务和领域。通过结合预训练的双向 Transformer 语言模型(BERT, Devlin et al., 2018),MT-DNN 扩展了 Liu et al. (2015) 提出的模型。MT-DNN 在 10 个 NLU 任务上获得了新的当前最优结果,包括 SNLI、SciTail 和另外 9 个 GLUE 基准任务中的 8 个,MT-DNN 将 GLUE 基准总体评分推升至 82.2%(1.8% 的绝对提升)。我们还表示使用 SNLI 和 SciTail 数据集,MT-DNN 学习到的表征能允许实现更高效的领域自适应。即相比于预训练的 BERT,预训练 MT-DNN 需要的领域标注数据少得多。我们的预训练模型和代码很快都将公开发布。
3.MT-DNN 模型
MT-DNN 模型的架构如下图 1 所示。下面几层在所有的任务中共享,上面的几层表示特定任务输出。
单词序列(可以是一句话或者打包在一起的句子对)作为输入 X,先表示为一个嵌入向量序列,其中 l_1 中一个向量对应一个单词。然后 Transformer 编码器通过自注意机制捕捉每个单词的语境信息,在 l_2 中生成语境嵌入序列。这就是我们的多任务目标函数训练得到的共享语义表征。
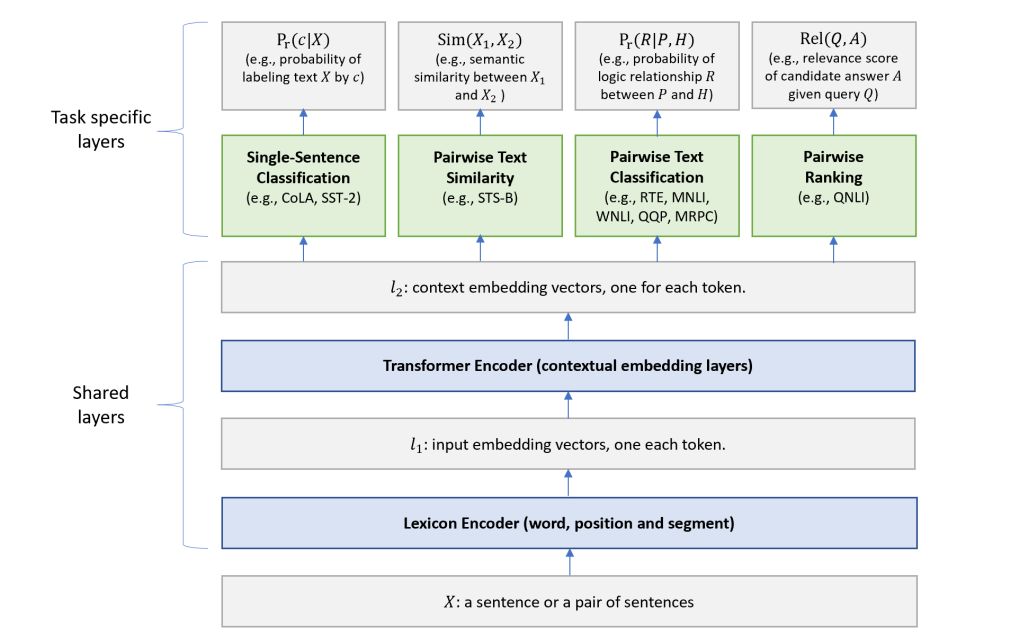
图 1:表征学习 MT-DNN 模型的架构。下面的网络层在所有任务中都共享,上面的两层是针对特定任务。输入 X(一句话或句子对)首先表征为一个序列的嵌入向量,在 l_1 中每个词对应一个向量。然后 Transformer 编码器捕捉每个单词的语境信息并在 l_2 中生成共享的语境嵌入向量。最后,针对每个任务,特定任务层生成特定任务的表征,而后是分类、相似性打分、关联排序等必需的操作。
3.1 训练程序
MT-DNN 的训练程序包含两个阶段:预训练和多任务精调。预训练阶段遵循 BERT 模型的方式。词汇编码器和 Transformer 编码器的参数使用两个无监督预测任务学习:掩码语言建模和下一句预测。
在多任务精调阶段,我们使用基于 minibatch 的随机梯度下降(SGD)来学习模型参数(也就是,所有共享层和任务特定层的参数),如下图算法 1 所示。

4. 实验
我们在 GLUE、斯坦福自然语言推理(SNLI)和 SciTail 三个流行的自然语言理解基准上评估了 MT-DNN。我们对比了 MT-DNN 与现有的包括 BERT 在内的 SOTA 模型,在 GLUE 上证明了 MTL 进行模型精调的有效性,在 SNLI 和 SciTail 上证明了 MTL 的领域适应性。
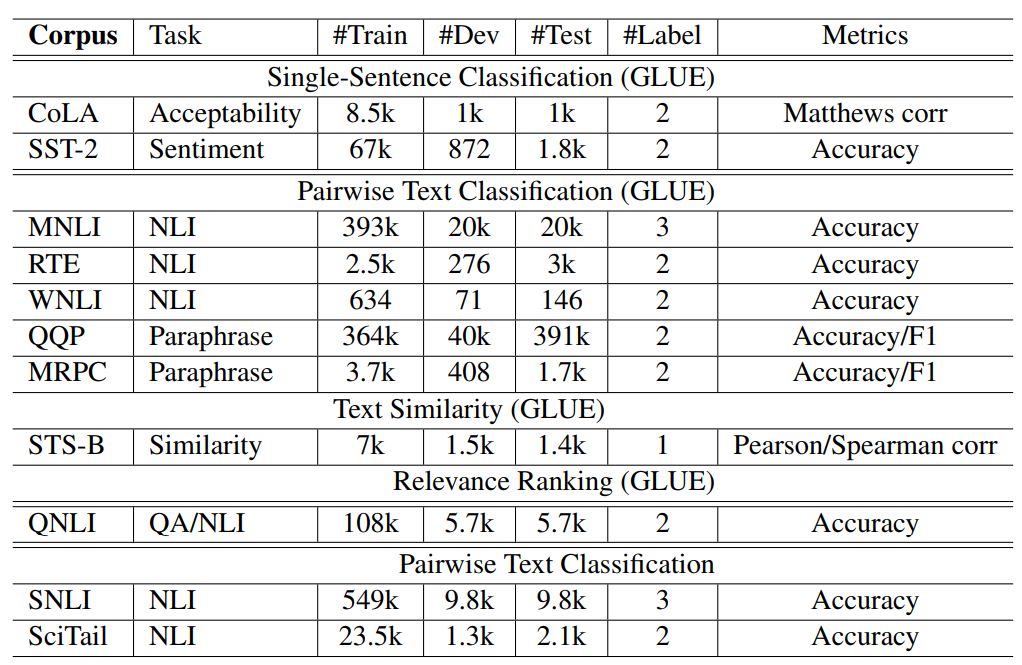
表 1:三个基准总结:GLUE、SNLI 和 SciTail。
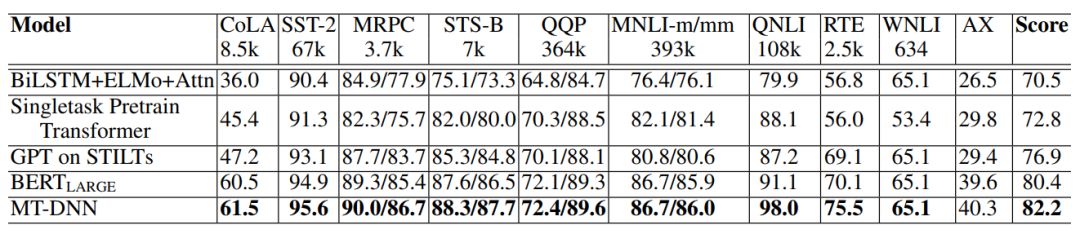
表 2:GLUE 测试集结果,通过 GLUE 评估服务器进行评分。每个任务下的数值表示训练样本的数量。SOTA 结果做了加粗显示。MT-DNN 使用 BERTLARGE 作为共享层。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com
