图神经网络的ImageNet?斯坦福大学等开源百万量级OGB基准测试数据集
机器之心原创
作者:思、一鸣
在满是「MNIST」这样的小数据里,图神经网络也需要「ImageNet」这样的大基准?近日,斯坦福大学的 Jure Leskovec 教授在 NeurlPS 2019 大会演讲中宣布开源 Open Graph Benchmark,这是迈向图神经网络建模统一基准的重要一步。
图神经网络是近来发展较快的机器学习分支领域。通过将非结构数据转换为结构化的节点和边的图,然后采用图神经网络进行学习,往往能够取得更好的效果。
然而,图神经网络发展到现在,尚无一个公认的基准测试数据集。许多论文采用的方法往往是针对较小的、缺乏节点和边特征的数据集上进行的。因此,在这些数据集上取得的模型性能很难说是最好的,也不一定可靠,这对进一步发展造成阻碍。
在 NeurlPS 2019 大会的图表示学习演讲中,Jure Leskovec 宣布开源图神经网络的通用性能评价基准数据集 OGB(Open Graph Benchmark)。通过这一数据集,可以更好地评估模型性能等方面的指标。
项目地址:http://ogb.stanford.edu
图表示学习演讲合集:https://slideslive.com/38921872/graph-representation-learning-3

本次演讲的嘉宾为 Jure Leskovec,是斯坦福大学计算机科学的副教授。他主要的研究兴趣是社会信息网络的挖掘和建模等,特别是针对大规模数据、网络和媒体数据。
值得注意的是,OGB 数据集也支持了 PYG 和 DGL 这两个常用的图神经网络框架。DGL 项目的发起人之一、AWS 上海 AI 研究院院长,上海纽约大学张峥教授(学术休假中)说:「现阶段,我认为 OGB 的最大作用是促成学界走出玩具型数据集。一个统一的、更复杂、更多样的数据集会使得研究人员重新聚集力量,虽然还会有模型过拟合标准数据集带来的弊端,但对提升模型和算法效果、提高 DGL 等平台的能力有着重要作用。」
张峥教授表示,Open Graph Benchmark 这种多样与统一的基准,对于图神经网络来说,是非常有必要的一步。
首个统一的图神经网络开放基准
在演讲中,Jure Leskovec 表示,目前常用的节点分类数据集也有 2k~3k 个节点,4k 到 5k 条边,这实在是太小了。我们急需一种多样性、具有挑战性,且同时又非常接近真实业务的数据基准。
Open Graph Benchmark 就是这样背景下提出的一项工作,它包含了各种图数据、加载与处理图数据的代码库,以及度量图模型的代码库。整个实验流程,研究者只需要关注最核心的模型搭建就可以了,剩下的都可以交给 Open Graph Benchmark。
如下是 Jure Leskovec 在 NeurIPS 研讨会上介绍的 OGB:
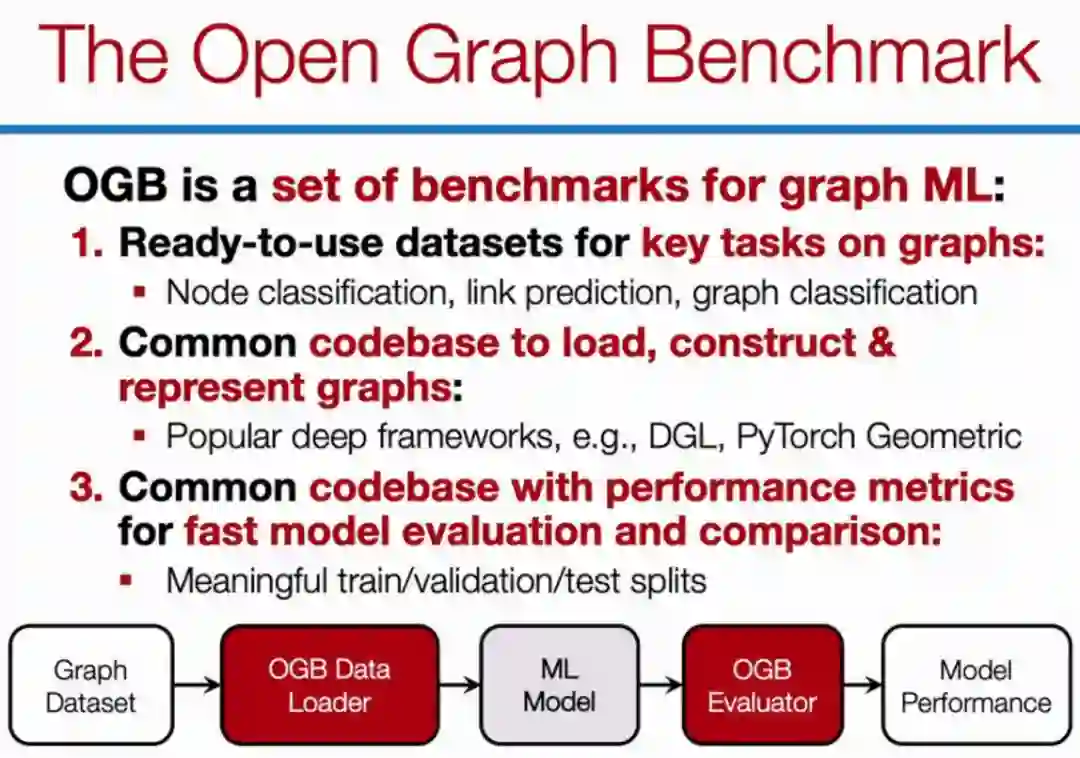
OGB 能支持 PyG 和 DGL 等主流图神经网络框架,也能支持新颖的数据集切分。其中在图神经网络中,数据集的切分特别重要,它和一般的机器学习任务有很大的不同。
「我认为随着研究的发展,OGB 还会继续滚动,目前它类似于视觉领域的 CIFAR。」,张峥教授说:「OGB 数据在异构图的占比还太小,任务局限在点、边、图的分类,而在图上做推理、时间这个重要的维度等都还没有考虑。总之,我期待 OGB 还有非常大的发展空间。」
OGB 的数据是什么
毕竟是一个基准测试数据集,OGB 的数据自然是重中之重。根据官网提供的资料,OGB 的数据按照任务要求分为以下几类:
节点预测;
连接预测(边)预测;
图预测;
以下为每个任务中包含的数据集:
节点预测
odbn-proteins:蛋白质数据集,有着蛋白质之间的关联网络,而且包括了多种生物;
odbn-wiki:维基百科数据形成的网络;
ogbn-products:亚马逊客户同时购买的商品的网络。
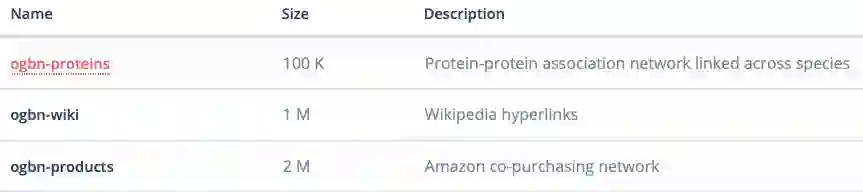
目前该基准测试所包含的数据集。
从数据集的类型来看,涵盖了现有的几大需要图表示学习的领域:生物学/分子化学、自然语言处理,以及商品推荐系统网络等。此外,这些图数据的量也非常大。例如,ogbn-wiki 的数据量已达到百万级别(节点),而最小的 ogbn-proteins 也有 100K 了。这和之前的很多图数据相比都显得更加庞大,因此也能更好地评价模型的性能表现。
连接预测
连接预测中的数据集则更多一些,包括:
ogbi-ddi:药物相互作用网络;
ogbi-biomed:人类生物医药知识图谱;
ogbi-ppa:蛋白质之间的关系网络;
ogbi-reviews:亚马逊的用户-商品评论数据集;
ogbi-citations:微软学术的引用关系网络图谱。
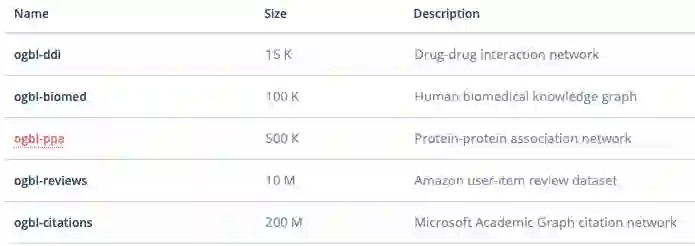
相比节点数据集来说,连接预测的数据集更多一些,类型也更为多样。
图预测
OGB 同时也提供了对图进行预测的任务数据集,分别有:
ogbg-mol:对分子进行预测,来自 MoleculeNet;
ogbg-code:代码段的语法树结构网络;
ogbg-ppi:蛋白质之间的交互网络;
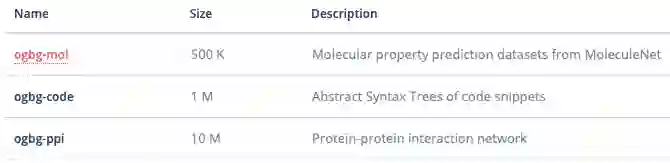
从总体来看,数据集中偏向医药和生物的数据集很多。张峥教授认为,这可能有两个原因,首先是项目主导者 Jure 等在这一领域做了比较多的工作,因此推动这些数据集开源顺理成章。另一个原因是药分子的图数据相对干净,噪声少。而药品的结构是 3D 的,可能需要比较复杂、层数更深的模型解决相关的问题。
对于未来会有哪些数据集加入,张教授认为现在关于异构图的数据还不够多,而现实中的很多数据都是异构图表示的。但是,OGB 的作用依然明显,它能够很好地提升开源图神经网络框架的能力,推动开源社区集中力量解决实际问题。
另外,OGB 数据集中缺少金融、征信等领域的数据集,特别是反欺诈类的。这可能是因为反欺诈数据集脱敏后特征丢失过多的问题所致,但瑕不掩瑜,OGB 无疑帮助图神经网络脱离了所谓的「玩具模型」阶段,开始逐渐进入工业应用。
数据加载与评估
OGB 如此庞大的数据量需要专门的代码进行提取。据悉,所有开源的数据集都可以用特定的代码进行提取和加载,使用过程和深度学习框架中的 data_loader 相似。不过在使用前,我们还需要简单地使用「pip install ogb」完成安装。目前 OGB 库主要依赖于 PyTorch、NumPy 和 Scikit-Learn 等常用建模库,当然图神经网络库也可以自由选择 DGL 或 PyTorch Geometric。
DGL:https://github.com/dmlc/dgl
PyG:https://github.com/rusty1s/pytorch_geometric
现在以节点预测为例,OGB 同时支持 PYG 和 DGL 两个图表示学习框架中的数据加载方法,加载代码如下:
1. PYG
from ogb.nodeproppred.dataset_pyg import PygNodePropPredDatasetdataset = PygNodePropPredDataset(name = d_name)num_tasks = dataset.num_tasks # obtaining number of prediction tasks in a datasetsplitted_idx = dataset.get_idx_split()train_idx, valid_idx, test_idx = splitted_idx["train"], splitted_idx["valid"], splitted_idx["test"]graph = dataset[0] # pyg graph object
2. DGL
from ogb.nodeproppred.dataset_dgl import DglNodePropPredDatasetdataset = DglNodePropPredDataset(name = d_name)num_tasks = dataset.num_tasks # obtaining number of prediction tasks in a datasetsplitted_idx = dataset.get_idx_split()train_idx, valid_idx, test_idx = splitted_idx["train"], splitted_idx["valid"], splitted_idx["test"]graph, label = dataset[0] # graph: dgl graph object, label: torch tensor of shape (num_nodes, num_tasks)
可以看出,代码非常简单,使用简便。其中「d_name」可以被替换成任何一个数据集的名字。
同时,项目提供了一些示例代码,以对每个数据集进行评估。如下所示:
from ogb.nodeproppred import Evaluatorevaluator = Evaluator(name = d_name)print(evaluator.expected_input_format)print(evaluator.expected_output_format)
这里,用户可以了解到针对这一数据集的输入和输出的特定格式。
然后,用户可以将输入字典(input dictionary)传递进评估器中,了解实际的性能:
In most cases, input_dict isinput_dict = {"y_true": y_true, "y_pred": y_pred}result_dict = evaluator.eval(input_dict)
据悉,OGB 官方已指明上海 AWS AI 研究院主打的开源框架 DGL 作为数据导入的平台之一。目前 DGL 兼容 PyTorch、MxNet 作为后端引擎,TensorFlow 也在开发中。实际上 DGL 在异构图和可扩展性已经做了很久,因此下一步可能会和 OGB 在相关领域进行新的技术结合,推动开源框架的发展。
张峥说:「DGL 目前在制药领域已有了一个效果不错的模型库,有了 OGB 数据集对模型库进行迭代,之后应当可以进一步提升。」
为什么说分割图数据是个问题?
在 Jure Leskovec 的演讲中,他特意强调了 OGB 所采用的数据分割方法,它能构建更合理的评估方案。他表示,似乎随机数据分割并不是一件值得关注的事,但当我们将数据随机分割为训练、验证和测试集时,很可能预测准确率看上去非常不错。但实际上,采用随机分割的模型验证,其效果是过于高估的。
Jure Leskovec 举了个例子,比如说自然科学研究者,他们每次收集的数据肯定不是重复的,他们每次都需要做一系列新实验,因此模型每次都在做分布外的预测。这就要求数据的分割方式需要非常合理,需要模型的泛化能力足够强大以处理这些分布外的数据预测。

谈及数据分割问题,张峥教授说:「我们在和制药行业的研究人员讨论时,都被提醒在训练集上做随机切分是不可取的,因为分子图样本有结构性质,独立同分布假设会对模型的泛化能力有影响,我认为其他领域也有同样的问题。」
为了处理这种情况,OGB 采用的数据分割方法也非常有意思。例如对于分子图数据集,分割方法可以是分子支架(scaffold),具体而言,我们可以通过分子的子结构做聚类,然后将常用的集群作为训练集,将其它非常见集群作为验证与测试集。这种处理方式会迫使神经网络获得更高的泛化性,不然它完全无法预测那些子结构不同的分子。
按物种分割或按代码库分割也是相同的道理,本质上这些数据分割都尝试把某一小部分整体移出来做测试。

最后,Jure Leskovec 也表明,他们预想 OGB 不仅能作为一种广泛使用的研究资源,同时也能作为各种新任务或新模型的真实测试环境。在不久的将来,OGB 将进一步支持更多的图数据集、更多的图建模任务,并同时提供一份开放的 LeadBoard。有了这样的 LeadBoard,我们就能更直观地评估各种图神经网络的特点,了解哪种情况下它们的效果是最好的。

点击阅读原文,立即访问。





