ChineseGLUE:为中文NLP模型定制的自然语言理解基准
机器之心整理
参与:张倩、郑丽慧
GLUE 是一个用于评估通用 NLP 模型的基准,其排行榜可以在一定程度上反映 NLP 模型性能的高低。然而,现有的 GLUE 基准针对的是英文任务,无法评价 NLP 模型处理中文的能力。为了填补这一空白,国内关注 NLP 的热心人士发布了一个中文语言理解测评基准——ChineseGLUE。ChineseGLUE 目前拥有八个数据集的整体测评及其基线模型,目前已经有 20多位来自各个顶尖机构的自愿者加入并成为了创始会员。
ChineseGLUE 的成员包括全国各地关注 NLP 的热心专业人士,包括清华、北大、浙大等知名高校的毕业生。团队的愿景是通过完善中文语言理解基础设施,促进中文语言模型的发展,能够作为通用语言模型测评的补充,以更好地服务中文语言理解、任务和产业界。
项目地址:https://github.com/chineseGLUE/chineseGLUE

中文是一个大语种,有其自身特定及大量的应用。产业界的 NLP 模型需要解决大量中文任务,而中文是象形文字,有文字图形;字与字之间没有分隔符,不同的分词 (分字或词) 会影响下游任务。
相对于英文数据集来说,中文数据集大多是非公开或者缺失基准测评的,大多数论文所描述的模型都是在英文数据集上做的测试和评估,在中文领域的效果却不得而知。
预训练模型的相继产生极大地促进了对自然语言的理解,但不少最先进的模型却没有中文版本,导致技术应用上的滞后。
3)基线模型,包含开始的代码、预训练模型
数据量:训练集 (238,766),验证集 (8,802),测试集 (12,500)
例子:
1. 聊天室都有哪些好的 [分隔符] 聊天室哪个好 [分隔符] 1
2. 飞行员没钱买房怎么办?[分隔符] 父母没钱买房子 [分隔符] 0
数据量:训练集 (392,703),验证集 (?),测试集 (?)
例子:
1. 从 概念 上 看 , 奶油 收入 有 两 个 基本 方面 产品 和 地理 .[分隔符] 产品 和 地理 是 什么 使 奶油 抹 霜 工作 . [分隔符] neutral
2. 我们 的 一个 号码 会 非常 详细 地 执行 你 的 指示 [分隔符] 我 团队 的 一个 成员 将 非常 精确 地 执行 你 的 命令 [分隔符] entailment
原始的 XNLI 覆盖 15 种语言(含低资源语言)。我们选取其中的中文,并将做格式转换,使得非常容易进入训练和测试阶段。
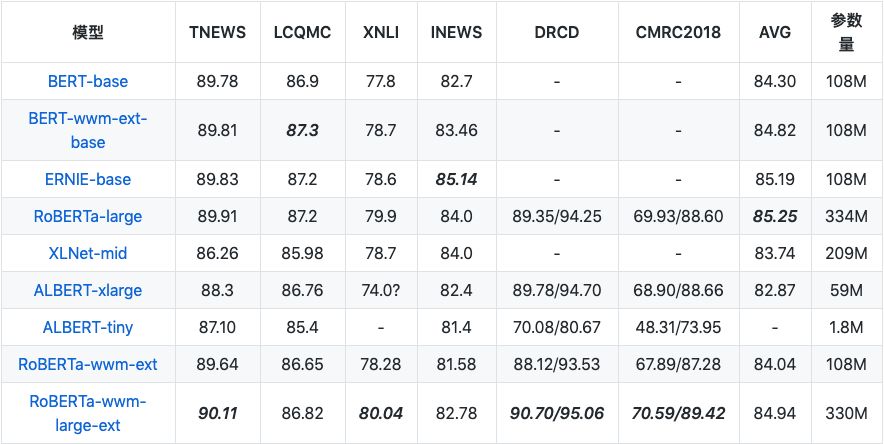
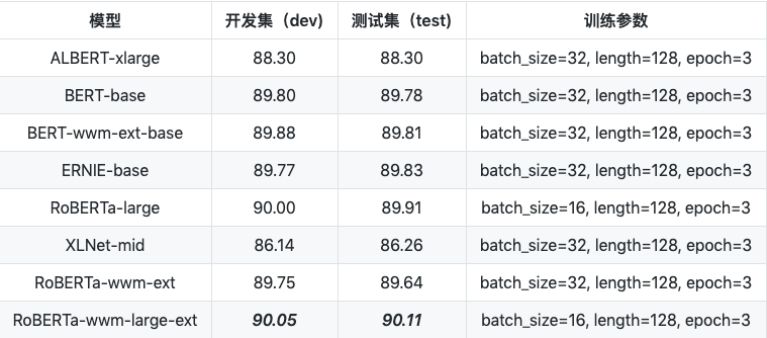
3.TNEWS 今日头条中文新闻(短文本)分类
数据量:训练集 (266,000),验证集 (57,000),测试集 (57,000)
例子:
6552431613437805063_!_102_!_news_entertainment_!_谢娜为李浩菲澄清网络谣言,之后她的两个行为给自己加分_!_佟丽娅, 网络谣言, 快乐大本营, 李浩菲, 谢娜, 观众们
每行为一条数据,以_!_分割的个字段,从前往后分别是 新闻 ID,分类 code,分类名称,新闻字符串(仅含标题),新闻关键词
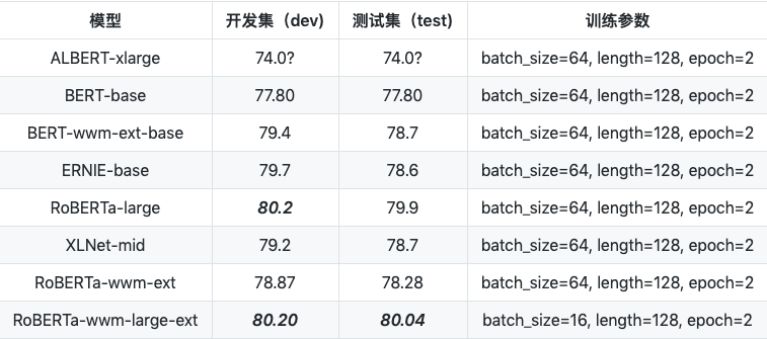
4.INEWS 互联网情感分析任务
数据量:训练集 (5,356),验证集 (1,000),测试集 (1,000)
例子:
1_!_00005a3efe934a19adc0b69b05faeae7_!_九江办好人民满意教育_!_近 3 年来,九江市紧紧围绕「人本教育、公平教育、优质教育、幸福教育」的目标,努力办好人民满意教育,促进了义务教育均衡发展,农村贫困地区办学条件改善。目前,该市特色教育学校有 70 所 ......
每行为一条数据,以_!_分割的个字段,从前往后分别是情感类别,数据 id,新闻标题,新闻内容
5.DRCD 繁体阅读理解任务
数据量:训练集 (8,016 个段落,26,936 个问题),验证集 (1,000 个段落,3,524 个问题),测试集 (1,000 个段落,3,493 个问题)
例子:
{
"version": "1.3",
"data": [
{
"title": "基督新教",
"id": "2128",
"paragraphs": [
{
"context": "基督新教與天主教均繼承普世教會歷史上許多傳統教義,如三位一體、聖經作為上帝的啟示、原罪、認罪、最後審判等等,但有別於天主教和東正教,新教在行政上沒有單一組織架構或領導,而且在教義上強調因信稱義、信徒皆祭司,以聖經作為最高權威,亦因此否定以教宗為首的聖統制、拒絕天主教教條中關於聖傳與聖經具同等地位的教導。新教各宗派間教義不盡相同,但一致認同五個唯獨:唯獨恩典:人的靈魂得拯救唯獨是神的恩典,是上帝送給人的禮物。唯獨信心:人唯獨藉信心接受神的赦罪、拯救。唯獨基督:作為人類的代罪羔羊,耶穌基督是人與上帝之間唯一的調解者。唯獨聖經:唯有聖經是信仰的終極權威。唯獨上帝的榮耀:唯獨上帝配得讚美、榮耀",
"id": "2128-2",
"qas": [
{
"id": "2128-2-1",
"question": "新教在教義上強調信徒皆祭司以及什麼樣的理念?",
"answers": [
{
"id": "1",
"text": "因信稱義",
"answer_start": 92
}
]
},
{
"id": "2128-2-2",
"question": "哪本經典為新教的最高權威?",
"answers": [
{
"id": "1",
"text": "聖經",
"answer_start": 105
}
]
}
]
}
]
}
]
}
数据格式和 squad 相同,如果使用简体中文模型进行评测的时候可以将其繁转简 (本项目已提供)
数据量:训练集 (短文数 2,403,问题数 10,142),试验集 (短文数 256,问题数 1,002),开发集 (短文数 848,问题数 3,219)
例子:
{
"version": "1.0",
"data": [
{
"title": "傻钱策略",
"context_id": "TRIAL_0",
"context_text": "工商协进会报告,12 月消费者信心上升到 78.1,明显高于 11 月的 72。另据《华尔街日报》报道,2013 年是 1995 年以来美国股市表现最好的一年。这一年里,投资美国股市的明智做法是追着「傻钱」跑。所谓的「傻钱」策略,其实就是买入并持有美国股票这样的普通组合。这个策略要比对冲基金和其它专业投资者使用的更为复杂的投资方法效果好得多。",
"qas":[
{
"query_id": "TRIAL_0_QUERY_0",
"query_text": "什么是傻钱策略?",
"answers": [
"所谓的「傻钱」策略,其实就是买入并持有美国股票这样的普通组合",
"其实就是买入并持有美国股票这样的普通组合",
"买入并持有美国股票这样的普通组合"
]
},
{
"query_id": "TRIAL_0_QUERY_1",
"query_text": "12 月的消费者信心指数是多少?",
"answers": [
"78.1",
"78.1",
"78.1"
]
},
{
"query_id": "TRIAL_0_QUERY_2",
"query_text": "消费者信心指数由什么机构发布?",
"answers": [
"工商协进会",
"工商协进会",
"工商协进会"
]
}
]
}
]
}
数据格式和 squad 相同
数据量:训练集 (70,000),验证集 (20,000),测试集 (10,000)
例子:
1. 我存钱还不扣的 [分隔符] 借了每天都要还利息吗 [分隔符] 0
2. 为什么我的还没有额度 [分隔符] 为啥没有额度!![分隔符] 1
数据量:训练集(46,364),测试集(4,365)
例子:
1.据说/o 应/o 老友/o 之/o 邀/o ,/o 梁实秋/nr 还/o 坐/o 着/o 滑竿/o 来/o 此/o 品/o 过/o 玉峰/ns 茶/o 。/o
2.他/o 每年/o 还/o 为/o 河北农业大学/nt 扶助/o 多/o 名/o 贫困/o 学生/o 。/o
wget https://storage.googleapis.com/chineseglue/chineseGLUEdatasets.v0.0.1.zip
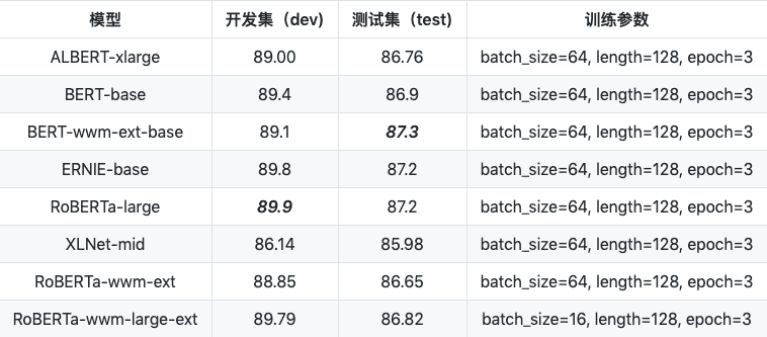
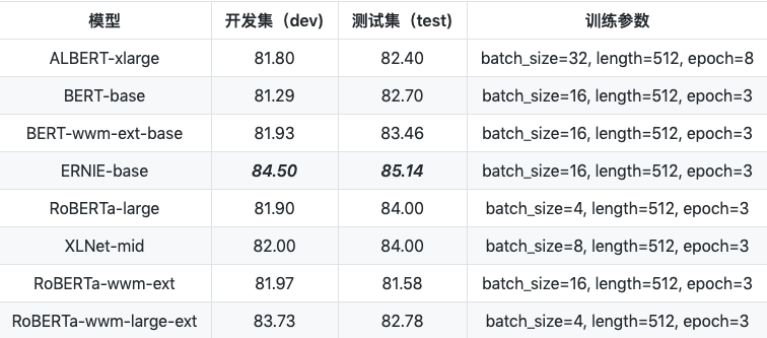
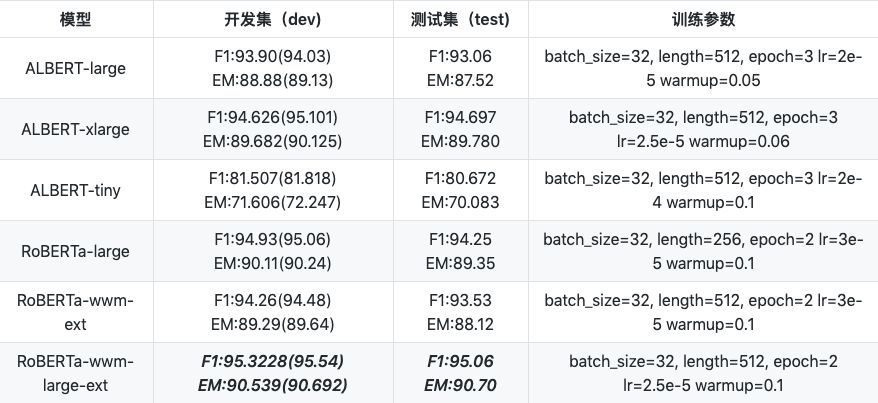
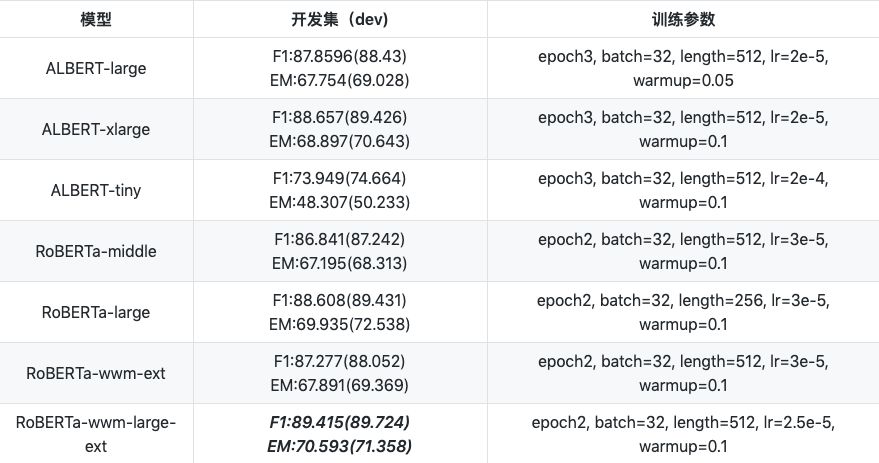
``` a1. albert ```
```https://github.com/brightmart/albert_zh ```
```a1. bert ```
```https://github.com/google-research/bert ```
b. 修改 run_classifier.sh 指定模型路径
新闻语料: 8G 语料,分成两个上下两部分,总共有 2000 个小文件。
社区互动语料:3G 语料,包含 3G 文本,总共有 900 多个小文件。
维基百科:1.1G 左右文本,包含 300 左右小文件。
评论数据:2.3G 左右文本,含有 811 个小文件,合并 ChineseNLPCorpus 的多个评论数据,清洗、格式转换、拆分成小文件。




