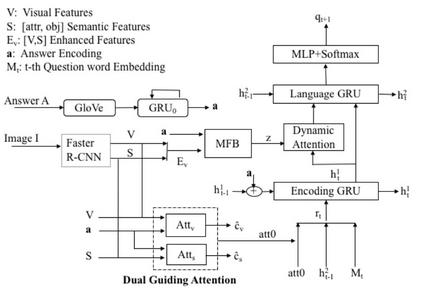
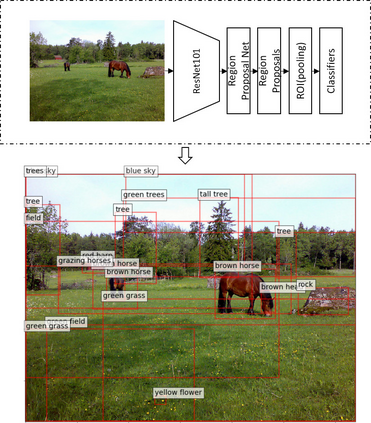
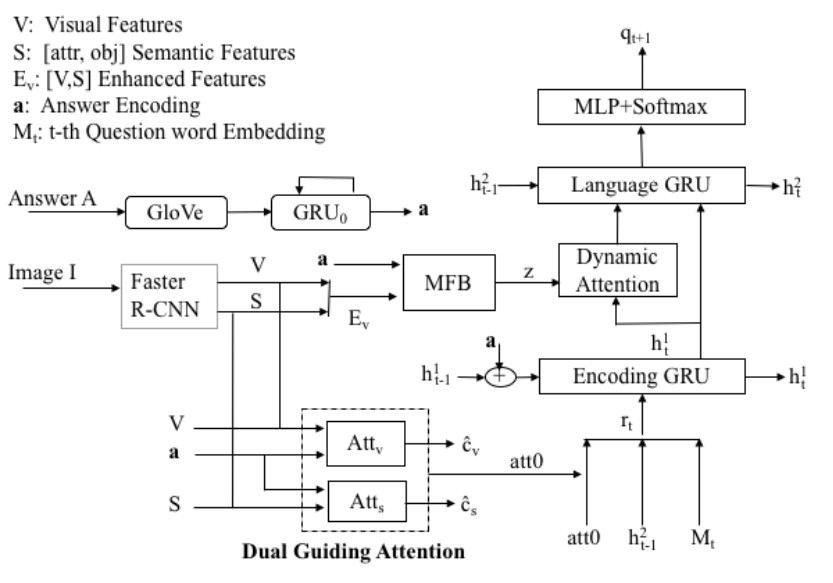
In this paper, we propose a novel deep multi-level attention model to address inverse visual question answering. The proposed model generates regional visual and semantic features at the object level and then enhances them with the answer cue by using attention mechanisms. Two levels of multiple attentions are employed in the model, including the dual attention at the partial question encoding step and the dynamic attention at the next question word generation step. We evaluate the proposed model on the VQA V1 dataset. It demonstrates state-of-the-art performance in terms of multiple commonly used metrics.
翻译:在本文中,我们提出了一个新的深刻的多层次关注模式,以解决反直观回答问题。拟议模式在目标层面产生区域视觉和语义特征,然后通过使用关注机制的回答提示来增强这些特征。模型使用了两个层次的多重关注,包括部分问题编码步骤的双重关注和下一个问题单词生成步骤的动态关注。我们评估了VQA V1数据集的拟议模式。它展示了多种常用指标的最新性能。