【论文笔记】NLP 预训练模型综述
-
在大语料下预训练的模型可以学习到 universal language representations,来帮助下游任务 -
PTMs 提供了一个更好的初始化模型,可以提高目标任务的效果和加速收敛 -
PTMs 可以看做是一种正则,防止模型在小数据集上的过拟合
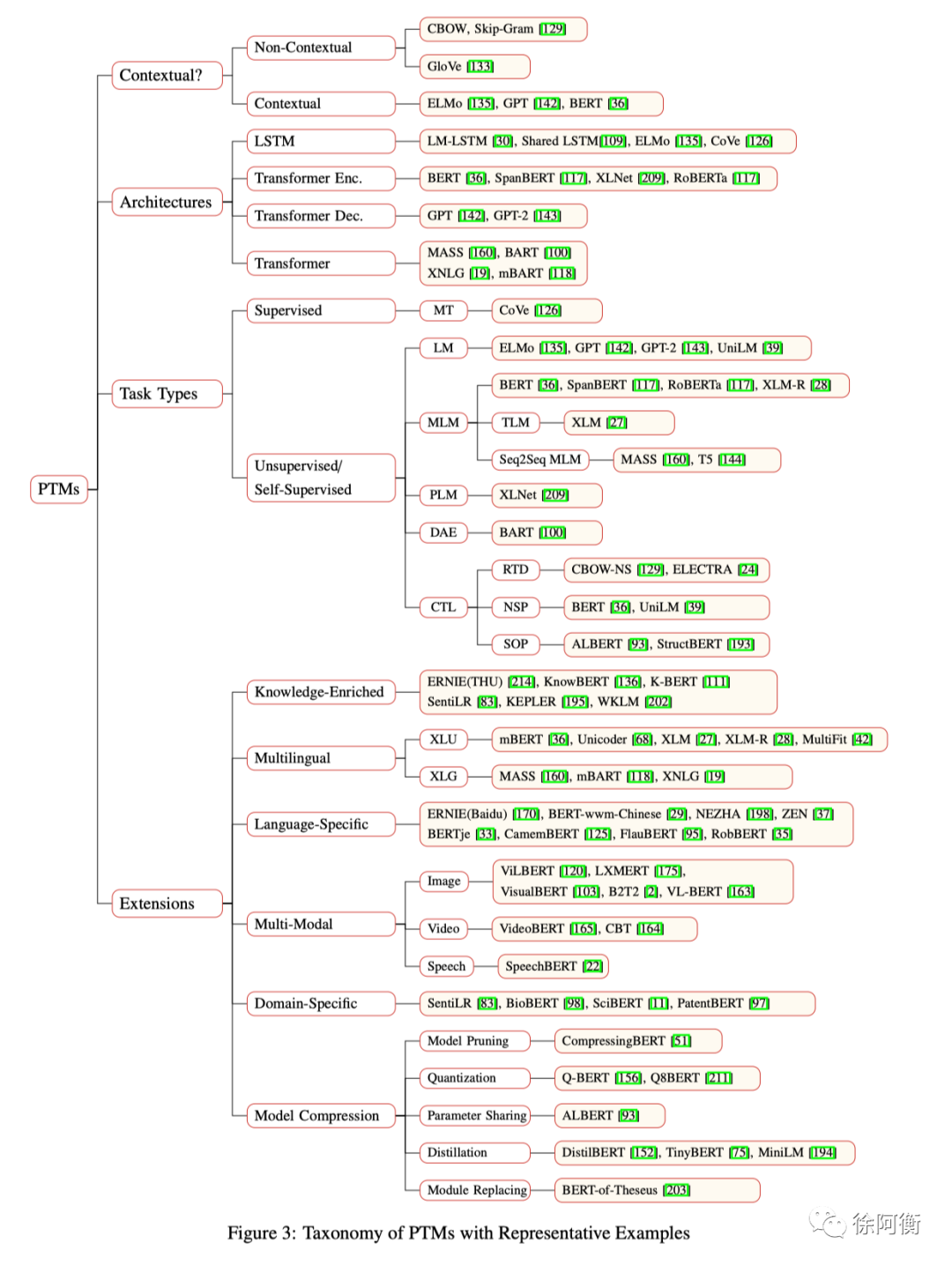
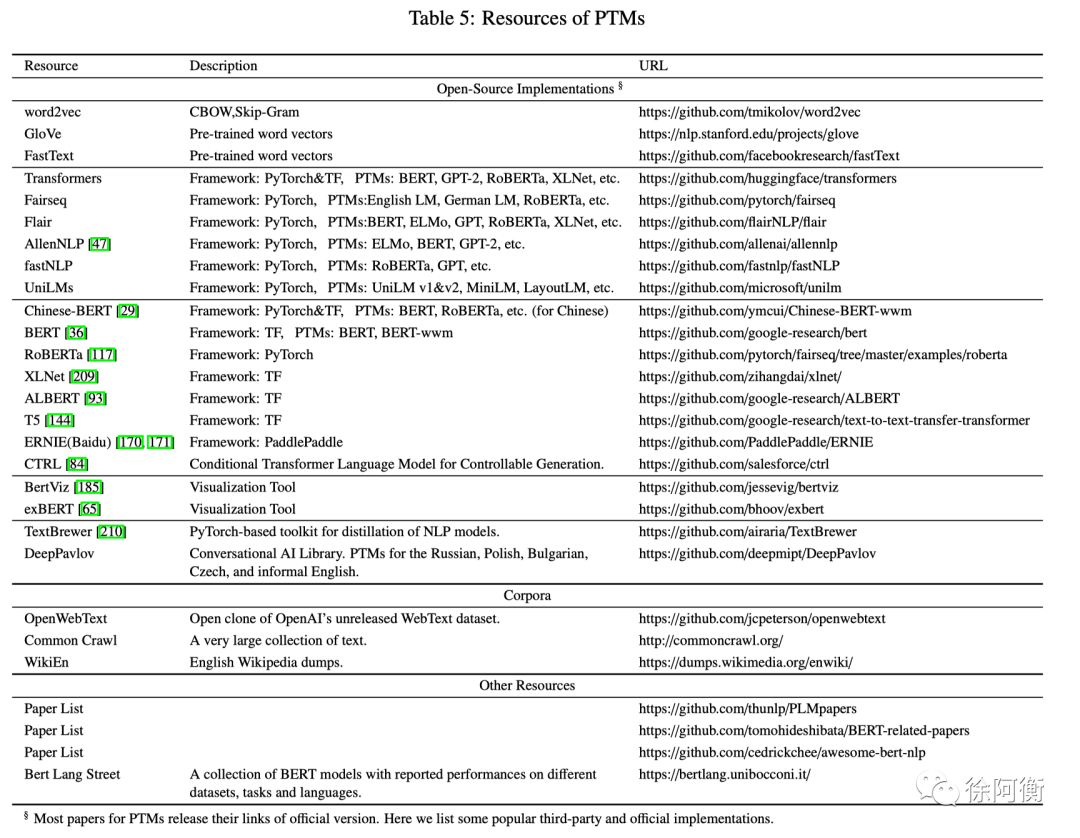
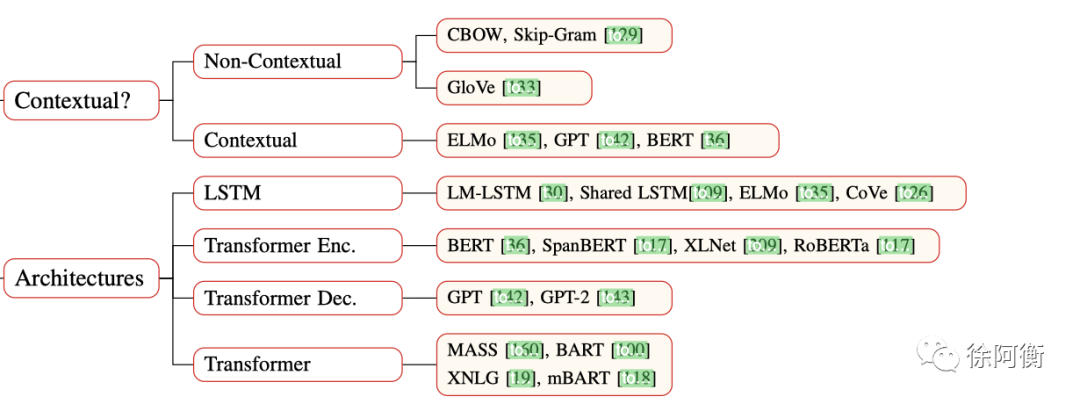
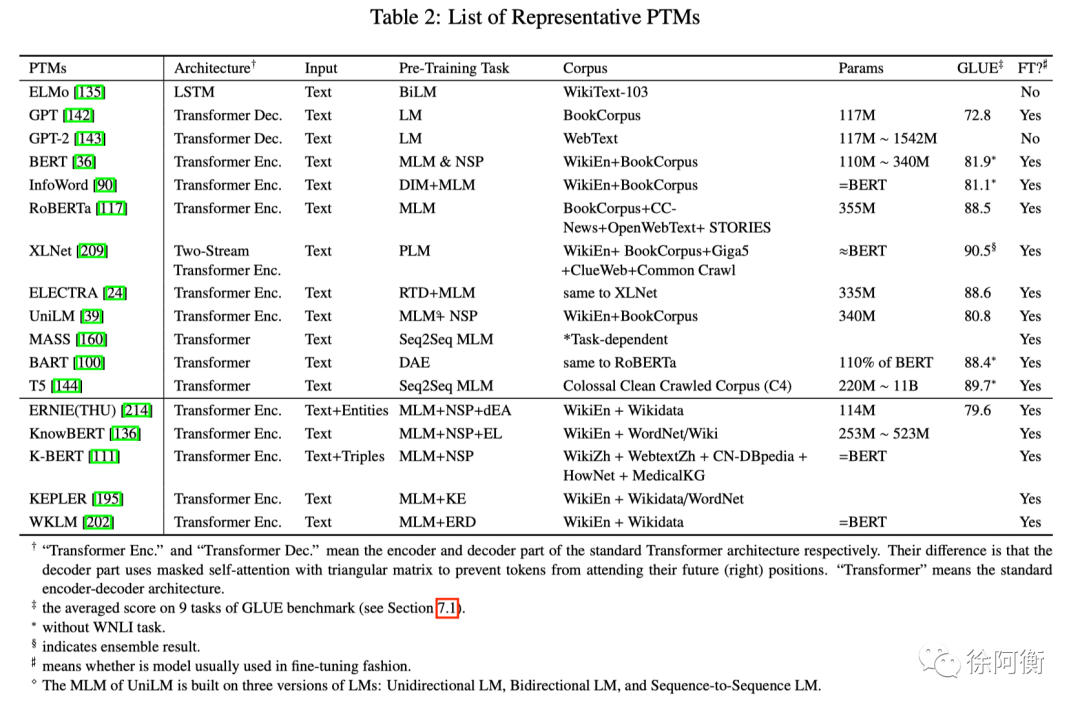
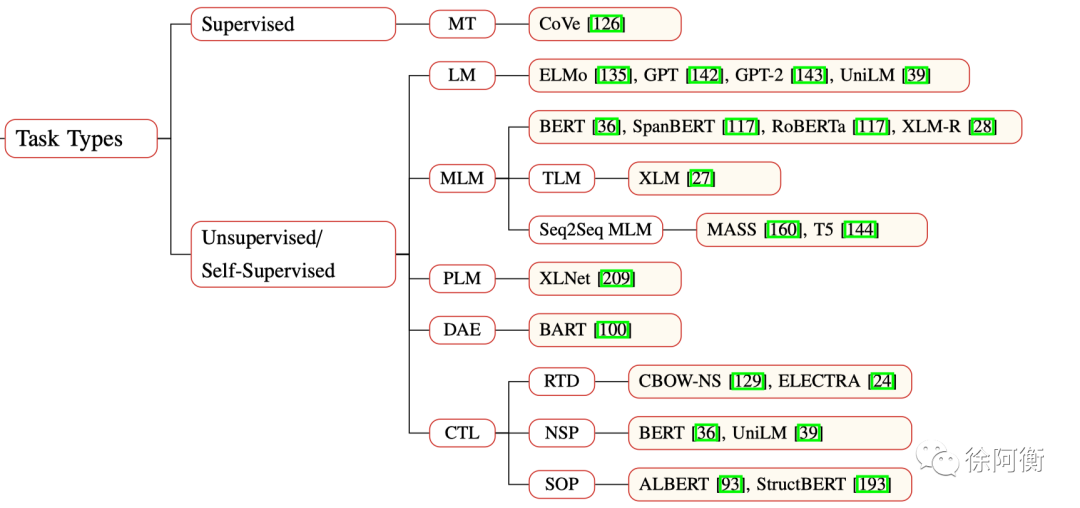
-
Supervised learning (SL) -
Unsupervised learning (UL) -
Self-Supervised learning (SSL) 这一类在传统意义上也是 UL 的一种,不过这里把它们区分了开来,UL 指不用人类标注的有监督的标签,而 SSL 指标签可以自动从训练数据中产生,如 MLM 任务,SSL 的学习过程其实和 SL 一样
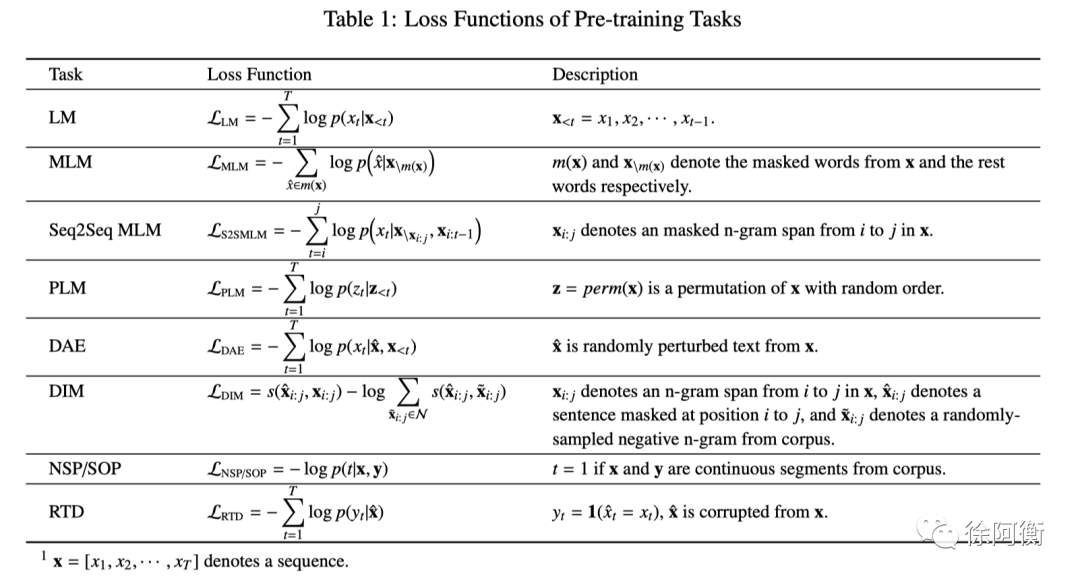
-
RoBERTa: dynamic masking -
UniLM: unidirectional, bidirectional, seq2seq prediction -
XLM: translation language modeling (TLM) -
Span-BERT: random contiguous words masking, span boundary objective -
StructBERT: span order recovery task -
External knowledge….
-
Token Masking -
Token Deletion: 模型需要预测删除的位置 -
Text Infilling:像 SpanBERT,模型预测 mask 的 span 有几个单词 -
Sentence Permutation:把文档分为句子然后随机打乱 -
Document Rotation:选择一个单词然后 rotate 文档,模型预测文档的真实起始位置
-
Deep InfoMax (DIM):比较难解释,上图

-
Replaced Token Detection (RTD):e.g., CBOW-NS 中的负样本选择可以看做是简单的 RTD, ELECTRA 利用生成器来选择替代序列中的某些 token, WKLM 替换某些实体为同一实体类型下的其他实体 Next Sentence Prediction (NSP):两个输入句子是否为训练数据中的连续片段 Sentence Order Prediction (SOP):两个连续片段作为正样本,而相同的两个连续片段互换顺序作为负样本。ALBERT 首次提出,NSP 同时做了 topic prediction 和 coherence prediction,而 topic prediction 太简单了模型会倾向用主题信息来做最后预测,而 SOP 更加聚焦在 coherence prediction 上

-
Linguistic -
LIBERT 通过额外的 linguistic constraint task 来融入语言学知识 -
SentiLR 引入 token 级别的情感极性,改造 MLM 为 label-aware MLM -
KnowBERT -
Semantic -
SenseBERT 不仅预测 masked token,还预测 token 在 WordNet 对应的 supersenses -
Commonsense -
ConceptNet, ATOMIC, 用来提高 GPT-2 在故事生成上的效果 -
Factual -
ERNIE(THU), KnowBERT, K-BERT, KEPLER -
Domain-specific -
K-BERT -
KG-conditioned language models -
KGLM, LRLM
-
Model Pruning:CompressingBERT -
Weight Quantization: Q-BERT, Q8BERT -
Parameter Sharing: ALBERT -
Knowledge Distillation -
Distillation from soft target probablilites: DistilBERT -
Distillation from other knowledge: TinyBERT, MobileBERT, MiniLM -
Distillation to other structures: from transformer to RNN / CNN -
Model Replacing -
BERT-of-Theseus -
Others -
FastBERT,动态减少计算步骤
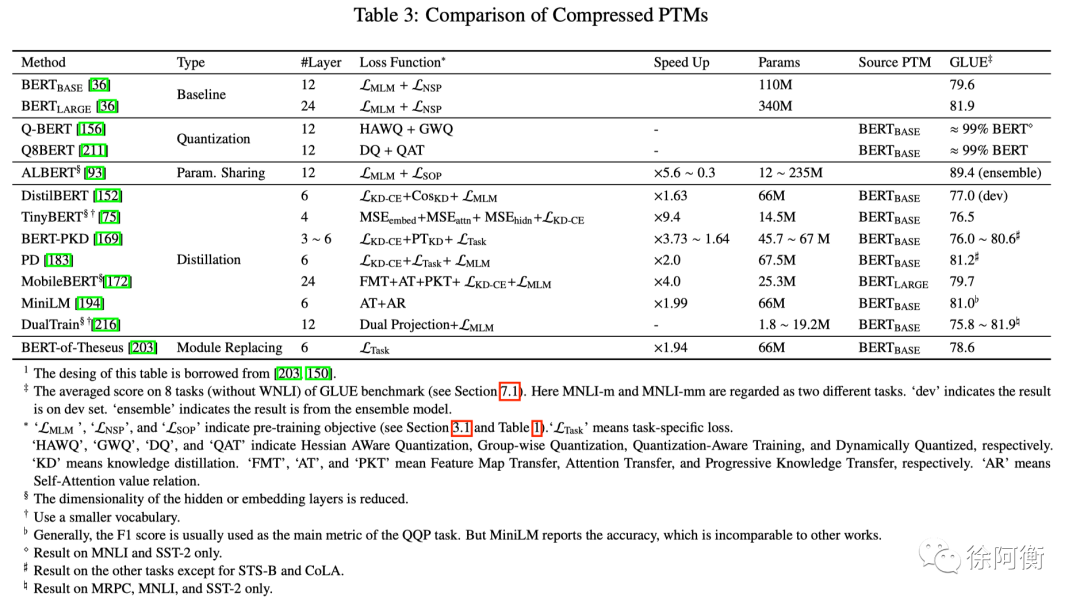
选择合适的预训练任务、模型框架和语料
选择合适的 layer
Embedding only; Top layer; All layers (更灵活的方式是像 ELMo 一样自动选择最好的层)选择迁移方式(to tune or not to tune)
Feature extraction: pre-trained parameters are frozen
Fine-tuning: pre-trained parameters are unfrozen and fine-tuned

-
Two-stage fine-tuning -
第一阶段,在一个中间任务/语料上进行迁移,第二阶段,迁移到目标任务 -
Story ending prediction by transferable bert: TransBERT -
How to fine-tune BERT for text classification? -
Sentence encoders on STILTs: Supplementary training on intermediate labeled-data tasks -
Convolutional sequence to sequence learning -
Multi-task fine-tuning -
多任务和预训练互为补充 -
Multi-task deep neural networks for natural language understanding -
Fine-tuning with extra adaptation modules -
原始参数固定,在 PTMs 里接入一些 fine-tunable adaptation modules -
BERT and PALs: Projected attention layers for efficient adaptation in multi-task learning -
Parameter-efficient transfer learning for NLP -
Others -
Improving BERT fine-tuning via self-ensemble and self-distillation -
Universal language model fine-tuning for text classification: gradual unfreezing -
An embarrassingly simple approach for transfer learning from pretrained language models: sequential unfreezing
-
Upper Bound of PTMs -
PTMs 并没有发展到其上限。目前大多数的 PTMs 都可以通过使用更多的步长以及更大的数据集来提升性能,因此一个实际的方向是在现有的软/硬件基础上,去设计更高效的模型结构、自监督预训练任务、优化器和训练技巧,如 ELECTRA -
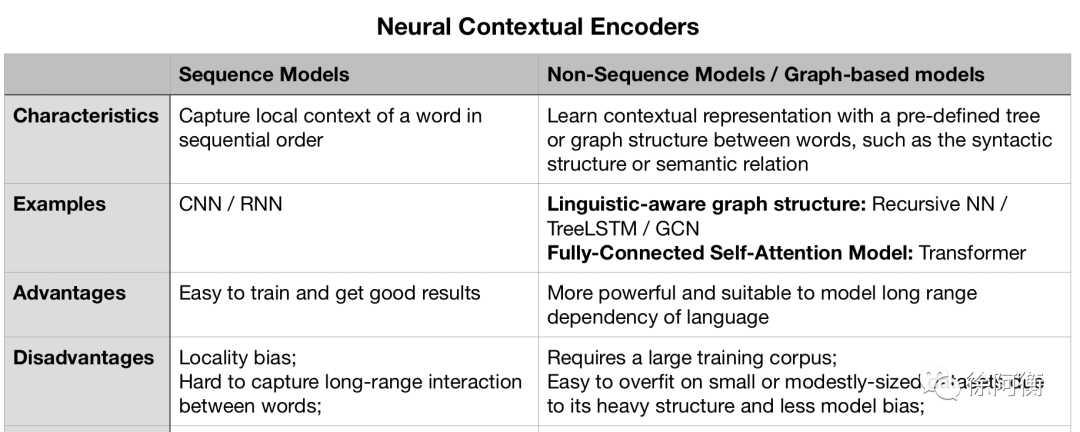
Architecture of PTMs -
Transformer 的主要局限在于其计算复杂度(输入长度的平方)。GPU 显存大小的限制使得多数 PTMs 无法处理超过 512 个 token 的序列长度。打破这一限制需要改进 Transformer 的结构设计,如 Transformer-XL。设计深层神经网络结构是很有挑战性的任务,或许使用如神经结构搜索 (NAS) 这类自动化的方案 -
Task-oriented Pre-training and Model Compression -
在实践中,不同的目标任务需要 PTMs 的不同功能。PTMs 和下游任务的差异通常在于模型架构与数据分发。更大的差异可能会使得 PTMs 的使用收益更小,比如 text generation 和 text matching 的任务就有很大差异 -
大型 PTMs 应用到实际场景时面临的低容量设备和低延迟应用的要求:为下游任务精心设计特定的模型结构与预训练任务,或者直接从现有的 PTMs 中提取部分与任务有关的知识 -
使用模型蒸馏技术对现有的 PTMs 进行教育,来完成目标任务 -
Knowledge Transfer Beyond Fine-tuning -
提高 Fine-tuning 的参数利用效率。之前 fine-tune 中的参数效率很低,要为每个下游任务 fine-tune 各自的参数。一个改进方案是之前提到过的固定 PTMs 的原始参数,并为特定任务添加小的 fine-tunable adaptation modules,这样就可以使用共享的 PTM 来支持多个下游任务 -
更灵活的从 PTMs 中挖掘知识,如 feature extraction, knowledge distillation, data augmentation, using PTMs as external knowledge -
Interpretability and Reliability of PTMs -
可解释性:PTMs 的深层非线性结构/Transformer 类结构/语言的复杂性使得解释 PTM 变得更加困难 -
可靠性:PTMs 在对抗性样本中显得非常脆弱。Adversarial defenses 也是一个非常有前景的方向


登录查看更多
相关内容

专知会员服务
94+阅读 · 2020年4月13日
Arxiv
8+阅读 · 2019年1月2日




相关VIP内容
专知会员服务
94+阅读 · 2020年4月13日
相关资讯
相关论文
Arxiv
8+阅读 · 2019年1月2日