【紫冬分享】移动机器人视觉里程计综述

【今日聚焦】
定位是移动机器人导航的重要组成部分。在定位问题中,视觉发挥了越来越重要的作用。本文按照数据关联方式的不同介绍了视觉里程计(Visualodometry, VO)所使用的较为代表性方法,讨论了提高视觉里程计鲁棒性的方法。此外,本文讨论了语义分析在视觉定位中作用以及如何使用深度学习神经网络进行视觉定位的问题。最后,本文简述了视觉定位目前存在的问题和未来的发展方向。
移动机器人想要完成自主导航,首先要确定自身的位置和姿态,即实现定位。一方面,一些移动机器人尤其是空中机器人的稳定运行需要位姿信息作为反馈,以形成闭环控制系统。另一方面,随着移动机器人的快速发展,移动机器人需要完成的任务多种多样,例如物体抓取、空间探索、农业植保、搜索救援等,这些任务对移动机器人的定位提出了更高要求。
常用的定位方法有全球定位系统(Globalpositionsystem, GPS)、基于惯性导航系统(Inertianavigationsystem, INS)的定位、激光雷达定位、基于人工标志的定位方法、视觉里程计(Visualodometry, VO)定位等。下面主要针对VO展开讨论。
主流的视觉定位方法
VO系统中的数据关联表示了3D点在不同帧之间的关系。在运动估计中,使用当前帧图像和过往帧图像进行数据关联求解相机运动量,通过递推每一步的运动量可以得到相机和机器人的位姿。所以如何确定数据关联便成了机器人定位中需要解决的问题之一。
数据关联中的点所在空间有三种形式:2D-2D、3D-3D、3D-2D。在VO系统初始化时,地图未建立,系统无法确定当前状态,采用2D-2D数据关联,对基础矩阵或单应矩阵分解求解相机的相对位姿,三角化求解路标点的三维坐标。按照2D-2D数据关联方式的不同,视觉定位方法可以分为直接法、非直接法和混合法。
直接法使用了简单的成像模型,假设帧间光度值具有不变性,即相机运动前后特征点的灰度值是相同的。数据关联时,根据灰度值对特征点进行匹配。这种方法适用于帧间运动较小的情形,但这种假设与实际情况存在差异,在场景的照明发生变化时,特征点容易出现误匹配。
主要方法有:FAIA、FCIA、ICIA和IAIA。
非直接法又称为特征法,该方法提取图像中的特征进行匹配,最小化重投影误差得到位姿。图像中的特征点以及对应描述子用于数据关联,通过特征描述子的匹配,完成初始化中2D-2D以及之后的3D-2D的数据关联。
常用的旋转、平移、尺度等不变性特征及描述子有ORB、FAST、BRISK和SURF,它们可用于完成帧间点匹配。

图1:直接法与非直接法的优缺点对比
SVO是一种混合式的VO,该方法首先提取FAST特征,使用特征点周围的图像块进行像素匹配,并对帧间的相对位姿累积以初步估计当前位姿,累积误差会导致系统产生漂移。SVO通过匹配当前帧与地图中的点约束当前帧的位姿,降低累积误差。SVO初始化时使用单应矩阵分解求解相机的位姿,假设初始化场景中的点分布在一个平面内,因此适合平面场景的初始化。
VO系统在实际应用中的主要问题是鲁棒性不足,限制条件过多。具体优化方法可以从传感器的特性建模(包括卷帘快门相机建模)、系统的前端(系统初始化、运动模型假设)、后端(目标函数、深度图模型)等方面改进。
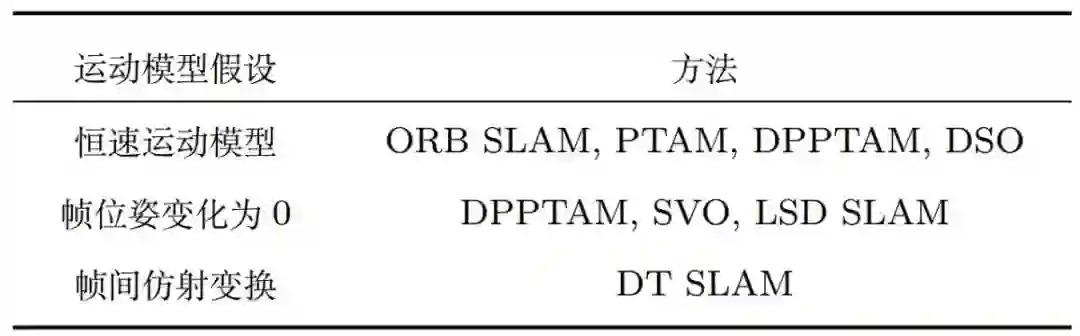
图2:常用运动模型先验假设

图3:常用的鲁棒估计器

图4:VO系统中的鲁棒目标函数设计
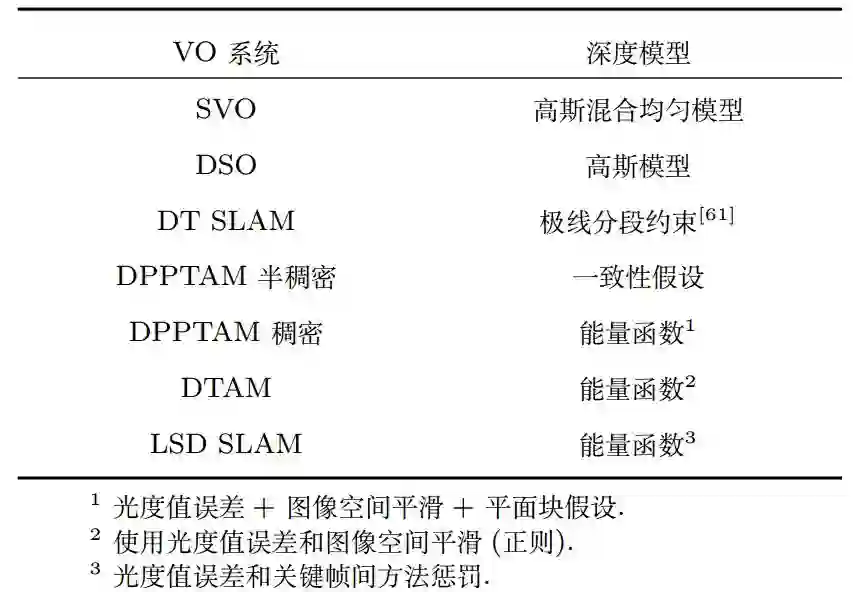
图5:深度图模型
视觉语义分析和深度学习网络在位姿估计中的应用
上文介绍了改进视觉里程计鲁棒性的措施,视觉语义分析以及深度学习的应用同样对提高系统的鲁棒性具有帮助。
语义分析根据结构型数据的相似特性对像素(区域)进行标记,对场景中的区域分类。粗粒度的语义分析应该包括物体检测、区域分割等。语义分析和位姿估计之间相互影响,可以体现在两个方面:1) 语义分析能够提高位姿及建图的精度;2) VO的测量结果降低语义分析的难度。
主要方法有:MO-SLAM(Multi-object SLAM),DARNN(Data association Recurrent neural network),FCN(Fully convolutional network)等。
人类可以不监督的完成认知任务,通过在代理任务(例如本体运动估计)的监督学习可以解决其他的任务(例如深度理解),避免了显式的监督学习。一些任务学习的泛化能力强,可以作为其他任务的基础。
基于深度学习的方法要解决的一个基本问题是如何得到训练使用的大规模数据集合,KITTI(Karlsruhe institute of technology and Toyota technological institute)和TUM(Technische Universitat Munchen)数据集中除了图像序列,还给出了图像的深度和相机采集图像时的位姿。如果不存在VICON或高精度IMU等数据作为真值,只有单纯图像序列的数据集,可以使用SFM(Structure from motion)方法计算每一帧图像的对应相机运动参数。
现有的深度学习还无法完成一个完整的视觉定位系统,但有望能够解决传统的VO方法难以解决的问题,例如重定位、长极线匹配、数据融合等。
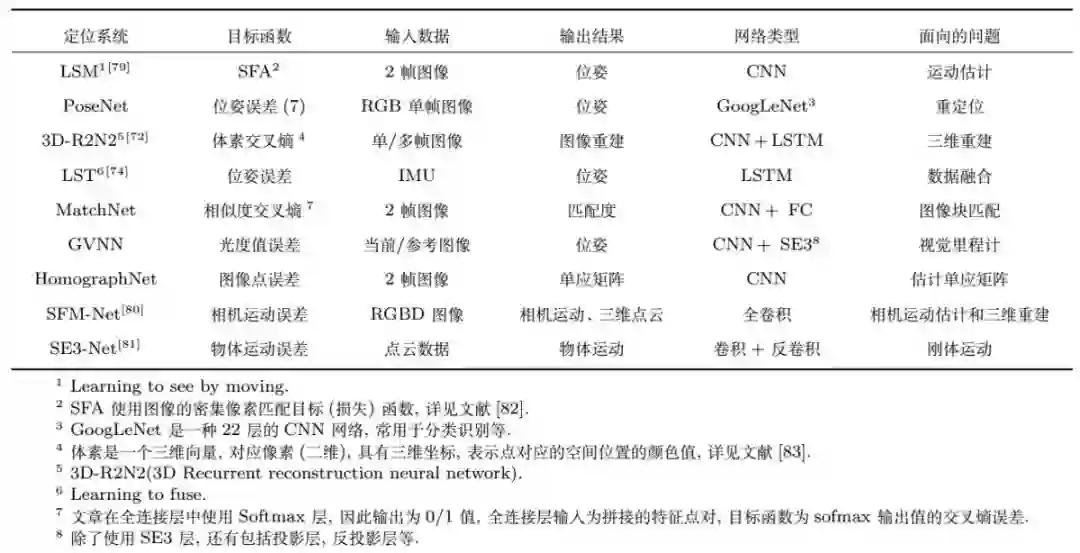
图6:深度网络定位系统特点
位姿估计的性能评价方法
① Engel等人给出了一种统一计算尺度误差、位置、姿态的误差的方法——对齐误差。这种测量方式可以应用于具有不同的观测方式的定位系统,被评估的系统可以是双目系统也可以是VIO系统,对于尺度、位置、旋转的误差影响是均衡的。
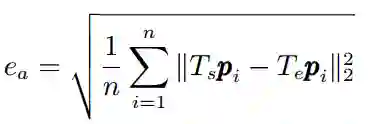
② Burgard等提出了一种基于图模型的相对位姿计算方法,但该方法是基于二维空间中三自由度的运动,我们将之拓展至三维空间六自由度的运动。两个位姿之间的相对误差为
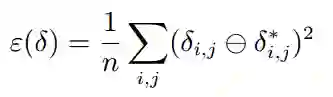
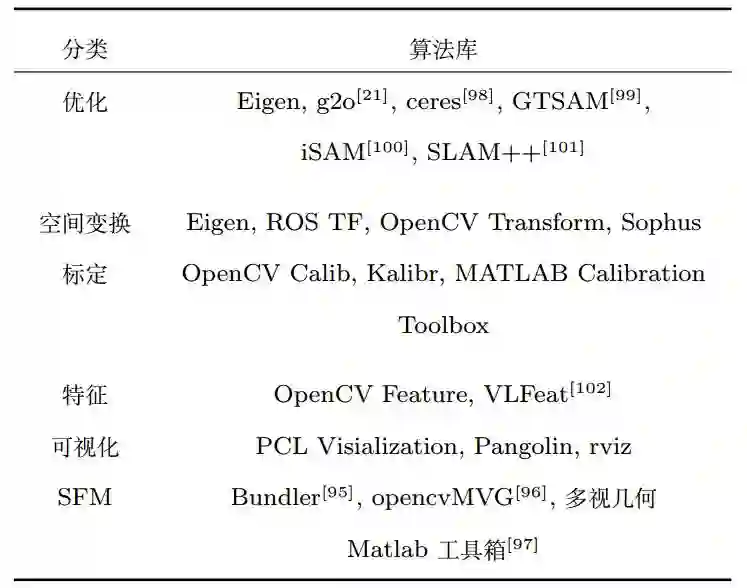
图7:视觉定位系统工具库
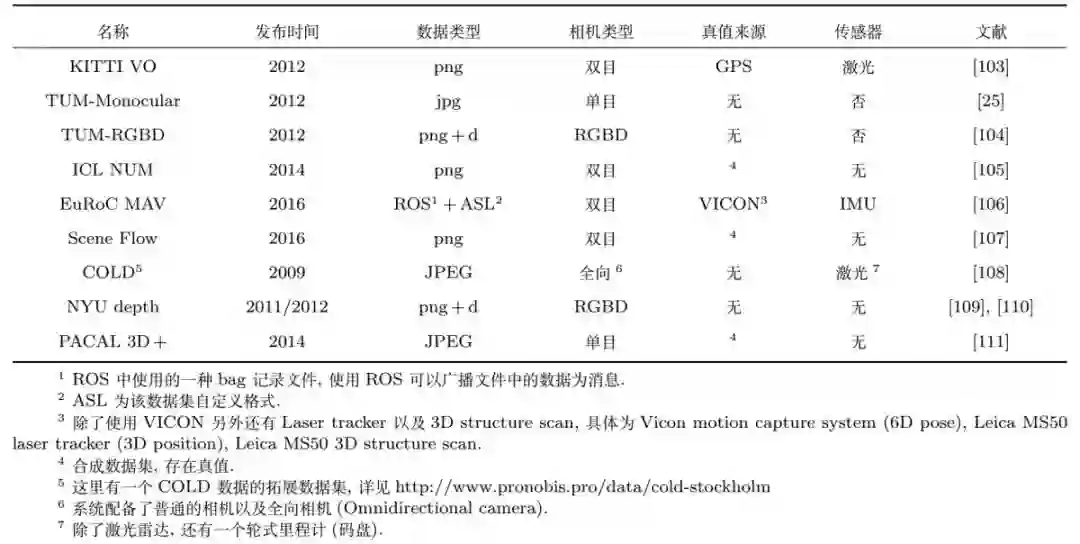
图8:VO系统常用验证数据集
视觉定位的现状与未来
目前而言移动机器人的视觉方法仍然存在多个方面的问题,鲁棒性方面的问题主要集中在如何完成图像的配准以及系统初始化、卷帘快门等问题,效率方面主要集中在如何实时的完成稠密、半稠密重建、图像点的选择、如何进行边缘化等问题。
随着深度学习在物体检测、语义分割、物体跟踪等方向的发展,环境中语义和环境理解更多地与视觉定位相结合提高视觉定位的鲁棒性,并建立更精简的地图,为我们提供了许多使用深度学习网络完成定位的思路。另外,语义分析与视觉定位的结合、深度学习应用于视觉定位、嵌入式视觉定位系统和组合定位等都是未来定位和视觉定位系统的重要发展方向,这些方向有望在进一步提升系统鲁棒性的同时降低所需的计算资源。

Story of Convolution Network: 卷积网络也许是生物学启发人工智能的最为成功的案例之一。虽然卷积网络也受到过许多其他领域的影响,但神经网络的一些来自于神经科学关键设计原则仍旧保留了下来。卷积网络的历史始于神经科学实验,远早于相关计算模型的发展。一开始卷积网络是为了研究哺乳动物视觉系统的工作原理。神经生理学家David Hubel和Torsten Wiesel合作多年(Hubel and Wiesel, 1959, 1962, 1968),成功记录了猫的单个神经元的活动情况,凭借这一工作最终获得了诺贝尔奖。

更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
作者:丁文东 徐德 刘希龙 张大鹏 陈天
来源:自动化学报
审稿:徐德
排版:松栩栩
编辑:鲁宁


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!


