
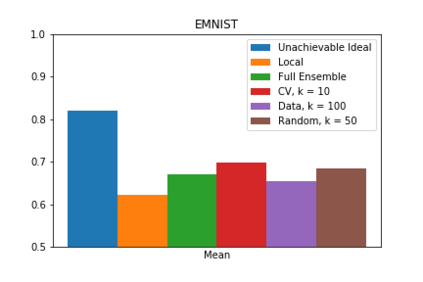
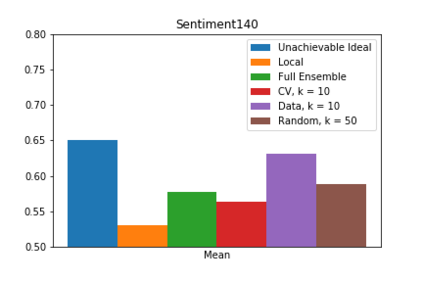
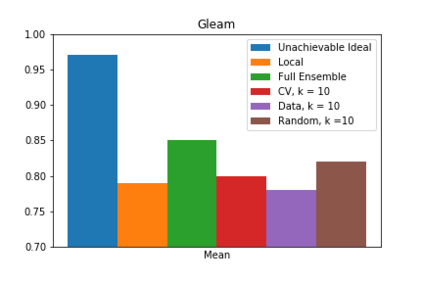
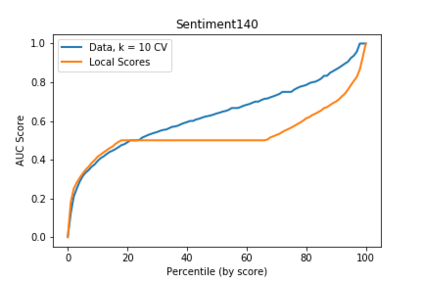
We present one-shot federated learning, where a central server learns a global model over a network of federated devices in a single round of communication. Our approach - drawing on ensemble learning and knowledge aggregation - achieves an average relative gain of 51.5% in AUC over local baselines and comes within 90.1% of the (unattainable) global ideal. We discuss these methods and identify several promising directions of future work.
翻译:我们展示了一次性的联盟学习,一个中央服务器通过单轮通信,通过一个联合设备网络学习一个全球模型。 我们的方法 — — 利用共同的学习和知识汇总 — — 在澳大利亚团结自卫军中取得了比当地基线平均51.5%的相对增益,并且超过了(不可避免)全球理想的90.1%。 我们讨论了这些方法,并确定了未来工作的若干有希望的方向。
相关内容

专知会员服务
47+阅读 · 2019年12月1日
Arxiv
20+阅读 · 2020年3月10日



相关VIP内容
专知会员服务
47+阅读 · 2019年12月1日
相关资讯
相关论文
Arxiv
20+阅读 · 2020年3月10日