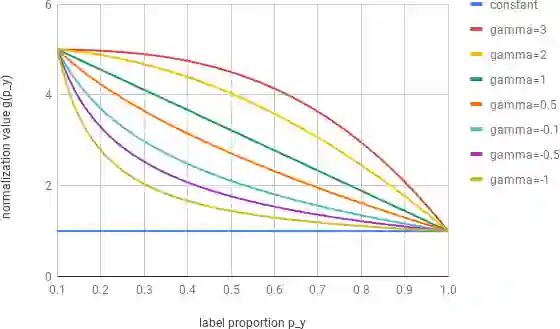
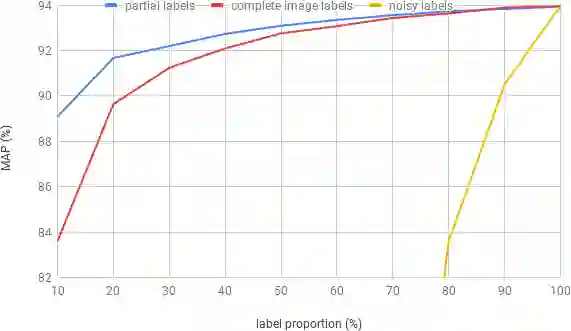
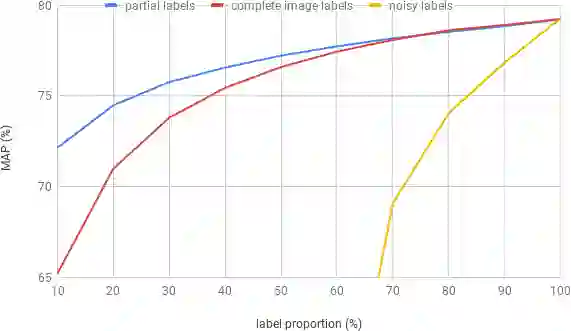
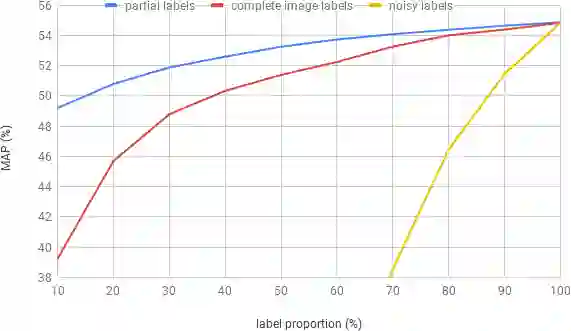
Deep ConvNets have shown great performance for single-label image classification (e.g. ImageNet), but it is necessary to move beyond the single-label classification task because pictures of everyday life are inherently multi-label. Multi-label classification is a more difficult task than single-label classification because both the input images and output label spaces are more complex. Furthermore, collecting clean multi-label annotations is more difficult to scale-up than single-label annotations. To reduce the annotation cost, we propose to train a model with partial labels i.e. only some labels are known per image. We first empirically compare different labeling strategies to show the potential for using partial labels on multi-label datasets. Then to learn with partial labels, we introduce a new classification loss that exploits the proportion of known labels per example. Our approach allows the use of the same training settings as when learning with all the annotations. We further explore several curriculum learning based strategies to predict missing labels. Experiments are performed on three large-scale multi-label datasets: MS COCO, NUS-WIDE and Open Images.
翻译:深 ConvNet 显示的单标签图像分类( 如图像网) 表现非常出色, 但必须超越单标签分类任务, 因为日常生活图片本质上是多标签的。 多标签分类比单标签分类更困难, 因为输入图像和输出标签空间都复杂。 此外, 收集清洁的多标签说明比单标签说明更难升级。 为了降低批注成本, 我们提议培训一个带有部分标签的模型, 即每个图像只知道一些标签。 我们首先对不同的标签战略进行实验性比较, 以显示在多标签数据集中使用部分标签的可能性。 然后, 以部分标签学习, 我们引入新的分类损失, 以利用每个示例的已知标签比例。 我们的方法允许使用与学习所有批注时相同的培训设置 。 我们进一步探索一些基于课程学习来预测缺失标签的战略 。 在三个大型多标签数据集上进行了实验 : MS COCO、 NUS 和 Open 图像 。