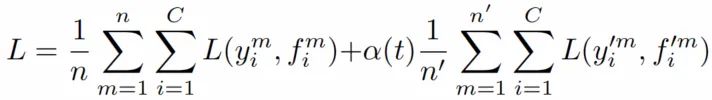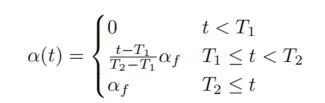![]()
©PaperWeekly 原创 · 作者|燕皖
单位|渊亭科技
研究方向|计算机视觉、CNN
在监督学习中,模型都是需要有一个大量的有标签的数据集进行拟合,通常数据成本、人力成本都很高。而现实生活中,无标签的样本的收集相对就很容易很多。因此,近年来,利用大量的无标签样本和少量的有标签样本的半监督学习备受关注。
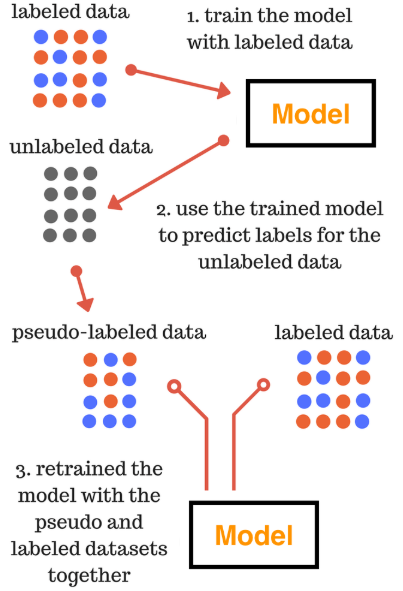
本文主要介绍一种半监督的方法——Self-training,其主要思路是:先利用有标签数据训练得到模型,然后对无标签数据进行预测,置信度高的数据可以用于加入训练集,继续训练,直到模型符合要求。首先介绍了两种经典的 Self-training 方法,然后介绍了 Self-training 在 Kaggle 比赛上的实践。
![]()
Pseudo-label
![]()
论文标题:
The Simple and EfficientSemi-Supervised Learning Method for Deep Neural Networks
论文链接:
http://deeplearning.net/wp-content/uploads/2013/03/pseudo_label_final.pdf
代码链接:
https://github.com/iBelieveCJM/pseudo_label-pytorch
1.1 训练策略
Pseudo-label 是 2013 年提出的一个非常简单有效的Semi-Supervised Learning 方法,其主要思想是在一批有标签和无标签的图像上,同时训练一个模型。训练流程如下:
Step 1:首先,同时使用有标记和未标记的 data,以有监督的方式训练 pretrained model。总损失是有标记和无标记损失项的加权和,前面是有标签数据的损失部分,后面的无标签数据的损失部分,如下:
其中,y 代表已标记数据的标签,y′ 代表了未标记数据的伪标签。
通常,为了确保模型已经从标记的数据中学习了足够多的信息,alpha_t 在最初的 N epoch 中,设置为 0,然后逐渐增加到 M epoch 后保持不变。如下式:
Step 2:然后,用训练好的 model 对一批未标记图像进行预测,用最大置信度作为 Pseudo-label ;
Step 3: 最后将有标签和伪标签的数据一起进行 finetune,直到最终得到最优 model。
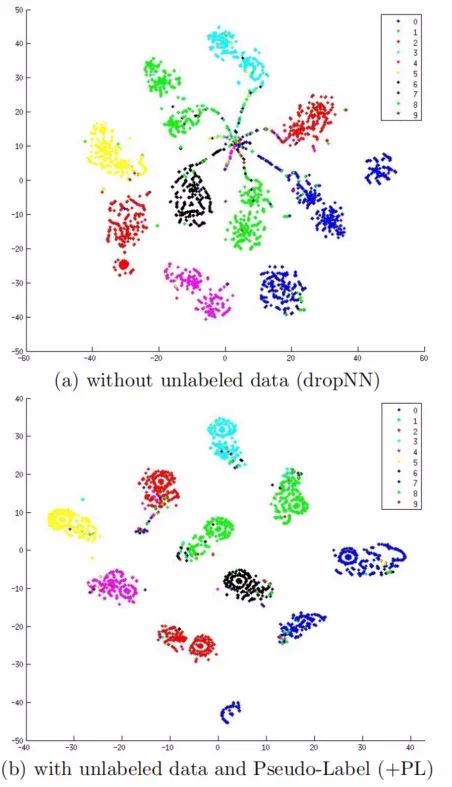
文章指出用 600 个标记数据对神经网络进行训练,和增加 60000 个未标记的数据和伪标签。从下图可以明显看到,通过使用未标记数据和伪标签训练的模型具有更好地泛化能力。
![]()
Noisy Student
论文标题:
Self-training with Noisy Studentimproves ImageNet classification
论文链接:
https://arxiv.org/abs/1911.04252
代码链接:
https://github.com/google-research/noisystudent
Google AI 年提出了一种受 Knowledge Distillation 启发的半监督方法“Noisy Student”。
2.1 Introduction
这篇文章主要的方法简单说就是使用更大的未标记图像的数据集,其中大部分图像不属于 ImageNet 训练集分布,来提高 SOTA-ImageNet 的精度。
其核心思想是 train 两种不同的模型,即“Teacher”和“Student”。教师模型首先对标签图像进行训练,然后对未标记图像进行伪标签推断。这些伪标签可以是 soft-label,也可以通过使用 most confident 转换的 hard-label。
然后,将有标记和未标记的图像组合在一起,并根据这些组合的数据训练学生模型。利用 RandAugment 作为输入噪声的一种形式对图像进行增强,最后训练得到最优 model。
对于一些有标签数据集 data1 和一些无标注数据集 data2
第一步:在有标签数据集上训练一个模型,称为 teacher;
第二步:利用第一步得到的模型,在未标注数据集上进行预测,softmax 输出结果是概率分布,一般称为称为 soft label,其只给出每个类别的 score,而非指定为具体某个类别,而 hard label 就是 one-hot 形式的取 max 后的结果,并且实验证明软标签更好一些;
第三步:将有标注数据集和伪标签数据集合并,然后利用 augmentation、droupout 等策略,基于这个大数据集进行训练一个新的 student 模型;
第四步:将学到的 student 当做 teacher 重新对无标注数据集进行打标签,回到第二步中,迭代直到得到最优 mdoel 为止。
对于标准数据集,仍使用 ImageNet 2012 基准数据集;
未标注数据集来自于 JFT 数据集,它实际含有大约 3 亿张图片,尽管这些图片实际有真实标签,但我们此处不需要,只当做无标记图片数据集即可。
为了实现无标签图片类别的平衡,作者拿在 ImageNet 上训练的 EfficientNet-B0 对 JFT 数据集打标签,并剔除了标签信任度低于 0.3 的图片,对于每个类别,挑选具有最高信任度的 13 万张图片,对于不足 13 万张的类别,随机再复制一些。
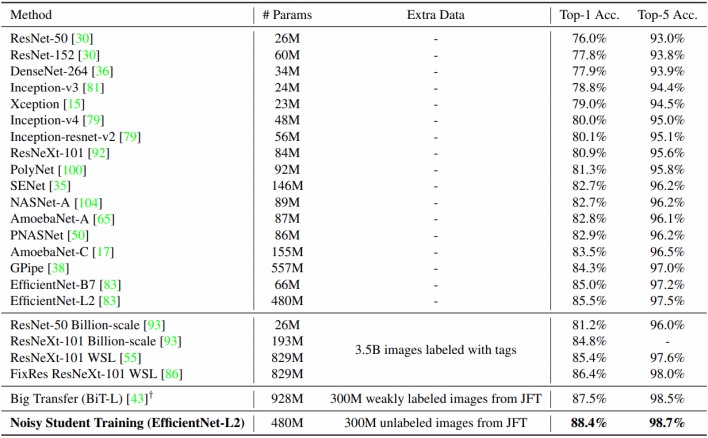
最终结果如下,可见 Noisy Student 方法在这一数据集上将 SOTA 性能提高了一个点。
![]()
Global Wheat Detection上的实践
接下来,将从目前正在参加的 kaggle 比赛(Global Wheat Detection)全球小麦头检测来分析Semi-Supervised Learning在目标检测中的作用。
https://www.kaggle.com/c/global-wheat-detection
在本竞赛中,将从室外的小麦植株图像(包括来自全球的小麦数据集)中检测出小麦植株的头部,训练数据集涵盖了多个区域,是来自欧洲(法国,英国,瑞士)和北美(加拿大)的 3,000 多张图像,测试数据包括来自澳大利亚,日本和中国的约 1,000 张图像。
下面是一些识别的小麦头图片,可以看到比赛困难点不仅仅是数据少,小麦头经常重叠、小麦头具有多种尺寸、小麦的外观颜色由于成熟度不同而各不相同,
由于在 kaggle 图像检测的比赛当中对于测试集的图片我们是无法查看的,只有在提交后代码运行才能调用测试集,因此我们在 kaggle 比赛使用需要对 Pseudo-label 的方法做些修改。
Step 1:将有标签部分数据分为两份:训练集和测试集,并训练出最优的 model1
Step 2:用训练好的 model 1 对一批未标记图像(测试集)进行预测,制作伪标签的过程中可以使用 Noisy Student 的方法,即通过图像翻折、旋转、缩放等对图像进行扩增,以此提升我们制作的伪标签的准确度,然后对预测的标签进行筛选选择大于预测阈值的标签作为伪标签。
Step 3:最后将有标签的数据(训练集)和伪标签的数据(测试集)一起进行 finetune model 1,通过验证集选取 best model。
3.2 阈值选取
在目标检测任务中使用 Pseudo-label 方法的关键在于如何设置好预测阈值,由于一张图片当中具有多个目标,如果只是选择预测概率较高的结果作为标签,那么一张图中就会有许多目标就没有被标记出来被当作负样本。
这样子制作的标签假负例(FN)过多,但是阈值也不能偏低太低的话会引入一些错误的假正例(FP)所以目标检测任务中的预测概率阈值成为伪标签制作的一个关键,不能太高但同时也不能太低(太低的话会引入一些错误的标签)。
在比赛我得到的关于阈值选取的经验是,当图像中目标较多的情况下选取的阈值应该要小一些这样可以避免较多的假负例,反之在目标少的情况选择的阈值应大一些,还有一个比较有效的方法是利用在训练集上训练好的模型通过滑动阈值(自动逐个尝试)先搜索出模型在验证集上取得较好效果的预测阈值,再通过微调这个阈值测试出最适合制作伪标签的阈值。
在使用 Semi-Supervised Learning 成绩为: 0.7720 ,没使用是 0.7522,增加了 0.0198,效果可以说是相当的明显了,排名提升了一百多名。
![]()
结论
可以看到,不论是小数据集,还是大数据集,Self training 都是一种有效的涨点方法,尤其是,在像 Kaggle 这样的比赛中,相信这项技术是很有用的,因为通常即使是轻微的分数提高也能让你在排行榜上得到提升。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
![]()
![]()