做目标检测,这一篇就够了!2019最全目标检测指南


-
图像分类:为图片中出现的物体目标分类出其所属类别的标签,如画面中的人、楼房、街道、车辆数目等; -
目标检测:将图片或者视频中感兴趣的目标提取出来,对于导盲系统来说,各类的车辆、行人、交通标识、红绿灯都是需要关注的对象; -
图像语义分割:将视野中的车辆和道路勾勒出来是必要的,这需要图像语义分割技术做为支撑,勾勒出图像物体中的前景物体的轮廓; -
场景文字识别:道路名、绿灯倒计时秒数、商店名称等,这些文字对于导盲功能的实现也是至关重要的。
-
R-CNN -
Fast R-CNN -
Faster R-CNN -
Mask R-CNN -
SSD (Single Shot MultiBox Defender) -
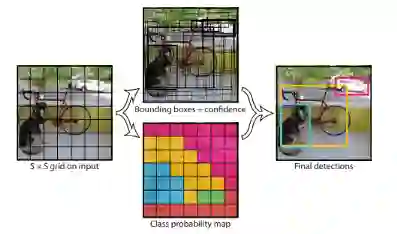
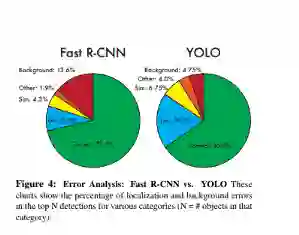
YOLO (You Only Look Once)


-
训练是一个多阶段的任务,调整物体区域的卷积神经网络,使SVM(支持向量机)适应ConvNet(卷积网络)功能,最后学习边界框回归; -
训练在空间和时间上都很昂贵,因为VGG16是占用大量空间的深层网络; -
目标检测很慢,因为它为每个候选区域都要执行ConvNet前向传播。
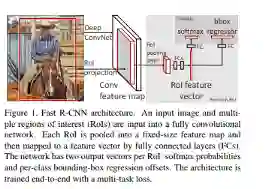
Fast R-CNN
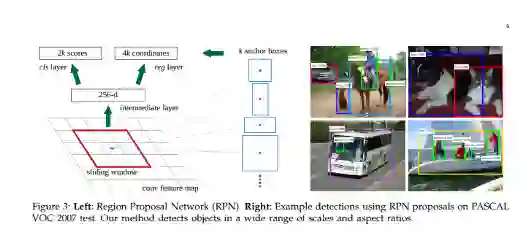
Faster R-CNN
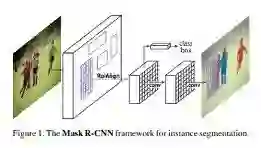
Mask R-CNN
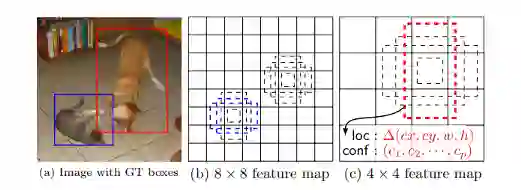
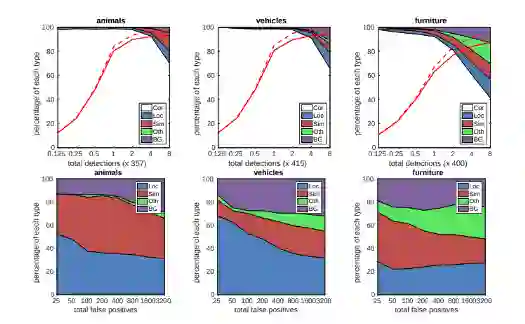
SSD: Single Shot MultiBox Detectorz





登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文