计算机视觉方向简介 | 目标检测最新进展总结与展望
点击上方蓝字关注、置顶、标星,获取一手信息
本文转载自“SIGAI人工智能学习与实践平台”(ID:SIGAICN)
导言
目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。由于深度学习的广泛运用,目标检测算法得到了较为快速的发展,本文广泛调研国内外目标检测方法,主要介绍基于深度学习的两种目标检测算法思路,分别为One-Stage目标检测算法和Two-Stage目标检测算法。
1. 相关介绍
1.1 背景介绍
从 2006 年以来,在 Hinton、Bengio、Lecun 等人的引领下,大量深度神经网络的论文被发表,尤其是 2012 年,Hinton课题组首次参加 ImageNet图像识别比赛,其通过构建的 CNN 网络AlexNet[1]一举夺得冠军,从此神经网络开始受到广泛的关注。深度学习利用多层计算模型来学习抽象的数据表示,能够发现大数据中的复杂结构,目前,这项技术已成功地应用在包括计算机视觉领域在内的多种模式分类问题上。计算机视觉对于目标运动的分析可以大致分为三个层次:运动分割,目标检测;目标跟踪;动作识别,行为描述[2]。其中,目标检测既是计算机视觉领域要解决的基础任务之一,同时它也是视频监控技术的基本任务。由于视频中的目标具有不同姿态且经常出现遮挡、其运动具有不规则性,同时考虑到监控视频的景深、分辨率、天气、光照等条件和场景的多样性,而且目标检测算法的结果将直接影响后续的跟踪、动作识别和行为描述的效果。故即使在技术发展的今天,目标检测这一基本任务仍然是非常具有挑战性的课题,存在很大的提升潜力和空间。
1.2 什么是目标检测
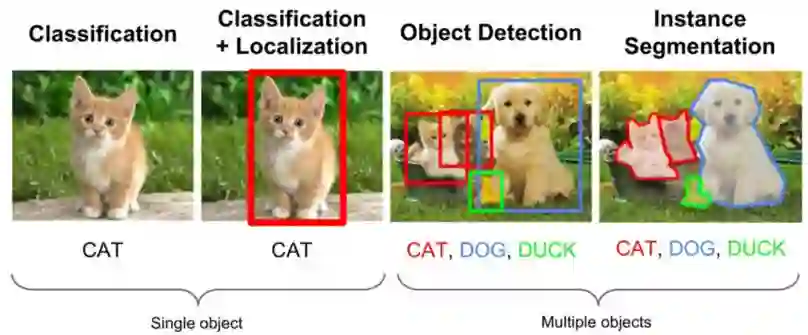
图1: 任务对比图
目标检测即找出图像中所有感兴趣的物体,包含物体定位和物体分类两个子任务,同时确定物体的类别和位置。
1.3 传统算法概述
传统目标检测的方法一般分为三个阶段:首先在给定的图像上选择一些候选的区域,然后对这些区域提取特征,最后使用训练的分类器进行分类。下面我们对这三个阶段分别进行介绍。
(1)区域选择:这一步是为了对目标的位置进行定位。由于目标可能出现在图像的任何位置,而且目标的大小、长宽比例也不确定,所以最初采用滑动窗口的策略对整幅图像进行遍历,而且需要设置不同的尺度,不同的长宽比。这种穷举的策略虽然包含了目标所有可能出现的位置,但是缺点也是显而易见的:时间复杂度太高,产生冗余窗口太多,这也严重影响后续特征提取和分类的速度和性能。
(2)特征提取:由于目标的形态多样性,光照变化多样性,背景多样性等因素使得设计一个鲁棒的特征并不是那么容易。然而提取特征的好坏直接影响到分类的准确性。其中,这个阶段常用的特征有 SIFT[3]、HOG[4]等。
2. 基于深度学习的目标检测算法
2.1 算法概述
目标检测任务可分为两个关键的子任务:目标分类和目标定位。目标分类任务负责判断输入图像或图像区域(Proposal)中是否有感兴趣类别的物体出现,输出一系列带分数的标签表明感兴趣类别的物体出现在输入图像或所选择图像区域(Proposal)中的可能性。目标定位任务负责确定输入图像或所选择图像区域(Proposal)中感兴趣类别的物体的位置和范围,输出物体的包围盒、或物体中心、或物体的闭合边界等,通常使用方形包围盒,即Bounding Box用来表示物体的位置信息。
目前主流的目标检测算法主要是基于深度学习模型,其可以分成两大类:
(1)One-Stage目标检测算法,这类检测算法不需要Region Proposal阶段,可以通过一个Stage直接产生物体的类别概率和位置坐标值,比较典型的算法有YOLO、SSD和CornerNet;
(2)Two-Stage目标检测算法,这类检测算法将检测问题划分为两个阶段,第一个阶段首先产生候选区域(Region Proposals),包含目标大概的位置信息,然后第二个阶段对候选区域进行分类和位置精修,这类算法的典型代表有R-CNN,Fast R-CNN,Faster R-CNN等。
目标检测模型的主要性能指标是检测准确度和速度,其中准确度主要考虑物体的定位以及分类准确度。一般情况下,Two-Stage算法在准确度上有优势,而One-Stage算法在速度上有优势。不过,随着研究的发展,两类算法都在两个方面做改进,均能在准确度以及速度上取得较好的结果。
2.2 One-Stage目标检测算法
One-Stage目标检测算法可以在一个stage直接产生物体的类别概率和位置坐标值,相比于Two-Stage的目标检测算法不需要Region Proposal阶段,整体流程较为简单。如下图所示,在Testing的时候输入图片通过CNN网络产生输出,解码(后处理)生成对应检测框即可;在Training的时候需要将Ground Truth编码成CNN输出对应的格式以便计算对应损失loss。
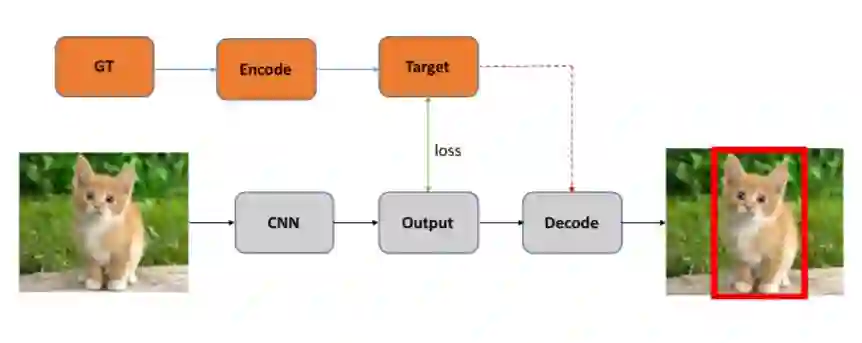
图2:One-Stage检测算法示意图
目前对于One-Stage算法的主要创新主要集中在如何设计CNN结构、如何构建网络目标以及如何设计损失函数上,接下来我将从这几个方面进行阐述。
2.2.1 如何设计CNN结构
设计CNN网络结构主要有两个方向,分别为追求精度和追求速度。最简单的一种实现方式就是替换Backbone网络结构,即使用不同的基础网络结构对图像提取特征。举例来说,ResNet101的表征能力要强于MobileNet,然而MobileNet的计算量要远远低于ResNet101,如果将ResNet101替换为MobileNet,那么检测网络在精度应该会有一定的损失,但是在速度上会有一定提升;如果将MobileNet替换为ResNet101,那么检测网络在速度上会有一定的损失,但是在精度上会有一定的提升。当然这只是一种相对简单的改进CNN网络结构的方式,实际上在改进CNN结构的时候需要很多的学术积累和经验,我将通过几篇SSD相关论文做一下简要分析。
SSD[5]:SSD检测算法的网络结构如下图所示,其中Backbone为VGG网络,使用不同阶段不同分辨率的feature map进行预测。
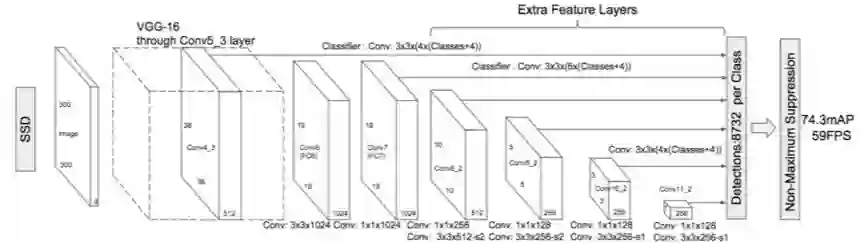
图3:SSD网络结构示意图
DSSD[6]:DSSD检测算法的网络结构如下图所示,DSSD也是使用不同阶段不同分辨率的feature maps进行预测,在不考虑Backbone网络结构差别的情况下,可以发现DSSD相比于SSD多了一系列的后续上采样操作,SSD是使用下采样过程中的feature maps进行预测,而DSSD是使用上采样过程中的feature maps进行预测。显而易见的是,SSD用于检测的feature maps位于网络的较低层,表征能力较弱,而DSSD用于检测的feature maps位于网络的较高层,表征能力较强,同时DSSD在反卷积的过程中通过Skip-Connection引入了较低层的feature maps,实现了一定程度的特征融合。所以DSSD的效果要优于SSD检测算法。

图4:DSSD网络结构示意图
FSSD[7]:FSSD检测算法的网络结构如下图所示,同样,FSSD也是使用不同阶段不同分辨率的feature maps进行预测,相比于SSD,FSSD多了一个特征融合处理,将网络较低层的特征引入到网络的较高层,在检测的时候能够同时考虑不同尺度的信息,使得检测更加准确。
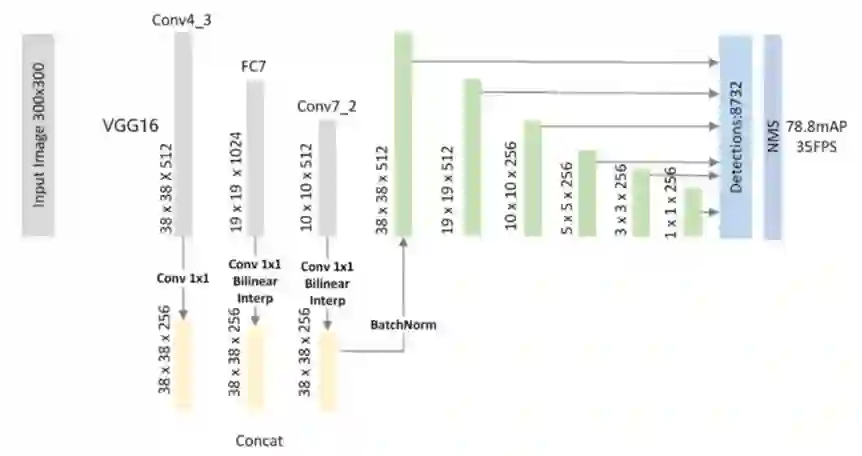
图5:FSSD网络结构示意图
2.2.2 如何构建回归目标
如何构建网络回归目标即如何区分正负样本使其与卷积神经网络的输出相对应,最简单直接的方法是直接回归物体的相关信息(类别和坐标),稍微复杂一些,在回归坐标时可以回归物体坐标相对于anchor的偏移量等等。对于One-Stage检测方法主要有如下三种典型的回归目标构建方式,其中代表方法分别为YOLO系列算法、SSD系列算法以及CornerNet目标检测算法。
YOLO系列算法:如下图所示,其中左图取自YOLOv1[8],右图取自YOLOv2[9],需要说明的是YOLOv1相比于YOLOv2在坐标回归的时候没有anchor的概念。YOLO系列算法在构建回归目标时一个主要的区别就是如果将图像划分成SxS的格子,每个格子只负责目标中心点落入该格子的物体的检测,如果没有任何目标的中心点落入该格子,则为负样本。
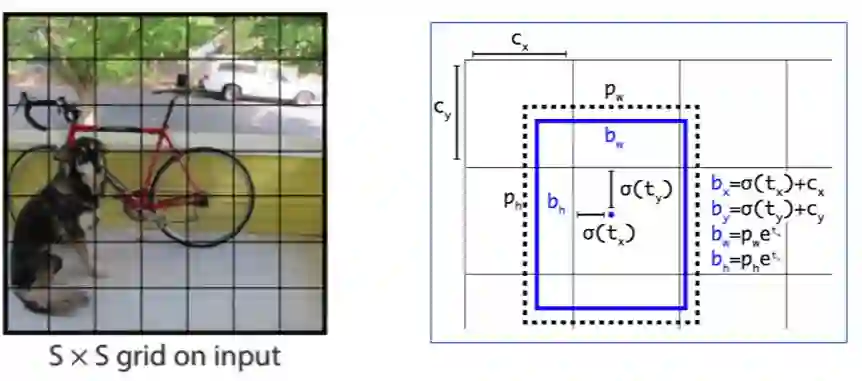
图6:YOLO系列算法正负样本区分图
SSD系列算法:如下图所示,SSD系列检测算法在确定正负样本的时候通过交并比大小进行区分,当某一个Ground Truth的目标框与anchor的交并比最大且对应的交并比大于某一个阈值的时候,对应anchor即负责检测该Ground Truth,即每一个anchor最多负责一个物体的检测,同一个物体可能被多个anchor同时检测。

图7:IOU(交并比)示意图
CornerNet[10]:如下图所示,CornerNet检测算法巧妙的将检测框转换成了关键点,即一个目标框可以由两个点(左上角和右下角)来表示,那么对于一个目标物体在预测的时候就可以直接预测两个类别的关键点,然后对关键点进行组合即可生成对应的目标框。

图8:CornerNet目标示意图
2.2.3 如何设计损失函数
目标检测算法主要分为两个子任务,分别为物体分类和物体定位。损失主要包括分类损失(Cls Loss)和定位损失(Loc Loss),常见的损失组合主要有如下两种Cls Loss + Loc Loss(SSD系列算法)、Cls Loss + Obj Loss + Loc Loss (YOLO系列算法),其中YOLO系列算法相比于SSD系列算法多了Object Loss,即判断对应区域是否为物体的损失。除此之外,One-Stage目标检测算法的正负样本不均衡的问题比较严重,对于设计损失函数还会有一些针对创新。
Hard Negative Mining:即对于大量的负样本只挑取其中适当比例的损失较大的负样本来计算损失,其余损失较小的负样本忽略不计,防止负样本过多干扰网络学习;
Focal Loss:由于大多数都是简单易分的负样本(属于背景的样本),使得训练过程不能充分学习到属于那些有类别样本的信息;其次简单易分的负样本太多,可能掩盖了其他有类别样本的作用。Focal Loss希望那些hard examples对损失的贡献变大,使网络更倾向于从这些样本上学习。
需要说明的是,个人任务One-Stage检测算法和Two-Stage检测算法的第一个Stage并没有太大区别,在某种程度上Two-Stage检测算法的第一个Stage可以看成是One-Stage检测算法,而第二个Stage只是对前一个Stage的结果做进一步精化,上述所有思路本人觉得都适用于Two-Stage检测算法的第一个Stage。除此之外针对于Two-Stage检测框架设计的相关损失函数同样适用于One-Stage检测算法,如针对遮挡问题设计的相关loss,具体不再阐述。
2.3 Two-Stage目标检测算法
Two-Stage目标检测算法本人认为可以看作是进行两次One-Stage检测,第一个Stage初步检测出物体位置,第二个Stage对第一个阶段的结果做进一步的精化,对每一个候选区域进行One-Stage检测。整体流程如下图所示,在Testing的时候输入图片经过卷积神经网络产生第一阶段输出,对输出进行解码处理生成候选区域,然后获取对应候选区域的特征表示(ROIs),然后对ROIs进一步精化产生第二阶段的输出,解码(后处理)生成最终结果,解码生成对应检测框即可;在Training的时候需要将Ground Truth编码成CNN输出对应的格式以便计算对应损失loss。

图9:Two-Stage检测算法示意图
如上图所示,Two-Stage的两个阶段拆开来看均与One-Stage检测算法相似,所以我觉得Two-Stage可以看成是两个One-Stage检测算法的组合,第一个Stage做初步检测,剔除负样本,生成初步位置信息(Region of Interest),第二个Stage再做进一步精化并生成最终检测结果。目前对于Two-Stage算法的主要创新主要集中在如何高效准确地生成Proposals、如何获取更好的ROI features、如何加速Two-Stage检测算法以及如何改进后处理方法,接下来我将从这几个方面进行阐述。
2.3.1 如何高效准确地生成Proposals
如何高效准确地生成Proposals考虑的是Two-Stage检测算法的第一个Stage,获取初步的检测结果,供下一个Stage做进一步精化。接下来我将通过对比R-CNN、Faster R-CNN和FPN来做简要说明。
R-CNN[11]:R-CNN生成Proposals的方法是传统方法Selective Search,主要思路是通过图像中的纹理、边缘、颜色等信息对图像进行自底向上的分割,然后对分割区域进行不同尺度的合并,每个生成的区域即一个候选Proposal,如下图所示。这种方法基于传统特征,速度较慢。
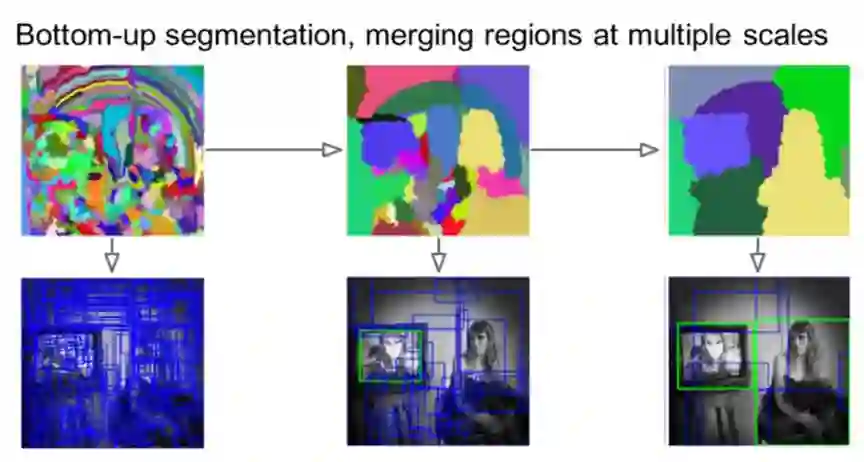
图10:Selective Search示意图
Faster R-CNN[12]:Faster R-CNN使用RPN网络代替了Selective Search方法,大大提高了生成Proposals的速度,具体实现策略同One-Stage检测算法,这里不再做过多赘述。网络示意图如下图所示。
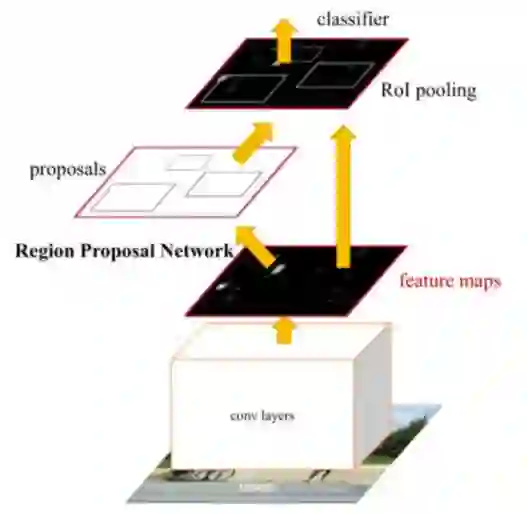
图11:Faster R-CNN网络示意图
FPN[13]:Faster R-CNN只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。FPN算法把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征进行自上而下的侧边连接,使得所有尺度下的特征都有丰富的语义信息,然后在不同尺度的特征层上进行预测,使得生成Proposals的效果优于只在顶层进行预测的Faster R-CNN算法。如下图所示。

图12:FPN Proposal网络示意图
Cascade R-CNN[14]:类似于Faster R-CNN、FPN等,其Proposal网络对于正样本只设置了一个阈值,只做了一次较为宽松的约束,得到的Proposals结果较为粗糙,当对检测框的定位结果要求更为精确的时候就稍显不足。而Cascade R-CNN在获取Proposals的时候也采用逐步求精的策略,前一步生成的Proposals作为后一步的输入,通过控制正样本的交并比阈值不断提高Proposals的质量,如下图所示。准确来说,Cascade R-CNN应该不能算Two-Stage检测算法,应该是多Stage检测算法,多步求精。
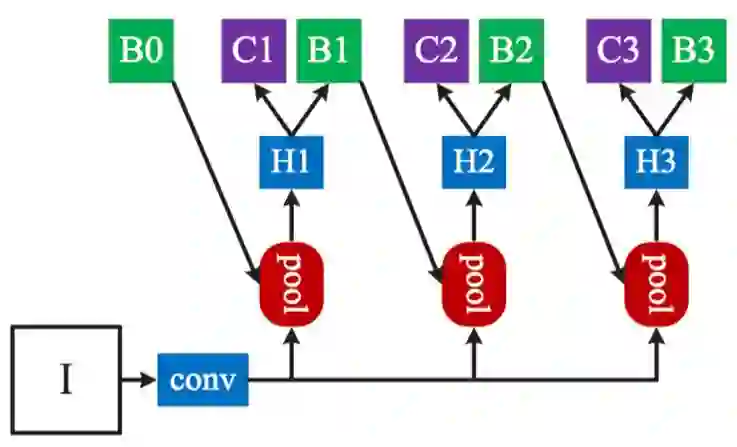
图13:Cascade R-CNN Proposal网络示意图
2.3.2 如何获取更好的ROI features
在获取Proposals之后,如何获取更好的ROI features是Two-Stage检测算法第二个Stage的关键,只有输入比较鲁棒的情况下才能得到较好的输出。对于这个问题主要考虑的有两个方向,其一是如何获取Proposals的features,其二是得到Proposals的features之后如何align到同一个尺度。首先对于第一个问题主要有如下几种策略:
R-CNN:在原图裁剪Proposals对应区域,然后align到同一个尺度,分别通过对每一个alignalign 之后的原图区域通过神经网络提取特征;
Fast/Faster R-CNN:对原图提取一次特征,将对应Proposals的坐标映射到提取的feature map上提取对应特征;
FPN:对原图提取不同尺度的特征,将不同尺度的Proposals映射到不同尺度的feature map上提取对应特征;
R-FCN[15]:同样只对原图提取一次特征,主要区别是提取目标特征的同时加上了位置信息(Position-Sensitive),即目标的不同区域的特征维护在不同channels上,对于一个候选目标Proposal,其不同区域区域的特征需要映射到原图特征的不同channels上。如下图所示。
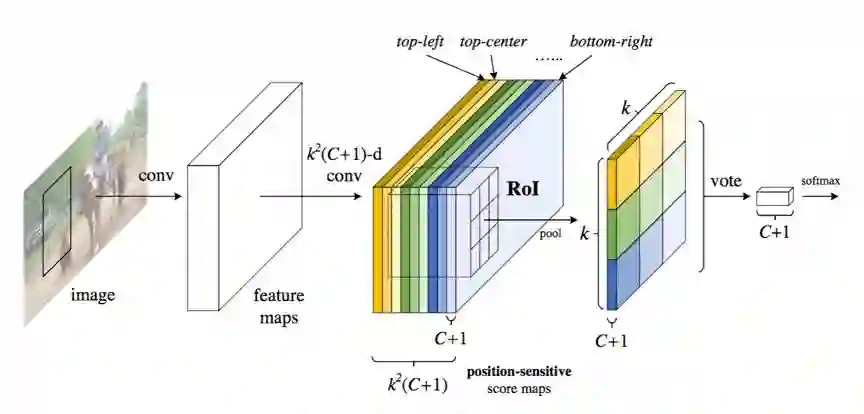
图14:R-FCN网络示意图
其次对于第二个问题主要有如下几种策略,分别为ROI Pool、ROI Align、PSROI Pool、PrROI Pool,接下来做简要说明。
ROI Pool:即对Proposal区域分割固定大小的格子,每个格子做Adaptive的Pooling操作,获取一个值,从而所有Proposal生成同样大小的输出。
ROI Align:主要解决了ROI Pool的量化误差问题,即浮点数坐标转换成整数坐标产生的误差,主要解决方式即不采用量化方式获取具体坐标,每个格子的值通过采样多个点获得,其中被采样点的值采用双线性插值的方式获得,不需要量化成整数坐标。
PSROI Pool:即R-FCN采用的Pooling方式,与ROI Pool的唯一区别在于PSROI Pool需要每一个Proposal的不同区域对应到feature map的不同channels进行取值。
PrROI Pool:即Precise ROI Pooling,其考虑了Proposal对应格子区域的每个值,采用积分的方式进行求解,而ROI Align只Sample对应格子区域的几个值。

图15:ROI 策略对比图
2.3.3 如何加速Two-Stage检测算法
Two-Stage检测算法在一般情况下要慢于One-Stage检测算法,然而随着研究的发展,速度上的差别也在逐渐缩小,Two-Stage算法的开销主要有两部分,一个是Proposal的开销,一个是ROI Sub-Network的开销,提高Region Proposal的效率和降低ROI Sub-Network的开销均可以加速Two-Stage检测算法。
Fast R-CNN vs. Faster R-CNN:Faster R-CNN使用神经网络代替Selective Search,大大提高了Region Proposal的的速度,前面已有描述。
Faster R-CNN vs. Light-Head R-CNN[16]:Light-Head R-CNN使用更小的Sub-Network代替Faster R-CNN较为臃肿的Sub-Network,使得第二阶段的网络更小,大大提高了Two-Stage检测算法的速度。
2.3.4 如何改进后处理方法
这里所说的后处理方法仅指NMS相关算法,NMS即非极大值抑制算法,在目标检测,定位等领域是一种被广泛使用的方法,主要目的是为了消除多余的框,找到最佳的物体检测的位置,几乎所有的目标检测方法都用到了这种后处理算法。接下来我将简要介绍如下几种NMS相关算法,分别为NMS、Soft NMS、Softer NMS、IOU-Guided NMS。

图16:NMS示例
Soft NMS[17]:Soft NMS相对于NMS的改进即每次并不是直接排除掉和已选框重叠大于一定阈值的框,而是以一定的策略降低对应框的得分,直到低于某个阈值,从而不至于过多删除拥挤情况下定位正确的框。
Softer NMS[18]:Softer NMS相对于NMS的改进即每次并不是直接以得分最大的框的坐标作为当前选择框的坐标,而是和得分最大的框重叠大于一定阈值的所有框的坐标进行一定策略的加权平均,所得的新的框作为当前选择的得分最大的框的坐标,从而尽可能准确地定位物体。
IOU-Guided NMS[19]:即以IOU(交并比)得分作为NMS的排序依据,因为IOU得分直接反应了对应框的定位精确程度,优先考虑定位精度较高的框,防止定位精度较低但是其他得分较高的框被误排序到前面。
小结
目标检测至今仍然是计算机视觉领域较为活跃的一个研究方向,虽然One-Stage检测算法和Two-Stage检测算法都取得了很好的效果,但是对于真实场景下的应用还存在一定差距,目标检测这一基本任务仍然是非常具有挑战性的课题,存在很大的提升潜力和空间。
欢迎关注https://github.com/youansheng
参考文献
[1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in neural information processing systems, 2012, pp. 1097–1105.
[2] Vishwakarma S, Agrawal A. A survey on activity recognition and behavior understanding in video surveillance [J]. The Visual Computer, 2012: 1-27.
[3] D. Lowe. Distinctive image features from scale-invariant keypoints. IJCV, 2004.
[4] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In CVPR, 2005.
[5] Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." European Conference on Computer Vision Springer International Publishing, 2016:21-37.
[6] Fu C Y, Liu W, Ranga A, et al. DSSD : Deconvolutional Single Shot Detector[J]. 2017.
[7] Li Z, Zhou F. FSSD: Feature Fusion Single Shot Multibox Detector[J]. 2017.
[8] Redmon, Joseph, et al. "You Only Look Once: Unified, Real-Time Object Detection." (2015):779-788.
[9] Redmon, Joseph, and A. Farhadi. "YOLO9000: Better, Faster, Stronger." (2016):6517-6525.
[10] Law H, Deng J. CornerNet: Detecting Objects as Paired Keypoints[J]. 2018.
[11] Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR 2014.
[12] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In Neural Information Processing Systems (NIPS), 2015.
[13] Lin T Y, Dollár P, Girshick R, et al. Feature Pyramid Networks for Object Detection[J]. 2016.
[14] Cai Z, Vasconcelos N. Cascade R-CNN: Delving into High Quality Object Detection[J]. 2017.
[15] Dai J, Li Y, He K, et al. R-FCN: Object Detection via Region-based Fully Convolutional Networks[J]. 2016.
[16] Li Z, Peng C, Yu G, et al. Light-Head R-CNN: In Defense of Two-Stage Object Detector[J]. 2017.
[17] Bodla N, Singh B, Chellappa R, et al. Soft-NMS — Improving Object Detection with One Line of Code[J]. 2017.
[18] Softer-NMS: Rethinking Bounding Box Regression for Accurate Object Detection. arxiv id:1809.08545
[19] Jiang B, Luo R, Mao J, et al. Acquisition of Localization Confidence for Accurate Object Detection[J]. 2018.




