无监督学习中的目标检测
无监督学习是当今计算机视觉领域最困难的挑战之一。这项任务在人工智能和新兴技术中有着巨大的实用价值,因为可以用相对较低的成本收集大量未标注的视频。
——————
01 概述
——————
今天,我们介绍的这个技术在对单个图像中的主要前景目标进行检测的背景下,研究了无监督学习问题。我们训练student deep network预测teacher路径的输出,该路径在视频或大型图像集合中执行无监督的目标发现。该方法不同于已发表的无监督目标发现方法。
在训练期间,移动无监督学习阶段,然后在测试阶段沿着student路径应用标准的前向处理。这种策略的好处是可以在训练期间增加泛化的可能性,同时保持测试的快速性。该无监督学习算法可以跨越几代student-teacher的训练。
因此,一群在第一代中接受训练的student deep network共同造就了下一代的teacher。实验表明,该方法在视频目标发现、无监督图像分割和显着性检测三个方面取得了较好的效果。在测试时,所提出的系统速度快,比已发表的无监督方法快一到两个数量级。
——————
02 背景
——————
无监督学习是当今计算机视觉和机器学习中最困难、最重要的问题之一。许多研究人员认为,从大量未贴标签的视频中学习可以帮助破解有关智力和学习本质的难题。此外,由于未标注的视频易于以较低的成本收集,因此无监督学习在许多计算机视觉和机器人应用中具有实际的实用价值。今天介绍的,就是提出了一种新的无监督学习方法,它成功地解决了与此任务相关的许多挑战。
提出了一个系统,该系统由两条主要路径组成,一条是在视频或大型图像集合中沿teacher分支进行无监督的目标发现,另一种是student分支,它向teacher学习,在单个图像中检测前景目标。该方法是普遍的,因为student或teacher的路径不依赖于特定的神经网络架构或实现。此外,该方法允许无监督的学习过程在数代student和teacher中继续进行。在算法1中,给出了该方法的高级描述。
也会将在整个技术中交替使用算法1的“生成”和“迭代”两个术语。这项工作的初步版本,在几个领域没有提出学习的可能性,而且在2017年ICCV上出现的实验结果也较少(Croitoru等人(2017年)。
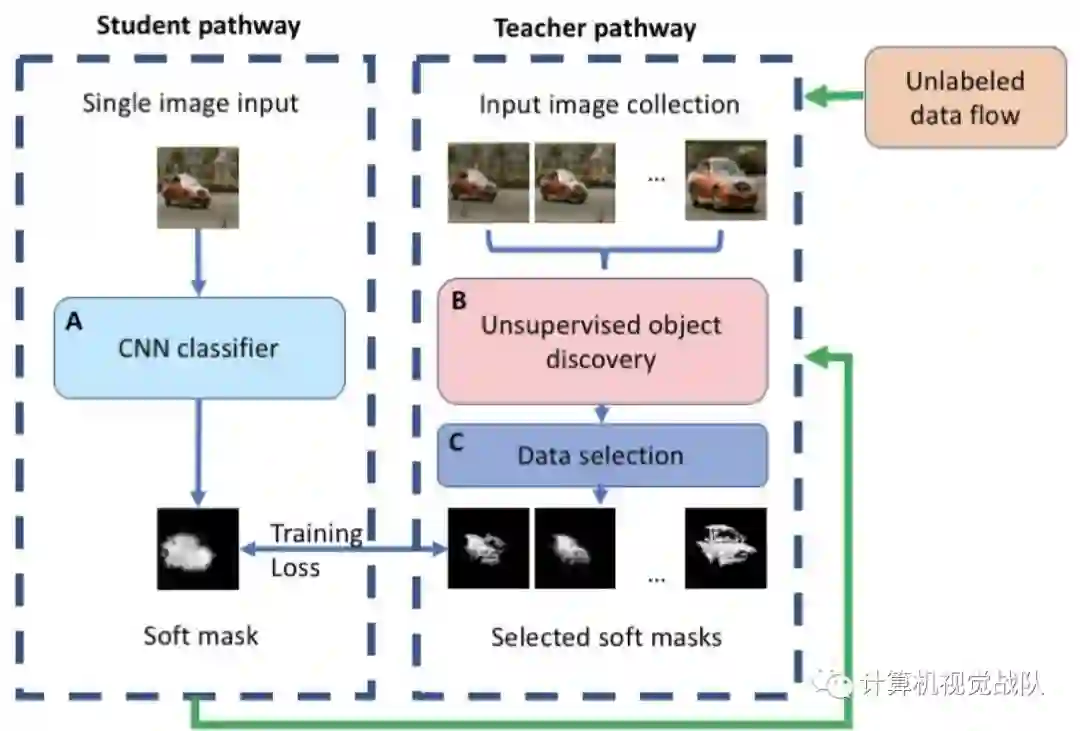
在上图中,展示了整个系统的图表概述。在无监督训练阶段,student网络(模块A)从无监督的teacher路径(模块B和模块C)逐帧学习,在单个图像中产生相似的目标掩码。Student分支试图对每一帧输入teacher的输出,同时作为输入只有一个图像-当前帧。另一方面,teacher可以访问整个视频序列。算法1中提出的方法在从一次迭代(生成)到下一次迭代(生成)过程中遵循系统的主要步骤。下面将更详细地讨论这些步骤。
————————
03 总体方法
————————
提出了一种真正的无监督学习的前景目标检测算法,为前景目标检测提供了经过多次迭代改进的可能性。该方法以互补的方式结合了适合这个任务的多个模块。它从teacher路径开始,在未标记的视频中发现对象,并在每个帧中生成前景目标的soft-mask。产生的低质量soft-mask然后被自动过滤掉。
接下来,将剩下的内容传递给Student ConvNet,后者学习在单个图像中预测目标掩码。当几个不同架构的Student ConvNet被学习后,他们为下一代形成了一个新的teacher,然后整个过程被重复。在下一次迭代中,引入更多未标注的数据,以无监督的方式学习更好的数据选择机制,并最终训练出更强大的Student ConvNet。在算法1中,简要地列举了该方法的主要步骤。

Figure 1
————————
04 系统框架
————————
4.1 Student Path:单图像分割
Student处理路径(图1中的模块A)由一个深层次的卷积网络组成。测试了不同的神经网络体系结构,其中一些在最近关于语义图像分割的文献中得到了广泛的应用。于是,创建了一个由相对多样化的体系结构组成的small pool,接下来将介绍。
测试的第一个用于语义分割的卷积网络结构是基于更传统的CNN设计的。由于它的低分辨率Soft-mask输出,称它为LowRes-net(见Figure 2)。它有十个层(七个卷积层、两个池化层和一个全连接层)和skip connections。
事实证明,skip connection可以提高性能,如文献所示(Raiko等人(2012年);Pinheiro等人(2016年)。我们还观察到,在使用skip connection时,实验也有类似的改进。LowRes-net以128×128 RGB图像(以及它的色调、饱和度和导数w.r.t.x和y)作为输入,并对图像中的主要目标进行32×32的软分割。由于LowRes-net在顶部有一个全连接层,因此降低软分割掩码的输出分辨率,以限制内存开销。虽然w.r.tx和y在原则上是不需要的(因为它们可以在训练期间通过适当的过滤器来学习),但是在测试中,明确地提供了与HSV一起的衍生产品,并且使用了skip connection,使准确率提高了1%以上。LowRes-net共有78M个参数,大部分都在最后一个全连接的层中。
Raiko等人(2012年):
Raiko T, Valpola H, LeCun Y (2012) Deep learning made easier by linear transformations in perceptrons. In: AIS- TATS, vol 22, pp 924–932
Pinheiro等人(2016年):
Pinheiro PO, Lin TY, Collobert R, Dolla ́r P (2016) Learning to refine object segments. In: ECCV
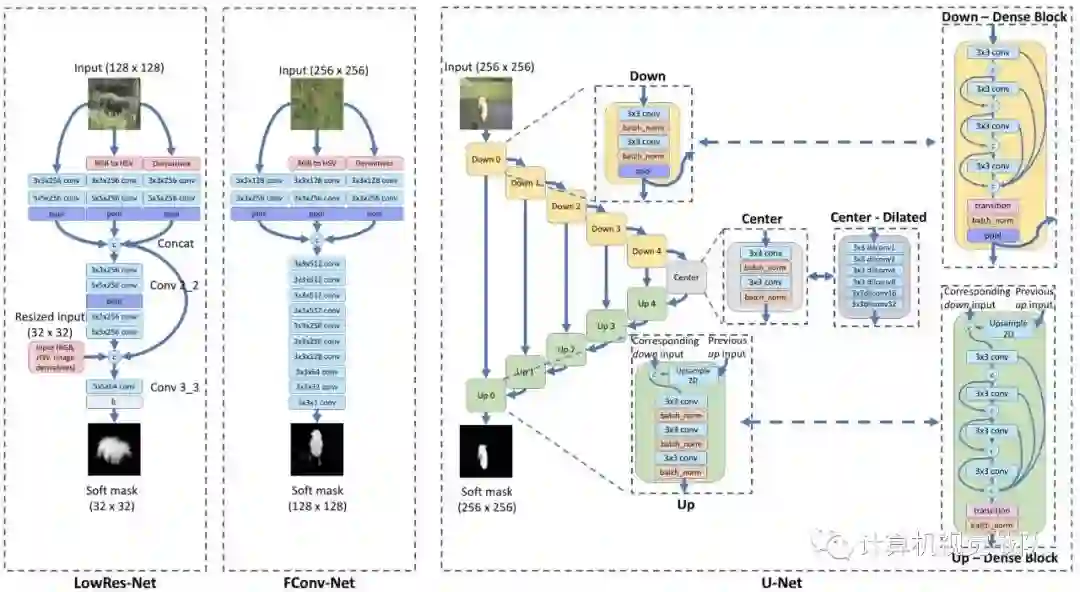
Figure 2
4.2 Teacher Path:在视频中无监督挖掘
VideoPCA:
视频主成分分析的主要思想是对视频帧中的背景进行主成分分析。利用主成分分析(PCA)模型,将初始前景区域作为帧的一部分进行重建。前景物体比背景小,具有鲜明的外观和更复杂的运动。它们可以被看作是孤立点,在更大的背景场景中。这使得它们不太可能被第一个PCA组件很好地捕获。因此,对于每个帧,一个初始soft-mask是从一个错误图像处理,这是原始图像和PCA重建之间的差异。这些误差图像首先用大高斯滤波器平滑,然后进行阈值处理。所获得的二值掩码用于学习前景和背景的颜色模型,根据这些模型将单个像素划分为属于前景或不属于前景。根据前景物体往往更接近图像中心的假设,所获得的目标掩码与大中心高斯进一步相乘。这些是系统中使用的最后一个掩码。关于更多技术细节,请阅读Stretcu和Leordeanu(2015年)。
在本工作中使用的方法与在(https://sites.google.com/site/multipleframesmatching/)中发现的方法完全相同,无需任何参数调整。
Stretcu和Leordeanu(2015年):
Stretcu O, Leordeanu M (2015) Multiple frames matching for object discovery in video. In: BMVC
下一代teacher path:
在算法1的下一次迭代中,用在前一次迭代中训练的Student ConvNet以下列方式取代VideoPCA(模块B)。虽然可以使用两个组件中的任何一个多网或多选择网作为新模块B,但为了更简单、更有效的方法。
对于每个未标记的训练图像,运行所有的Student ConvNet并获得多个soft-mask,而不是将它们组合在一起来产生每个图像的单个输出。因此,新模块B是所有Student ConvNet并行工作的集合。然后,它们的soft-mask由图1中的新模块C独立过滤(使用给定的阈值),该模块在EvalSeg-net的第二次迭代中表示。
注意,以这种方式可以为给定的训练图像获得一个、几个或没有软分割。这种方法是快速的,它提供了在多个GPU上并行处理数据的优点,而不必等待所有的Student ConvNet完成每个输入图像。实验表明,该方法也是有效的,在第二代时取得了更好的效果。
Mask 选择评价:
在Figure 3中,给出了分割性能w.r.t真实的目标框(仅用于评估)与自动选择后保持的掩码百分位数之间的依赖关系(用于两代人)。我们注意到保持帧的百分比与分割质量之间存在很强的相关性。同样明显的是,EValSeg-net比迭代1中使用的更简单的过程要好得多。即使在更复杂的情况下,EvaSeg-net也能够正确地评估软分段(见Figure 4)。
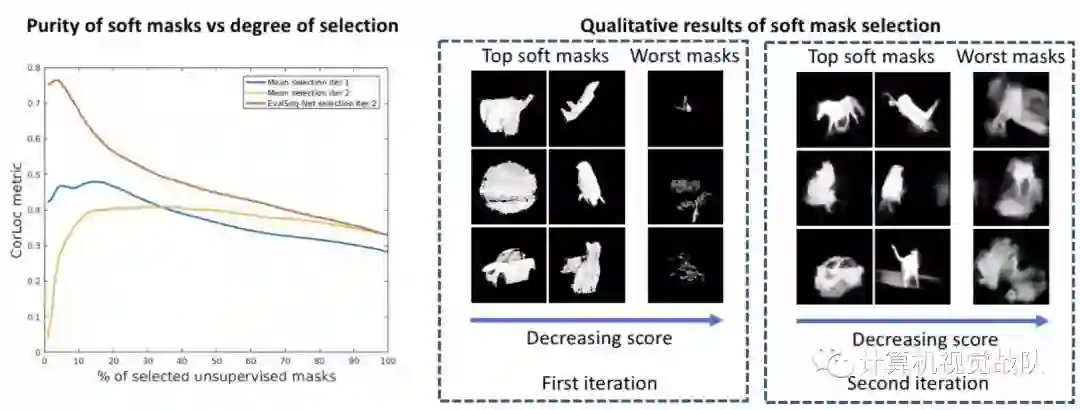
Figure 3

Figure 4
计算和储存费用:
在训练过程中,算法1第一次迭代期间通过teacher path的计算时间约为2-3天:它需要处理来自VID和YTO数据集的数据,包括运行VideoPCA模块。
然后,训练第一次迭代的Student,可以访问6个GPU,大约需要5天-训练5个不同的student体系结构需要6个GPU,因为FConv-net的训练需要两个GPU并行。
接下来,在一个GPU上训练EvalSeg-net需要额外4天。
在第二次迭代中,通过teacher path处理数据需要在6个GPU上并行处理大约3周-由于使用EvalSeg-net只从其中选择了很小的百分比(约10%)的更大的训练集,因此成本更高。最后,训练第二代student需要2周的时间。
总之,训练所需的总计算时间(完全可以访问6个GPU)大约是7周,此时一切都进行了优化。总存储成本约为4TB。在测试时,Student Net速度很快,每幅图像花费0.02秒,而集合网每幅图像花费大约0.15秒。
———————
05 实验
———————
在YouTube Objects v1上的结果

在Internet Images上的结果

在Pascal-S上的结果

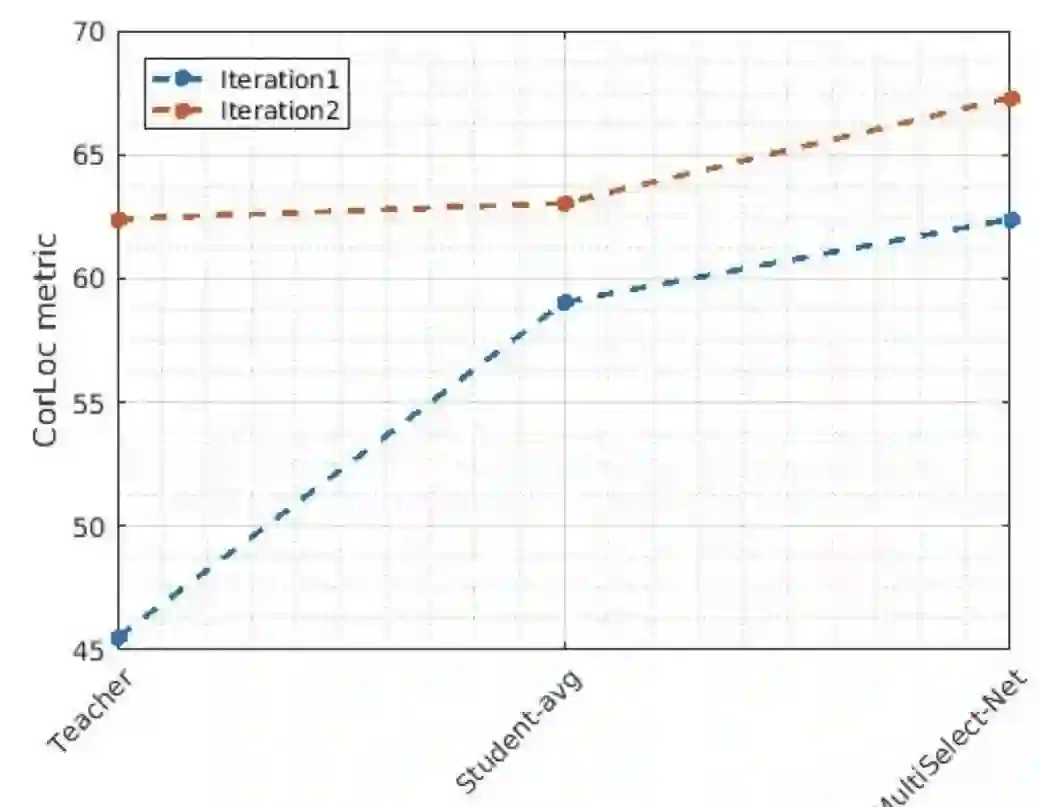
Teacher,individual student nets和组合的比较,跨越两代(蓝线-第一次迭代;红线-第二次迭代)。Individual student在两次迭代中都优于teacher,而组合甚至比individual nets更强。对于第二个迭代teacher,集成的MultiSelect-Net版本(因为这是一个上限)。图是根据YouTube对象数据集上的结果使用CorLoc度量(百分比)计算的。
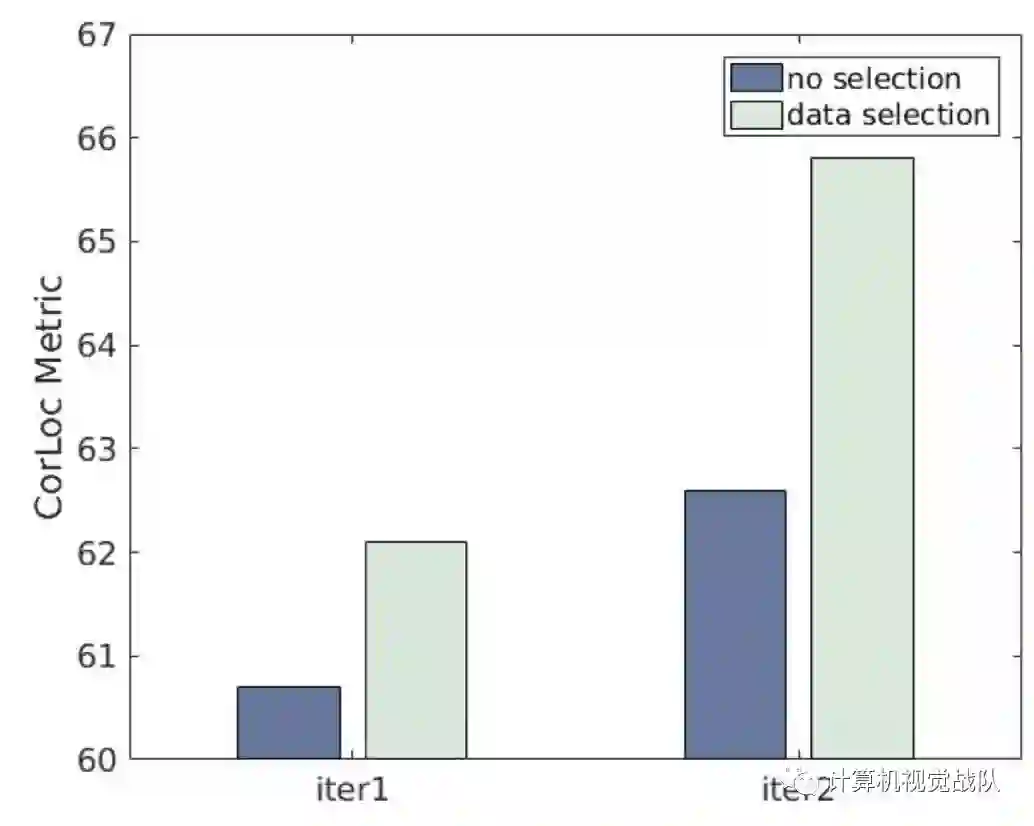
数据选择对两次迭代的影响
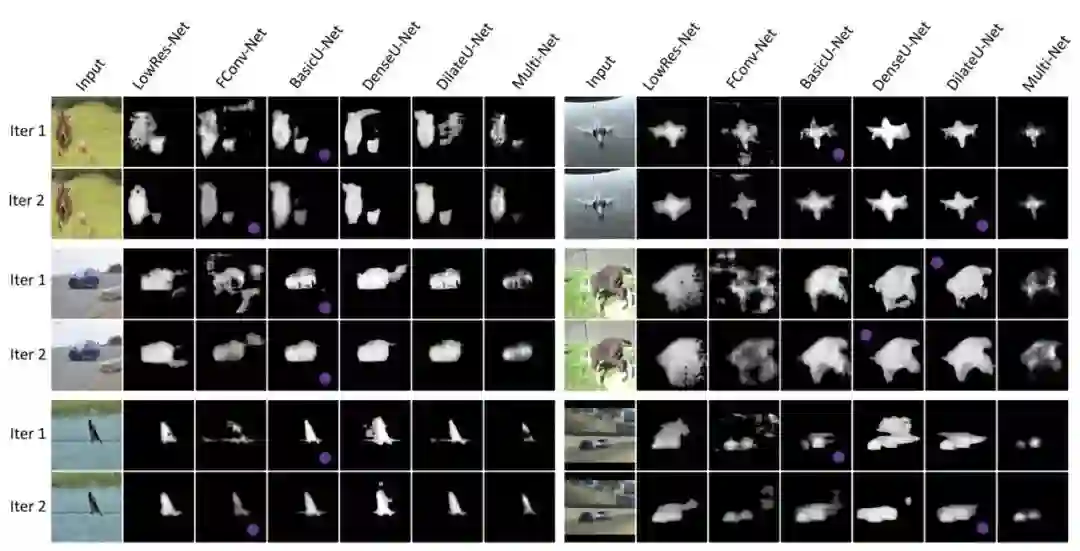
每次迭代时模型之间的视觉比较(生成)。用一个紫色的点标记了MultiSelect-net的输出(EvalSeg-net是最优秀的student soft-mask)。Multi-net表示五种模型之间的像素相乘,注意第二代的高级mask,有更好的形状,更少的洞和更锋利的边缘。

VID数据集的定性结果

关于Object Discovery数据集的定性结果与(B)Rubinstein等人(2013年)相比
Rubinstein等人(2013年):
Rubinstein M, Joulin A, Kopf J, Liu C (2013) Unsupervised joint object discovery and segmentation in internet im- ages. In: CVPR

Internet Images中物体发现的定性结果
—————————
06 总结&展望
—————————
在本次分享中,内容较多,现在我慢慢给大家总结。
首先,提出了一种新的、有效的视频学习方法,在没有监督的情况下,在单个图像中检测前景目标。针对这一任务,提出了一种相对通用的算法,为几代student和teacher的学习提供了可能。在实践中证明,该系统在两代人的过程中提高了性能。还测试了不同的系统组件对性能的影响,并在三个不同的数据集上显示了最新的结果。
据我们所知,这是第一个系统,学习检测和分割前景对象的图像以无监督的方式,没有预先训练的特征或手动标记,在测试时间而只需要一张图像。
沿着student路径训练的卷积网络能够学习一般的“客观”特征,包括良好的形式、闭包、平滑的轮廓以及与背景的对比。随着时间的推移,最初的视频PCA teacher发现了什么,深而复杂的student能够在不同抽象层次的几层现代特征中学习。
关于转移学习实验的结果也是令人鼓舞的,并且显示了这样一个系统可能有用的更多的例子。在今后的工作中,将计划进一步提高计算和存储能力,以演示提出的无监督学习算法的强大能力,以及许多代student和teacher nets。
我们相信,该方法在广泛的实验中测试,对于计算机视觉研究将带来宝贵的贡献。
———————————————
07 “计算机视觉战队”
———————————————
文章下载地址:
https://pan.baidu.com/s/1lc16TvAtQpyB4C7FrexVNA
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群,我们一起学习进步,探索领域中更深奥更有趣的知识!



