
半监督学习(Semi-supervised Learning, SSL)提供了一种利用未标记数据改进模型性能的有效方法。Google研究院近期在论文《FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence》中提出了一种简单粗暴却极其有效的半监督学习方法FixMatch。
论文展示了将两种常见半监督学习方法(一致性正则化和伪标签)简单结合后产生的威力。论文提出的FixMatch方法首先利用模型为经过弱增强的无标签图像生成伪标签。对于给定的图像,只有在模型产生高可信预测时,才保留伪标签。然后,该模型被训练来预测当输入同一图像的强增强版本时的伪标签。
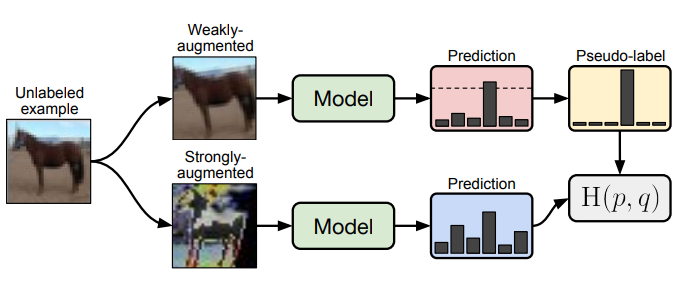
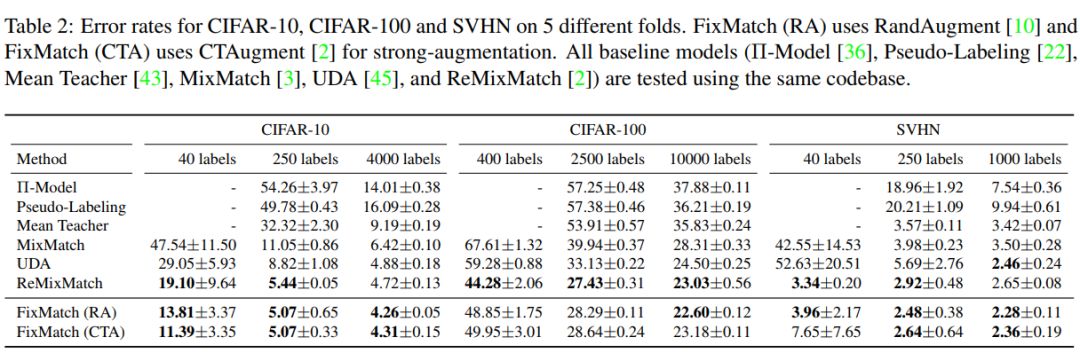
尽管这个模型很简单,但论文展示了FixMatch在各种标准的半监督学习基准测试中都取得了最先进的性能,包括在CIFAR-10上使用250个标签获得94.93%的准确率,使用40个标签(相当于每个类只有4个标签)获得88.61%的准确率。由于FixMatch与现有的性能更差的半监督学习方法有许多相似之处,论文中进行了大量的消去测试,以梳理出对FixMatch成功最重要的实验因素。
论文开源了代码:
- https: //github.com/google-research/fixmatch
简单介绍一下上面提到的两种常见半监督学习方法:
-
一致性正则化(Consistency Regularization): 它是当前许多最先进的半监督学习算法的重要组成部分。一致性正则化依赖以下假设来利用未标注数据:当输入扰动版本的图像时,模型应该输出相似的预测。
-
伪标签(Pseudo-labeling): 它的核心思想是利用模型自身来为未标注数据生成标签。该方法几十年前就被提出。伪标签特别指使用“硬”标签(模型输出中概率最高的标签)并且只保留概率大于指定阈值的标签。
FixMatch通过将这两种已有的方法进行简单的组合,取得了惊人的效果:
更多详细内容可以参考论文原文《FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence》:



