【泡泡图灵智库】不基于传感器的深度估计: 利用单目视频进行结构性的无监督学习(CVPR)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
作者:Vincent Casser,Soeren Pirk,Reza Mahjourian,Anelia Angelova
来源:CVPR 2018
编译:杨宇超
审核:谭艾琳
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Depth Prediction Without the Sensors : Leveraging Structure for Unsupervised Learning from Monocular Videos,该文章发表于CVPR 2018。
从RGB图像中估计场景深度,对于室内和室外机器人导航都是一项具有挑战性的任务。在本文工作中,作者探究了基于无监督学习的场景深度估计和机器人的帧间运动估计,将单目视频序列作为监督对象而不是原始深度信息,因为相机是机器人最便宜、限制最少和最普遍的传感器。之前在无监督图像深度估计方面的工作已经在该领域建立了强大的基线。本文提出了一种新的方法,它可以产生更高质量的结果,能够对移动的对象建模,并且可以跨数据域进行传输,例如从室外场景迁移到室内场景。主要思想是在学习过程中引入几何结构,通过对场景和个体对象的建模;摄像机的帧间运动和物体运动是通过单眼视频作为输入来学习的。在此基础上,提出了一种在线改进方法,将动态学习应用于未知领域。
主要贡献
1.本文探究了基于无监督学习的场景深度估计和机器人的帧间运动估计的方法。
2. 提出了一种新的方法,可以建模动态场景的对象运动,并可以选择性地适应其学习策略的在线细化技术。
3.提出了一种在线改进方法,将动态学习应用于未知领域。
算法流程
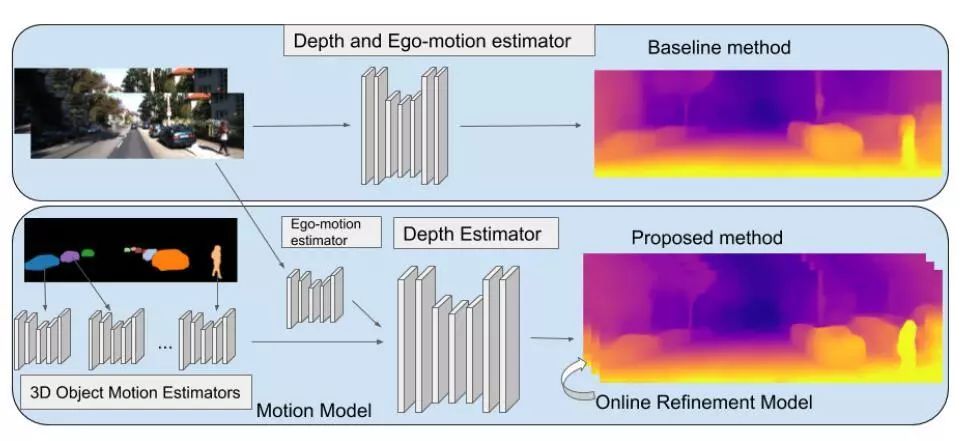
图1 本文方法的流程图
该方法在学习过程中引入了三维几何结构,通过对单个物体的运动、帧间运动和场景深度进行建模。此外,利用一种改进方法以在线方式动态地适应模型。
1.算法基线
重构损耗计算(前一帧或后一帧扭曲到中间一帧之间的最小重构损耗),如下公式:
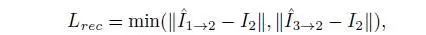
总损失表示为:
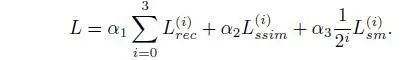
2.运动模型
本文引入了一个运动模型,专门用于估计单个物体在三维场景中的运动。类似于帧间运动模型,它需要将RGB图像序列作为输入,但这一次由预先计算的实例分割掩码进行补充。运动模型的任务是学习预测三维空间中每个物体的变换向量,从而在各自的目标帧中创建观察到的物体外观。
对于图像中的每个对象实例,第i个对象的对象运动估计值M(i)计算为:
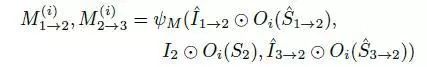
最终扭曲结果如下公式所示:
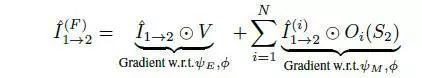
3.施加对象大小的限制
在之前的研究中,一个常见的问题是,以大致相同的速度行驶在前面的汽车,往往会被预测到无限的深度。为了解决这一问题,本文的关键思想是将模型学习对象缩放作为训练过程的一部分,从而能够在三维场景中进行对象的建模。设D为深度映射估计,S为对应的对象轮廓掩码,损失可表示为:
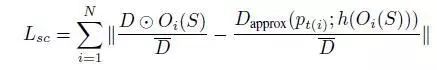
这样有效防止所有分割的对象退化为无限深度,迫使网络产生合理的深度和匹配的目标运动估计。我们以
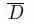
为尺度,即中间帧的平均估计深度,通过联合收缩先验值和深度预测范围来减少潜在的小损失减少问题。
4.测试时间细化模型
使用单帧深度估计器的一个优点是它的广泛适用性。然而,在对图像序列进行连续深度估计时,这是有代价的,因为连续预测常常是不对齐或不连续的。这是由两个主要问题造成的:1)相邻帧之间的尺度不一致,因为模型和相关的模型都没有全局尺度感;2)深度预测的时间一致性较低。
在这项工作中,作者主张在推理过程中不需要或不需要固定模型权重,并且能够在线调整模型。更具体地说,在执行推理时保持模型训练,通过有效地执行在线优化来解决这些问题。在此过程中,本文还表明,即使在时间分辨率非常有限的情况下,可以显著提高深度预测的质量,无论是定性的还是定量的。有了这种低时间分辨率,该方法仍然可以实时在线运行,通常可以忽略单个帧的延迟。对N个步骤(所有实验N = 20)进行在线细化,有效地对模型进行动态微调;N确定了充分利用在线调优和防止过度训练之间的良好折中。在线细化方法可以无缝地应用于任何模型,包括上面描述的运动模型。
主要结果
1、在KITTI数据集上的结果
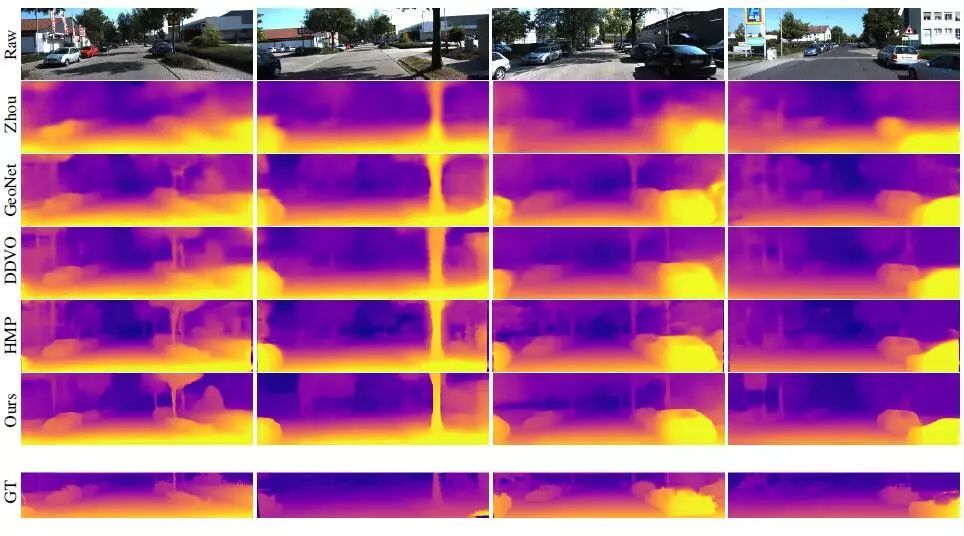
图2 KITTI数据集上可视化结果对比
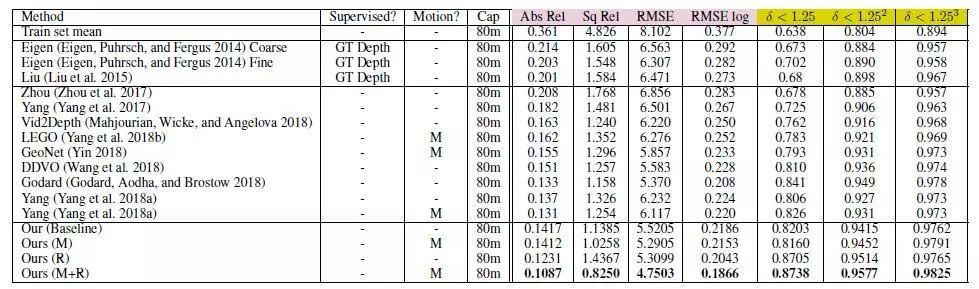
表1 KITTI数据集上指标对比
图2显示了本文的方法与最先进的方法相比的结果,表1显示了定量结果。这两种方法都比基线和文献中先前的方法有显著的改进。由于绝对相对误差为0.1087,该方法优于Yang et al.的0.131 和Yin的0.155。此外,本文的研究结果虽然是单眼的,但正在接近使用双目或双目与单目结合的方法,例如(Godard, Aodha, and Brostow 2017;Kuznietsov, Stuckler, and Leibe 2017;Yang et al. 2018a;goard, Aodha和Brostow 2018)。
2.运动模型结果
运动模型的主要贡献是它能够学习运动物体的适当深度,并能更好地学习帧间运动。
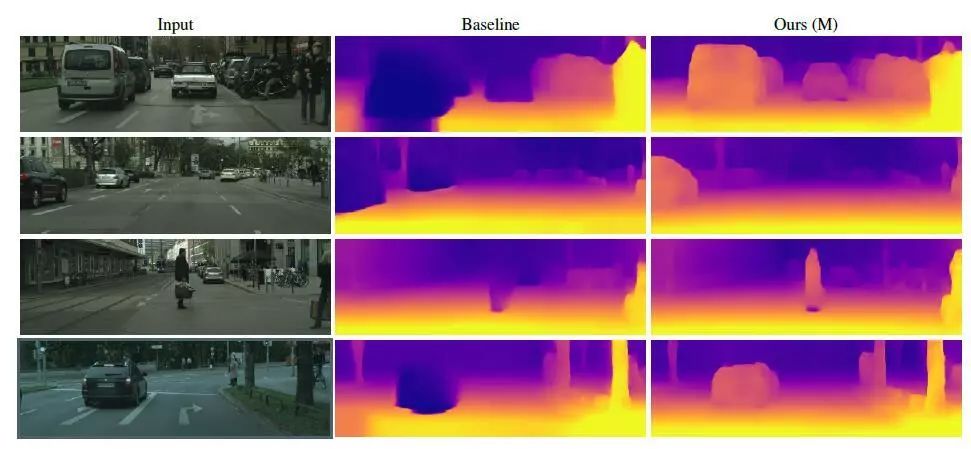
图3 运动模型的效果
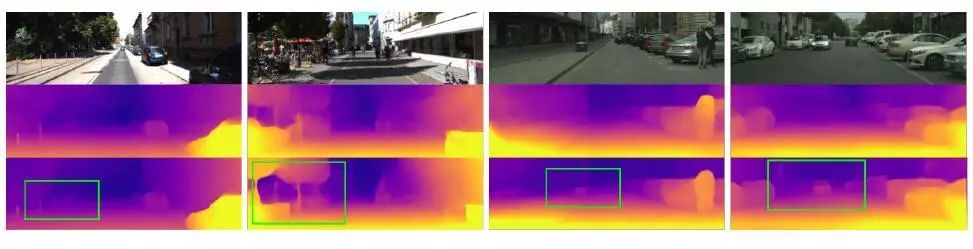
图4 精化模型的效果

图5 单独物体的深度估计

表2 在Cityscapes训练和在KITTI评价时深度预测结果
图3显示了来自Cityscapes数据集的几个动态场景示例,其中包含许多移动对象。基线本身就是KITTI上的佼佼者,但是在移动对象上却失败了。本文的方法在定性上(图3)和定量上(见表2)都有显著的不同。该运动模型的另一个好处是它学会了预测单个物体的运动。图5可视化了单个对象的学习运动。在项目网页上可以看到一个视频,它展示了深度预测和相对速度估计,这与视频中明显的帧间运动是一致的。
3.在Cityscapes数据集上的结果
表2展示了在Cityscapes数据上进行训练时的实验结果,然后对KITTI进行评估(没有对KITTI训练数据进行进一步的微调)。这个实验清楚地展示了本文方法的好处,对比基线方法,绝对相对误差从0.205提高到0.153。
4.视觉测距的结果
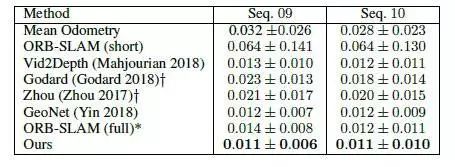
表3 KITTI测程序列的测程定量评价
表3总结了帧间运动估计结果。测试的总驱动序列长度分别为1702米和918米。本文的算法性能是最先进的方法中最好的,甚至比那些使用更多的时间信息或确定的方法表现更好,如ORB-SLAM。

Abstract
Learning to predict scene depth from RGB inputs is a challenging task both for indoor and outdoor robot navigation. In this work we address unsupervised learning of scene depth and robot ego motion where supervisionis provided by monocular videos, as cameras are the cheapest, least restrictive and most ubiquitous sensor for robotics. Previous work in unsupervised image-to-depth learning has established strong baselines in the domain. We propose a novel approach which produces higher quality results, is able to model moving objects and is shown to transfer across data domains, e.g. from outdoors to indoor scenes. The main idea is to introduce geometric structure in the learning process, by modeling the scene and the individual objects; camera ego-motion and object motions are learned from monocular videos as input. Furthermore an online refinement method is introduced to adapt learning on the fly to unknown domains. The proposed approach outperforms all state-of-the-art approaches, including those that handle motion e.g. throughlearned flow. Our results are comparable in quality to the ones which used stereo as supervision and significantly improve depth prediction on scenes and datasets which contain a lot of object motion. The approach is of practical relevance, as it allows transfer across environments, by transferring models trained on data collected for robot navigation in urban scenes to indoor navigation settings. The code associated with this paper can be found at https://sites.google.com/ view/struct2depth.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



