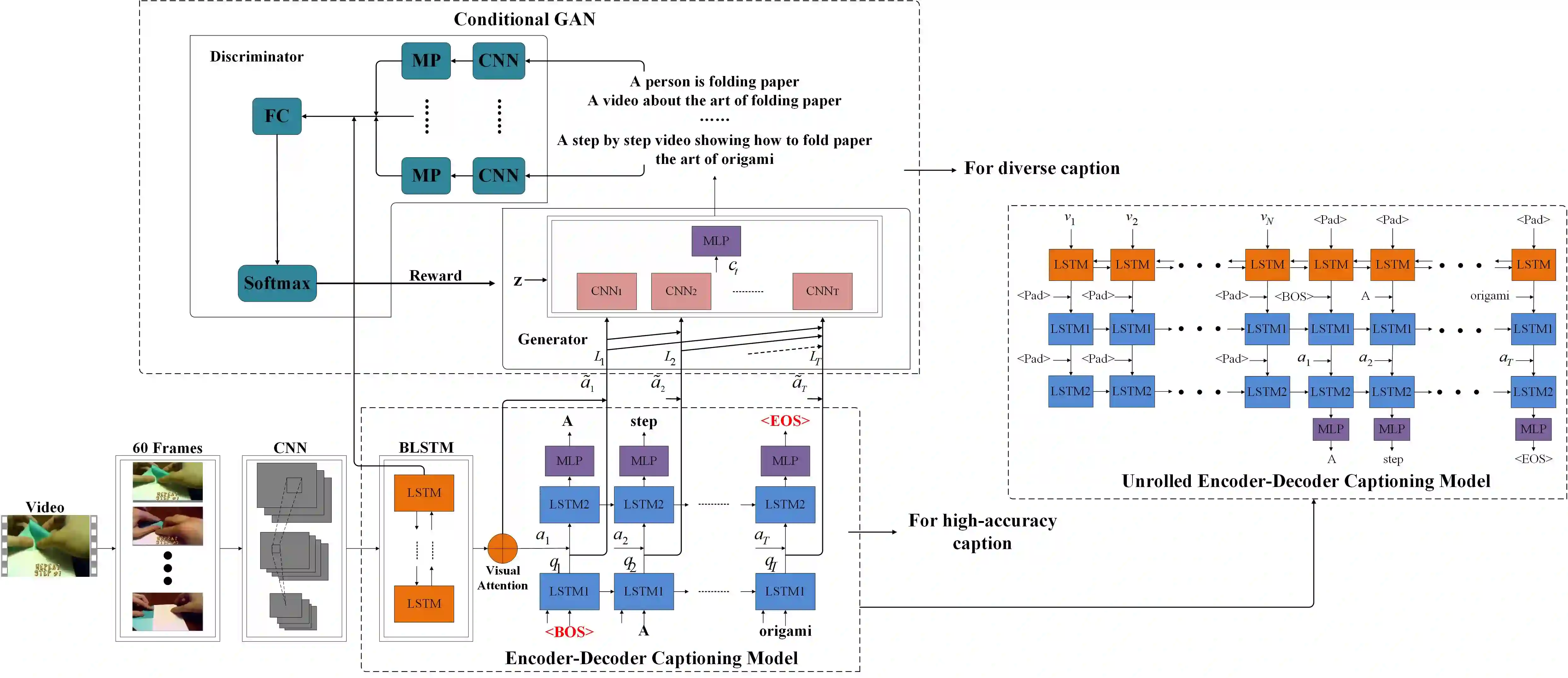
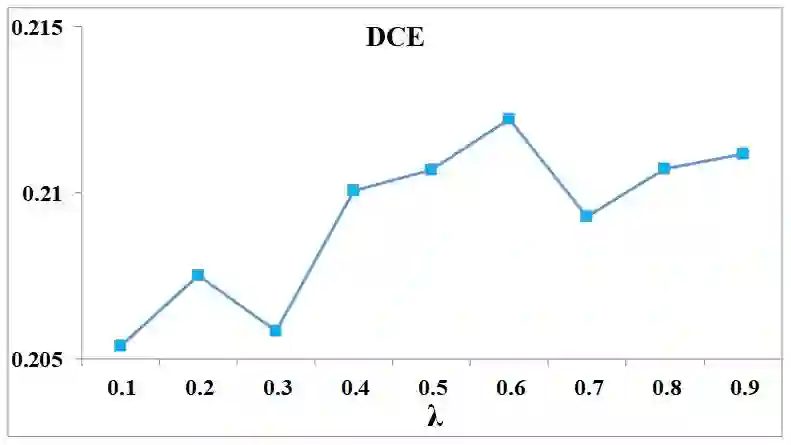
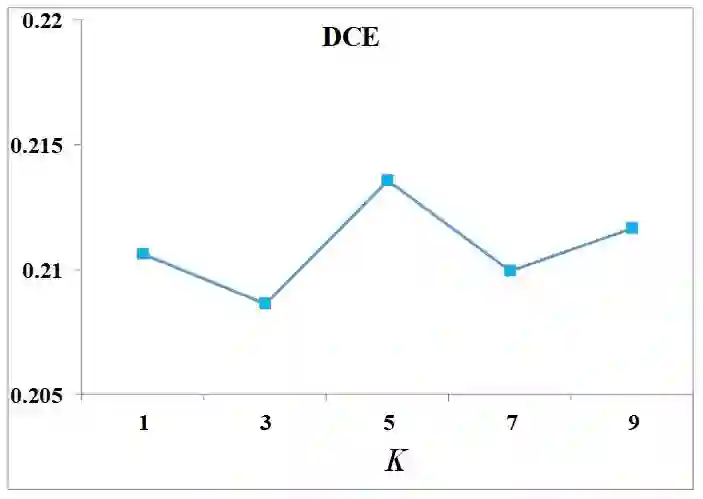
Automatically describing video content with text description is challenging but important task, which has been attracting a lot of attention in computer vision community. Previous works mainly strive for the accuracy of the generated sentences, while ignoring the sentences diversity, which is inconsistent with human behavior. In this paper, we aim to caption each video with multiple descriptions and propose a novel framework. Concretely, for a given video, the intermediate latent variables of conventional encode-decode process are utilized as input to the conditional generative adversarial network (CGAN) with the purpose of generating diverse sentences. We adopt different CNNs as our generator that produces descriptions conditioned on latent variables and discriminator that assesses the quality of generated sentences. Simultaneously, a novel DCE metric is designed to assess the diverse captions. We evaluate our method on the benchmark datasets, where it demonstrates its ability to generate diverse descriptions and achieves superior results against other state-of-the-art methods.
翻译:以文字描述自动描述视频内容是一项具有挑战性但重要的任务,它吸引了计算机视觉界的很多关注。 先前的工作主要是努力提高生成的句子的准确性,而忽略了与人类行为不符的句子多样性。 在本文中,我们的目标是为每段视频提供多个描述,并提出一个新的框架。 具体地说,对于某段视频来说,常规编码编码过程的中间潜伏变量被用作有条件的基因对抗网络(CGAN)的输入,目的是生成不同的句子。 我们采用不同的CNN作为生成器,生成的描述以潜在变量和区分器为条件,对生成的句子的质量进行评估。 同时,我们设计了一个新的DCE 度量度来评估不同的描述。 我们在基准数据集上评估我们的方法,显示它能够生成不同的描述并与其他最先进的方法相比取得优异的结果。