南大本科生论文获NeurIPS Poster!俞扬团队首次揭示强化学习「记忆池」最优利用方法
![]()
新智元报道

新智元报道
编辑:好困
【新智元导读】在刚刚结束的NeurIPS 2021上,俞扬团队首次揭示了深度强化学习「记忆池」的最优利用方法。那么,在南京大学人工智能学院做科研又是怎样的一种体验呢?
「记忆池」是深度强化学习的基本部件,但多年以来如何最优利用记忆池仍然未知。
在刚刚闭幕的机器学习国际顶级会议NeurIPS 2021上,南京大学人工智能学院独立完成的工作「Regret Minimization Experience Replay in Off-Policy Reinforcement Learning」,首次揭示了深度强化学习「记忆池」的最优利用方法。

https://openreview.net/forum?id=5AixAJweEyC
该工作由俞扬教授指导,其共同第一作者,2018级本科生薛正海,是南大人工智能学院的首届本科生。
本文对论文工作进行了总结,并采访了薛正海同学在南大人工智能学院学习的体验。
从本质出发,解决深度强化学习难题
什么是强化学习
与广为人知的人脸识别技术不同,强化学习并非通过带有标签的数据,而是考虑一个处在环境中的智能体,通过智能体与环境的交互进行学习。
这就类似于人类的婴儿,他会观察、倾听、触摸所在的环境,收获环境的反馈,来认识这个世界,改变自己的行为。
2016年AlphaGo运用了这项技术,在围棋项目中战胜了人类选手,也让强化学习这项技术获得了空前的曝光度。
经过近年来的发展,强化学习技术在许多环境中都取得了超越人类的决策水平,也被认为是实现通用人工智能的一种重要途径。
图1. 强化学习与环境交互的过程
强化学习的记忆池
人类会记住自己经历过的事情,通过回忆这些经历,进行学习。与此类似,强化学习将智能体与环境交互的数据存入记忆池,再从记忆池中取出数据,从而训练智能体。
自记忆池这个概念提出一来,就产生了一个问题,我们应当如果利用记忆池中的数据?最直接的做法我们把记忆池中的数据认为是同等重要的,在学习过程中所有的记忆拥有相同的权重。
这也正是2015年第一个能玩Atari游戏的「深度强化学习」所采用的方法。
但是这个做法是不是最好的呢?
如果我们从我们人类自身角度来看,至少我们人类并不是所有的记忆都有相同的权重,首先一般而言我们对更近时间的记忆会更清晰,时间久远的记忆就更模糊,其次就是某些事情我们会印象深刻,另外一些事情我们很快就会忘记。
这是因为,并不是所有记忆都是同等重要的,重点关注关键的记忆,忽略意义不大的记忆,是利用好我们记忆的重点。
那么,我们人类的直觉对于强化学习来说是不是适用的呢?强化学习又如何对于记忆池中的数据进行更好的利用?
自记忆池出现以来,学术界就开始关注记忆池的数据利用问题。尤其随着深度强化学习的兴起,记忆池越来越大,问题也越来越紧迫。
2015年,Schaul等人从优化角度上来审视这个问题,设计了优先级记忆回放机制(PER)。仅此一项改进,就在Atari游戏上取得了很大的提升,这说明记忆池的数据利用确实是影响强化学习的性能的一个重要因素。
自此,这方面的研究开始活跃起来。例如,优先级序列记忆回放(PSER)考虑到了强化学习的序列关系;近期记忆增强(ERE)认为相较于时间更久的数据,新采集到的数据更重要;分布修正(DisCor)则选择在记忆池中避开值学得比较差的地方;无似然重要性采样(LFIW)认为智能体用当前策略采集的数据更重要。
从本质问题出发,求解最优利用方法
以往研究从不同的角度发明了不同的记忆池利用方案,但是完整的答案仍然缺失,其中的原因在于,它们的出发点忽略了强化学习的最终目标。
强化学习的目标是获取最高的回报,以此目标作为出发点,就是这项工作的初衷。在这个思想的启发下,工作构造了针对回放池权重的最大回报优化问题:
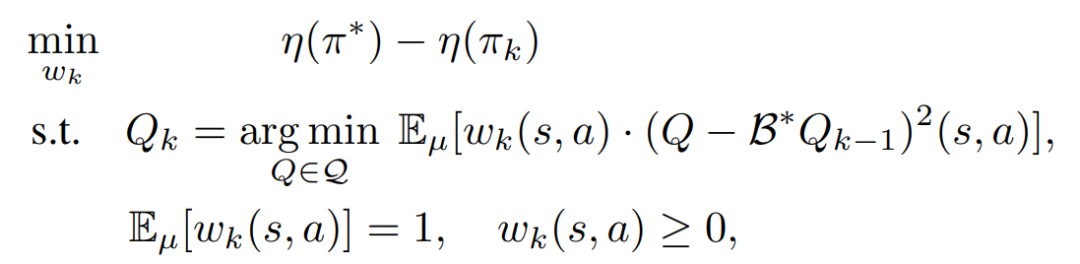
其中wk就是历史记忆的权重。
通过求解这样一个优化问题,该工作得到了关于最优回放池的结论:
1)如上面提到的LFIW算法的原则,要更多的选取由智能体当前策略采集到的数据。
2)也不能仅仅局限于当前策略,数据的分布要稍微广一些,也要重视当前策略附近的数据。
3)同DisCor算法原则一样,要避开值学得较差的地方,避免被优化过程带偏。
4)类似于PER算法的原则,要更多关注差分误差较大的地方。
这个定理给出了实现记忆池数据的最优利用的四项原则,可以看到,以往研究只是其中的一个拼图。自此,该工作回答了如何最优利用强化学习记忆池的问题。
但是,这几项原则是在理论层面上的阐述,真正去实现与之相匹配的算法并非一件简单的事情。
论文中提出了ReMERN和ReMERT两个算法,这两个算法对上面提到的四项原则进行了逼近。
从算法设计的角度,ReMERT在环境随机性较小的情况下近似较为准确,ReMERN则不太受环境随机性影响。
实验表明,ReMERT在环境随机性较小的MuJoCo和Atari环境里取得了SoTA的效果,ReMERN则在环境随机性较大的MetaWorld上有更好的表现。
在南大人工智能学院读书的体验
薛正海同学是南大人工智能学院的首批本科生,目前已在NeurIPS 2021发表共同作者论文一篇,获得DAI2020自动驾驶竞赛第三名,并参与了创新工场与南京大学组织的Deecamp人工智能夏令营等。
关于在南大人工智能学院学习的体验,笔者采访了薛同学。
笔者:能说说你感受到的南大的氛围?
薛正海:在南大的校园、教室、图书馆、实验室里,南大的师生或多或少都有“诚朴雄伟“的气质,认认真真做事,踏踏实实做人。这些都时时刻刻影响着我,提醒自己做一个合格的南大人。可以说,学校更多是潜移默化的影响着我的成长。
笔者:人工智能学院对你的成长有什么帮助?
薛正海:学院对我的帮助,我认为主要可以体现在扎实的数理和专业基础、良好的科研环境这两方面。前期主要是在大一大二安排了很多数理和专业基础课,打下了扎实的基础。我们这篇论文涉及到很多微积分、线性代数和概率论的知识,实验代码的编写也与之前的编程训练密不可分。后期是大三进入专业选修阶段后,课程压力相对小了很多,我有充足的时间在实验室进行科研工作。此外,周院长每一次的座谈会总能给我们鼓舞士气、坚定信心,班主任、辅导员和教务员老师也都给过我各种各样的帮助。
笔者:在人工智能学院你是怎么参加科研的?
薛正海:我很早就加入了LAMDA研究所俞扬老师的课题组,一直在了解强化学习的基础知识。2020年5月左右俞老师安排我与李子牛师兄交流学习。李师兄向我推荐了很多前沿论文,当时我只是囫囵吞枣地读了,也没有太多想法,但回过头看却是帮助我熟悉了研究领域。2021年的3月我在和刘旭辉师兄讨论其中一篇论文时恰好发现了一处漏洞。经过初期的理论和实验验证,我们发现这一漏洞可以被一种全新的强化学习算法弥补。得到俞老师的认可后,我们便开展了进一步研究,期间得到了庞竟成、徐峰和蒋圣翊师兄的帮助。我们在5月28日提交了论文,在8月份的时候经历了rebuttal(与审稿人来回讨论),随后就得到了论文被接受的消息。
笔者:俞老师在科研过程中与你的交流如何?
薛正海:指导老师俞扬老师对我的帮助,首先是俞老师为我们创造了良好的科研环境,比如大一时就让我加入实验室旁听组会,大三时为我在实验室分配座位——正好在刘旭辉师兄边上,这次的论文也是从我们的交流讨论开始的。当然俞老师实验室的计算设备也必不可少。然后,关于具体的研究课题、理论、算法和论文,俞老师都会亲自指点并提出关键意见。在论文和rebuttal提交ddl前,俞老师还和我们一起熬夜修改,精益求精。另外,平时的组会上俞老师时常会对我们进行方法论层面的指导,比如科研怎么选题、实验环境如何选择、如何展示自己的工作等。
有关南京大学人工智能学院
南京大学人工智能学院于2018年3月5日成立,是我国C9高校中首个人工智能学院,致力于建设人工智能领域国际一流学术重镇和拔尖创新人才培养基地。
学院成立三年来取得了长足发展,建设了一支由世界级专家领衔、青年学者蓬勃成长、具有国际影响力的高水平教师队伍,倾力培养家国情怀厚植、专业能力突出、德智体全面发展的优秀学生,率先发布我国首个人工智能本科专业教育培养体系,首批入选国家一流本科人工智能专业建设点,并在连续15年获评计算机类第一名的国家重点实验室、国家基金委创新群体、教育部引智基地、江苏省优秀协同创新中心等一流平台的支撑下,在多家著名头部企业联合实验室/研究中心/实训基地等的助力下,在前沿科技研究、国家重大工程、产学研协同创新方面不断取得重要进展。




