多智能体学习
·

探索 - 利用(exploration-exploitation)是多智能体学习(MAL)中强大而实用的工具,但其效果远未得到理解。为了探索这个目标,这篇论文研究了 Q 学习的平滑模拟。首先,研究者认为其学习模型是学习「探索 - 利用」的最佳模型,并提供了强大的理论依据。具体而言,该研究证明了平滑的 Q 学习在任意博弈中对于成本模型有 bounded regret,该成本模型能够明确捕获博弈和探索成本之间的平衡,并且始终收敛至量化响应均衡(QRE)集,即有限理性下博弈的标准解概念,适用于具有异构学习智能体的加权潜在博弈。
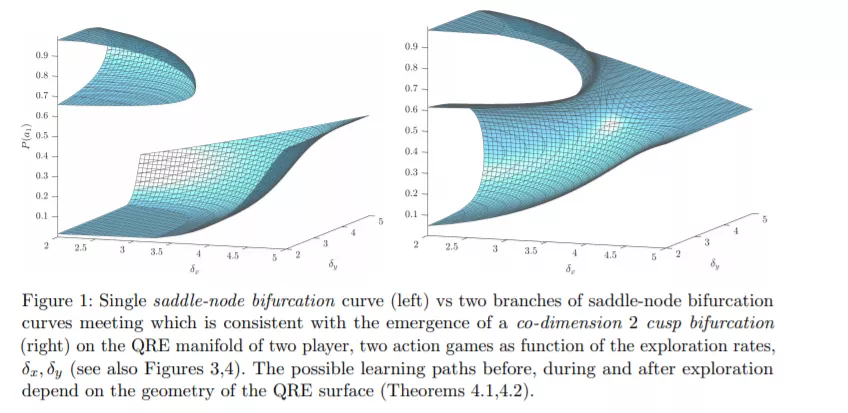
该研究的主要任务转向衡量「探索」对集体系统性能的影响。研究者在低维 MAL 系统中表征 QRE 表面的几何形状,并将该研究的发现与突变(分歧)理论联系起来。具体而言,随着探索超参数随着时间的演化,系统会经历相变。在此过程中,给定探索参数的无穷小变化,均衡的数量和稳定性可能会发生剧烈变化。在此基础上,该研究提供了一种形式理论处理方法,即如何调整探索参数能够可验证地产生均衡选择,同时对系统性能带来积极和消极(以及可能无限)的影响。
https://www.zhuanzhi.ai/paper/58dfd45f8af99a926fb48199e1447e9a
成为VIP会员查看完整内容
相关内容
Arxiv
3+阅读 · 2019年7月8日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年7月8日