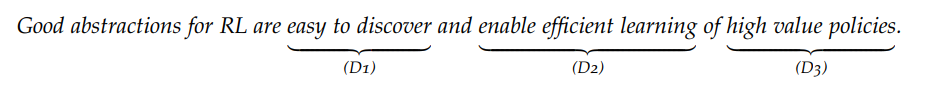除了论文本身超有技术含量之外,文中使用的图表也非常美观漂亮。
作为人工智能里最受关注的领域之一,强化学习的热度一直居高不下,在游戏、自动驾驶、机器人路线规划等领域得到了广泛的应用。但是,强化学习的学习难度也同样不低。
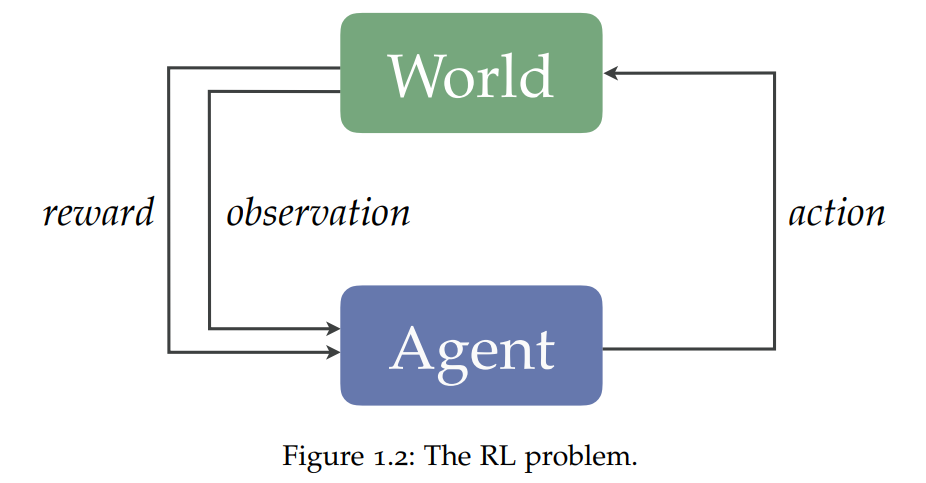
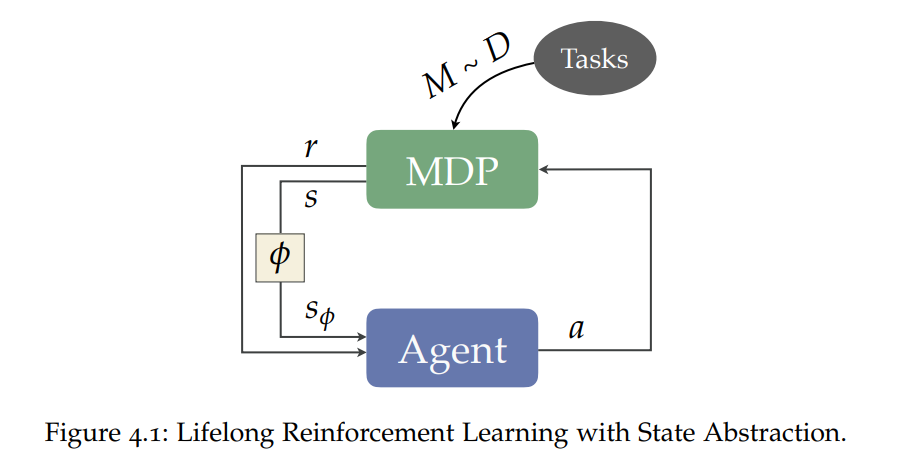
强化学习定义了学习仅通过行动和观察做出好的决策的智能体所面临的问题。要成为有效的问题解决者,这些智能体必须有效地探索广阔的世界,从延迟的反馈中获得credit,并归纳出新的经验,同时利用有限的数据、计算资源和感知带宽。
![]()
抽象(abstraction)对于所有这些努力都是必不可少的。通过抽象,智能体可以搭建起关于其环境的简洁模型,这些模型支持一个合理的、适应性强的决策者所需的许多实践。
在前段时间结束的第36 届 AAAI 人工智能会议上,大会官方公布了新一届的 AAAI/ACM SIGAI 博士论文奖,其中一篇专门分析强化学习抽象理论的论文《A Theory of Abstraction in Reinforcement Learning》获得了该奖项提名。论文作者David Abel 博士毕业于布朗大学,他于近日将这篇博士论文上传到了arXiv上,共有295页。
![]()
在这篇论文中,作者提出了强化学习中蕴含的抽象理论。
维护近似最优行为的表示;
它们应该被有效地学习和构建;
计划或学习时间不应该太长。
然后提出了一套新的算法和分析方案,阐明智能体如何根据这些要素学会抽象。总的来说,这些研究结果为发现和使用抽象提供了一些途径,从而把有效强化学习的复杂性降至最低。
![]()
论文地址:https://arxiv.org/pdf/2203.00397.pdf
这篇博士论文所涉及的核心问题:
强化学习智能体是如何发现和使用高质量的抽象
?
作者通过以下理论来回答这个问题:借鉴计算复杂性理论、决策理论和信息论的思想,是可能设计出高效的算法来启发抽象,从而减少RL智能体寻找好的解决方案所需的"经验值"或"思考"时间。
为了论证本论文的思想,作者从三个方面阐述了哪些抽象在RL中有用,并将其研究成果高度概括为如下内容:
![]()
更具体地,作者通过以下四个部分对强化学习的抽象理论展开了探讨。
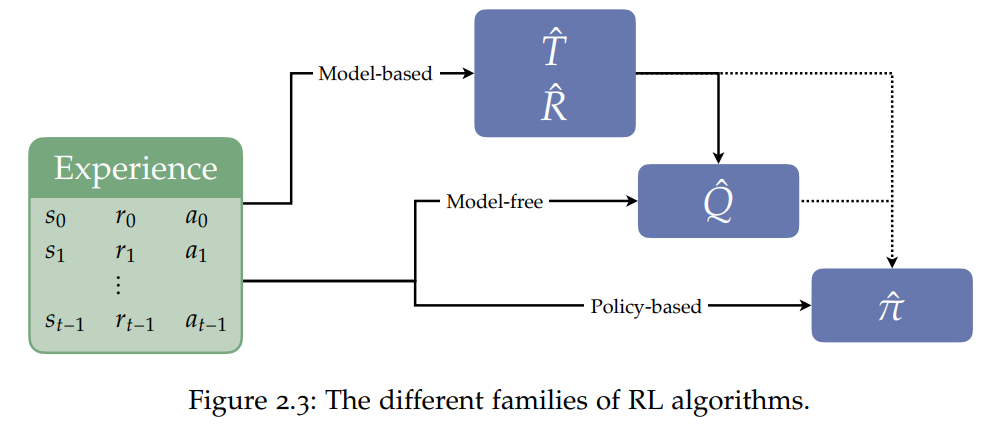
第一部分。在第2章中,作者提供了
关于RL以及状态抽象、行动抽象的必要背景知识
。然后,他更详细地介绍和激励抽象必须的要素。
![]()
第二部分。作者致力于
状态抽象研究
,提出了新的算法以及三个密切相关的分析集,每个分析集的目标都是发现状态抽象所必需的要素。
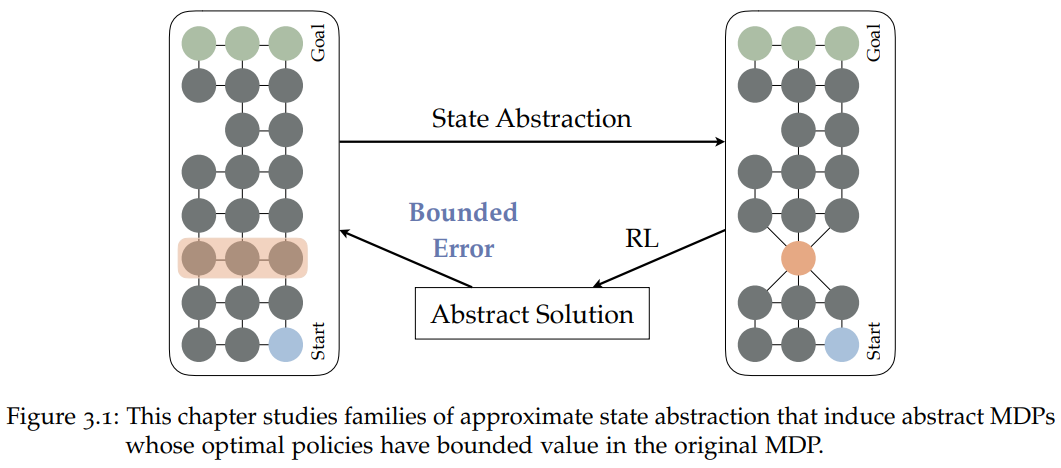
在第3章中,作者开发了一个形式化的框架,用于对维护近似最优行为的状态抽象进行推理。论文中定理3.1总结该框架,它强调了四个值保留状态抽象的充分条件。
![]()
本章研究了包括抽象MDP(马尔科夫决策过程)在内的不同族的近似状态抽象。
在第4章中,作者将此分析扩展到终身性强化学习,其中智能体必须不断与不同的任务进行互动并解决不同的任务。本章主要是对终身学习环境下的PAC状态抽象的洞察,并阐明如何有效计算它们的结果。定理4.4阐明了保证这些抽象保持良好行为的意义,定理4.5说明了要多少以前解决的任务才能计算出PAC状态抽象。作者重点介绍了模拟实验的结果,这些结果说明了引入的状态抽象类型在加速学习和规划方面的效用。
![]()
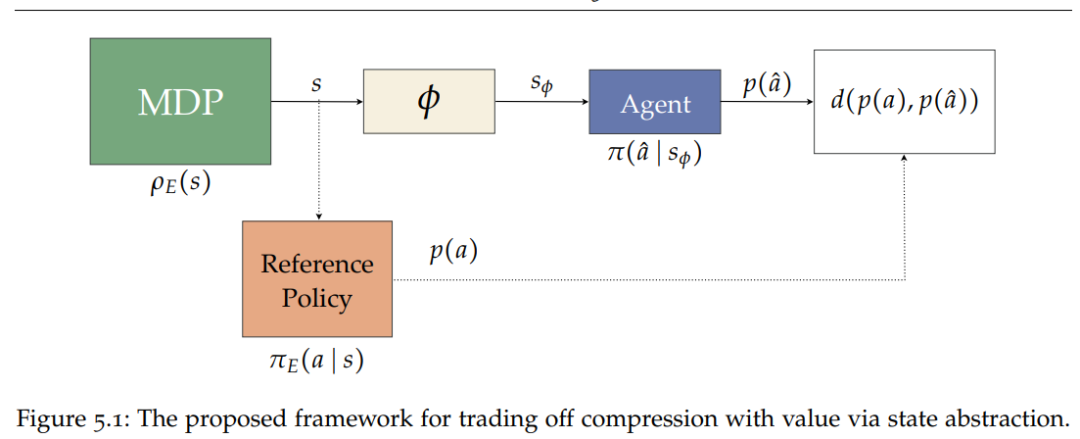
第 5 章介绍了信息论工具对状态抽象的影响。作者在状态抽象和数据率失真理论以及信息瓶颈方法之间建立了紧密的理论联系,并利用这种联系设计了新的算法来高效地构建状态抽象,在压缩和良好行为的表示之间取得了优雅的平衡。作者通过多种方式扩展了该算法框架,充分展示了它发现状态抽象的能力,并且为良好行为的有效学习提供了样本。
![]()
作者提出的通过状态抽象权衡压缩与价值(value)的框架。
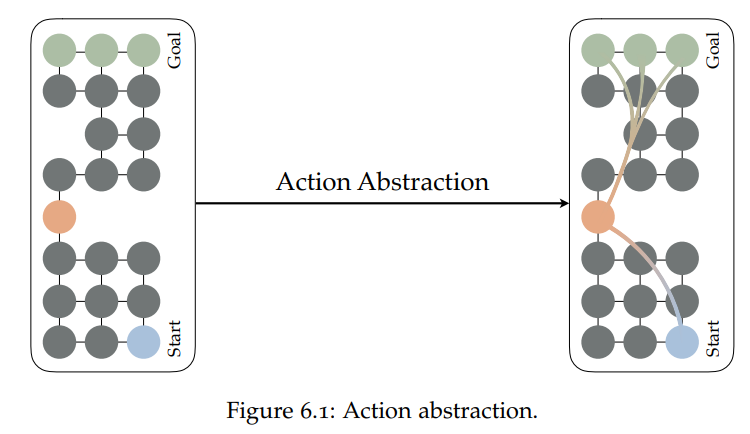
在第6章中,作者介绍了Jinnai等人的相关工作,它研究了如何找到使规划尽可能快的抽象动作的问题。结果表明,这个问题基本是NP难问题,甚至很难在多项式时间内近似。
![]()
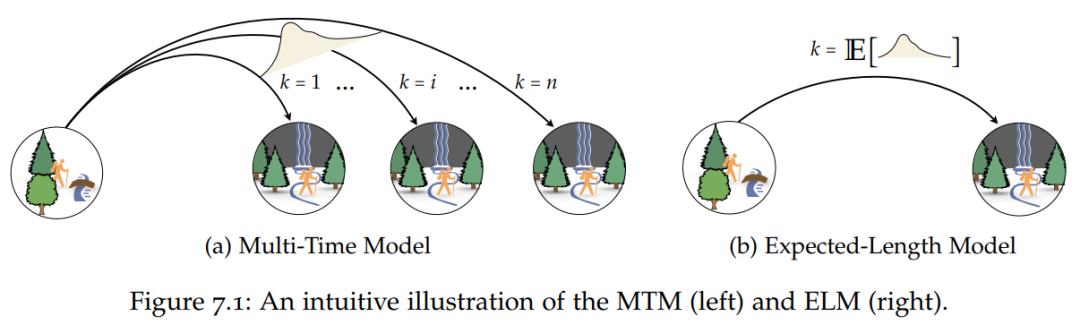
在第 7 章中,作者讨论了如何构建规划中同时伴有高级行为的预测模型。这样的模型使智能体能够预估在给定状态下执行某行为的结果(打开这扇门后世界会是什么样子?)。作者介绍并分析了这些高级次行为的新模型,并证明在不太严格的假设下,这个更简单的替代方案仍然有效。作者在文中提供的经验证据表明,新的预测模型可以作为更复杂模型的合适替代品。
![]()
多时间模型(Multi-Time Model, MTM)与预期长度模型(Expected-Length Model)的比较。
在第8章中,作者研究了抽象行为改善探索过程的可能性。他介绍了Jinnai等人开发的算法,该算法基于构造简易环境所有部分的抽象动作的概念,并证明该算法可以加速基准任务的探索。
第四部分。作者研究了
状态-行动抽象的联合处理过程
。
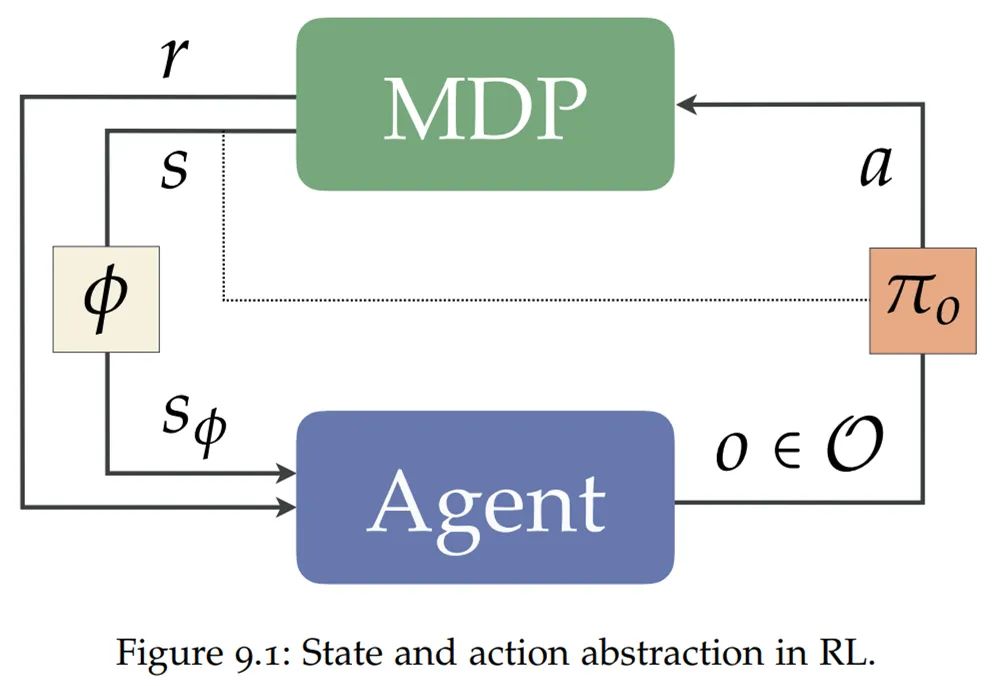
在第 9章中,作者介绍了一种将状态和行动抽象结合在一起的简单方案,利用这个方案,作者证明了状态和行动抽象的哪些组合可以在任何有限 MDP 中保持良好行为策略的表示,论文中定理9.1对此做了总结。接着,作者将研究这些联合抽象的重复应用,作为构建层次抽象的机制。在关于层次结构和底层状态行动抽象的温和假设下,作者证明这些层次结构还可以保持全局接近最优行动策略的表示,论文中定理9.3对此有阐述。
![]()
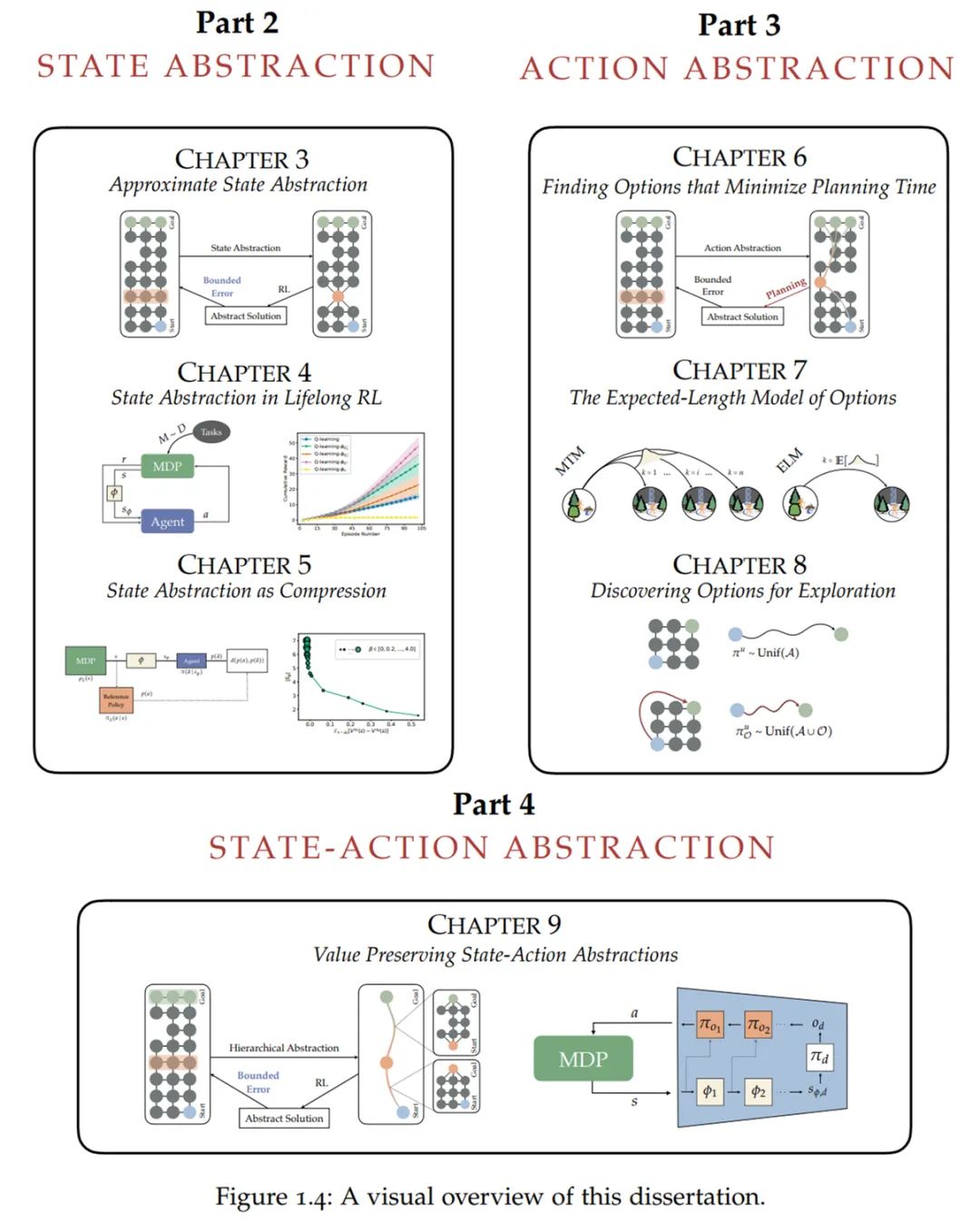
总之,以上各章内容阐述了强化学习的抽象理论。下图为论文结构的可视化呈现。
![]()
David Abel现为DeepMind(伦敦)研究科学家。他的研究兴趣主要在于搞清楚围绕计算与学习的核心哲学问题。他非常看中那些着力提供新见解的研究,并往往对简单但基础性的问题感到兴奋。
更具体地将,David Abel致力于研究强化学习问题,并借鉴计算学习理论、计算复杂度和分析哲学等领域的工具和观点。
目前,他感兴趣的研究方向是「更好地定义AI问题。」
![]()
个人主页:https://david-abel.github.io/
![]()
![]()
时在中春,阳和方起——机器之心「AI科技年会」
机器之
心AI科技年会将于3月23日在线上
举办
,本次活动分为三场论坛:
-
「人工智能论坛」直播间:
http://live.bilibili.com/3519835
-
「AI x Science 论坛」直播间:
http://live.bilibili.com/24531944
-
「首席智行官大会」直播间:
https://live.bilibili.com/24532108
人工智能论坛关注高性能计算、联邦学习、系统机器学习、强化学习、CV与NLP发展、RISC-V等。
AI x Science论坛关注AI与蛋白质、生物计算、数学、物理、化学、新材料和神经科学等领域的交叉研究进展。
首席智行官大会关注智能汽车、汽车机器人、无人驾驶商业化、车规级芯片和无人物流等。
点击阅读原文,查看全部日程。
欢迎大家加入本次年会交流群,就感兴趣的话题进行讨论和交流:关注下方服务号-点击菜单即可扫码入群。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com