【强化学习】重磅 | 详解深度强化学习,搭建DQN详细指南
选自 Nervana
作者:Tambet Matiisen
机器之心编译
参与:Rick、李亚洲、吴攀
本文为作者 Tambet Matiisen 在 Nervana 上发表的有关深度强化学习的系列博文,分为两部分:第一部分作者对 DeepMind 提出的深度强化学习进行了详细的讲解;第二部分作者使用案例讲解如何在 Neon 上建立深度强化学习模型。
一、详解深度强化学习
两年前,一家位于伦敦的小公司 DeepMind 在 arXiv 上上传了他们开创性的论文《Playing Atari with Deep Reinforcement Learning》。在这篇论文中,他们证明了计算机可以如何通过仅仅观察屏幕像素以及游戏分数上升的奖励学会玩雅达利 2600 型电子游戏。结果是惊人的,因为游戏和每个游戏中的目标都非常不同,而且是专为人类设计的挑战。相同模式的架构在没有任何变化的情况下,可以用来学习七种不同的游戏,并且在其中三个里,算法甚至比人类玩得更好!
它被喻为是迈向通用人工智能的第一步——不会被局限在某一个领域,例如围棋,而在任何环境下都能生存的人工智能。无怪乎 DeepMind 迅速就被谷歌所收购,并从此成为了深度学习研究的前线。2015年的二月,他们的论文《Human-level control through deep reinforcement learning》登上了最富盛名的科学期刊《Nature》的封面。 在这篇论文中,他们在 49 种不同的游戏里应用了相同的模型,并在其中的一半里有着超乎人类的表现。
但是,尽管监督与无监督学习的深度模型已经在这一领域内得到了广泛的应用,但深度强化学习还笼罩着神秘的面纱。在这篇文章中,我会试着揭开这项技术的神秘面纱,并理解它背面的基本原理。这篇文章的目标读者应该有机器学习以及最好神经网络的相关背景,但是还没有时间深入了解过强化学习。
下面将是此篇文章的重点所在:
增强学习的主要挑战是什么?我们会在这里谈及信用分配问题(credit assignment problem )与探索-开发困境(exploration-exploitation dilemma)。
如何用数学术语公式化强化学习?我们将会定义马尔可夫决策过程(Markov Decision Process)并利用它来推导强化学习。
我们如何生成长期策略?我们会定义「折扣未来奖励(discounted future reward)」,其奠定了下一章节的算法的基础。
我们怎样能够估测未来奖励? 简单的基于表格的 Q 学习(Q-learning)算法在这里会得到定义与解释。
如果我们的状态空间( state space)过大该怎么办?在这里我们会看到 Q 表格(Q-table)可以如何被(深度)神经网络所取代。
让它真正地运转起来还需要些什么?我们将讨论经验重放技术(Experience replay technique ),它可以稳定化神经网络的学习。
到这里就结束了吗?在最后,我们会考虑一些探索-开发的简单解决方案。
如何用数学术语公式化强化学习?我们将会定义马尔可夫决策过程(Markov Decision Process)并利用它来推导强化学习。
1、强化学习
在《打砖块(Breakout)》 这个游戏中,玩家需要控制屏幕底下的短板让球反弹,去清除屏幕上方所有的砖块。 每一次你击碎了一个砖块,它就会消失,然后获取分数——你就有了奖励(reward)。
图1:雅达利《打砖块》游戏.图源:DeepMind
假设你希望教一个神经网络去玩这个游戏。那么神经网络的输入应该是屏幕的图片,输出则应该是分为三个动作:向左、向右或者发射。这可以被看为是一种分类问题——你需要对每一个游戏画面做出决定,是该往左移,还是往右或者选择发射。听起来是不是很简洁?当然,但是你还需要训练样本,很多的样本。当然了,你也可以直接录下专业玩家的游戏视频,但是这并不是我们学习的方式。我们不需要其他人无数次地告诉我们该在每个画面上选择怎样的动作。我们只需要做出对的决策后的几次反馈,然后就可以自己解决了。
这是一个强化学习尝试解决的任务。强化学习位于监督与无监督式之间的某个位置。而监督式学习每一个训练样本都有着目标标签,在无监督学习中则没有,强化学习则有着稀疏(sparse)和延时(_time-delayed)_的标签——奖励(reward)。仅仅基于这些奖励,人工智能代理必须学会在这个环境中的行为方式。
尽管这个想法十分的直观,但是在实际中仍然有不少挑战。例如,当你在《打砖块》游戏里击碎了一个砖块并拿到分数时,这与你在刚刚拿到分数之前的动作(拍子移动)并没有关系。在你正确地放好拍子并反弹球的时候,所有的活都已经做好了。这也叫作信用分配问题(credit assignment problem )——例如,到底之前的哪个动作才导致了分数的获得,以及何种程度。
一旦你找到了能够获得一定分数的奖励的策略,那么你会坚持它,还是去用可能带来更大的奖励的动作来实验呢?在上述《打砖块》游戏中,最简单的策略就是让拍子待在左边并等待。当球被发射后,它倾向于更向左边飞而不是右边,你会在游戏结束前轻易地获得 10 分。你是想就此为止还是更进一步?这叫做探索-开发困境问题——你想要用现有的策略,还是其他可能更棒的策略呢?
强化学习是一个关于我们(以及所有广义上的动物)如何学习的重要模型。我们的父母的夸奖、学校获得的分数、工作薪水——这些都是奖励的形式。信用分配问题与探索-开发困境每天都会在生意与人际关系中出现。这正是研究这个问题,以及组成有意思的沙箱的游戏对于找出新的方法为何是非常重要的原因。
2、马尔可夫决策过程
现在的问题是,你如何公式化一个强化学习问题,然后进行推导呢?最常见的方法是通过马尔可夫决策过程。
假设你是一个代理,身处某个环境中(例如《打砖块》游戏)。这个环境处于某个特定的状态(例如,牌子的位置、球的位置与方向,每个砖块存在与否)。人工智能可以可以在这个环境中做出某些特定的动作(例如,向左或向右移动拍子)。
这些行为有时候会带来奖励(分数的上升)。行为改变环境,并带来新的状态,代理可以再执行另一个动作。你选择这些动作的规则叫做策略。通常来说,环境是随机的,这意味着下一状态也或多或少是随机的(例如,当你漏掉了球,发射一个新的时候,它会去往随机的方向)。
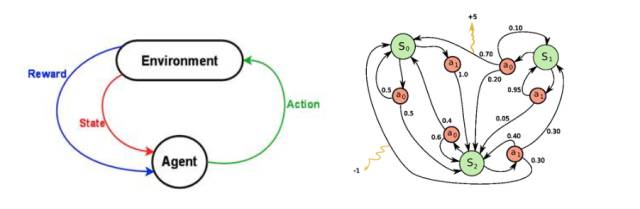
图2:左:强化学习问题.右:马尔可夫决策过程
状态与动作的集合,加上改变状态的规则,组成了一个马尔可夫决策过程。这个过程(例如一个游戏)中的一个情节(episode)形成了状态、动作与奖励的有限序列。
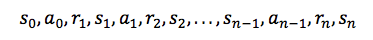
其中 si 表示状态,ai 表示动作,ri+1 代表了执行这个动作后获得的奖励。情节以最终的状态 sn 结束(例如,「Game Over」画面)。一个马尔可夫决策过程基于马尔可夫假设(Markov assumption),即下一状态 si+1 的概率取决于现在的状态 si 和动作 ai,而不是之前的状态与动作。
3、折扣未来奖励(Discounted Future Reward)
为了长期表现良好,我们不仅需要考虑即时奖励,还有我们将得到的未来奖励。我们该如何做呢?
对于给定的马尔可夫决策过程的一次运行,我们可以容易地计算一个情节的总奖励:
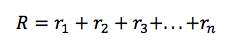
鉴于此,时间点 t 的总未来回报可以表达为:
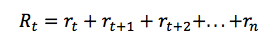
但是由于我们的环境是随机的,我们永远无法确定如果我们在下一个相同的动作之后能否得到一样的奖励。时间愈往前,分歧也愈多。因此,这时候就要利用折扣未来奖励来代替:
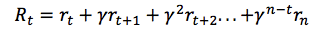
在这里 γ 是数值在0与1之间的贴现因子——奖励在距离我们越远的未来,我们便考虑的越少。我们很容易看到,折扣未来奖励在时间步骤 t 的数值可以根据在时间步骤 t+1 的相同方式表示:
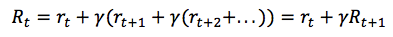
如果我们将贴现因子定义为 γ=0,那么我们的策略将会过于短浅,即完全基于即时奖励。如果我们希望平衡即时与未来奖励,那么贴现因子应该近似于 γ=0.9。如果我们的环境是确定的,相同的动作总是导致相同的奖励,那么我们可以将贴现因子定义为 γ=1。
一个代理做出的好的策略应该是去选择一个能够最大化(折扣后)未来奖励的动作。
4、Q- 学习(Q-learning)
在 Q-学习中,我们定义了一个函数 Q(s,a) 表示当我们在状态(state)s 中执行动作(action)a 时所获得的最大折扣未来奖励(maximum discounted future reward),并从该点进行继续优化。
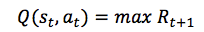
可以将 Q(s,a) 看作是「在状态 s 中执行完动作 a 后,游戏结束时最好的得分」。它被称为 Q-函数(Q-function),因为其代表了给定状态中特定动作的「质量」。
这个定义听起来可能有些费解。如果我们只知道当前状态和动作,而不知道后续的动作和奖励,那我们该怎么估计游戏最后的得分呢?我们实际上不能。但作为一种理论构想,我们可以假设确实存在这样一个函数。只要闭上你的眼睛重复五次:「Q(s,a) 存在、Q(s,a) 存在……」懂了吗?
如果你仍没被说服,那就考虑一下存在这样一个函数会有怎样的影响。假设你在一个状态中,并在琢磨应该采取动作 a 还是 b. 你想选择在游戏最后能得到最高得分的动作。一旦你有了神奇的 Q-函数,答案就变得非常简单了——采取 Q 值最高的动作!
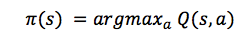
其中 π 表示策略,即我们在每一个状态中选择动作时所遵循的规则。
好了,那么我们如何得到 Q 函数呢?让我们只关注一个转换(transition)<s, a, r, s’>。 和上一节中提到折扣未来奖励一样,我们可以根据下一个状态 s’ 的 Q 值得到状态 s 和动作 a 的 Q 值。
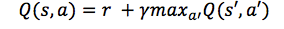
这被称为贝尔曼方程(Bellman equation)。你想想看,这是很合乎逻辑的——该状态和动作的最大未来奖励等于立即得到的奖励加上下一状态的最大未来奖励。
Q 学习的主要思想是我们可以使用贝尔曼方程不断迭代近似 Q-函数。在最简单的例子中,Q -函数可通过一个表格的形式实现,其中状态作为行,动作作为列。Q-学习算法的要点可简单归结如下:

算法中的 α 是指学习率,其控制前一个 Q 值和新提出的 Q 值之间被考虑到的差异程度。尤其是,当 α=1 时,两个 Q[s,a] 互相抵消,结果刚好和贝尔曼方程一样。
我们用来更新 Q[s,a] 的
5、深度 Q 网络(Deep Q Network)
《打砖块(Breakout)》 游戏环境的状态可由拍子的位置、球的位置和方向以及每个砖块的存在与否来定义。但这种直观的表征是这个游戏独有的。我们能想出适合所有游戏的表征吗?屏幕像素是一个明显的选择,它们毫无疑问包含了游戏状况中除了球的速度和方向以外的所有相关信息。两个连续的屏幕就能覆盖这些例外。
像 DeepMind 的论文描述的那样,如果我们在游戏屏幕上应用相同的预处理——以最近四张屏幕照片为例,将它们的尺寸调整到 84×84 并将它们灰度调整为 256 阶灰度——我们会得到 256^84x84x4≈10^67970 种可能的游戏状态。这意味着我们想象的 Q 函数表有 10^67970 行——超过已知宇宙中原子的总数!有人可能会说很多像素组合(即状态)根本不可能出现——我们也许可以用一个只包含可访问状态的稀疏的表格来表示它。即便如此,其中大部分状态都是极少能出现的,要让 Q-函数表收敛,那得需要整个宇宙寿命那么长的时间。理想情况下,我们也喜欢对我们从未遇见过的状态所对应的 Q 值做出很好的猜测。
这就到了深度学习的用武之地。神经网络在高度结构化数据的特征提取方面表现格外优异。我们可以使用神经网络表示我们的 Q 函数,并将状态(四个游戏屏幕)和动作作为输入,将对应的 Q 值作为输出。或者我们也可使用唯一的游戏屏幕作为输入,并为每一个可能的动作输出 Q 值。这种方法有自己的优势:如果我们想执行 Q 值更新或选取对应最高 Q 值的动作,我们只需对网络进行一次彻底的前向通过,就能立即获得所有可能的动作的 Q 值。
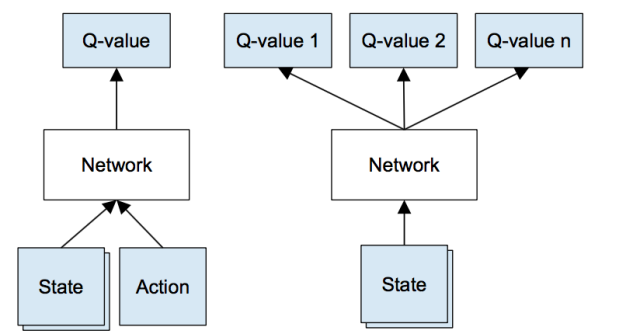
图3:左图:深度 Q 网络基本形式;右图:优化过的深度 Q 网络架构,在 DeepMind 论文中使用过
DeepMind 使用的网络架构如下:
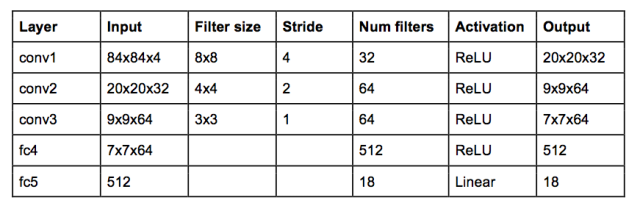
这是一个经典的带有三个卷积层的卷积神经网络,后面跟随着两个全连接层。熟悉对象识别网络的人可能注意到这里并不没有池化层(pooling layer)。但如果真正仔细想想,池化层让你获得了平移不变性(translation invariance)——网络变得对图像中的物体的位置不敏感。这对于 ImageNet 这样的分类任务是有意义的,但游戏中球的位置对确定潜在的奖励是至关重要的,而且我们并不希望丢弃这个信息!
这个网络的输入是 4 个 84×84 的灰度游戏屏幕。这个网络的输出是是每一个可能动作的 Q 值(Atari 中有 18 个动作)。Q 值可以是任何真实值,这使其成为了一个回归( regression )任务,可以使用简单的平方误差损失进行优化。
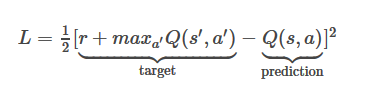
对于给定变换< s, a, r, s’ >,前一算法中的 Q 表格更新规则必须被以下规则取代:
为当前状态 s 进行一次前向通过,获得所有动作的预测的 Q 值.
为下一个状态 s’ 进行一次前向通过,计算整体网络输出的最大值
。
为动作设置 Q 值目标
(使用第 2 步中计算出的最大值).对于所有其它动作,设置 Q 值目标为第 1 步中原本返回的值,使这些输出的误差为 0。
使用反向传播更新权重
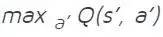 。
。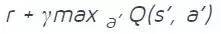
6、经验回放(experience replay)
现在,我们有一个使用 Q 学习估计每个状态的未来奖励和使用一个卷积神经网络逼近 Q 函数的想法了。但事实证明,使用非线性函数的 Q 值逼近不是很稳定。事实上你不得不使用很多技巧才能使其收敛。而且也需要很长的处理时间——在单个 GPU 上需要几乎一周的时间。
最重要的技巧是经验回放。在游戏过程中,所有经验 < s, a, r, s’ > 都被存储在回放存储器中。当训练网络时,使用的是来自回放存储器的随机微批数据(minibatches),而不是使用最近的变换。这打破了后续训练样本的相似性,否则其就可能使网络发展为局部最小。经验回放也会使训练任务更近似于通常的监督式学习,从而简化了算法的调式和测试。我们实际上可以从人类玩的游戏中学习到所有这些经验,然后在这些经验之上训练网络。
7、探索-开发(Exploration-Exploitation)
Q-学习试图解决信用分配问题(Credit Assignment Problem)——它能在时间中反向传播奖励,直到其到达导致了实际所获奖励的关键决策点。但我们还没触及到探索-开发困境呢……
首先观察,当 Q 函数表或 Q 网络随机初始化时,那么其预测一开始也是随机的。如果我们选择一个有最高 Q 值的动作,那么该动作就将是随机的且该代理会执行粗糙的「探索(exploration)」。当 Q 函数收敛时,它返回更稳定的 Q 值,探索的量也会减少。所以我们可以说,Q 学习将探索整合为了算法的一部分。但这种探索是「贪心的(greedy)」,它会中止于其所找到的第一个有效的策略。
针对上述问题的一个简单而有效的解决方法是 ε-贪心探索(ε-greedy exploration)——其概率 ε 选择了一个随机动作,否则就将使用带有最高 Q 值的「贪心的」动作。在 DeepMind 的系统中,他们实际上随时间将 ε 从 1 降至了 0.1——一开始系统采取完全随机的行动以最大化地探索状态空间,然后再稳定在一个固定的探索率上。
8、深度 Q 学习算法
这带给了我们使用经验回放的最后的深度 Q 学习算法:

DeepMind 还使用了更多技巧使其真正能够工作——如目标网络、错误剪裁(error clipping)、奖励剪裁(reward clipping),但这些超出了本文的介绍范围。
这个算法最精彩的一面在于其能学习任何事物。试想一下,因为我们的 Q 函数是随机初始化的,它的初始输出完全是垃圾。而我们使用这个垃圾(下一状态的最大 Q 值)作为网络的目标,只有偶尔处在一个很小的奖励范围内。这听起来很疯狂,它到底怎么能学习任何有意义的事物呢?但事实是它确实可以。
9、最后说明
自问世以来,Q 学习已经取得了很多改进——比如:双 Q 学习(Double Q-learning)、优先经验回放(Prioritized Experience Replay)、竞争网络架构(Dueling Network Architecture)和连续动作空间的扩展。NIPS 2015 深度强化学习研讨会和 ICLR 2016 上可以看到一些最新的进展。但要清楚,深度 Q 学习已被谷歌申请了专利。
人们常常说,人工智能是一种我们仍未清楚明白的东西。一旦我们理解了它们的工作方式,它就看起来不再智能了。但深度 Q 网络仍然让我惊叹。看着它们弄懂一个新游戏就像是在观察野生动物——这本身就是一个有益的体验。
二、使用 Neon 的深度强化学习
这是探讨深度强化学习系列博文的第二部分。
当我们研究组第一次读到 DeepMind 的论文「Playing Atari with Deep Reinforcement Learning」时,便当即想要复制这一惊人结果。那是在 2014 年初, 当时 cuda-convnet2 是性能最强的卷积网络实现方式,而 RMSProp 还只是 Hinton 在Coursera课上的一张幻灯片。我们不断调试,学习,但是当DeepMind与他们的《自然》论文「Human-level control through deep reinforcement learning」同时公布了代码时,我们便开始在他们的代码上做研究。
从那时起深度学习系统已经演进了很多。据说 2015 年时每 22 天就会出现一个新的深度学习工具包。其中著名的有像 Theano、Torch7 和 Caffe 这些老前辈们,也有 Neon、Keras 和 TensorFlow 这些新生代。新的算法一经公布就会被实现。
在某种程度上我意识到一年前困扰我们的所有困难部分,如今都在大多深度学习工具包中都能被轻而易举地实现。当 Arcade Learning Environment 这一仿真 Atari 2600 游戏的系统发布一款本地 Python API 后,它可刚好用以执行新的深度强化学习。编写主代码只需花费一周左右,然后是数周的调试。
我选择在 Neon 上编写,因为它有:
最快的卷积核(convolutional kernel);
实现所需的所有算法(如 RMSProp);
一个合理的 Python API;
我试着保持我的代码的简介性和易扩展性,同时兼顾性能。目前 Neon 最知名的限制是它仅能在最新的英伟达 Maxwell GPU 上运行,不过也就快改变了。
下面我将介绍:
如何安装 Simple-DQN
你能用 Simple-DQN 做什么
比较 Simple-DQN 与其它算法
如何修改 Simple-DQN
1、如何安装 Simple-DQN?
这里没什么可说的,就按说明书 README 来吧。基本上你所需要的只是 Neon、Arcade Learning Environment 和 simple_dqn。尝试预训练模型时你甚至不需要 GPU,因为它们也能在 CPU 上运行,虽然很慢。
2、你能用 Simple-DQN 做什么?
运行一个预训练模型:一旦你安装完所有部分,首先要做的就是尝试运行预训练模型。例如运行一个《打砖块》的预训练模型,输入:
./play.sh snapshots/breakout_77.pkl
或者如果你没有可用的 (Maxwell) GPU,也可以换成 CPU:
./play.sh snapshots/breakout_77.pkl –backend cpu
你应当会看到这样的画面,并可能伴随一些恼人的声音: )

你可以关掉人工智能并按[m]键来掌控游戏——看看能坚持多久!再按[m]键即返回人工智能控制模式。
事实上通过重复按[a]键来降低游戏速度很管用——你可以真正看到游戏中在发生什么。按[s]重新加速。
录制视频:同样你可以录制一个游戏视频(在《打砖块》中录制,直到失去 5 条命之后):
./record.sh snapshots/breakout_77.pkl
视频将存储为 videos/breakout_77.mov 而游戏截屏存储在 videos/breakout 中。这有一个视频案例:
训练一个新模型:要训练新模型,首先需要一个游戏的 Atari 2600 ROM 文件。然后将它保存在 roms 文件夹中并运行以下训练代码:
./train.sh roms/pong.rom
其结果就是创建了下列文件:
results/pong.csv,包括训练过程的各个统计数据,
snapshots/pong_<epoch>.pkl,每个时期的模型简介
测试一个模型:训练过程中在每个时期后有一个测试阶段。如果你想稍后再重新测试预训练模型,则可用以下测试脚本:
./test.sh snapshots/pong_141.pkl
它将测试结果打印到控制台。保存文件并添加–csv_file <filename>参数。
绘制统计数据:训练过程中及之后,你可能想要知道模型的效果。这里有段简单的从统计文件中制作图像的绘制脚本。例如:
./plot.sh results/pong.csv
它创建了这个文件results/pong.png.
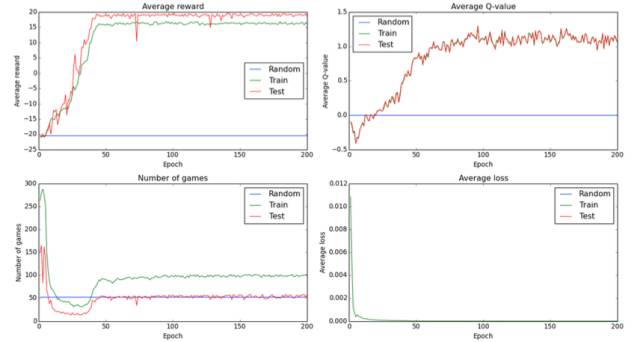
它会默认绘制 4 张图:
平均得分,
玩过的游戏数量,
验证集合状态的平均最大 Q值 ,
平均训练损失。
对于所有的图,你能看到随机基线(那是它们有意义的位置)和训练阶段及测试阶段的结果。实际上你可以通过列出 –fields参数中的字段名,从统计文件中绘制出任何字段。默认图由 –fieldsaverage_reward,meanq,nr_games,meancost 实现。字段名可从 CSV 文件的第一行得出。
可视化滤波器:运用这个代码可做的最令人兴奋的事莫过于窥视人工智能的心灵。我们将用到导向型反向传播(guided backpropagation),它带有即开即用的 Neon 。简单的说,对于每个卷积滤波器,它会从给定的数据集合中找到一副最能激活该滤波器的图像。然后它执行关于输入图像的反向传播,观察图像的哪一部分对滤波器的「活性(activeness)」影响最大。这可以被当做是一种形式的显著性检测(saliency detection)。
执行滤波器可视化运行以下代码:
./nvis.sh snapshots/breakout_77.pkl
它以玩游戏收集样本数据开始,然后执行导向型反向传播。结果可在 results/breakout.html 中找到,它们看起来像这样:

有三个卷积层(记为 0000、0002 和 0004),这里我只从每个(Feature Map 0-1(特征映射 0-1))中对 2 个滤波器进行了可视化。还有有 16 个滤波器可视化的《打砖块》的更细节的文件。每个滤波器选择了最能激活它的图像。右边的图像展现原始输入,左边图像展示导向型反向传播结果。你可以把每个过滤器看成一只人工智能的「眼睛」。即左侧图展现了在右侧图像的条件下,这个特定的「眼睛」所导向的位置。
由于我们网络的输入是一系列 4 灰度级图像,所以可视化过程并不清晰。我做了一个简化:只选用某种状态的最后 3 张图像并将它们放入不同 RGB 颜色信道中。因此 3 张图像上的所有灰色部分都没有改变;蓝色是最近的变化,然后是绿色,然后又是红色。放大观察你便轻松可知——其轨道由红-绿-蓝所标记。这使得理解反向传播结果的难度增加了,不过有时你可以猜测滤波器的轨道运动(tracks movement)——从一个角落到另一个角落,颜色从红到绿到蓝变化。
可视化滤波器是一款十分有用的工具,你能够立刻得到一些有趣的观察结果。
第一层滤波器主要针对抽象模式,不能与任何特定对象建立可靠的关联。它们通常最能激发比分和生命值,这可能由于其有着众多边角(供识别)。当然你也能偶尔在更高层发现一些关注比分和生命值的滤波器。
正如预期的那样,有些滤波器追踪球和拍子。还有些滤波器在球将要撞上砖头或牌子时激活最多。
同样如预期的是,更高层的滤波器有着更大感受域(receptive field)。这在《打砖块》中还不明显,但是在这个《乒乓球(Pong)》游戏的文件中可以清楚地看到。有意思的是《打砖块》中不同层的滤波器比《乒乓球》中的更相似。
模型上使用。这么做的一个好处是它将导向型反向传播及可视化整合进同一个步骤中并且无需临时文件来编写中间结果。不过那样的话我需要对保存在 nvis 文件夹中的 Neon 代码做一些修正。
3、比较 Simple-DQN 与其它算法
另外还有一些深度强化学习实现方式,将它们与在 Neon 中的实现方式进行比较会很有意思。其中最知名的是连同其《自然》杂志文章一起发表的原始版 DeepMind 代码。另一个维护版本是弗吉尼亚州詹姆斯·麦迪逊大学 Nathan Sprague 开发的 deep_q_rl。
深度强化学习中最普遍的度量标准是平均每局游戏得分。为了计算它用于 simple_dqn,我使用了与那篇《自然》杂志文章中提到的相同的评估程序——运用不同初始随机条件和一个 ε=0.05 的 ε-贪心策略( ε-greedy policy)获得的 30 场比赛的平均分数。我并没有麻烦为每个游戏执行 5 分钟的限制,因为《打砖块》和《乒乓球》中的游戏不会持续那么久。对于 DeepMind 我是用了自然杂志那篇文章里的数据。而对于 deep_q_rl,我让 deep-q-learning 列表中的成员提供了数据。他们的分数采集没有使用完全相同的协议(下面的特殊数字是 11 场游戏的平均成绩),所以可能需要考虑一点言过其实。
另一个有趣的测试是每秒的训练步数。DeepMind 和 simple_dqn 都报告了每个时期每秒的平均训练步数(250000步)。deep_q_rl报告了动态的步速而我只是粗略估计了下其平均步数: )。在所有案例中我都查看了第一个时期,其探测率接近 1,因此这个结果更多反映了训练速度而非预测速度。所有测试均在英伟达 Geforce Titan X 上完成。
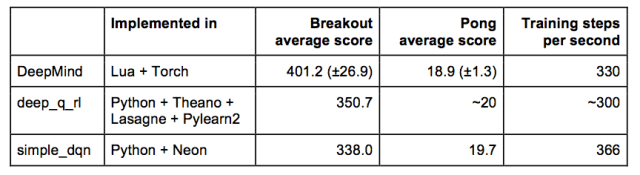
可以看到 simple_dqn 在速度方面明显优于其他算法。尽管学习结果还不能向 DeepMind 看齐,不过运行一些有趣的实验已经足够可行了。
4、如何修改Simple-DQN?
公布 simple_dqn 代码的主要考量是展示实现过程实际上可以多么简单,每个人都能够拓展它去做一些有趣的研究。
代码中存在四个类: Environment、ReplayMemeory、DeepQNetwork 和 Agent。还有用于处理解析和实例化上述类的参数的 main.py,以及执行基本回调机制以保证统计数据收集与主循环分离的 Statistics 类。但是深度强化学习算法的主要部分会在上述四个类中执行。
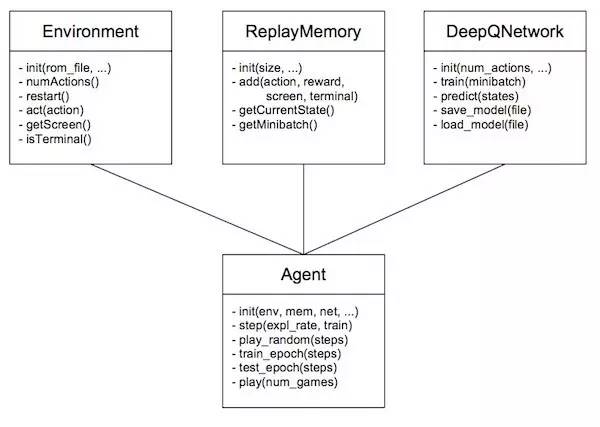
Environment 类:Environment 类只是微软 A.L.E Python API 外的轻巧包装。除了 A.L.E 应该也可轻而易举地添加其他环境。例如 Flappy Bird 和 Torcs——你只需执行一个新的 Environment 类。试试看吧!
ReplayMemory 类:回放记忆(replay memory)存储状态转换或经验。基本上它只是屏幕、动作、奖励和终端状态指示器的四个大数组。
回放记忆作为一组屏幕序列存储,而非由 4 个屏幕组成的状态序列。这使得内存使用大大减少而性能方面也无重大损失。运用 NumPy 数组切片将屏幕组装进状态会更快。
屏幕像素的数据类型是 uint8(8位无符号整型),这意味着1M 经验需要 6.57GB ——只需 8GB 内存来运行!而默认的 float32(32位浮点型)数据类型则 1M 需要大约 26GB。
如果你想实现优先经验回放(prioritized experience replay),那么这是你主要需要改变的类。
DeepQNetwork 类:此类用于实现深度 Q 网络。它其实也是唯一一个依赖 Neon 的类。
由于深度强化学习的迷你批处理(minibatching)方式各有不同,所以没有理由运用 Neon 的 DataIterator 类。因此转而使用更低级的 Model.fprop() 和 Model.bprop()。下面是给想做同样事情的人的建议:
你需要在构建模型后调用 Model.initialize()。它在 GPU 内存中为层的激活及权重分配张量。
Neon 张量有几个维度(信道、高度、宽度、批大小)。尤其批大小是最后一维。这种数据布局能实现最快卷积核。
置换一个 Numpy 数组的维度来匹配 Neon 张量需求时,一定要复制数组!否则实际的内存布局并不会改变且数组不能直接复制进 GPU 中。
除了使用有数组索引的单个张量元素(比如张量 [i,j]),试着运用 tensor.set() 和 tensor.get() 将张量作为一个整体复制到 Numpy 数组中。这能让 CPU 和 GPU 间往返过程更少。
考虑到要在 GPU 中执行张量算法,Neon backend 提供了一个好方法。同时也要注意这些操作运算不会立即被评估,而是作为 OpTree 存储起来。只有在你使用张量或将其转换到 CPU 里时,张量才能真正得到评估。
如果想要实现双 Q 学习(double Q-learning),则需要对此类进行修改。
Agent 类:Agent 类连接所有部件并执行主要的逻辑。
5、结论
正如我向你们展示的那样,运用类似 Neon 的优良深度学习工具包实现 Atari 视频游戏的深度强化学习简直宛若一道春风。Neon 中滤波器可视化功能提供了有关模型实际所学习内容的重要参考。
尽管这不是它本身的目标,但是计算机游戏为试验新的强化学习方法提供了卓越的沙盘。希望我的 simple_dqn 实现能够成为大家进入深度强化学习研究这一迷人领域的垫脚石。
©本文由机器之心编译,转载请联系本公众号授权。

新一代技术+商业操作系统:
AI-CPS OS
在新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生,在行业、企业和自身三个层面勇立鳌头。
数字化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置。
分辨率革命:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品控制、事件控制和结果控制。
复合不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊化:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。随着变革范围不断扩大,一切都几乎变得不确定,即使是最精明的领导者也可能失去方向。面对新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)颠覆性的数字化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位。
如果不能在上述三个层面保持领先,领导力将会不断弱化并难以维继:
重新进行行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建你的企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造新的自己:你需要成为怎样的人?要重塑自己并在数字化时代保有领先地位,你必须如何去做?
子曰:“君子和而不同,小人同而不和。” 《论语·子路》
云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。
在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。
云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
人工智能通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
新一代信息技术(云计算、大数据、物联网、区块链和人工智能)的商业化落地进度远不及技术其本身的革新来得迅猛,究其原因,技术供应商(乙方)不明确自己的技术可服务于谁,传统企业机构(甲方)不懂如何有效利用新一代信息技术创新商业模式和提升效率。
“产业智能官”,通过甲、乙方价值巨大的云计算、大数据、物联网、区块链和人工智能的论文、研究报告和商业合作项目,面向企业CEO、CDO、CTO和CIO,服务新一代信息技术输出者和新一代信息技术消费者。
助力新一代信息技术公司寻找最有价值的潜在传统客户与商业化落地路径,帮助传统企业选择与开发适合自己的新一代信息技术产品和技术方案,消除新一代信息技术公司与传统企业之间的信息不对称,推动云计算、大数据、物联网、区块链和人工智能的商业化浪潮。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发人工智能型企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。
重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能)正在经历从“概念”到“落地”,最终实现“大范围规模化应用,深刻改变人类生活”的过程。
产业智能官 AI-CPS
用新一代技术+商业操作系统(AI-CPS OS:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能驾驶”、“智能金融”、“智能城市”、“智能零售”;新模式:“案例分析”、“研究报告”、“商业模式”、“供应链金融”、“财富空间”。
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com



