网络架构设计:CNN based和Transformer based

极市导读
本文主要解析了CNN based和Transformer based的网络架构设计,其中CNN based涉及ResNet和BoTNet,Transformer based涉及ViT和T2T-ViT。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
从DETR到ViT等工作都验证了Transformer在计算机视觉领域的潜力,那么很自然的就需要考虑一个新的问题,图像的特征提取,究竟是CNN好还是Transformer好?
其中CNN的优势在于参数共享,关注local信息的聚合,而Transformer的优势在于全局感受野,关注global信息的聚合。直觉上来讲global和local的信息聚合都是有用的,将global信息聚合和local信息聚合有效的结合在一起可能是设计最佳网络架构的正确方向。
如何有效的结合global和local信息,最近的几篇文章主要分成了两个方向:CNN based和Transformer based。以下主要解析一下CNN based和Transformer based的网络架构设计,其中CNN based涉及ResNet和BoTNet,Transformer based涉及ViT和T2T-ViT。
网络架构设计的相互关系
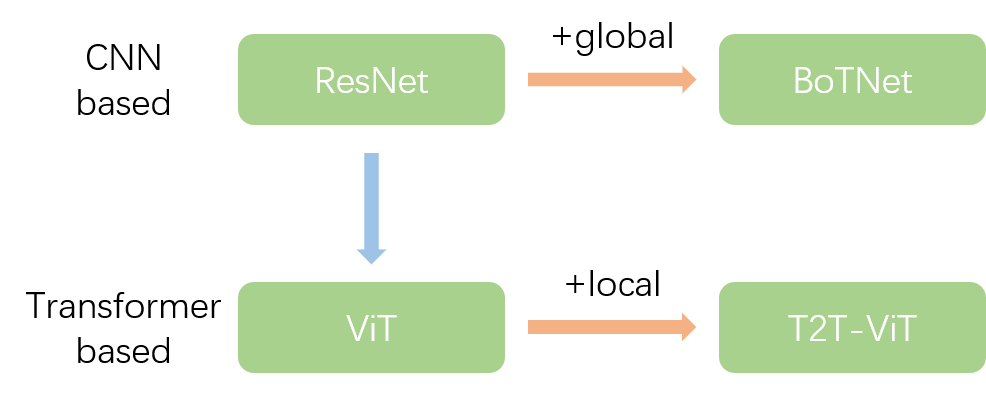
BoTNet在ResNet的基础上将Bottlenneck的3x3卷积替换成MHSA,增加CNN based的网络架构的global信息聚合能力。T2T-ViT在ViT的基础上将patch的linear projection替换成T2T,增加Transformer based的网络架构的local信息聚合能力。
ResNet&BoTNet
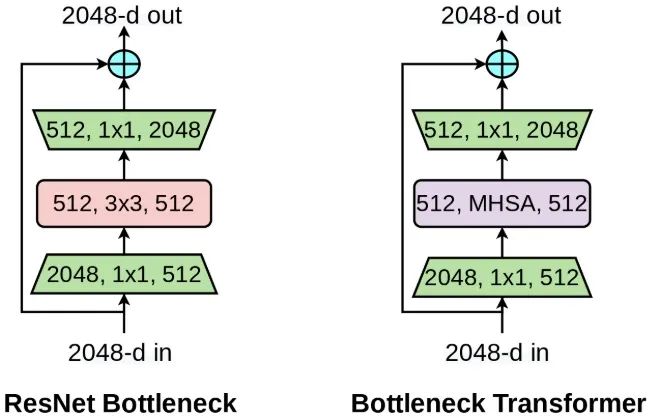
ResNet的结构设计,ResNet主要由Bottleneck结构堆叠而成,一层Bottlenneck由1x1conv、3x3conv和1x1conv堆叠构成残差分支,然后和skip connect分支相加。BoTNet在Bottlenneck结构的基础上将中间的3x3conv替换成MHSA结构,跟之间的Non-local等工作非常相似,本质上在CNN中引入global信息聚合。
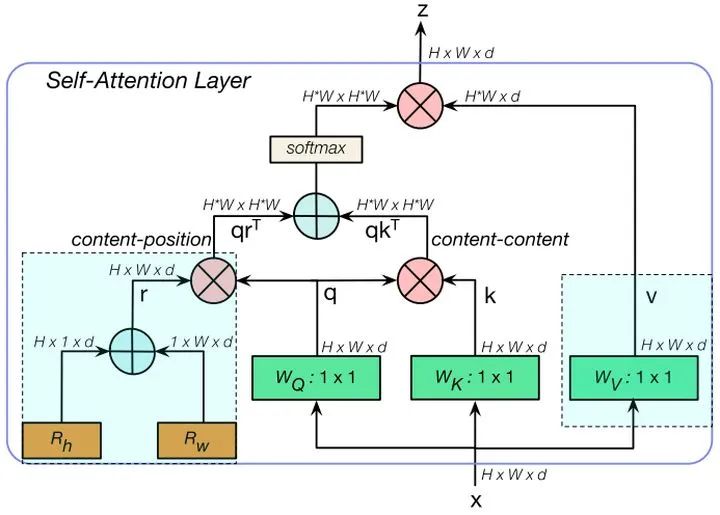
MHSA结构如上图所示,代码如下。
class MHSA(nn.Module): def __init__(self, n_dims, width=14, height=14): super(MHSA, self).__init__()
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1) self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1) self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.rel_h = nn.Parameter(torch.randn([1, n_dims, 1, height]), requires_grad=True) self.rel_w = nn.Parameter(torch.randn([1, n_dims, width, 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x): n_batch, C, width, height = x.size() q = self.query(x).view(n_batch, C, -1) k = self.key(x).view(n_batch, C, -1) v = self.value(x).view(n_batch, C, -1)
content_content = torch.bmm(q.permute(0, 2, 1), k)
content_position = (self.rel_h + self.rel_w).view(1, C, -1).permute(0, 2, 1) content_position = torch.matmul(content_position, q)
energy = content_content + content_position attention = self.softmax(energy)
out = torch.bmm(v, attention.permute(0, 2, 1)) out = out.view(n_batch, C, width, height)
return out
跟Transformer中的multi-head self-attention非常相似,区别在于MSHA将position encoding当成了spatial attention来处理,嵌入两个可学习的向量看成是横纵两个维度的空间注意力,然后将相加融合后的空间向量于q相乘得到contect-position(相当于是引入了空间先验),将content-position和content-content相乘得到空间敏感的相似性feature,让MHSA关注合适区域,更容易收敛。另外一个不同之处是MHSA只在蓝色块部分引入multi-head。
ViT
ViT是第一篇纯粹的将Transformer用于图像特征抽取的文章。
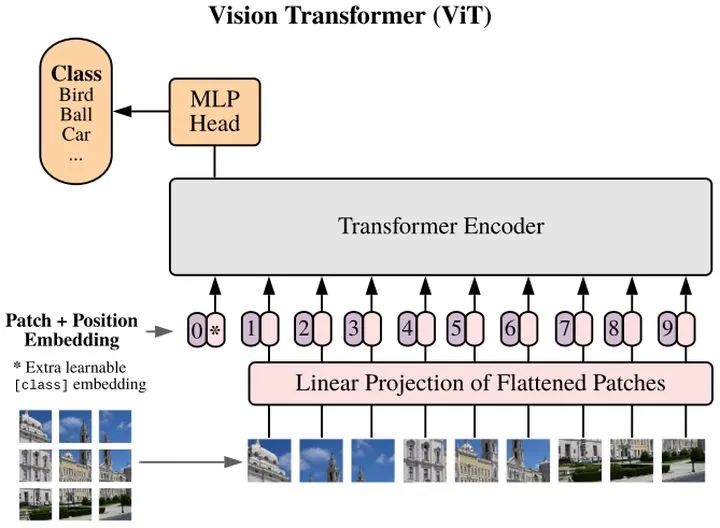
Vision Transformer(ViT)将输入图片拆分成16x16个patches,每个patch做一次线性变换降维同时嵌入位置信息,然后送入Transformer。类似BERT[class]标记位的设置,ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位,并且该位置的Transformer Encoder输出作为图像特征。
假设输入图片大小是256x256,打算分成64个patch,每个patch是32x32像素。
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)# 将3072变成dim,假设是1024self.patch_to_embedding = nn.Linear(patch_dim, dim)x = self.patch_to_embedding(x)
这个写法是采用了爱因斯坦表达式,具体是采用了einops库实现,内部集成了各种算子,rearrange就是其中一个,非常高效。p就是patch大小,假设输入是b,3,256,256,则rearrange操作是先变成(b,3,8x32,8x32),最后变成(b,8x8,32x32x3)即(b,64,3072),将每张图片切分成64个小块,每个小块长度是32x32x3=3072,也就是说输入长度为64的图像序列,每个元素采用3072长度进行编码。考虑到3072有点大,ViT使用linear projection对图像序列编码进行降维。
T2T-ViT
ViT虽然验证了Transformer在图像分类网络架构设计的潜力,但是需要额外的大规模数据来进行pre-train,而在中等规模数据集如imagenet上效果却不理想。T2T-ViT引入了local的信息聚合来增强ViT局部结构建模的能力,使得T2T-ViT在中等规模imagenet上训练能达到更高的精度。
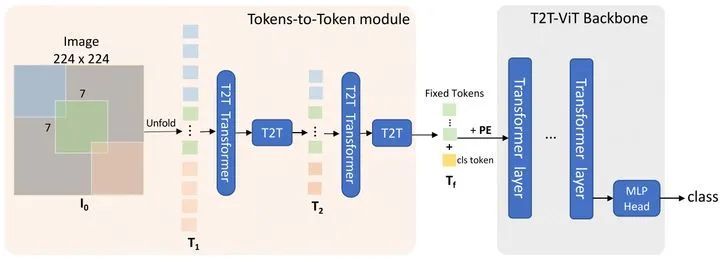
在T2T模块中,先将输入图像软分割为小块,然后将其展开成一个tokens T0序列。然后tokens的长度在T2T模块中逐步减少(文章中使用两次迭代然后输出Tf)。后续跟ViT基本上一致。
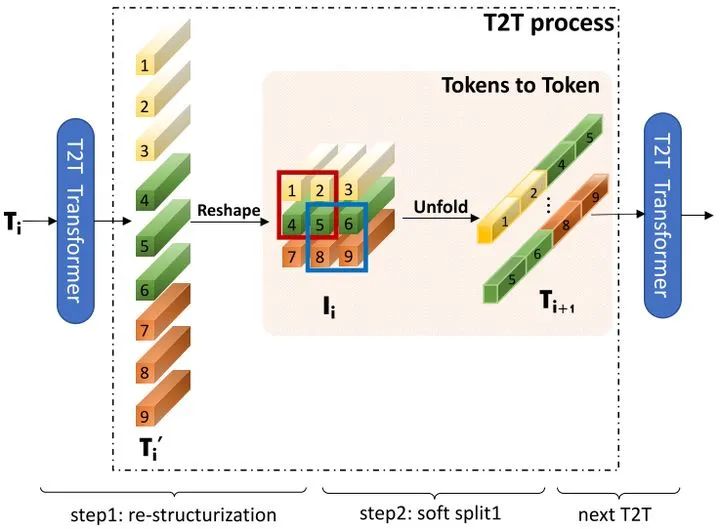
一次迭代T2T结构由re-structurization和soft split构成,re-structurization将一维序列reshape成二维图像, soft split对二维图像进行滑窗操作,拆分成重叠块。
以token transformer为例,先将输入图像拆分成7x7的重叠块,然后通过token transformer,进行块内的global信息聚合,然后通过re-structurization和soft split进行token重组和拆分成3x3的重叠块,得到长度更短的token序列,重复迭代两次,最后linear projection进一步降低token序列长度。
class T2T_module(nn.Module): """ Tokens-to-Token encoding module """ def __init__(self, img_size=224, in_chans=3, embed_dim=768, token_dim=64): super().__init__()
self.soft_split0 = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2)) self.soft_split1 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)) self.soft_split2 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.attention1 = Token_transformer(dim=in_chans * 7 * 7, in_dim=token_dim, num_heads=1, mlp_ratio=1.0) self.attention2 = Token_transformer(dim=token_dim * 3 * 3, in_dim=token_dim, num_heads=1, mlp_ratio=1.0) self.project = nn.Linear(token_dim * 3 * 3, embed_dim)
self.num_patches = (img_size // (4 * 2 * 2)) * (img_size // (4 * 2 * 2)) # there are 3 soft split, stride are 4,2,2 seperately
def forward(self, x): # step0: soft split x = self.soft_split0(x).transpose(1, 2)
# iteration1: restricturization/reconstruction x = self.attention1(x) B, new_HW, C = x.shape x = x.transpose(1,2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW))) # iteration1: soft split x = self.soft_split1(x).transpose(1, 2)
# iteration2: restricturization/reconstruction x = self.attention2(x) B, new_HW, C = x.shape x = x.transpose(1, 2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW))) # iteration2: soft split x = self.soft_split2(x).transpose(1, 2)
# final tokens x = self.project(x)
return x
总结
1.global和local信息聚合的关系
global和local应该相互补充来同时balance 速度和精度,同时提升速度和精度的上限
2.CNN based和Transformer based的关系,CNN based 和 Transformer based哪个好
本质上是网络架构设计是以CNN为主好还是Transformer为主好的问题,CNN为主还是将输入当成二维的图像信号来处理,Transformer为主则将输入当成一维的序列信号来处理,所以想要研究清楚CNN为主好还是Transformer为主好的问题,需要去探索哪种输入信号更加具有优势,之前不少研究都表明CNN的padding可能透露了位置信息,而Transformer因为没有归纳偏见,需要增加position encoding来引入位置信息。CNN为主和Transformer为主各有优劣,目前来看暂无定论,且看后续发展。
Reference
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~