一文细数73个Vision transformer家族成员

极市导读
本文主要包含跟Transformer相关的CV文章(主要包含图像分类/目标检测/语义分割等任务),本文用简短的话来描述一下涉及到文章的核心idea。可以看作是vision transformer的idea集,查漏补缺使用。需要精读的文章前面加了*号,均附有文章链接及代码链接。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
https://github.com/dk-liang/Awesome-Visual-Transformer
https://github.com/IDEACVR/awesome-detection-transformer
Image Classification
Uniform-scale
*ViT
paper:https://arxiv.org/abs/2010.11929
code:https://github.com/google-research/vision_transformer
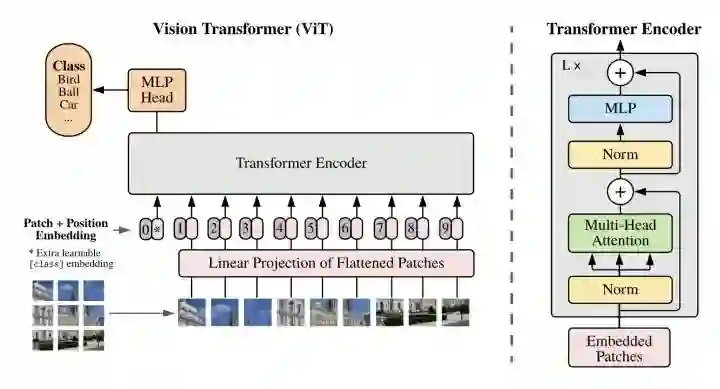
最简洁的Vision Transformer模型,先将图片分成16x16的patch块,送入transformer encoder,第一个cls token的输出送入mlp head得到预测结果。
*DeiT
paper:https://arxiv.org/abs/2012.12877
code:https://github.com/facebookresearch/deit)
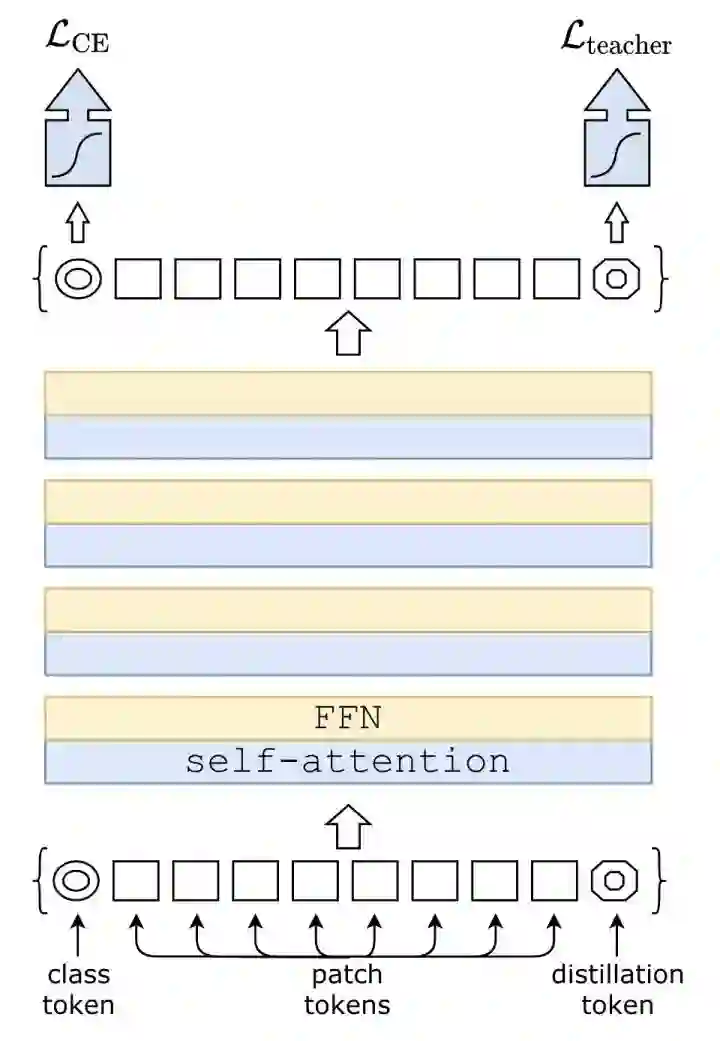
在ViT的基础上增加了一个distillation token,巧妙的利用distillation token提升模型精度。
T2T-ViT
paper:https://arxiv.org/abs/2101.11986
code:https://github.com/yitu-opensource/T2T-ViT
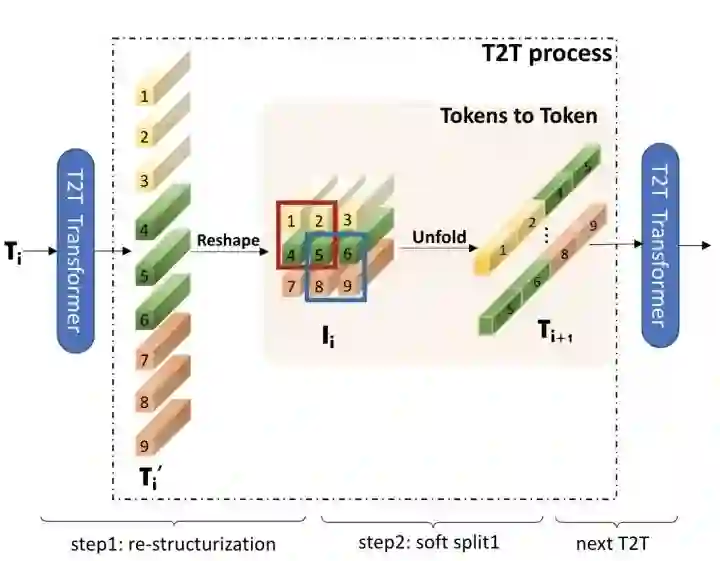
将ViT的patch stem改成重叠的滑窗形式,增强patch之间的信息交流。
Conformer
paper:https://arxiv.org/abs/2105.03889
code:https://github.com/pengzhiliang/Conformer
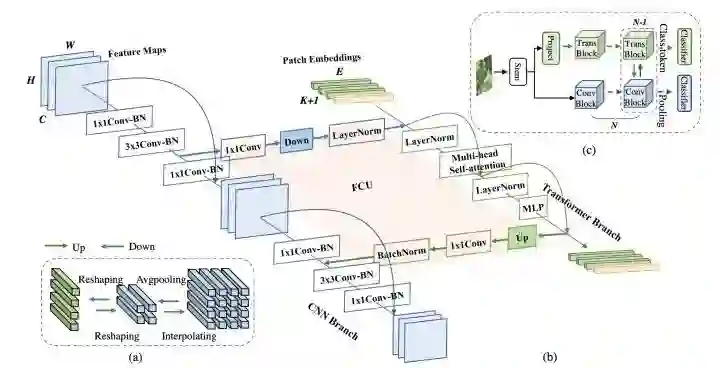
设计了一个CNN和Transformer双分支结构,利用FCU模块进行两个分支的信息交流,推理的时候使用两个分支的输出取平均进行预测。
TNT
paper:https://arxiv.org/abs/2103.00112
code:https://github.com/huawei-noah/noah-research/tree/master/TNT
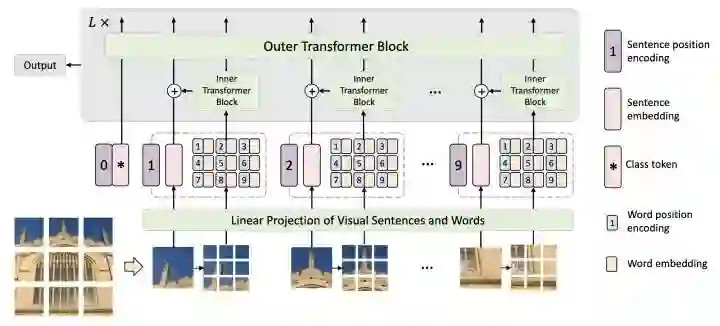
在ViT的基础上,对每个patch进一步切分,用嵌套的方式提升每个patch对于局部区域的特征表达能力,然后将局部提升后的特征和patch特征相加送入下一个transformer block中。
XCiT
paper:https://arxiv.org/pdf/2106.09681.pdf
code:https://github.com/facebookresearch/xcit
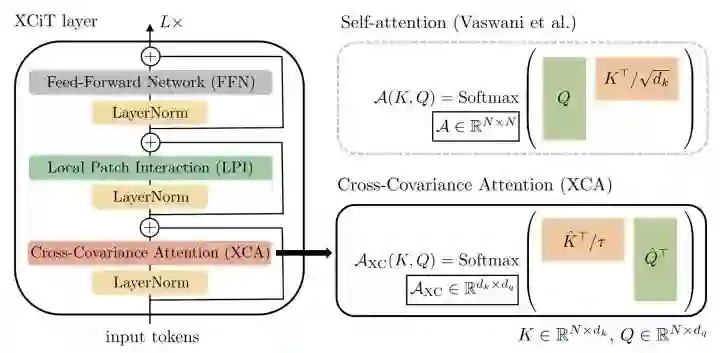
XCiT通过置换q和k的计算,从tokens做self-attention转变成channels纬度做self-attention(也就是通道的协方差计算),复杂度从平方降到了线性。
DeepViT
paper:https://arxiv.org/abs/2103.11886
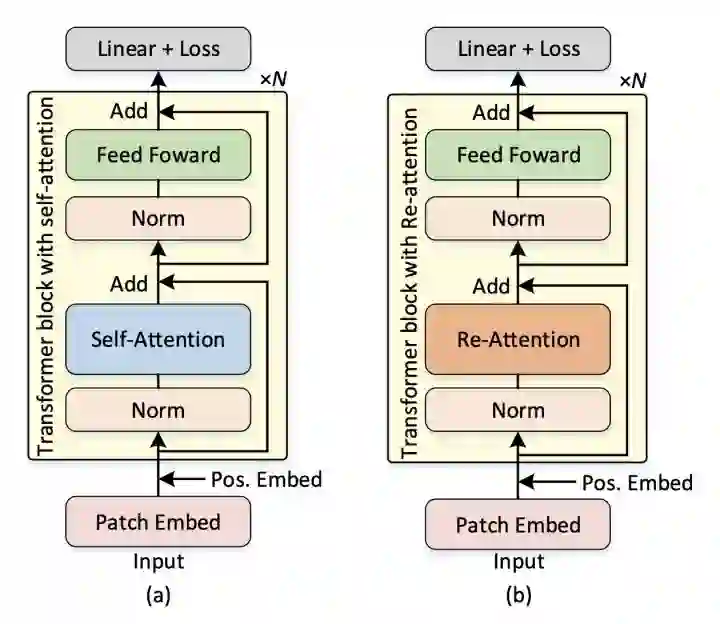
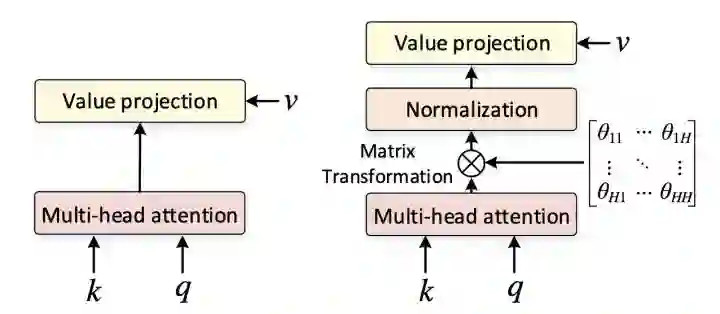
DeepViT发现随着深度的增加,ViT的self-attention会出现坍塌现象,DeepViT提出用Re-Attention来替代Self-Attention可以避免坍塌,可以训练更深的ViT,Re-Attention在MHSA之后增加了一个可学习的Matrix Transformation。
*Token Labeling ViT
paper:https://arxiv.org/abs/2104.10858
code:https://github.com/zihangJiang/TokenLabeling
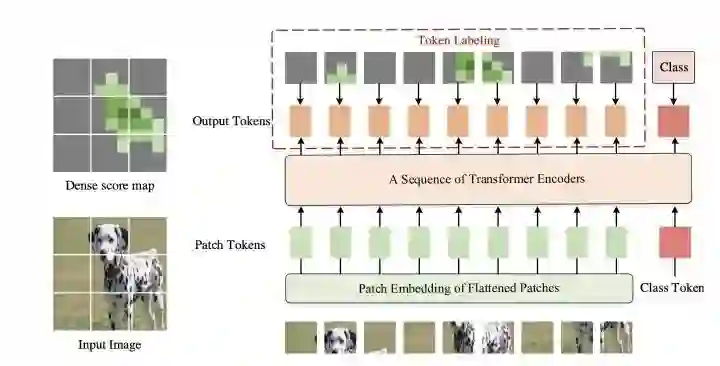
为了增加ViT对于局部区域的定位和特征提取能力,token labeling在每个patch的输出都增加一个局部监督,token label通过一个预训练过的特征提取器获得(本文可以看成是AutoEncoder+CLS的预训练方法)。由于需要一个额外的特征提取器,所以需要更多的计算资源(可以用MaskFeat的方法改进)。
SoT
paper:https://arxiv.org/abs/2104.10935
code:https://github.com/jiangtaoxie/So-ViT
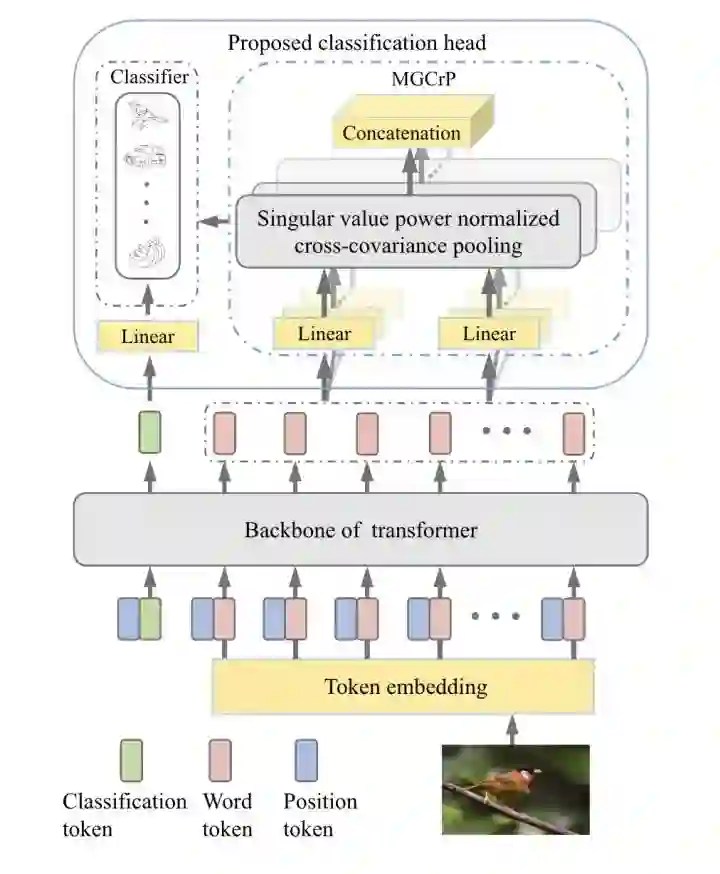
对patch输出的word token进行协方差池化,然后和cls token的输出进行融合,提高分类对局部区域的感知能力。
DVT
paper:https://arxiv.org/abs/2105.15075
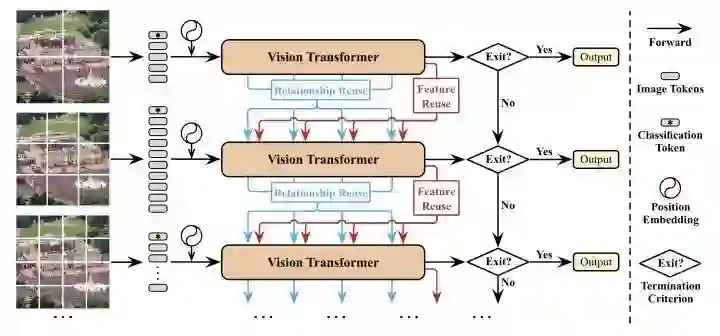
DVT提出每个图片应该有自己独有的token数量,于是设计了一个级联tokens数量逐渐增加的多个transformer,推理的时候可以从不同级的transformer判断输出。
DynamicViT
paper:https://arxiv.org/abs/2106.02034
code:https://dynamicvit.ivg-research.xyz/
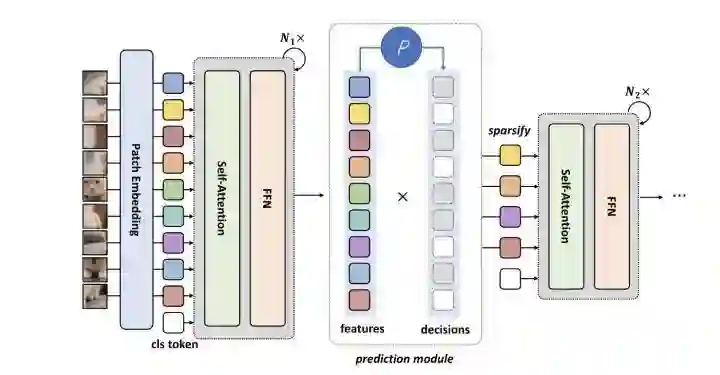
通过一个预测模块来决定token的重要程度,剪枝掉少量不重要的token,将剩余的token送入下一个block中。
PSViT
paper:https://arxiv.org/abs/2108.03428
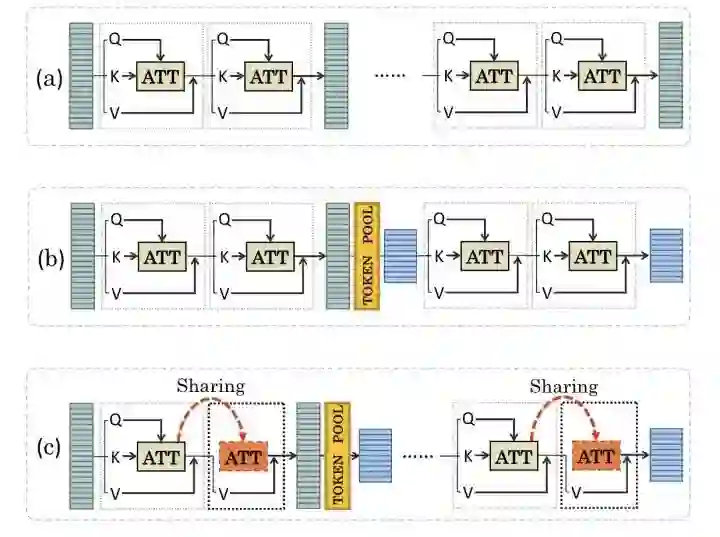
为了减少ViT计算上的冗余,PSViT提出token pooling和attention sharing两个操作,其中token pooling用来减少token的数量,attention sharing作用在相关性较强的相邻层上。
*TokenLearner
paper:https://arxiv.org/abs/2106.11297
code:https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
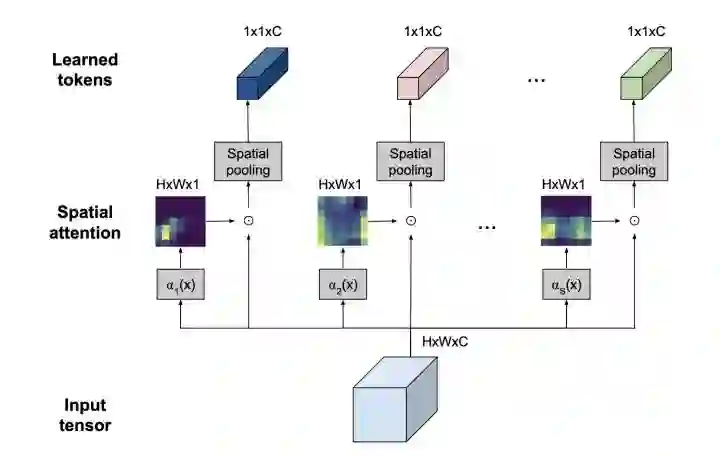
利用spatial attention来提取出最重要的token信息,减少token数量。
Evo-ViT
paper:https://arxiv.org/abs/2108.01390
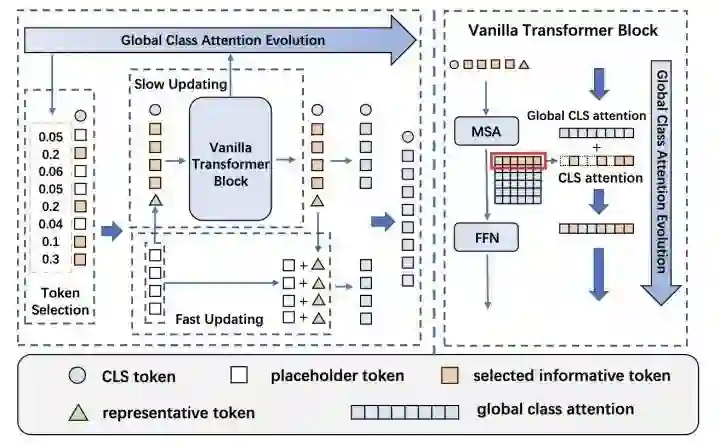
增加一个representative token,通过global class attention evolution来判断patch token的重要程度,重要程度高的送入block中缓慢更新,重要程度低的和representative token(由placeholder token得到)残差更新。其中vanilla transformer block的MSA输出和global cls attention相加得到重要性权重。
AugViT
paper:https://arxiv.org/abs/2106.15941
code:https://github.com/huawei-noah/CV-Backbones/tree/master/augvit_pytorch
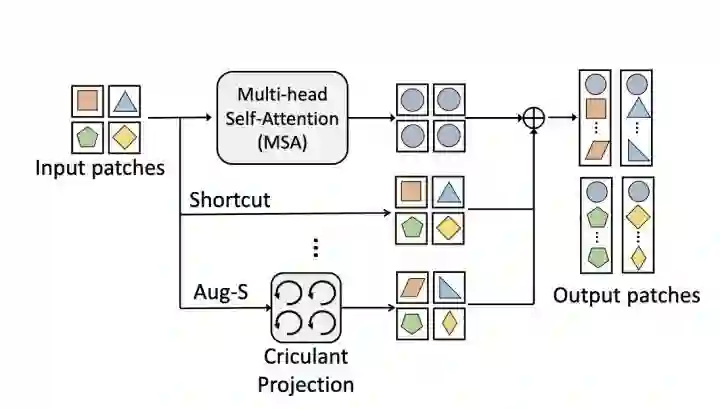
为了避免ViT出现模型坍塌现象,AugViT设计了一个augmented shortcuts结构。具体地,在MSA结构上并行增加两个分支,一个分支做shortcut操作,另一分支对每个patch做augmentation来增加特征表达的多样性,最后将三个分支的输出相加到一起。
CrossViT
paper:https://arxiv.org/abs/2103.14899
code:https://github.com/IBM/CrossViT
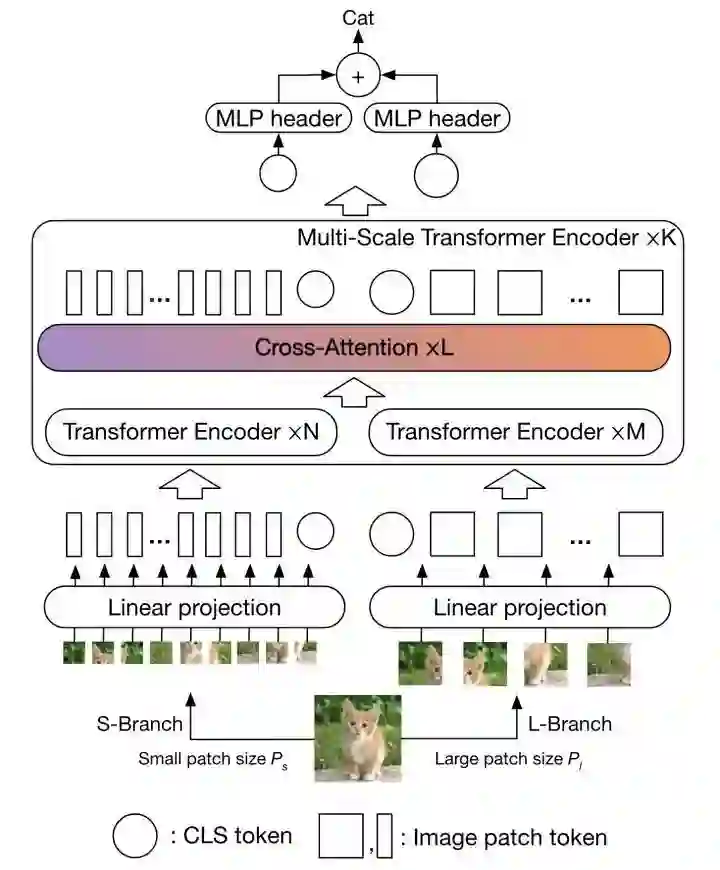
将两种不同数量的patch序列分别送入encoder中,然后通过cross-attention对两个分支的cls token和patch token同时进行融合,最后将两个分支的cls token位置的输出结果进行融合。
AutoFormer
paper:https://arxiv.org/pdf/2107.00651.pdf
code:https://github.com/microsoft/AutoML
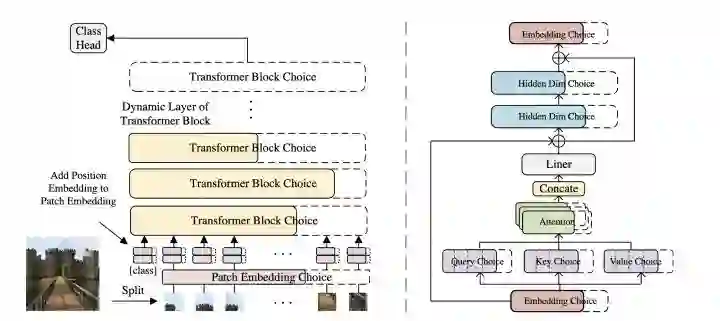
AutoFormer动态的搜索transformer中每一层的embedding纬度、head的数量、MLP比例和QKV纬度。
*CPVT
paper:https://arxiv.org/abs/2102.10882
code:https://github.com/Meituan-AutoML/CPVT
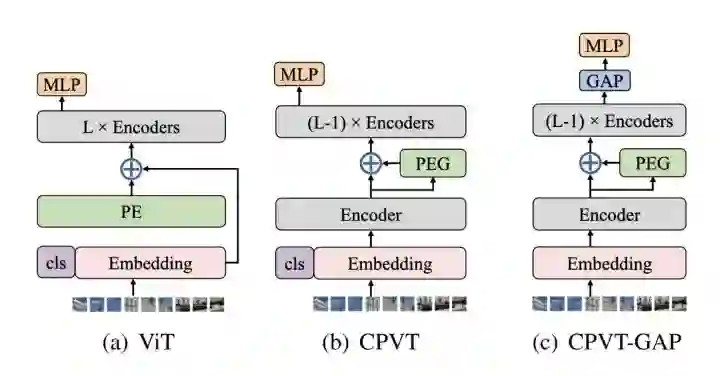
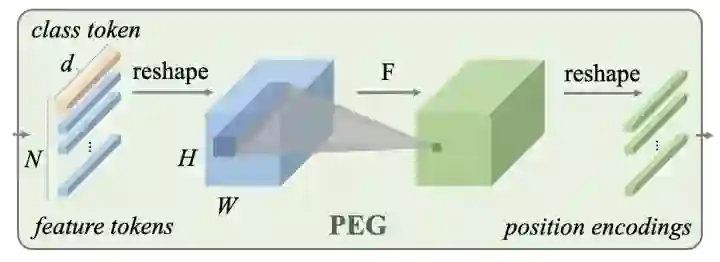
CPVT设计了一个PEG结构来替代PE(positional encoding),PEG通过feature token生成得到。
V-MoE
paper:https://arxiv.org/pdf/2106.05974v1.pdf
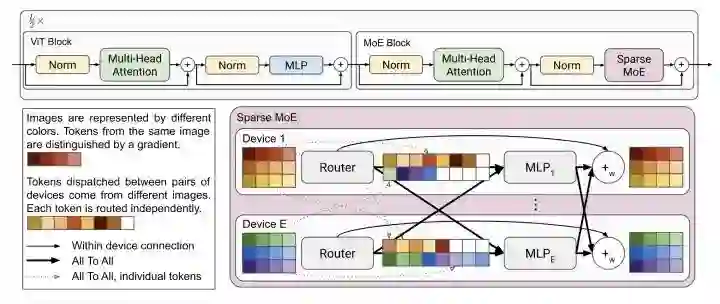
V-MoE用Sparse MoE来替换ViT中的MLP结构。Sparse MoE中的每个MLP分别保存在独立的device上,并且处理相同固定数量的tokens。
DPT
paper:https://arxiv.org/abs/2107.14467
code:https://github.com/CASIA-IVA-Lab/DPT
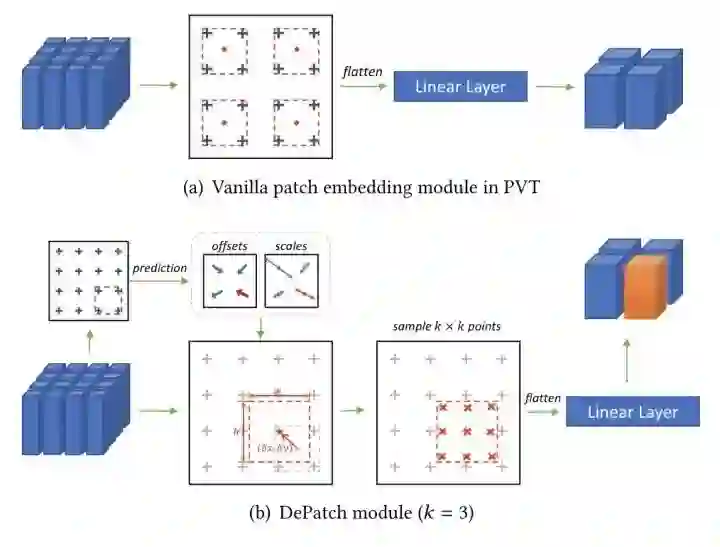
DPT设计另一个可形变的patch选取方式。
*EViT
paper:https://arxiv.org/pdf/2202.07800.pdf
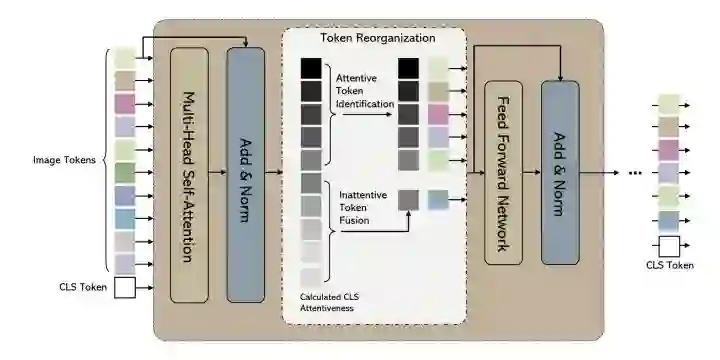
EViT通过计算每个patch token和cls token的相关性来决定重要程度,重要程度高的直接送入FFN,重要程度低的融合成一个token。
Multi-scale
*SwinTv1
paper:https://arxiv.org/abs/2103.14030
code:https://github.com/microsoft/Swin-Transformer
*SwinTv2
paper:https://arxiv.org/abs/2111.09883
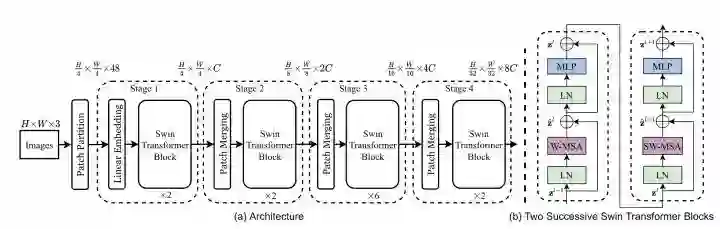
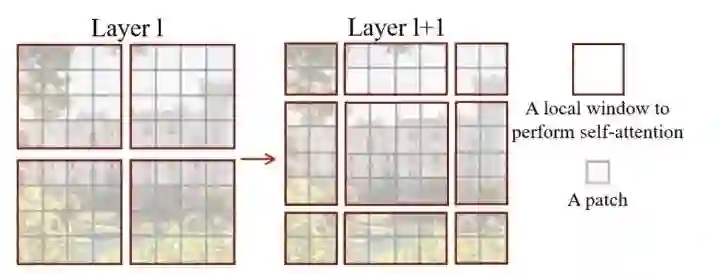
为了更好的应用于det、seg等下游任务,需要对ViT进行多尺度设计。SwinT通过patch merging减少token的数量,另外设计了W-MSA结构,只对windows内的patch进行self-attention计算来降低计算量,为了增加不同windows之间的信息传递,设计了SW-MSA结构。
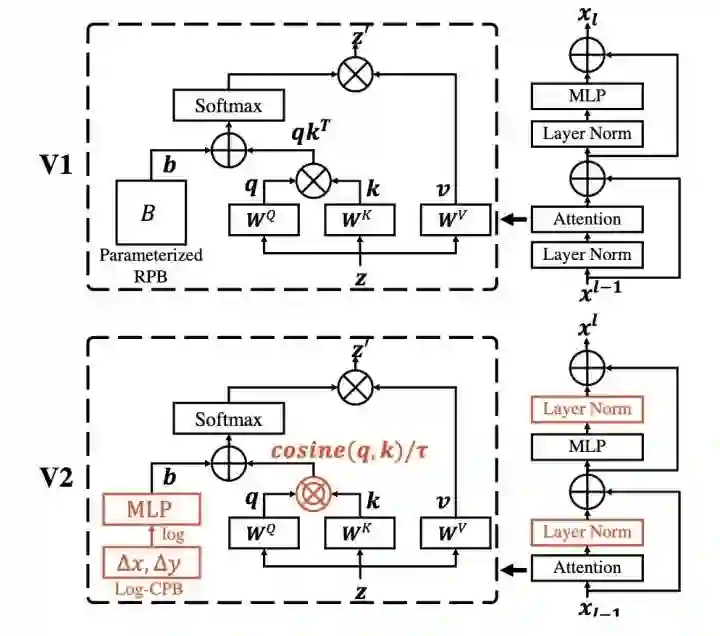
为了更好的扩大SwinT的模型容量和window的分辨率,SwinTv2重新设计了block结构。
-
用post-norm替代pre-norm -
用cosine attention替代dot product attention -
用log-spaced continuous relative position替代parameterized relative position
1和2使得SwinT更容易扩大模型容量,3使得SwinT更容易跨window分辨率迁移。
*PVTv1
paper:https://arxiv.org/abs/2102.12122
code:https://github.com/whai362/PVT
*PVTv2
paper:https://arxiv.org/pdf/2106.13797.pdf
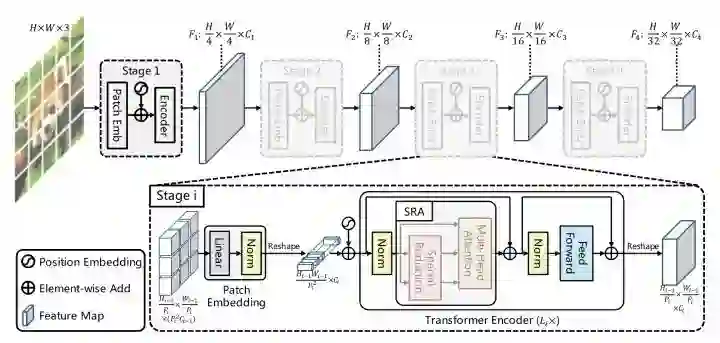
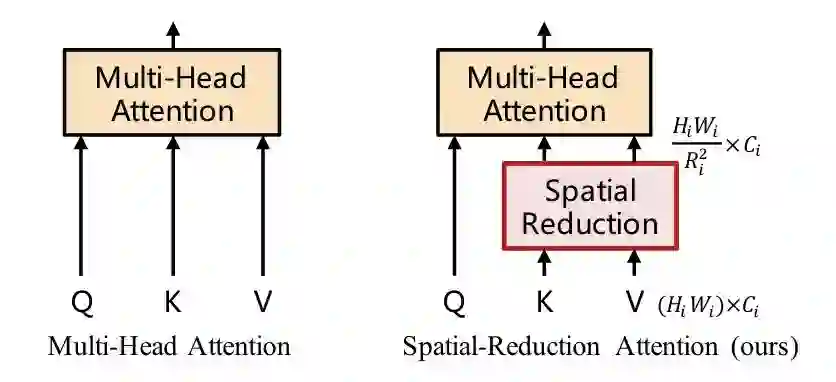
PVT设计了一个多stage的多尺度架构,为了做stage之间的下采样,将MHSA改造成SRA,SRA中的K和V都下采样R^2倍。
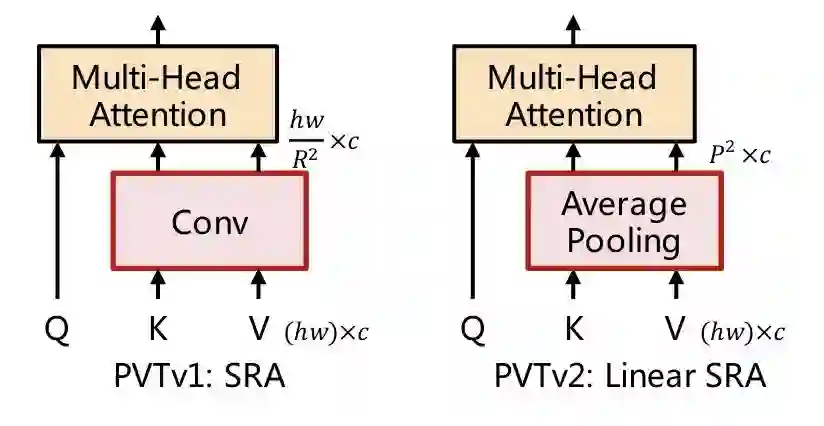
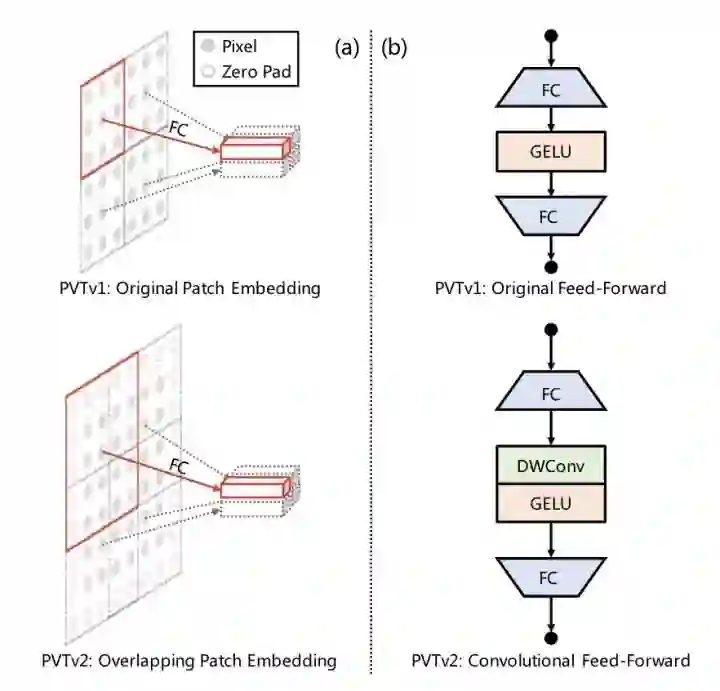
PVTv2在PVTv1的基础上做了三点改进:
-
将SRA的下采样conv替换成average pooling -
将不重叠的patch embedding替换成重叠的patch embedding -
移除position encoding,并且在FFN中增加一个dwconv
1可以将PVT计算量降到线性,2可以获得更多局部连续的特征,3可以处理任意尺寸的图像。
*Twins
paper:https://arxiv.org/abs/2104.13840
code:https://github.com/Meituan-AutoML/Twins
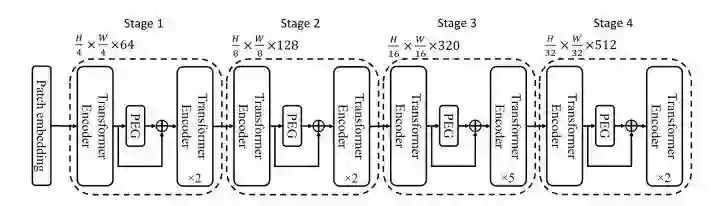
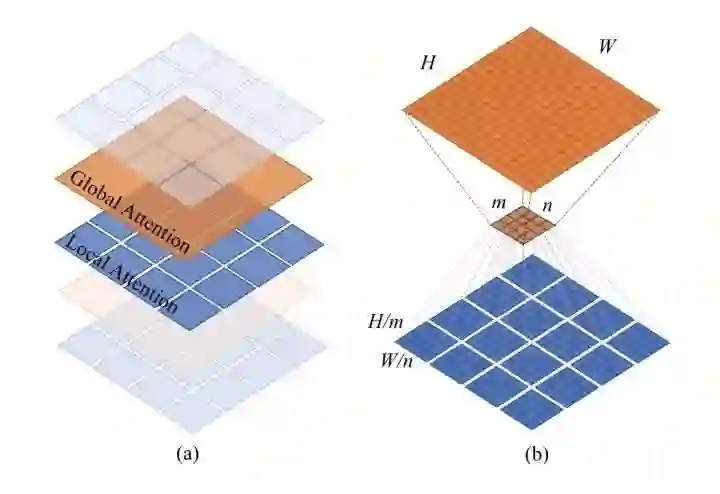
Twins沿用PVT的整体架构,并且用CPVT中的PEG来替代PE,同时将transformer block堆叠设计成global attention和local attention交替使用的形式,并且为了减少计算量,global attention将重要信息总结成mxn个表示,同时每个表示和其他sub-windows进行信息交流。
CoaT
paper:https://arxiv.org/abs/2104.06399
code:https://github.com/mlpc-ucsd/CoaT
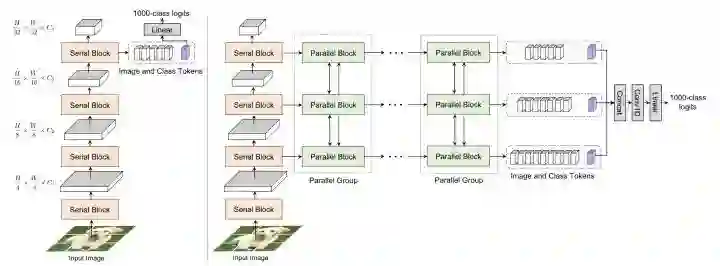
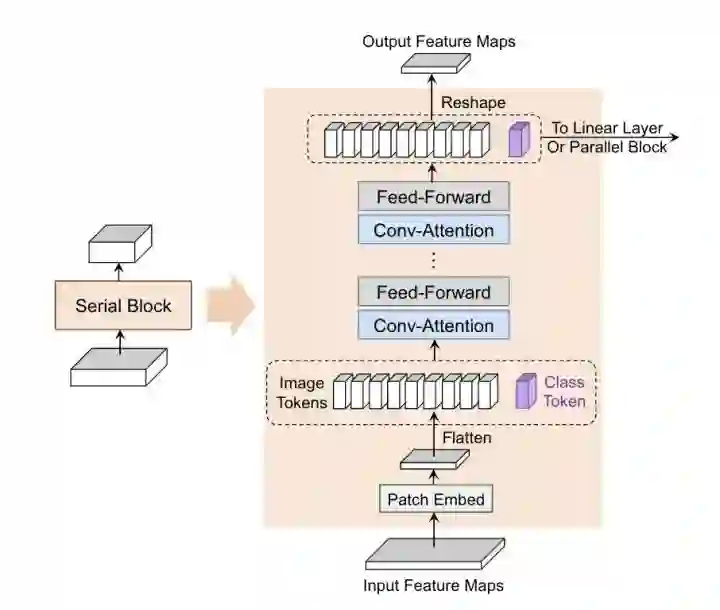
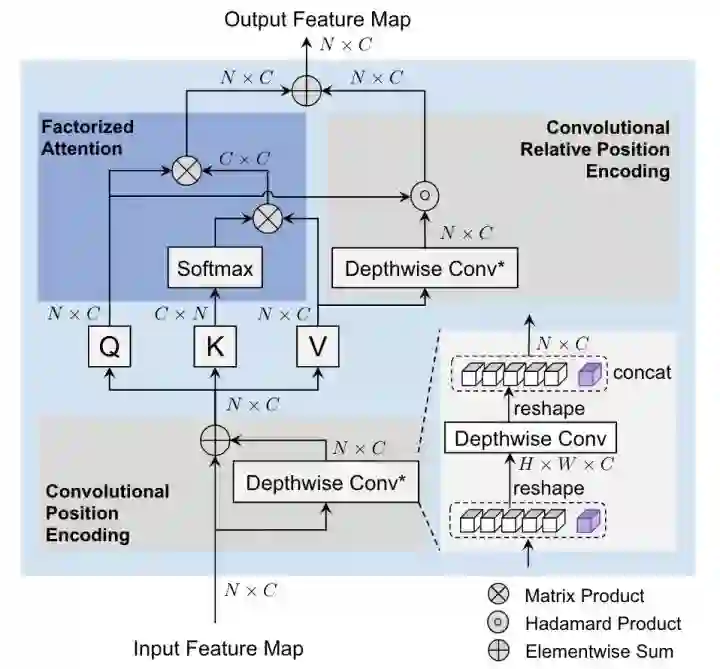
CoaT设计了一个co-scale机制,通过一系列串行和并行的block来预测结果,同时设计了一个Conv-Attention结构来替代MHSA,用一个dwconv来得到position encoding,另一个dwconv来得到relative position encoding。
CvT
paper:https://arxiv.org/abs/2103.15808
code:https://github.com/leoxiaobin/CvT
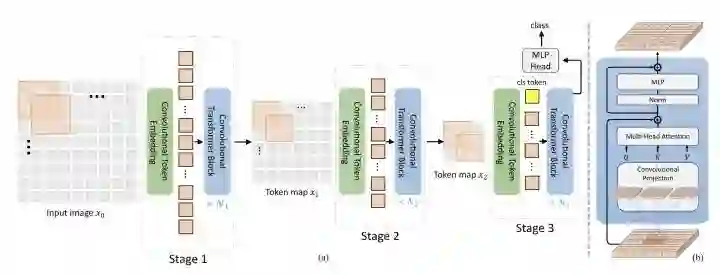
CvT去掉position encoding,用conv同时替换掉token embedding和MHSA中的QKV projection,通过conv来引入位置信息。
Shuffle Transformer
paper:https://arxiv.org/abs/2106.03650
code:https://github.com/mulinmeng/Shuffle-Transformer
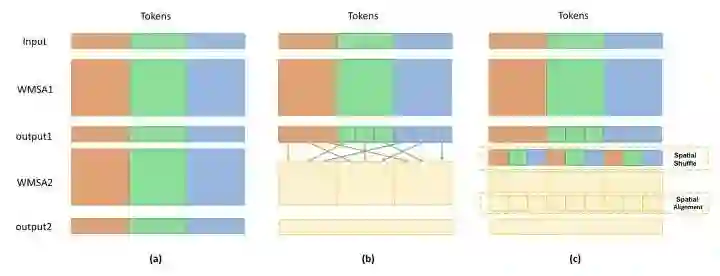
通过shuffle和unshuffle操作,来增加token之间的信息交流。
Focal Transformer
paper:https://arxiv.org/abs/2107.00641
code:https://github.com/microsoft/Focal-Transformer
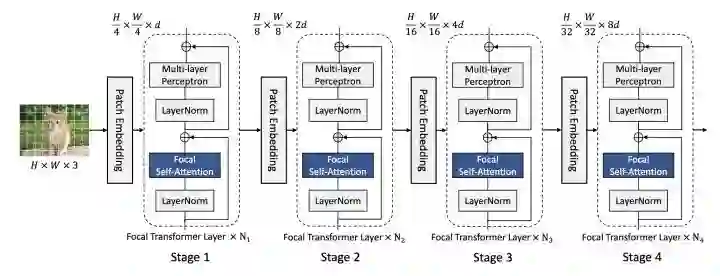

改变SwinT的划分windows的方式,每个query patch对应三种粒度的windows尺寸,如图所示。将W-MSA替换成Focal Self-Attention整体架构和SwinT保持一致。
CSWinT
paper:https://arxiv.org/abs/2107.00652
code:https://github.com/microsoft/CSWin-Transformer
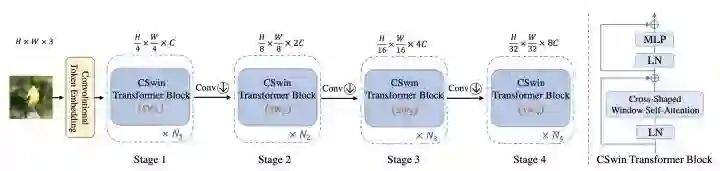
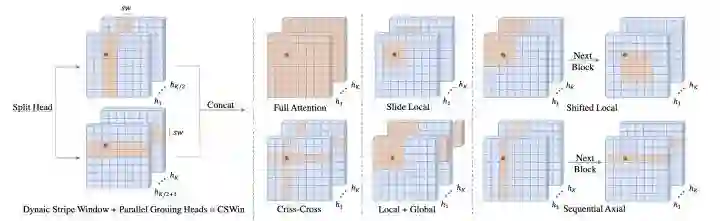
改变SwinT的划分windows的方式,每个query patch通过两个并行分支做self-attention,并且kv从dynaic stripe window中取。
*MViT
paper:https://arxiv.org/abs/2104.11227
code:https://github.com/facebookresearch/SlowFast
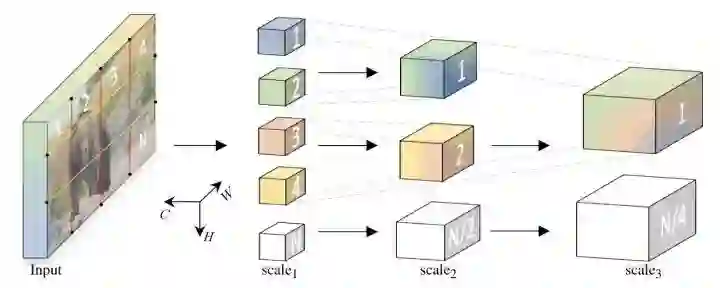
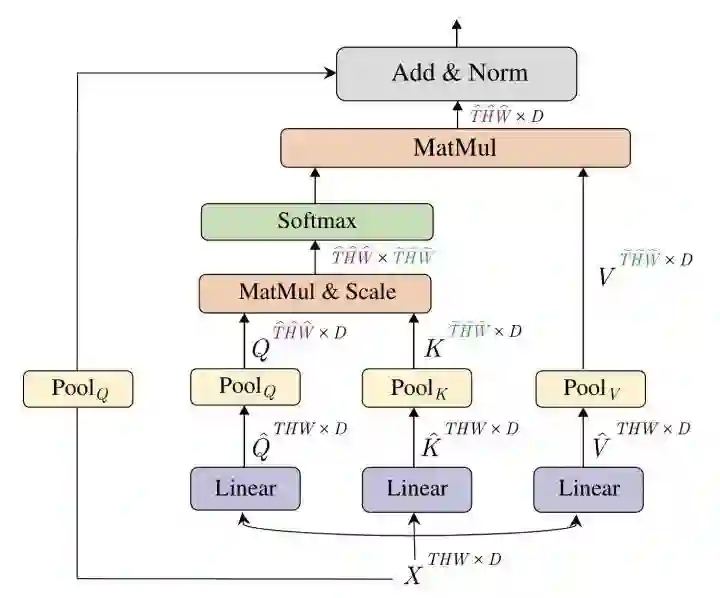
MViT通过对XQKV池化进行下采样构建金字塔架构。
Hybrid ViTs with Convolutions
LeViT
paper:https://arxiv.org/abs/2104.01136
code:https://github.com/facebookresearch/LeViT
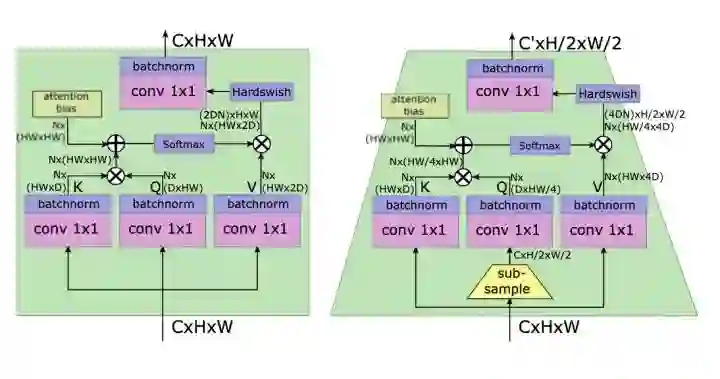
LeViT的patch embedding设计成4个conv3x3堆叠,同时下采样的self-attention对Q进行下采样。
localViT
paper:https://arxiv.org/abs/2104.05707
code:https://github.com/ofsoundof/LocalViT
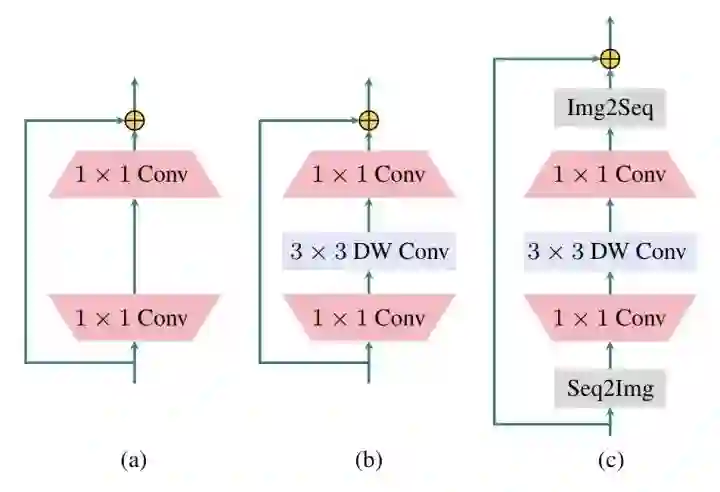
FC和1x1conv等效,在FFN中增加一个3x3的DWConv就变成了图c,输入输出增加Img2Seq和Seq2Img的操作。
ResT
paper:https://arxiv.org/abs/2105.13677
code:https://github.com/wofmanaf/ResT
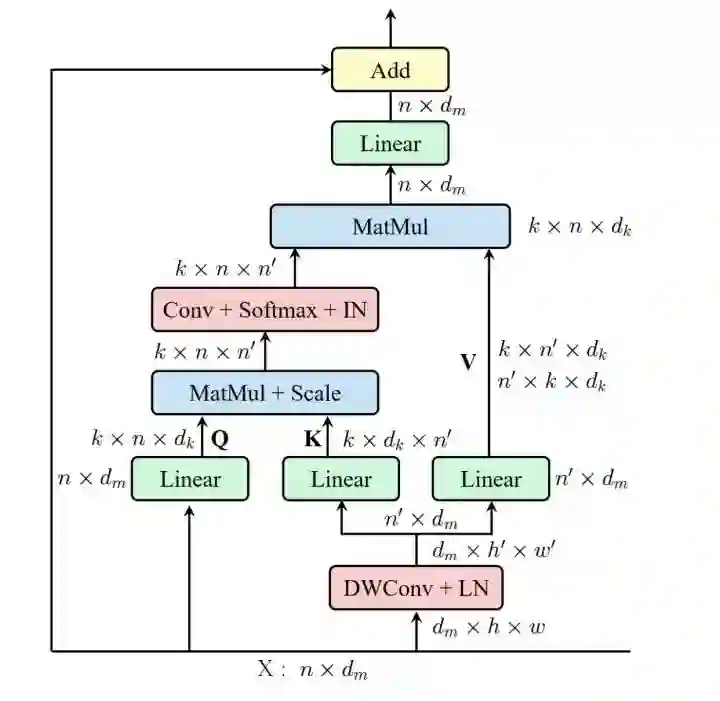
ResT在MHSA中增加DWConv降低KV的纬度,另一个conv用来增加不同head的信息交流。
NesT
paper:https://arxiv.org/abs/2105.12723

NesT通过最大池化对patch进行聚合。
CoAtNet
paper:https://arxiv.org/pdf/2106.04803.pdf
通过交替堆叠depthwise conv和self-attention来设计架构。
BoTNet
paper:https://arxiv.org/abs/2101.11605
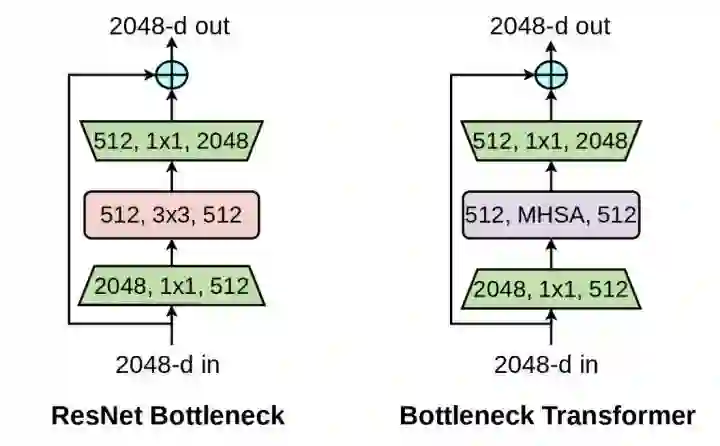
模仿ResNet的bottleneck,将Transformer的block设计成bottleneck的形式,一个bottleneck由1x1conv、MHSA、1x1conv堆叠而成。
ConViT
paper:https://arxiv.org/abs/2103.10697
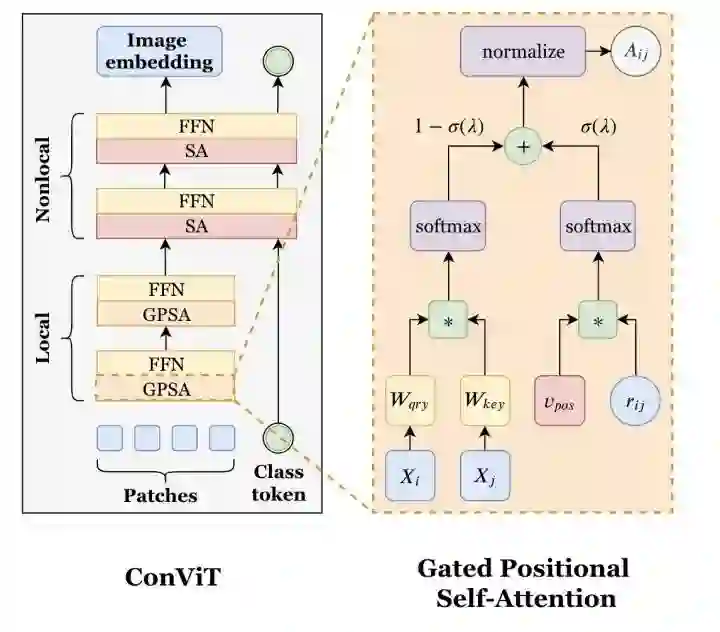
ConViT设计了一个GPSA,只对patch token进行操作,并且引入了位置信息。10个GPSA堆叠之后接2个SA。
MobileViT
paper:https://arxiv.org/abs/2110.02178
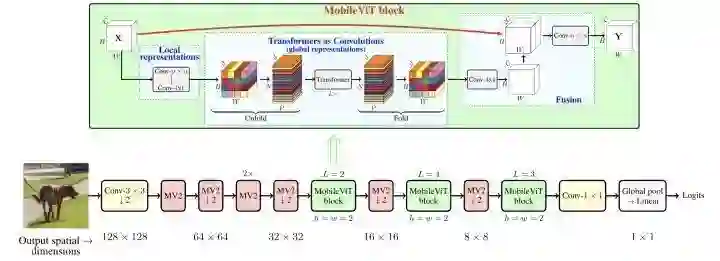
MobileViT通过堆叠MobileNetv2 block和MobileViT block构成。
CeiT
paper:https://arxiv.org/abs/2103.11816
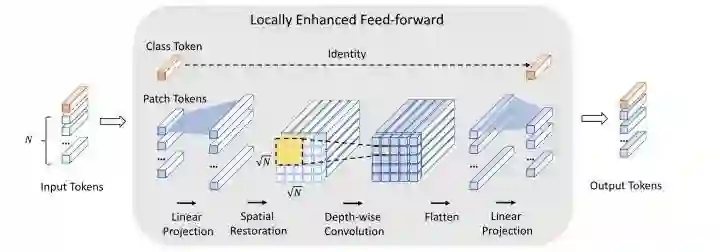
CeiT设计了一个局部增强的LeFF结构,只对patch token部分做linear projection和depth-wise conv。
CMT
paper:https://arxiv.org/abs/2107.06263
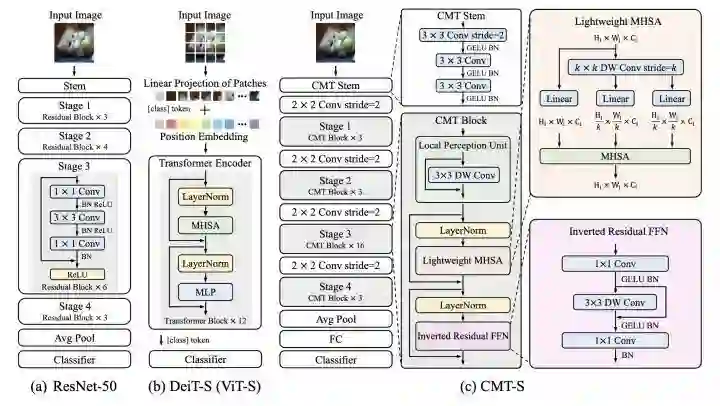
CMT设计了一个CMT block,如图所示。
Object Detection
CNN backbone
*DETR
paper:https://arxiv.org/abs/2005.12872
code:https://github.com/facebookresearch/detr
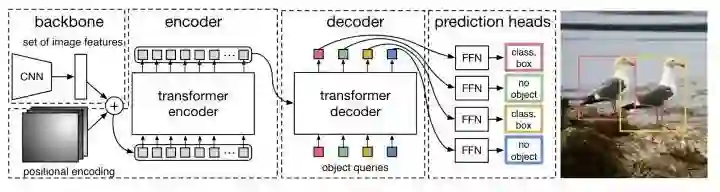
DETR是第一个使用Transformer做目标检测的算法。图片先通过CNN提取特征,然后和positional encoding相加送入transformer,最后通过FFN预测结果。其中decoder部分需要设置object queries,并行输出预测结果,训练的时候pred和target通过双边匹配算法进行匹配。
*UP-DETR
paper:https://arxiv.org/abs/2011.09094
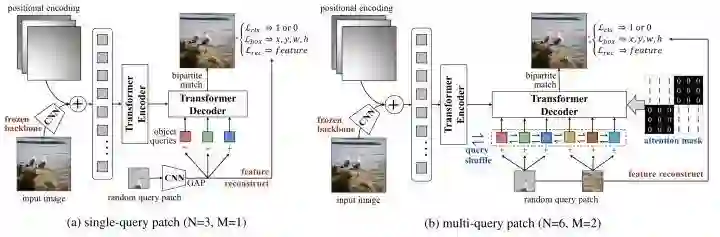
为了对DETR进行预训练,UP-DETR处理了两个关键问题:
-
为了进行分类和定位对多任务训练,UP-DETR固定住预训练过的backbone和对patch特征进行重建来保留transformer的判别力。 -
为了对多个patch进行定位,不同queries设置不同的区域和大小。UP-DETR设计了两种预训练方式,一种是single-query,另一种是multi-query。对于multi-query设计了object query shuffle和attention mask操作来解决query patches和object queries对齐问题。
DETReg
paper:https://arxiv.org/abs/2106.04550
code:https://amirbar.net/detreg
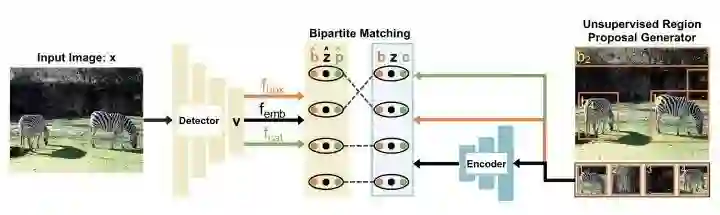
上图是DETReg的整体框架。给定一张图片x,使用DETR得到embeddings v,总共设计了三个分支,一个分支预测box,一个分支预测embdding,还有一个分支预测目标分数cat。伪gt区域提议label通过selective search得到,伪gt目标embedding通过自监督算法SwAV得到,proposal的目标分数都设置为1。通过双边匹配将预测proposal和伪label进行匹配,不匹配的预测proposal分数用0填充。
SMCA
paper:https://arxiv.org/abs/2101.07448
code:https://github.com/abc403/SMCA-replication
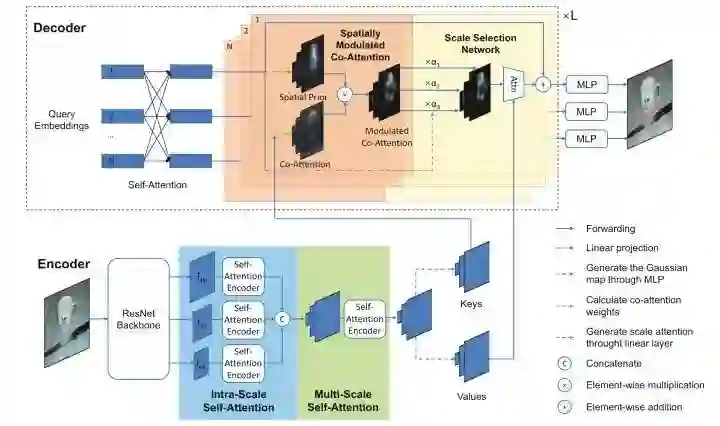
SMCA设计了一个Spatially Modulated Co-Attention组件来加快DETR的收敛速度,具体地,decoder的每个query先做一个spatial prior,然后和key进行co-attention。另外SMCA还设计来一个Multi-Scale Self-Attention来进一步提升精度。
*Deformable DETR
paper:https://arxiv.org/abs/2010.04159
code:https://github.com/fundamentalvision/Deformable-DETR
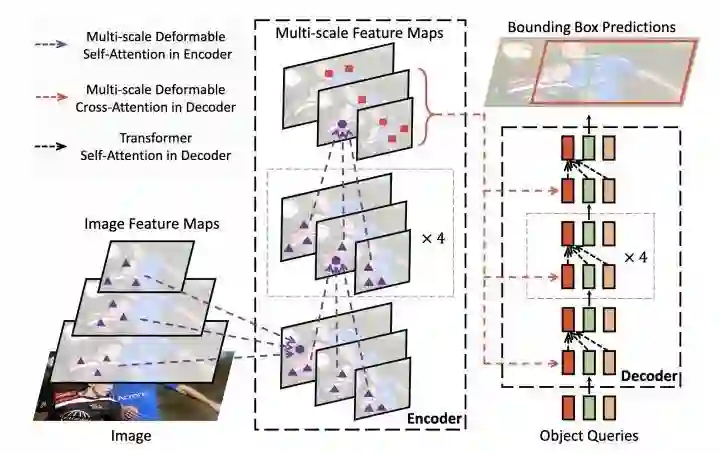
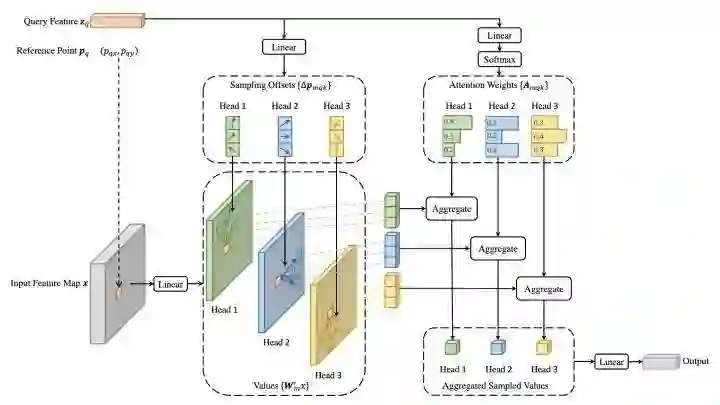
Deformable DETR结合了deformable conv的稀疏空间采样和transformer的相关性建模能力的优点。提出的deformable attention module用一些采样位置作为重要的key元素,并且Deformable DETR将该谋爱拓展到multi-scale上。
Anchor DETR
paper:https://arxiv.org/abs/2109.07107
code:https://github.com/megvii-model/AnchorDETR
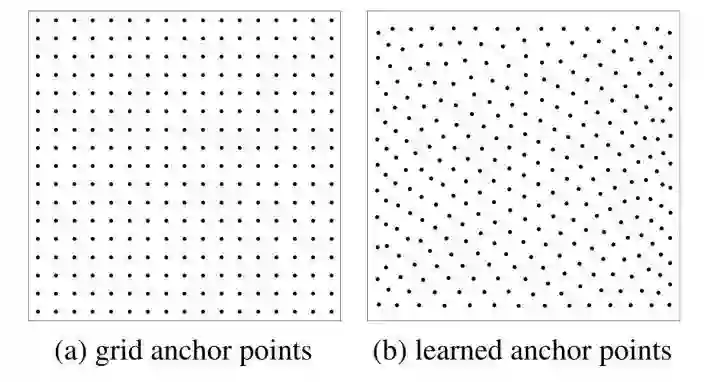
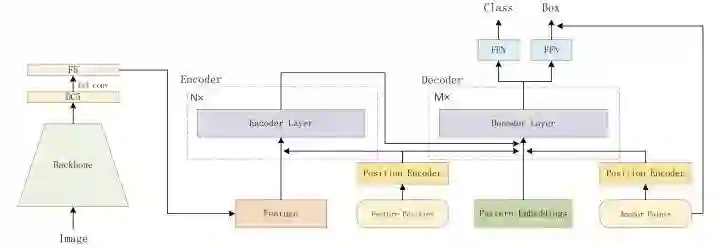
Anchor DETR在decoder部分设计了基于anchor points的object queries,并且row-column decoupled attention来替代MHSA,降低计算复杂度。
*Conditional DETR
paper:https://arxiv.org/abs/2108.06152
code:https://github.com/Atten4Vis/ConditionalDETR
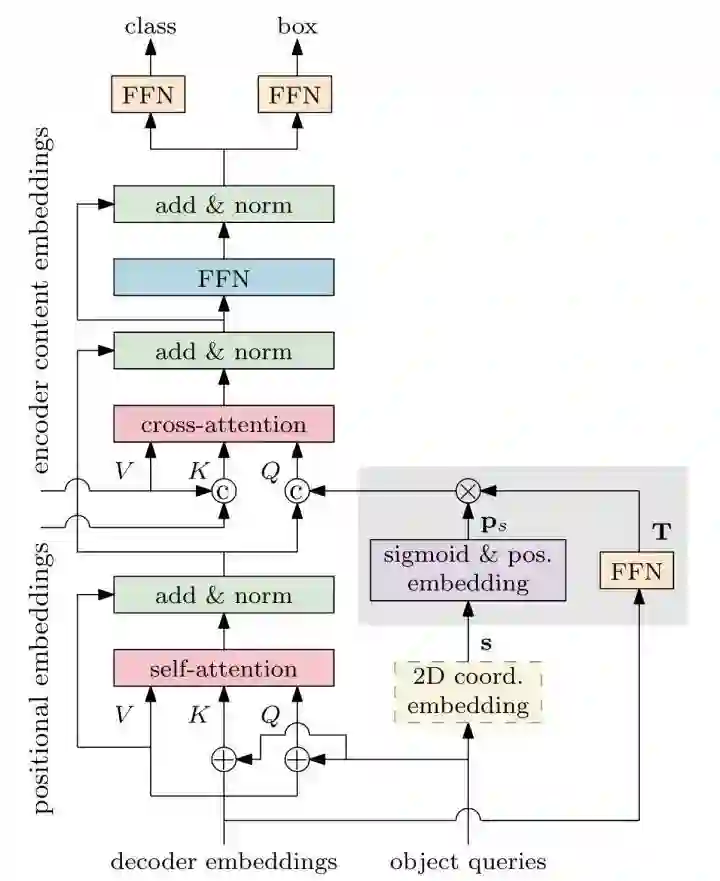
Conditional DETR将content queries和spatial queries独立开,使得各自关注于content attention weights和spatial attention weights,加快训练的收敛速度。
*TSP-FCOS
paper:https://arxiv.org/abs/2011.10881
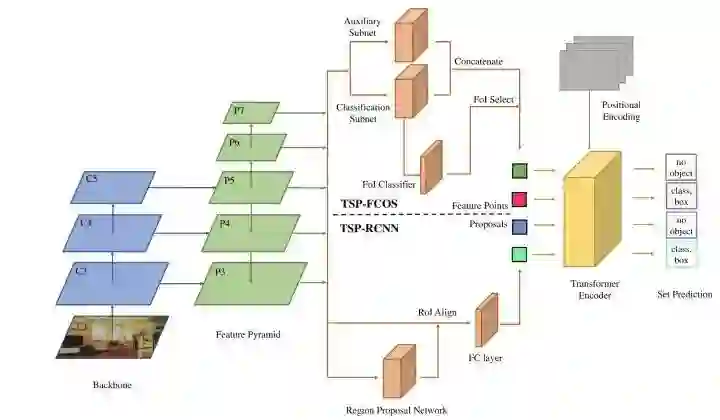
本文实验观察发现,影响DETR收敛速度的主要原因是cross-attention和双边匹配的不稳定。于是本文提出只使用transformer的encoder,其中TSP-FCOS设计了一种FoI Select来选择特征。并且还设计来一种新的双边匹配算法来加快收敛。
PnP-DETR
paper:https://arxiv.org/abs/2109.07036
code:https://github.com/twangnh/pnp-detr
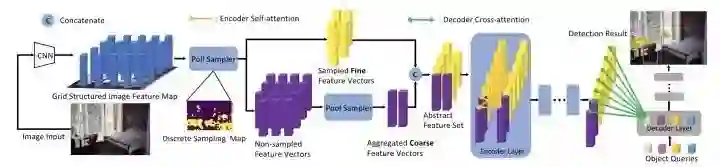
PnP-DETR设计了两种采样方式来降低计算复杂度,poll sampler和pool sampler,poll sampler对feature map对每个位置预测分数,然后挑选出fine的特征,通过pool sampler对coarse特征进行聚合。
D^2ETR
paper:https://arxiv.org/pdf/2203.00860.pdf
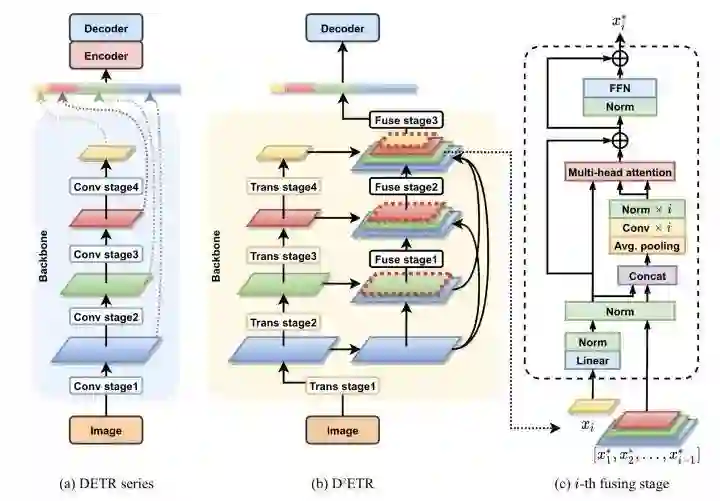
D^2ETR去掉了DETR的encoder部分,同时在backbone部分对不同stage的特征进行融合操作。
Sparse DETR
paper:https://arxiv.org/abs/2111.14330
code:https://github.com/kakaobrain/sparse-detr
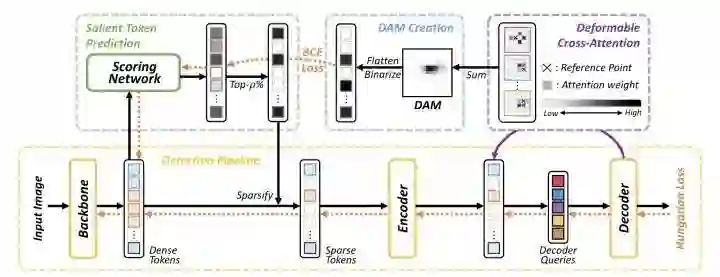
Sparse DETR通过Deformable cross-attention得到binarized decoder cross-attention map(DAM),用来作为scoring network的监督信号,预测出token的重要程度,并且只保留top-p%的token进行训练。
*Efficient DETR
paper:https://arxiv.org/pdf/2104.01318.pdf
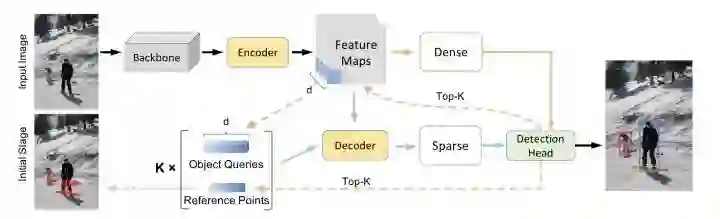
Efficient DETR通过预测结果来初始化object queries,具体地,选取top-K个位置的feature当作object queries,位置当作reference points,k组embedding送入decoder进行稀疏预测,最终Efficient DETR只需要一个decoder就能超过DETR 6个decoder的精度。
Dynamic DETR
paper:https://openaccess.thecvf.com/content/ICCV2021/papers/Dai_Dynamic_DETR_End-to-End_Object_Detection_With_Dynamic_Attention_ICCV_2021_paper.pdf
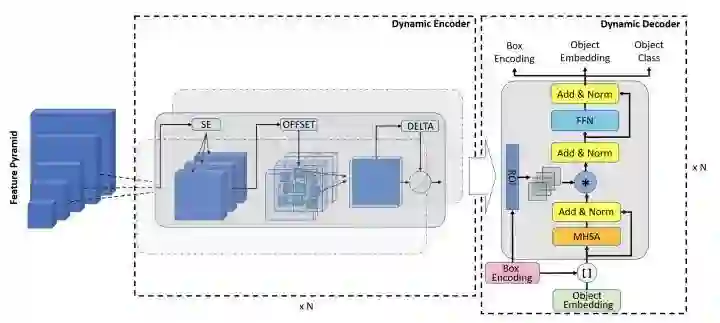
Dynamic DETR的dynamic encoder部分引入SE然后用deformable self-attention来提取多尺度特征,dynamic decoder部分引入可学习的box encoding,然后对encoder的特征做roi池化,最后和decoder的中间层embedding做相乘。
*DAB-DETR
paper:https://arxiv.org/abs/2201.12329 code](https://github.com/SlongLiu/DAB-DETR
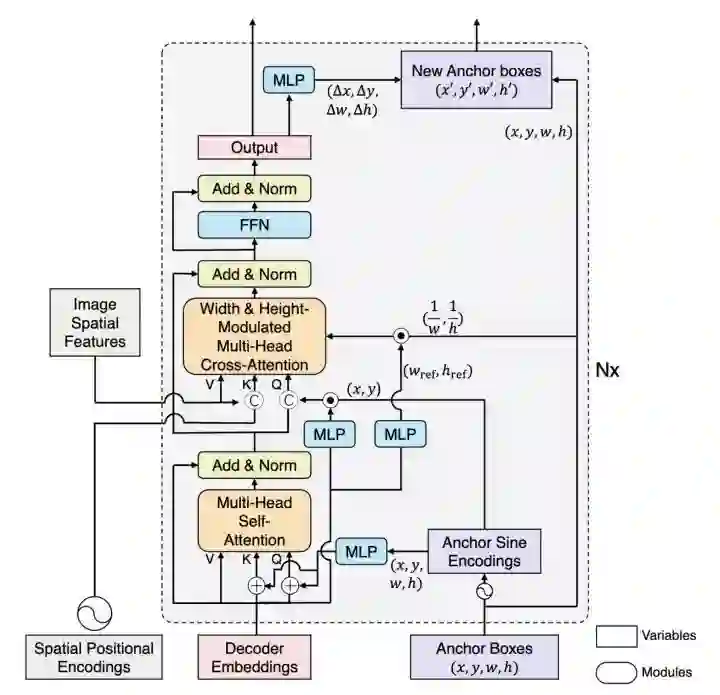
DAB-DETR直接动态更新anchor boxes提供参照点和参照anchor尺寸来改善cross-attention的计算。
*DN-DETR
paper:https://arxiv.org/abs/2203.01305
code:https://github.com/FengLi-ust/DN-DETR
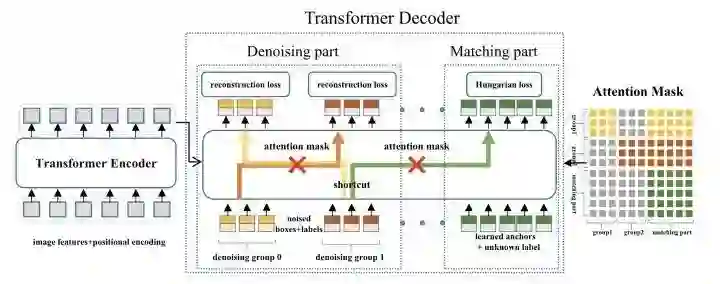
DN-DETR在DAB-DETR的基础上,增加来一个denoising辅助任务,从而避免训练前期双边匹配的不稳定,加快收敛速度。
*DINO
paper:https://arxiv.org/pdf/2203.03605.pdf
code:https://github.com/twangnh/pnp-detr
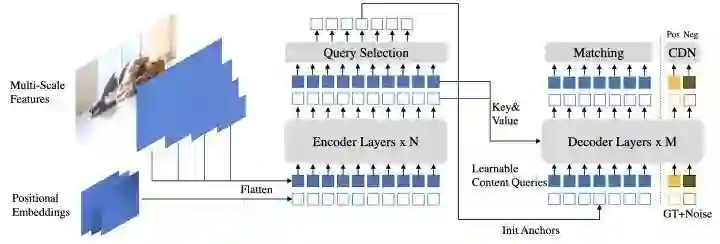
DINO在DN-DETR的基础上引入了三点改进:
-
增加了一个新的辅助任务contrastive denoising training,在相同的gt box添加两种不同的noise,noise小的当作正样本,noise大的当作负样本。 -
提出mixed query selection方法,从encoder的输出中选择初始anchor boxes作为positional queries。 -
提出look forward twice方法,利用refined box信息来帮助优化前面层的参数。
Pure Transformer
Pix2Seq
paper:https://arxiv.org/abs/2109.10852
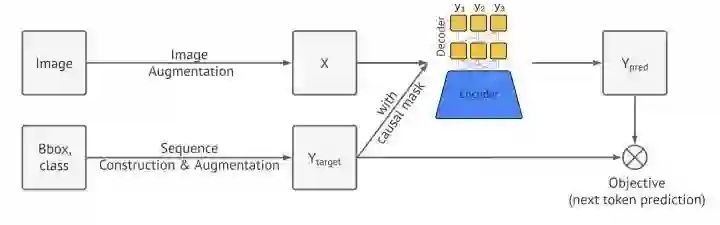
Pix2Seq直接把目标检测任务当成是序列任务,将cls和bbox构建成序列目标,图片通过Transformer直接预测序列结果。
YOLOS
paper:https://arxiv.org/abs/2106.00666
code:https://github.com/IDEACVR/DINO
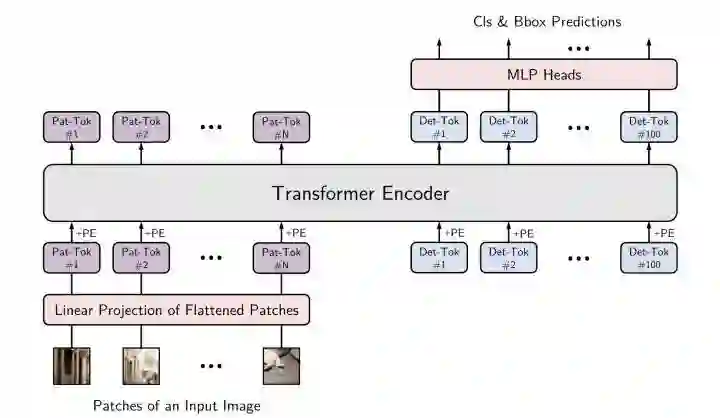
YOLOS只使用transformer encoder做目标检测,模仿vit在encoder部分设置det token,在输出部分接MLP预测出cls和bbox。
FP-DETR
paper:https://openreview.net/pdf%3Fid%3DyjMQuLLcGWK
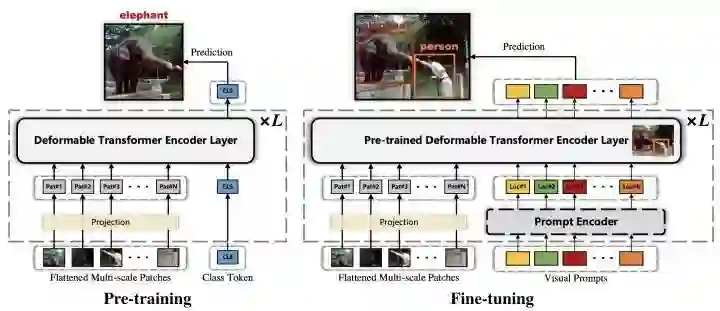
FP-DETR只使用transformer encoder部分,先使用cls token来做pre-training,然后替换成visual prompts来做fine-tuning。其中visual prompts由query content embedding和query positional embedding相加得到。
Instance segmentation
SOTR
paper:https://arxiv.org/abs/2108.06747
code:https://github.com/easton-cau/SOTR
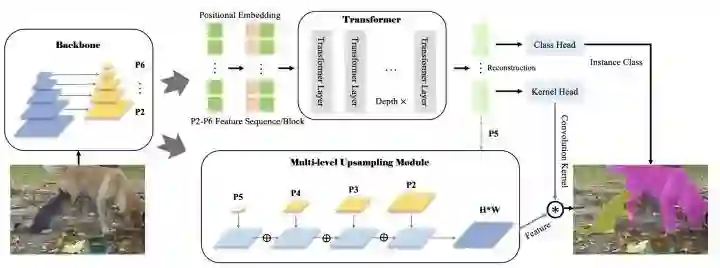
SOTR在FPN backbone的基础上最小修改构建的。将多尺度的feature map加上positional embedding送入transformer模型中,通过cls head和kernel head预测出instance cls和dynamic conv,另一个分支对多尺度特征进行上采样融合得到,最后和dynamic conv想乘得到不同instance cls的区域。
panoptic segmentation
Max-DeepLab
paper:https://arxiv.org/pdf/2012.00759.pdf
code:https://github.com/google-research/deeplab2
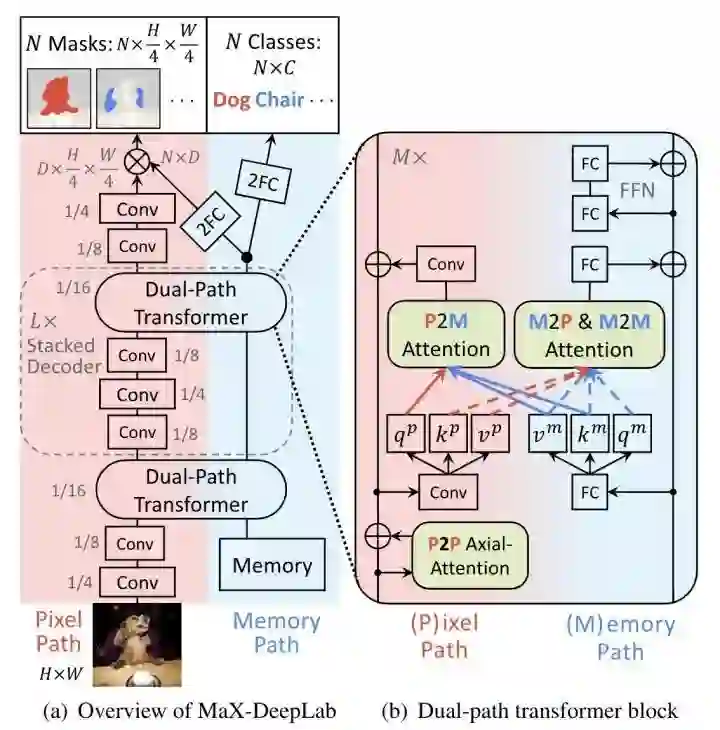
Max-DeepLab设计了两个分支pixel path和memory path,两个分支在dual-path tansformer中进行交互,最终pixel path预测出mask,memory path预测出cls。
MaskFormer
paper:https://link.zhihu.com/?target=http%3A//arxiv.org/abs/2107.06278
code:https://github.com/facebookresearch/MaskFormer
Mask2Former
paper:https://arxiv.org/abs/2112.01527
code:https://github.com/facebookresearch/Mask2Former
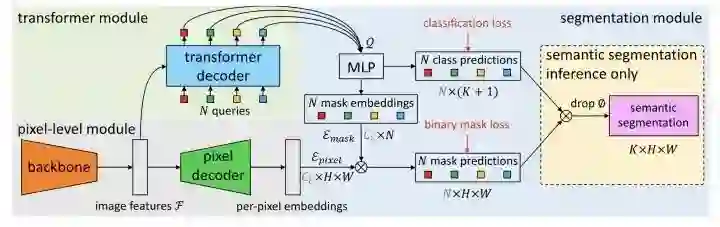
MaskFormer提出将全景分割看成是mask分类任务。通过transformer decoder和MLP得到N个mask embedding和N个cls pred。另一个分支通过pixel decoder得到per-pixel embedding,然后将mask embedding和per-pixel embedding相乘得到N个mask prediction,最后cls pred和mask pred相乘,丢弃没有目标的mask,得到最终预测结果。
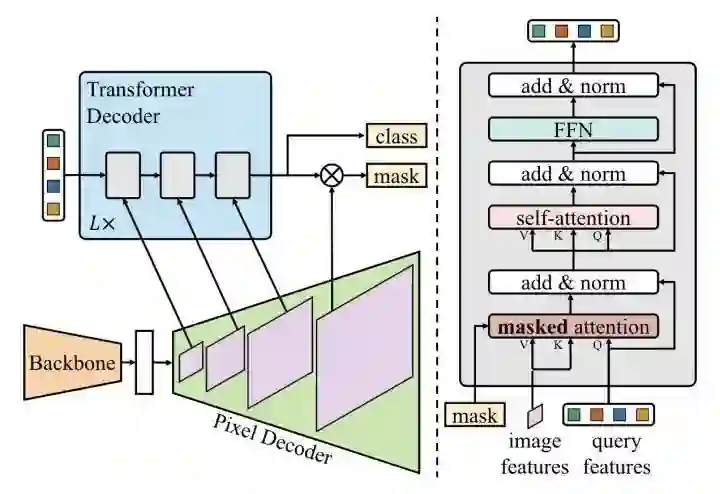
Mask2Former在MaskFormer的基础上,增加了masked attention机制,另外还调整了decoder部分的self-attention和cross-attention的顺序,还提出了使用importance sampling来加快训练速度。
Image Segmentation
semantic segmentation
SETR
paper:https://arxiv.org/abs/2012.15840
code:https://fudan-zvg.github.io/SETR/
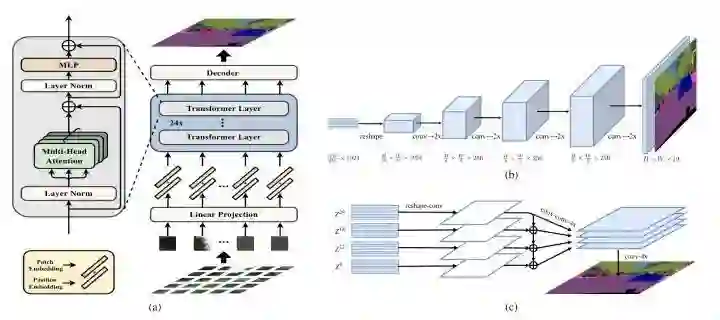
SETR用ViT/DeiT作为backbone,然后设计了两种head形式:SETR-PUP和SETR-MLA。PUP将backbone输出的feature reshape成二维形式,然后不断的上采样得到最终的预测结果;MLA将多个stage的中间feature进行reshape,然后融合上采样得到最终的预测结果。
SegFormer
paper:https://arxiv.org/abs/2105.15203
code:https://github.com/NVlabs/SegFormer
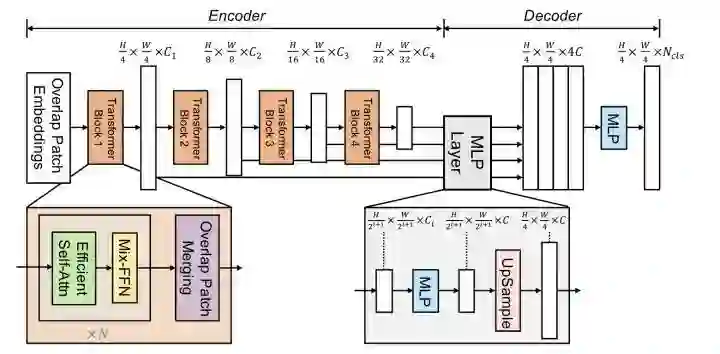
SegFormer设计了一个encoder-decoder的分割框架,其中transformer block由Efficient Self-Attn、Mix-FFN、Overlap Patch Merging构成。Efficient Self-Attn对K进行下采样,Mix-FFN额外使用了conv。
Segmenter
paper:https://arxiv.org/abs/2105.05633
code:https://github.com/rstrudel/segmenter
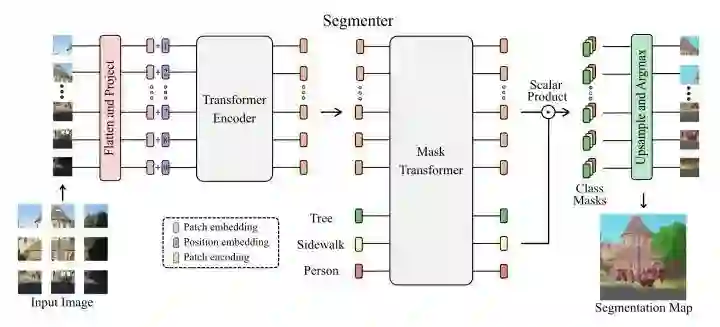
Segmenter设计了类别无关的cls token,最后预测的时候分别和patch token进行点乘,最后reshap成二维图像。
U-Net Transformer
paper:https://arxiv.org/abs/2103.06104
TransUNet
paper:https://arxiv.org/abs/2102.04306
code:https://github.com/Beckschen/TransUNet
Swin-Unet
paper:https://arxiv.org/abs/2105.05537
code:https://github.com/HuCaoFighting/Swin-Unet
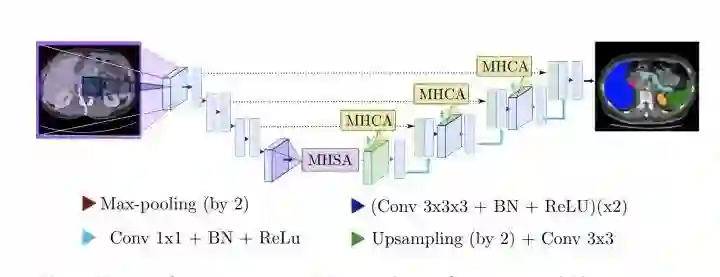
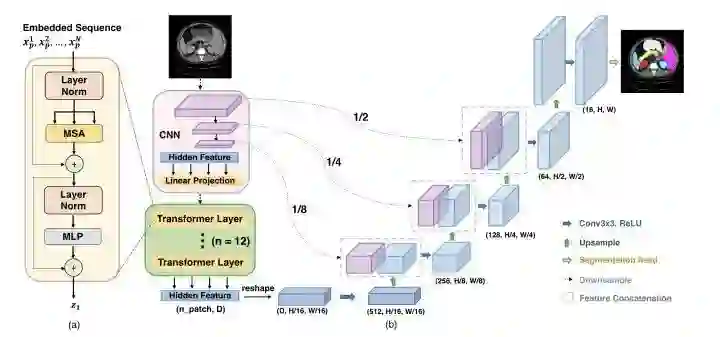
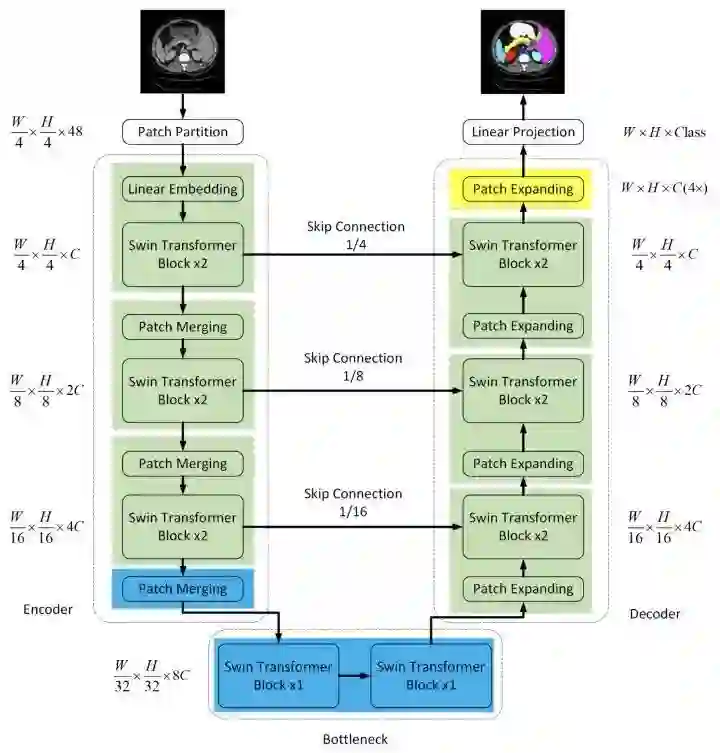
在U-Net结构中引入Transformer
P2T
paper:https://arxiv.org/abs/2106.12011
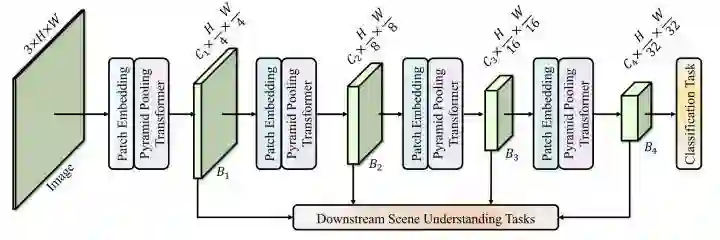
用对KV做池化的MHSA做下采样。
HRFormer
paper:https://papers.nips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html
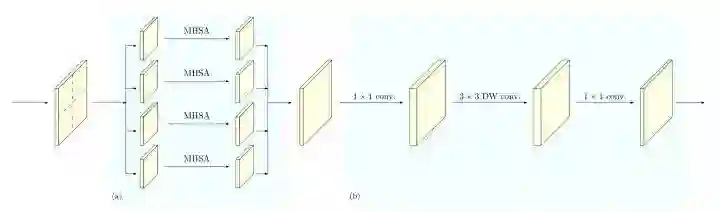
HRFormer的block由local-window self-attention和FFN组成。
公众号后台回复“数据集”获取火焰和烟雾图像数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~





