浅谈Transformer+CNN混合架构:CMT以及从0-1复现

极市导读
本文详细讲解了华为诺亚与悉尼大学在Transformer+CNN架构混合方面的尝试,一种同时具有Transformer长距离建模与CNN局部特征提取能力的CMT。并给出了自己从0-1的复现过程以及是实验结果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
论文链接: https://arxiv.org/abs/2107.06263
论文代码(个人实现版本): https://github.com/FlyEgle/CMT-pytorch
知乎专栏:https://www.zhihu.com/people/flyegle
写在前面
本篇博客讲解CMT模型并给出从0-1复现的过程以及实验结果,由于论文的细节并没有给出来,所以最后的复现和paper的精度有一点差异,等作者release代码后,我会详细的校对我自己的code,找找原因。
1. 出发点
-
Transformers与现有的卷积神经网络(CNN)在性能和计算成本方面仍有差距。 -
希望提出的模型不仅可以超越典型的Transformers,而且可以超越高性能卷积模型。
2. 怎么做
-
提出混合模型(串行),通过利用Transformers来捕捉长距离的依赖关系,并利用CNN来获取局部特征。 -
引入depth-wise卷积,获取局部特征的同时,减少计算量 -
使用类似R50模型结构一样的stageblock,使得模型具有下采样增强感受野和迁移dense的能力。 -
使用conv-stem来使得图像的分辨率缩放从VIT的1/16变为1/4,保留更多的patch信息。
3. 模型结构
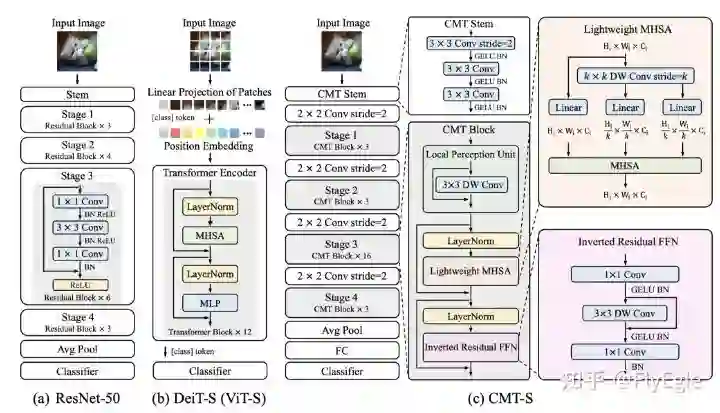
-
(a)表示的是标准的R50模型,具有4个stage,每个都会进行一次下采样。最后得到特征表达后,经过AvgPool进行分类 -
(b)表示的是标准的VIT模型,先进行patch的划分,然后embeeding后进入Transformer的block,这里,由于Transformer是long range的,所以进入什么,输出就是什么,引入了一个非image的class token来做分类。 -
(c)表示的是本文所提出的模型框架CMT,由CMT-stem, downsampling, cmt block所组成,整体结构则是类似于R50,所以可以很好的迁移到dense任务上去。
3.1. CMT Stem
使用convolution来作为transformer结构的stem,这个观点FB也有提出一篇paper,Early Convolutions Help Transformers See Better。
https://arxiv.org/abs/2106.14881
CMT&Conv stem共性
-
使用4层conv3x3+stride2 + conv1x1 stride 1 等价于VIT的patch embeeding,conv16x16 stride 16. -
使用conv stem,可以使模型得到更好的收敛,同时,可以使用SGD优化器来训练模型,对于超参数的依赖没有原始的那么敏感。好处那是大大的多啊,仅仅是改了一个conv stem。
CMT&Conv stem异性
-
本文仅仅做了一次conv3x3 stride2,实际上只有一次下采样,相比conv stem,可以保留更多的patch的信息到下层。
从时间上来说,一个20210628(conv stem), 一个是20210713(CMT stem),存在借鉴的可能性还是比较小的,也说明了conv stem的确是work。
3.2. CMT Block
每一个stage都是由CMT block所堆叠而成的,CMT block由于是transformer结构,所以没有在stage里面去设计下采样。每个CMT block都是由Local Perception Unit, Ligntweight MHSA, Inverted Residual FFN这三个模块所组成的,下面分别介绍:
-
Local Perception Unit(LPU)
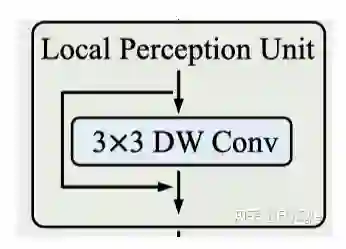
本文的一个核心点是希望模型具有long-range的能力,同时还要具有local特征的能力,所以提出了LPU这个模块,很简单,一个3X3的DWconv,来做局部特征,同时减少点计算量,为了让Transformers的模块获取的longrange的信息不缺失,这里做了一个shortcut,公式描述为:
-
Lightweight MHSA(LMHSA)
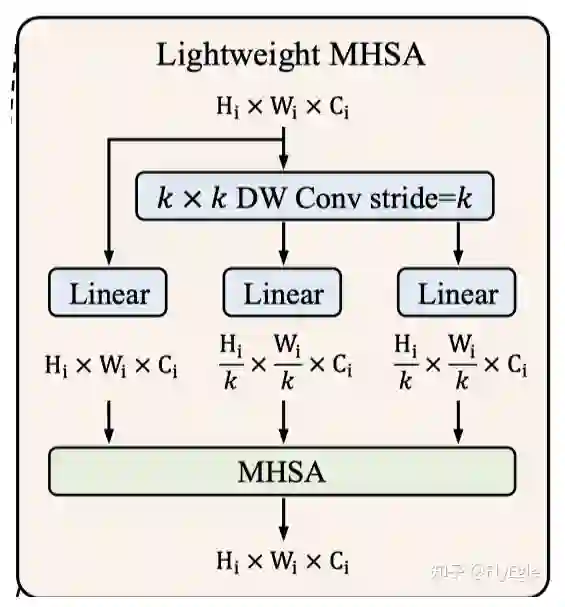
MHSA这个不用多说了,多头注意力,Lightweight这个作用,PVT 曾经有提出过,目的是为了降低复杂度,减少计算量。那本文是怎么做的呢,很简单,假设我们的输入为 , 对其分别做一个scale,使用卷积核为 ,stride为 的Depth Wise卷积来做了一次下采样,得到的shape为 ,那么对应的Q,K,V的shape分别为:
我们知道,在计算MHSA的时候要遵守两个计算原则:
-
Q, K的序列dim要一致。 -
K, V的token数量要一致。
所以,本文中的MHSA计算公式如下:
-
Inverted Resdiual FFN(IRFFN)
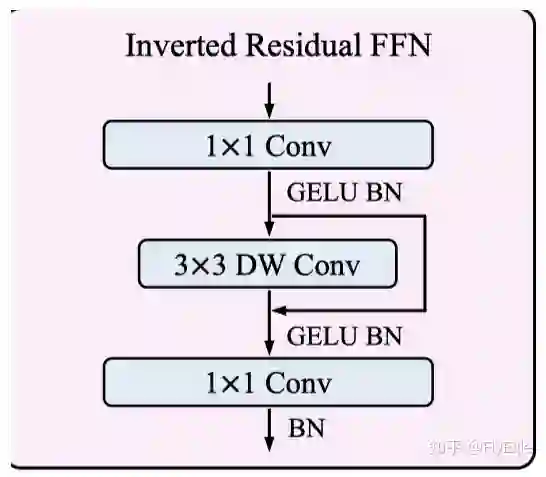
FFN的这个模块,其实和mbv2的block基本上就是一样的了,不一样的地方在于,使用的是GELU,采用的也是DW+PW来减少标准卷积的计算量。很简单,就不多说了,公式如下:
那么我们一个block里面的整体计算公式如下:
3.3 patch aggregation
每个stage都是由上述的多个CMTblock所堆叠而成, 上面也提到了,这里由于是transformer的操作,不会设计到scale尺度的问题,但是模型需要构造下采样,来实现层次结构,所以downsampling的操作单独拎了出来,每个stage之前会做一次卷积核为2x2的,stride为2的卷积操作,以达到下采样的效果。
所以,整体的模型结构就一目了然了,假设输入为224x224x3,经过CMT-STEM和第一次下采样后,得到了一个56x56的featuremap,然后进入stage1,输出不变,经过下采样后,输入为28x28,进入stage2,输出后经过下采样,输入为14x14,进入stage3,输出后经过最后的下采样,输入为7x7,进入stage4,最后输出7x7的特征图,后面接avgpool和分类,达到分类的效果。
我们接下来看一下怎么复现这篇paper。
4. 论文复现
ps: 这里的复现指的是没有源码的情况下,实现网络,训练等,如果是结果复现,会标明为复现精度。
这里存在几个问题
-
文章的问题:我看到paper的时候,是第一个版本的arxiv,大概过了一周左右V2版本放出来了,这两个版本有个很大的diff。
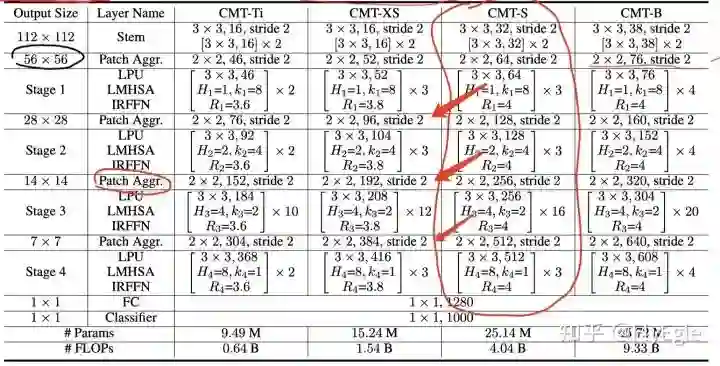
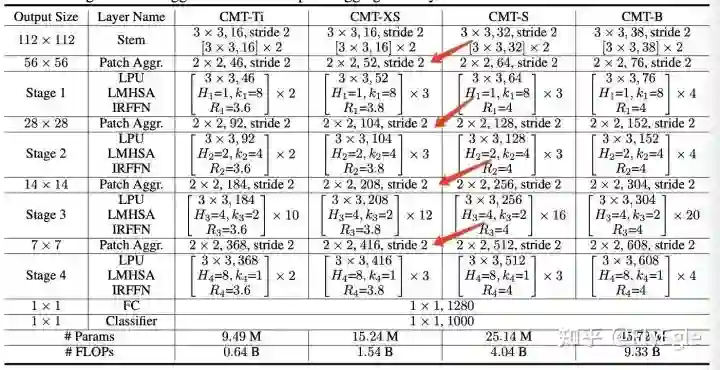
网络结构可以说完全不同的情况下,FLOPs竟然一样的,当然可能是写错了,这里就不吐槽了。不过我一开始代码复现就是按下面来的,所以对于我也没影响多少,只是体验有点差罢了。
-
细节的问题:paper和很多的transformer一样,都是采用了Deit的训练策略,但是差别在于别的paper或多或少会给出来额外的tirck,比如最后FC的dp的ratio等,或者会改变一些,再不济会把代码直接release了,所以只好闷头尝试Trick。
4.1 复现难点
paper里面采用的Position Embeeding和Swin是类似的,都是Relation Position Bias,但是和Swin不相同的是,我们的Q,K,V尺度是不一样的。这里我考虑了两种实现方法,一种是直接bicubic插值,另一种则是切片,切片更加直观且embeeding我设置的可BP,所以,实现里面采用的是这种方法,代码如下:
def generate_relative_distance(number_size):
"""return relative distance, (number_size**2, number_size**2, 2)
"""
indices = torch.tensor(np.array([[x, y] for x in range(number_size) for y in range(number_size)]))
distances = indices[None, :, :] - indices[:, None, :]
distances = distances + number_size - 1 # shift the zeros postion
return distances
...
elf.position_embeeding = nn.Parameter(torch.randn(2 * self.features_size - 1, 2 * self.features_size - 1))
...
q_n, k_n = q.shape[1], k.shape[2]
attn = attn + self.position_embeeding[self.relative_indices[:, :, 0], self.relative_indices[:, :, 1]][:, :k_n]
4.2 复现trick历程(血与泪TT)
一方面想要看一下model是否是work的,一方面想要顺便验证一下DeiT的策略是否真的有效,所以从头开始做了很多的实验,简单整理如下:
-
数据:
-
训练数据: 20%的imagenet训练数据(快速实验)。 -
验证数据: 全量的imagenet验证数据。
-
环境:
-
8xV100 32G -
CUDA 10.2 + pytorch 1.7.1
-
sgd优化器实验记录
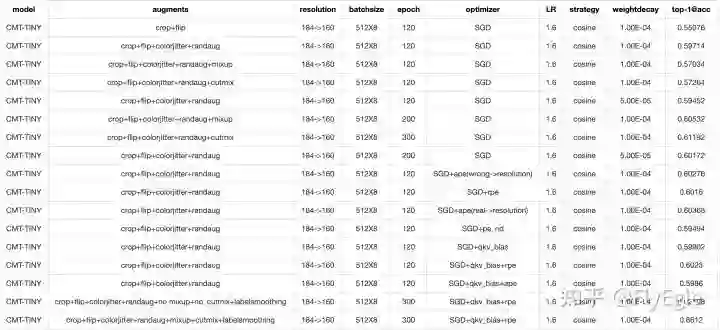
结论: 可以看到在SGD优化器的情况下,使用1.6的LR,训练300个epoch,warmup5个epoch,是用cosine衰减学习率的策略,用randaug+colorjitter+mixup+cutmix+labelsmooth,设置weightdecay为0.1的配置下,使用QKV的bias以及相对位置偏差,可以达到比baseline高11%个点的结果,所有的实验都是用FP16跑的。
-
adamw优化器实验记录
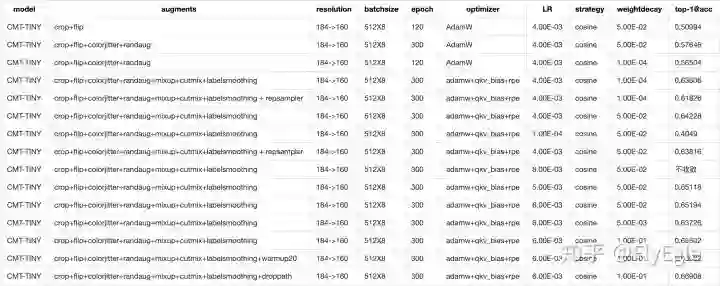
结论:使用AdamW的情况下,对学习率的缩放则是以512的bs为基础,所以对于4k的bs情况下,使用的是4e-3的LR,但是实验发现增大到6e-3的时候,还会带来一些提升,同时放大一点weightsdecay,也略微有所提升,最终使用AdamW的配置为,6e-3的LR,1e-1的weightdecay,和sgd一样的增强方法,然后加上了随机深度失活设置,最后比baseline高了16%个点,比SGD最好的结果要高0.8%个点。
4.3. imagenet上的结果

最后用全量跑,使用SGD会报nan的问题,我定位了一下发现,running_mean和running_std有nan出现,本以为是数据增强导致的0或者nan值出现,结果空跑几次数据发现没问题,只好把优化器改成了AdamW,结果上述所示,CMT-Tiny在160x160的情况下达到了75.124%的精度,相比MbV2,MbV3的确是一个不错的精度了,但是相比paper本身的精度还是差了将近4个点,很是离谱。
速度上,CMT虽然FLOPs低,但是实际的推理速度并不快,128的bs条件下,速度慢了R50将近10倍。
5. 实验结果
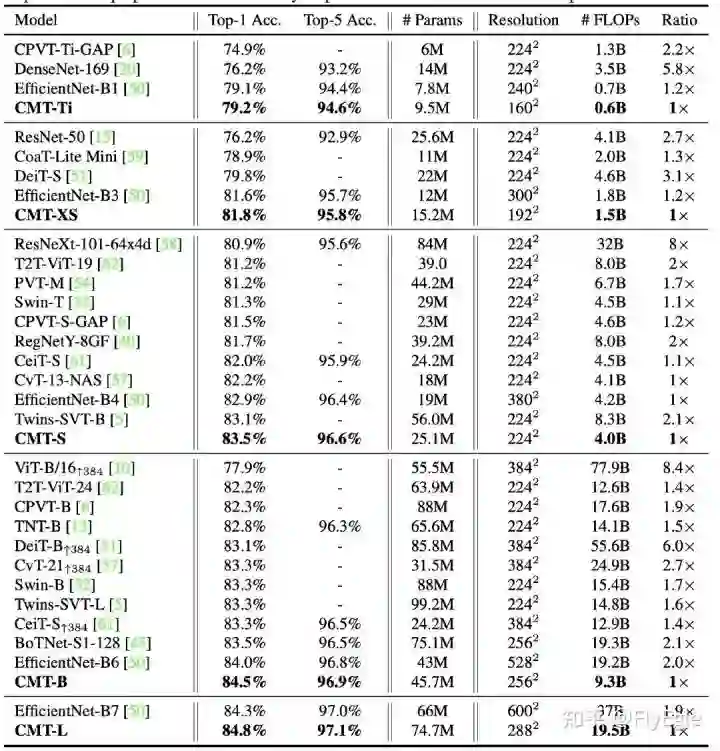
总体来说,CMT达到了更小的FLOPs同时有着不错的精度, imagenet上的结果如下:
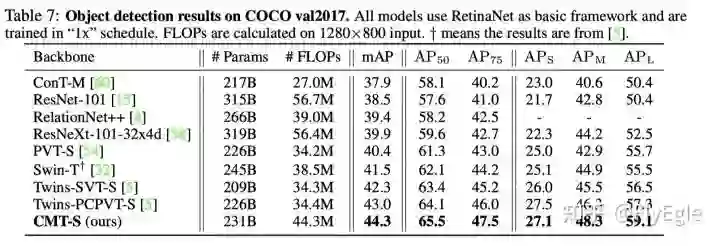
coco2017上也有这不错的精度
6. 结论
本文提出了一种名为CMT的新型混合架构,用于视觉识别和其他下游视觉任务,以解决在计算机视觉领域以粗暴的方式利用Transformers的限制。所提出的CMT同时利用CNN和Transformers的优势来捕捉局部和全局信息,促进网络的表示能力。在ImageNet和其他下游视觉任务上进行的大量实验证明了所提出的CMT架构的有效性和优越性。
代码复现repo:
https://github.com/FlyEgle/CMT-pytorch
实现不易,求个star!
本文亮点总结
-
使用4层conv3x3+stride2 + conv1x1 stride 1 等价于VIT的patch embeeding,conv16x16 stride 16. -
使用conv stem,可以使模型得到更好的收敛,同时,可以使用SGD优化器来训练模型,对于超参数的依赖没有原始的那么敏感。好处那是大大的多啊,仅仅是改了一个conv stem。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




