CVPR 2022 | GeoTransformer:基于Transformer的点云配准网络

©作者 | 秦政
单位 | 国防科技大学
研究方向 | 三维视觉
本文提出了一种基于 Transformer 的点云配准网络。通过引入点云中的全局结构信息,GeoTransformer 能够显著提高 correspondences 的 inlier ratio,从而实现了 RANSAC-free 的场景点云 registration,代码已开源。

Motivation
在这篇工作中,我们关注基于 correspondences 的点云配准方法。这类方法首先建立两个点云之间的 correspondences,再利用 correspondences 来估计 transformation。显然,这类的方法的核心在于找到高质量的 correspondences。
为了建立 correspondences,之前大部分工作都采用了 detect-then-match 的方法 [1,2,3],即先检测两个点云中的 keypoint,再对 keypoint 进行匹配。但是,在两个点云中找到重复的 keypoint 并不容易,当两个点云重叠度很低的时候会变的尤其困难。受到最近在 stereo matching 的一些 keypoint-free 工作的启发,CoFiNet [4] 也尝试了在点云配准中使用 coarse-to-fine 的匹配策略来建立 dense correspondences,避免了 keypoint detection 这个步骤,取得了非常不错的效果。
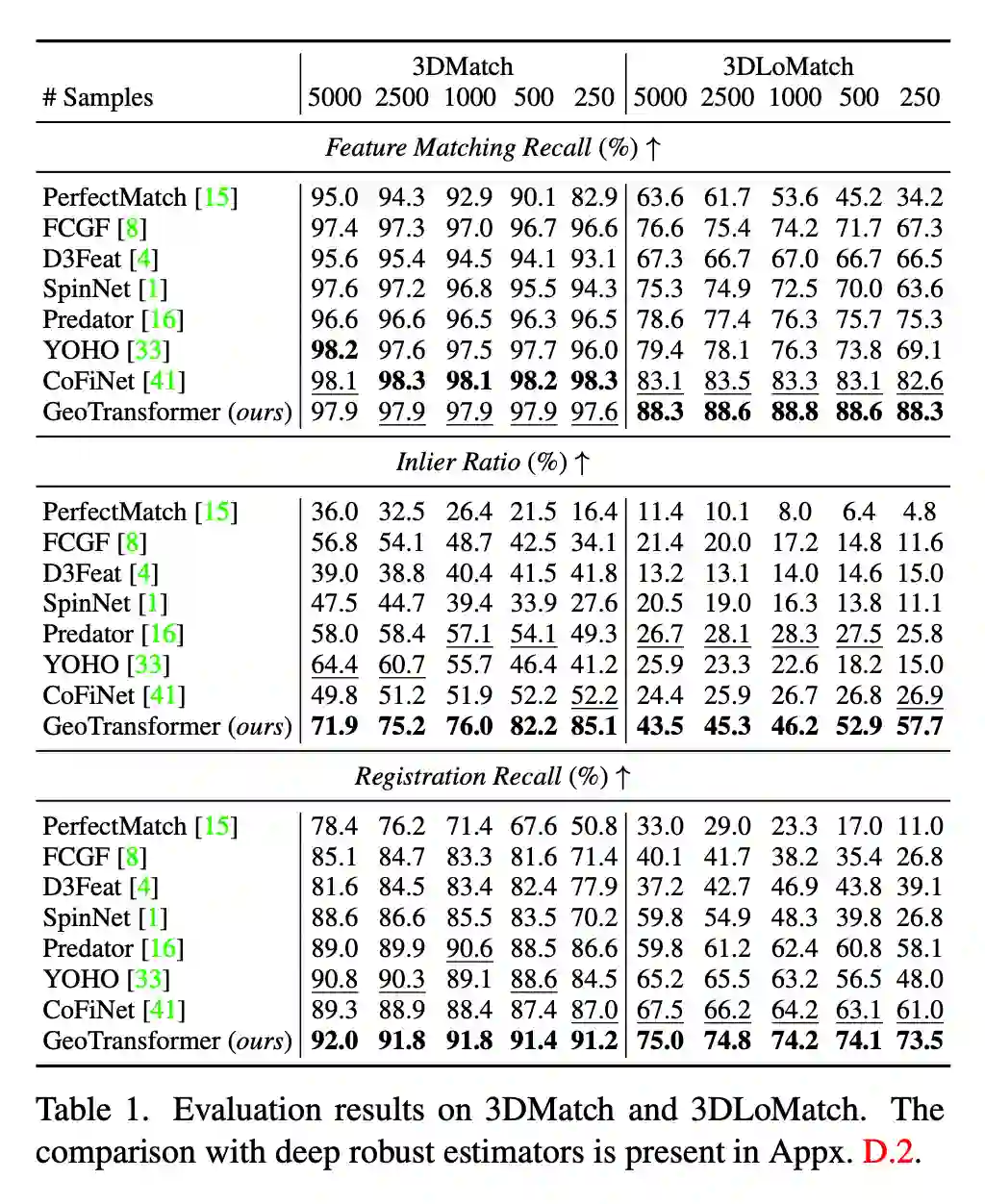
但是,如果仔细观察可以发现,之前这些方法的 correspondences 的质量都还是比较差的。以 CoFiNet 为例,其在 3DMatch 上的 inlier ratio 都只有 50% 上下,而在 3DLoMatch 上 inlier ratio 更是只有 20%+,这无疑很大程度的影响了配准的精度。而这其中的关键因素,就在于 CoFiNet 的 superpoint correspondences 的质量并不够好。
对于 superpoint 的匹配来说,因为整个场景点云中通常会存在很多类似的 local patch,因此对于全局结构的感知尤其重要。为了实现这一目标,之前的方法都使用了 transformer 来进行全局的特征特征。但是,transformer 本身是序列无关的,它不能够区分不同位置的 superpoint。当然,一个简单的方法是利用 NLP、ViT 和 Point Transformer 等工作中的方式,通过将 superpoint 的坐标进行映射作为 transformer 的位置编码。但是,基于坐标的位置编码是 transformation-variant 的,这对于点云配准任务来说并不合理。
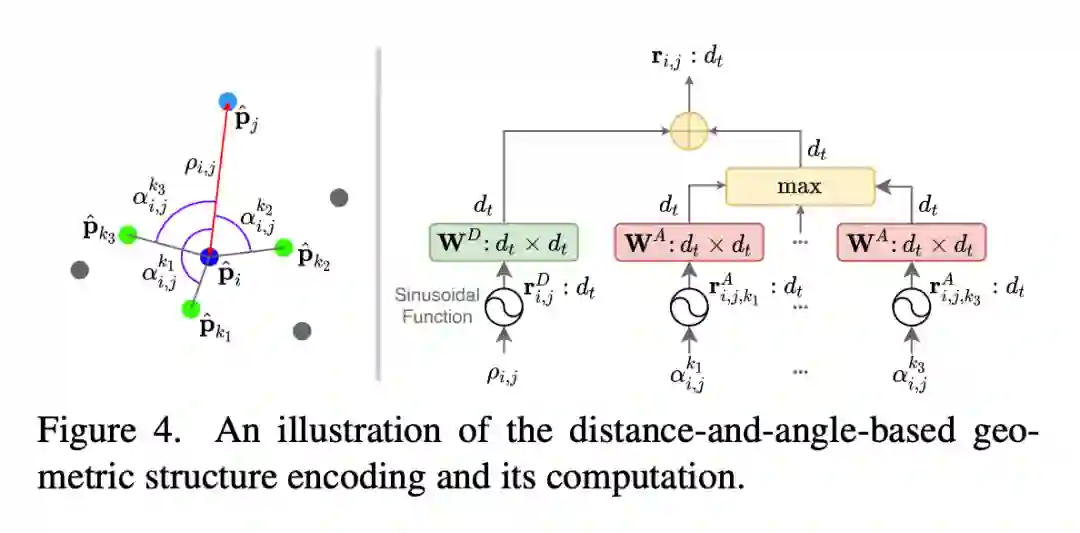
针对这个问题,我们设计了 GeoTransformer,通过对 superpoint pair 之间的距离信息和 superpoint triplet 之间的角度信息进行编码,嵌入到 transformer 中,实现了有效的全局结构信息学习。因为距离和角度信息都是 transformation-invariant 的,因此 GeoTransformer 在特征学习阶段就能够显式的捕捉到两个点云中的空间一致性,这在之前的方法中都是无法实现的。
这一优势使得 GeoTransformer 可以提取到非常高质量的 correspondences,并实现了 RANSAC-free 的点云配准。在 3DLoMatch 基准数据集上,GeoTransformer 相比于之前的方法实现了 17%~31% 的 inlier ratio 提升和 7% 的 registration recall 提升。

论文标题:
Geometric Transformer for Fast and Robust Point Cloud Registration
CVPR 2022
https://arxiv.org/abs/2202.06688
https://github.com/qinzheng93/GeoTransformer

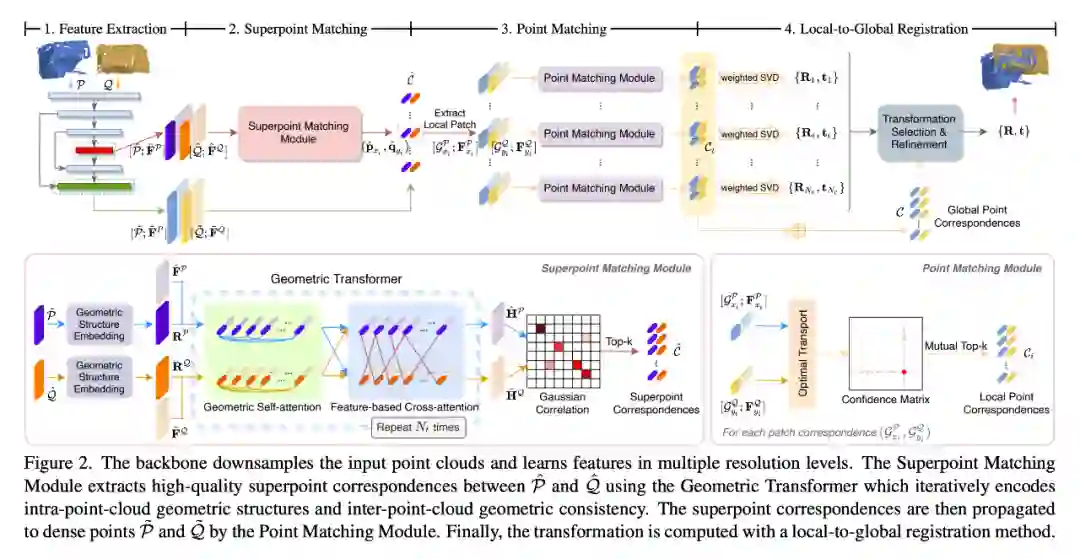
GeoTransformer 的整个算法分为四个部分。首先,对于输入点云,GeoTransformer 通过一个 KPConv backbone 来提特征。我们把最后一个分辨率下的点云所谓 superpoint,并通过 point-to-node 划分把每个点分配给最近的 superpoint,将 superpoint 扩展成 patch。
之后,我们通过 superpoint matching module 来提取 superpoint correspondences。在 superpoint matching module 中,我们使用了 self-attention 和 cross-attention 来进行点云内和点云间的特征学习。为了对点云的全局结构信息进行编码,我们设计了一种 geometric structure embedding,将 superpoint 之间的距离和角度信息引入到 self-attention 的计算中,我们把它称为 geometric self-attention:
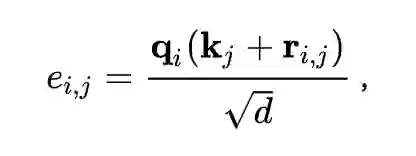

我们主要在 3DMatch、3DLoMatch 和 KITTI 上进行了对比实验。首先 Tab. 1 可以看到,我们的方法在 inlier ratio 这个指标上相对于之前的方法有非常明显的提升,高质量的 correspondences 保证了我们在配准时能够获得更好的精度。
▲ 3DMatch/3DLoMatch, RANSAC-based
而在 Tab. 2 中,在不使用 RANSAC 或者 LGR,仅仅使用 weighted SVD 计算 transformation 的情况下,得益于我们的高质量 correspondences,我们的方法能够得到与 PREDATOR 相近的精度;而在使用 LGR 得情况下,GeoTransformer 则能够实现与 RANSAC 几乎相互的配准精度。
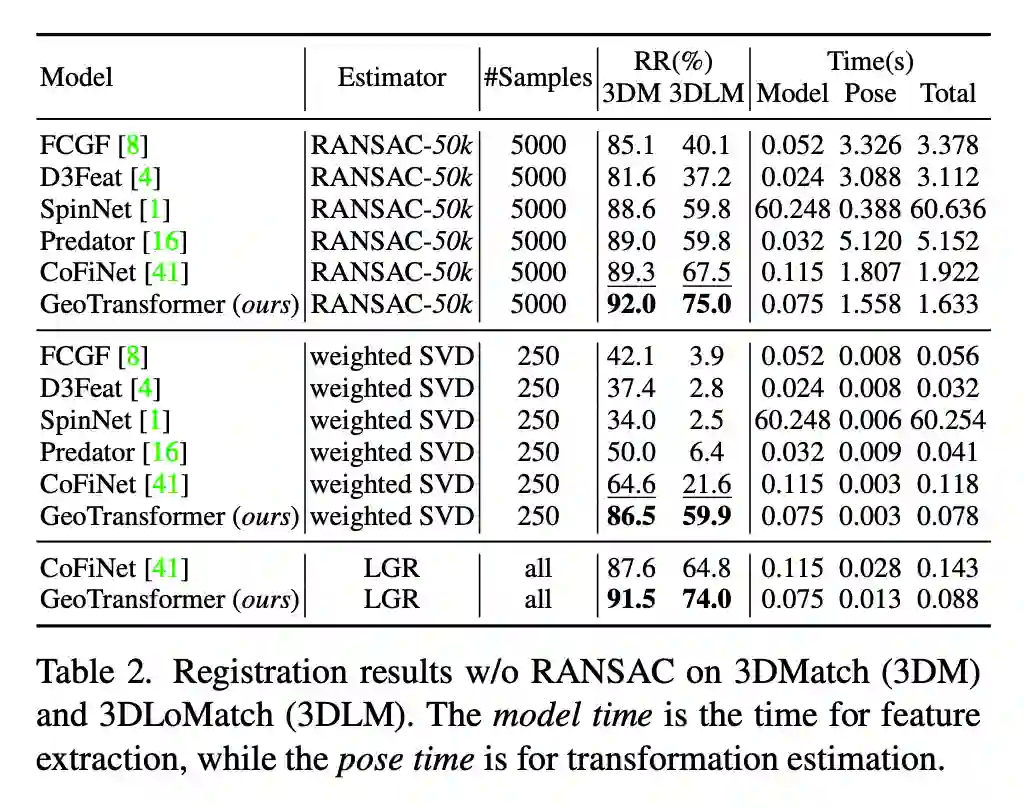
▲ 3DMatch/3DLoMatch, RANSAC-free
最后,我们还对我们的 geometric self-attention 的 attention score 进行了可视化,可以看到,即便是在 overlap 区域很小的情况下,对于匹配的super point/patch,我们的方法依然能够学习到非常一致的 attention score,这也证明了我们的方法能够有效的学习到两个点云中的空间一致性信息,来帮助建立更好的 correspondences。


参考文献
[2] Bai, X., Luo, Z., Zhou, L., Fu, H., Quan, L., & Tai, C. L. (2020). D3feat: Joint learning of dense detection and description of 3d local features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 6359-6367).
[3] Huang, S., Gojcic, Z., Usvyatsov, M., Wieser, A., & Schindler, K. (2021). Predator: Registration of 3d point clouds with low overlap. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 4267-4276).
[4] Yu, H., Li, F., Saleh, M., Busam, B., & Ilic, S. (2021). CoFiNet: Reliable Coarse-to-fine Correspondences for Robust PointCloud Registration.Advances in Neural Information Processing Systems,34.
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧





