稠密检索新突破:华为提出掩码自编码预训练模型,大幅刷新多项基准
机器之心专栏
华为泊松实验室联合北京邮电大学、华为昇思 MindSpore 团队提出了 RetroMAE,在零样本学习与监督学习场景下均展现了极强的稠密检索性能。
稠密检索是搜索、推荐、广告等领域的关键性技术;面向稠密检索的预训练是业界高度重视的研究课题。近期,华为泊松实验室联合北京邮电大学、华为昇思 MindSpore 团队提出“基于掩码自编码器的检索预训练语言模型 RetroMAE”,大幅刷新稠密检索领域的多项重要基准。而其预训练任务的简洁性与有效性,也为下一步技术的发展开辟了全新的思路。该工作已录用于自然语言处理领域顶级学术会议 EMNLP 2022。基于昇思开源学习框架的模型与源代码已向社区开放。

论文地址:https://arxiv.org/abs/2205.12035
开源地址:https://github.com/mindspore-ecosystem/mindsearch
一.稠密检索预训练
近年来,稠密检索技术被愈发广泛的应用于搜索引擎、开放域问答、推荐系统等场景。与传统的基于 “关键词 + 倒排索引” 的检索所方式不同,稠密检索利用深度神经网络理解并建模输入文本的实际含义,并为其生成相应的语义表征向量;借助语义表征向量之间的空间相似性,系统得以精准、快速的获取检索结果。
深度学习的繁荣特别是预训练语言模型的出现极大地促进了稠密检索的发展。特别的,以 BERT、RoBERTa 为代表的预训练语言模型已被普遍用作稠密检索中的骨干网络架构。借助预训练语言模型强大的语义建模能力,稠密检索的精度得到了极大的提升。
在 BERT、RoBERTa 等初代预训练语言模型之后,大量新方法被相继提出,如 XLNET、T5、ELECTRA、DeBERTa 等。这些新生代预训练语言模型在诸如 GLUE、SuperGLUE 等通用的自然语言处理评测基准上展现了更为强劲的实力。不过与人们预期不同的是,新生代预训练语言模型并未在稠密检索任务上带来实质的性能提升;时至今日,早期的 BERT 依然被用作稠密检索中的主流网络。
对此,业界的普遍观点是目前常见的预训练学习任务,如 MLM、Seq2Seq,并未有效关注到模型的语义表征能力,因而也就与稠密检索对模型能力的诉求南辕北辙。
为了克服这一问题,越来越多的学者尝试革新预训练策略以更好的因应稠密检索任务,近年来常被提及的自监督对比学习就是其中的代表。然而,当下基于自监督对比学习的预训练方法存在诸多限制。例如,自监督对比学习的一个重要环节是设计数据增强策略,而受制于 “伪正样例”、“平凡正样例” 等问题,各类数据增强策略在实际中的性能收益与通用性十分有限。另外,自监督对比学习高度依赖海量负样例,而这一需求也导致巨大的训练开销。就目前的研究现状而言,面向稠密检索的预训练算法依然有很大的亟待完善的空间。
二.RetroMAE:
基于掩码自编码器的稠密检索预训练
不同于以往常见的自监督对比学习方法,生成式的预训练因其学习任务更高的挑战性、对无标签数据更高的利用率、以及无需负采样及数据增强策略等特点,而被近来的检索预训练领域的工作所重视。在此之前,业界已提出了诸如 SEED [1]、TSDAE [2]等优秀工作,通过改造传统的 Seq2Seq 等类型的生成任务,这些工作有效提升了预训练语言模型在稠密检索任务上的表现。受到这些积极信号的启发,RetroMAE 继承并拓展了生成式预训练这一技术路线。
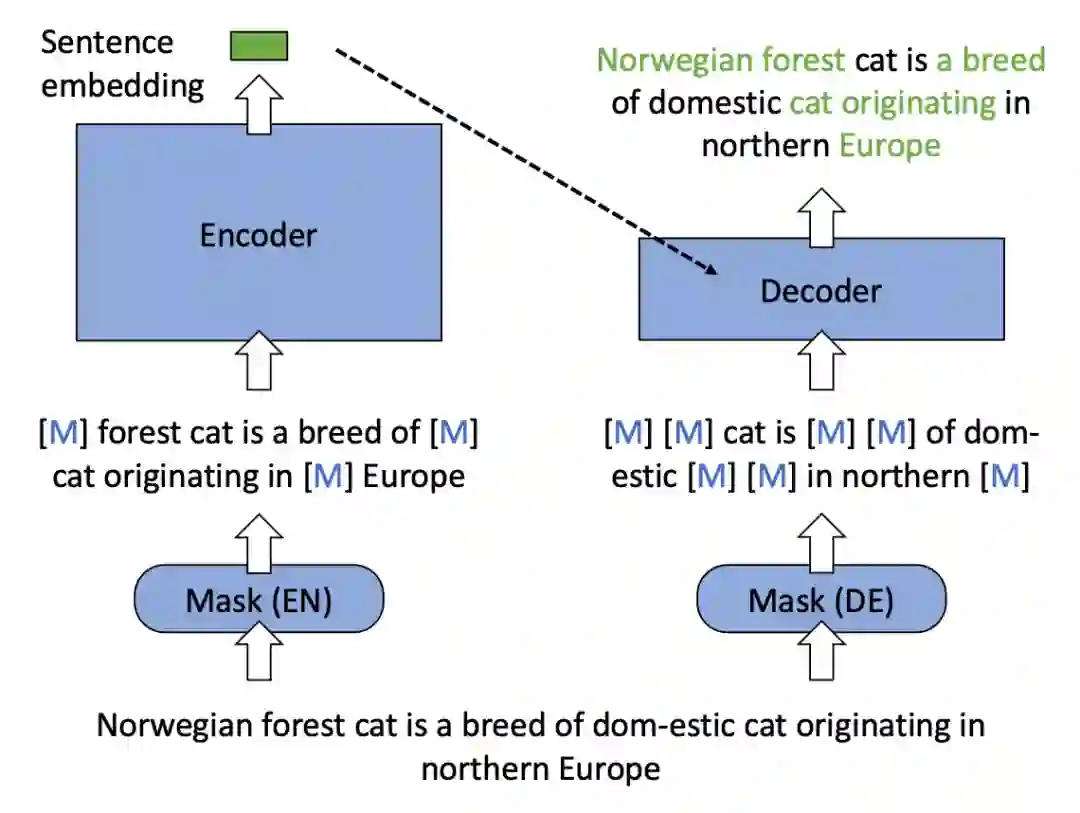
图 1. 基于掩码自编码器的预训练流程示例
基础架构:掩码自编码器。RetroMAE 采用了经典的掩码自编码器这一架构来预训练模型的语义表征能力。首先,输入文本经掩码操作后由编码器(Encoder)映射为隐空间中的语义向量;而后,解码器(Decoder)借助语义向量将另一段独立掩码的输入文本还原为原始的输入文本(如图 1)。
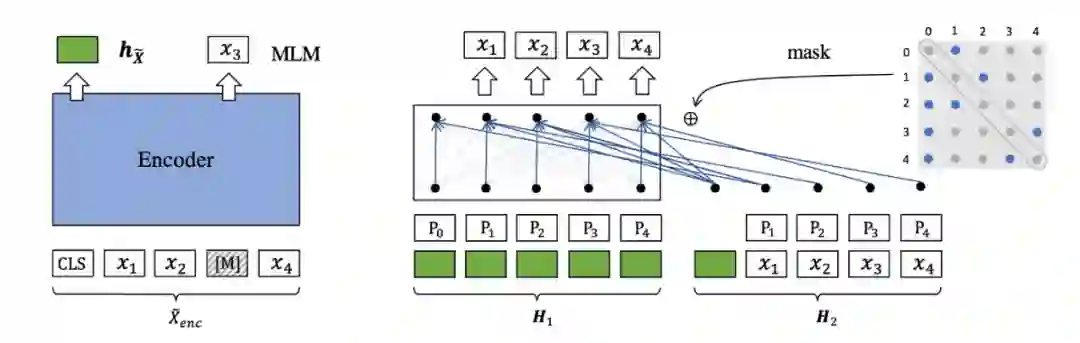
图 2. 解码增强。双流注意力机制(H1:query stream,H2:content stream),随机生成注意力掩码矩阵(蓝色点:可见位置,灰色点:掩码位置)
为了使训练任务更具挑战性、且实现更高的无标注数据利用率,RetroMAE 设计了如下三个关键技术。
非对称的网络结构。编码器采用全尺寸的 Transformer 网络(如 BERT),已实现对深度语义的有效建模。然而,解码器则采用单层的 Transformer 网络;这一设计不仅提升了解码难度,也使得解码任务可以灵活使用多样化的上下文信息,实现对无监督数据更加充分的利用。
非对称的掩码率。对于编码器端的输入,RetroMAE 采用了 “适度的” 掩码率,仅仅遮蔽其中 15~30% 的词汇;而对于解码器端的输入,RetroMAE 采用了非常 “激进的” 掩码率,50~90% 的词汇将会被遮蔽。
解码增强。由于解码器仅由单层 Transformer 构成,因此,RetroMAE 有针对性的设计了增强式的解码策略,即通过生成随机的注意力掩码矩阵(attention mask matrix)以及双流注意力机制(two-stream attention),以实现每个待解码单词对上下文的多样化利用。具体而言,解码器会同时编码两个输入序列,一个作为 query stream,另一个作为 content stream。此外,解码器将随机生成注意力掩码矩阵,矩阵中的每一行元素标明了每个待解码单词所能感知的上下文位置。在 query stream 对 content stream 进行自 self-attention 的过程中,注意力掩码矩阵将为每个单词过滤掉需要掩码的上下文。由于注意力掩码矩阵的随机性,每个单词所利用的上下文将彼此不同;而解码过程中多样化的上下文信息也将有效提升算法对无标注数据的利用效率。
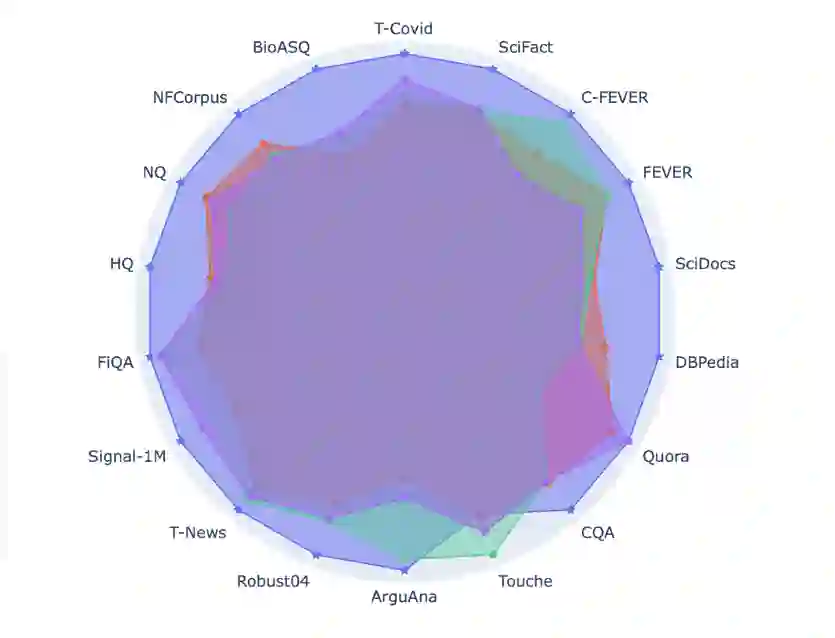
图 3. RetroMAE (blue)在 BEIR 上与 BERT (red)、RoBERTa (green)、DeBERTa(purple)的对比

图 4. RetroMAE 在零样本稠密检索基准 BEIR 上的表现
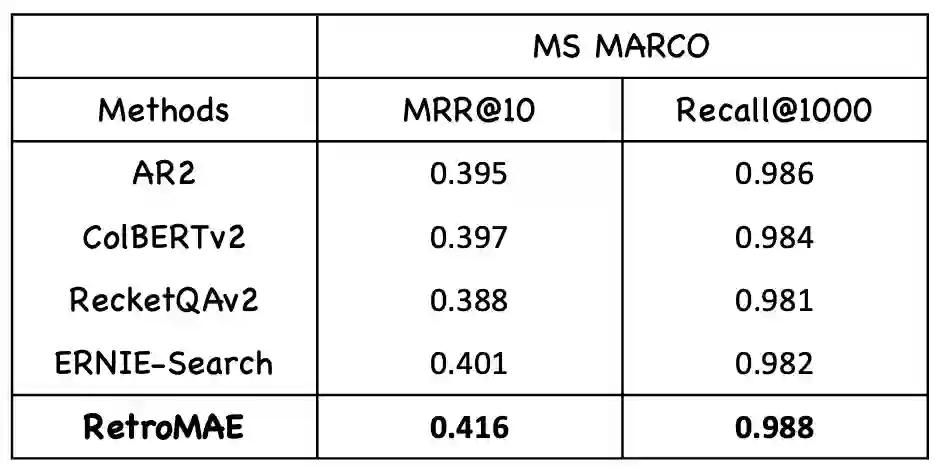
图 5. RetroMAE 在开放域问答检索基准 MS MARCO 上的表现
三.实验探究
RetroMAE 在零样本学习(zero-shot learning)与监督学习(supervised learning)场景下均展现了极强的稠密检索性能。根据在零样本稠密检索基准 BEIR [3]之上的表现(图 3、图 4),RetroMAE 在绝大多数任务中都明显优于 BERT、RoBERTa、DeBERTa 等传统基线,其平均检索精度更是远超此前同等规模的预训练模型。
与此同时,RetroMAE 在开放域问答基准 MS MARCO [4]上同样表现不俗(图 5),其段落检索精度取得了对比 RocketQAv2 [5]、AR2 [6]、ERNIE-search [7]、ColBERTv2[8]等近年稠密检索强基线的显著优势。
这些实验结果不仅验证了 RetroMAE 的有效性,更是进一步反映了预训练模型对于稠密检索的巨大意义。目前,RetroMAE 已逐步应用于包括网页搜索在内的华为各主要搜索产品,全面提升深度语义检索在实际场景中的有效性。为推动相关技术的进一步发展,RetroMAE 的模型、源代码均已向社区开放 [9,10]。
四.昇思 MindSpore AI 框架
昇思 MindSpore 是华为推出的全场景 AI 框架,旨在实现易开发、高效执行、全场景覆盖三大目标,为数据科学家和算法工程师提供设计友好、运行高效的开发体验。作为近年来人工智领域备受瞩目的议题,大规模预训练模型是昇思 MindSpore 框架着重打造的能力。为此,开发人员设计实现了 MindSpore Transformer 等套件,构建集模型训练、推理、部署为一体的全流程服务,实现从单 GPU 到大规模集群训练的无缝切换,并提供包括数据并行、模型并行、流水线并行在内的完备的训练策略。
此前,MindSpore 框架已成功支持包括盘古大模型在内的众多大规模预训练任务。RetroMAE 是昇思 MindSpore 框架的又一次成功实践。得益于昇思 MindSpore 深度协同优化的高性能算子库,RetroMAE 得以充分释放硬件算力,高效的实现了基于海量无标注数据的预训练任务。未来,华为将继续借助昇思 MindSpore 框架打造一流的深度语义检索能力,助力更加智慧、精准的搜索体验。
参考文献
[1] Less is More: Pre-train a Strong Text Encoder for Dense Retrieval Using a Weak Decoder
[2] TSDAE: Using Transformer-based Sequential Denoising Auto-Encoder for Unsupervised Sentence Embedding Learning
[3] BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
[4] MS MARCO: A Human Generated Machine Reading Comprehension Dataset
[5] RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking
[6] Adversarial Retriever-Ranker for dense text retrieval
[7] ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval
[8] ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction
[9] https://github.com/staoxiao/RetroMAE
[10] https://github.com/mindspore-ecosystem/mindsearch
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



