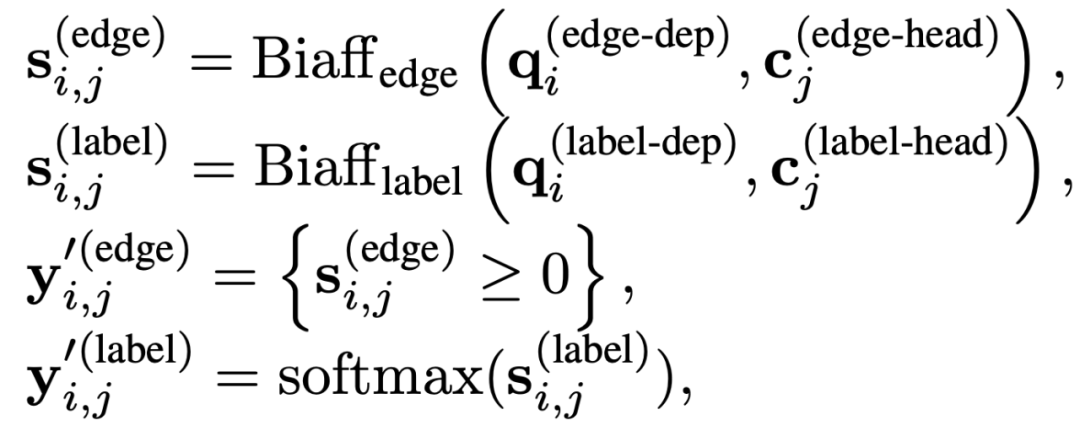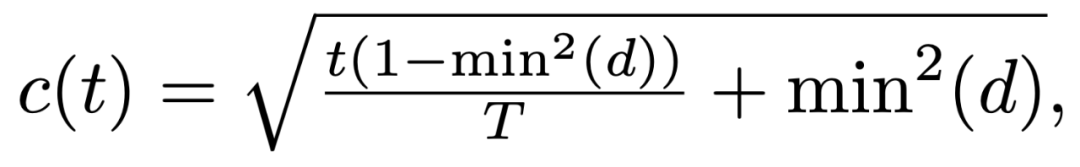12 月 2 日,达摩院深度语言模型体系 AliceMind 发布中文社区首个表格预训练模型 SDCUP,该模型在全球权威表格数据集 WikiSQL 和 SQuALL 上取得了业界最优效果,相关模型和训练代码已经开源于阿里巴巴深度语言模型体系 AliceMind 中。
![]()
此外,在达摩院构建的表格问答中文数据集 TaBLUE 上,SDCUP 比同参数规模 BERT 模型效果提升约 3 个百分点。达摩院资深算法专家李永彬介绍,SDCUP 模型是达摩院表格对话技术系列研发的一部分,后续将持续对外开源。
目前,预训练表格模型 SDCUP 和相关 NL2SQL 技术已经应用在了阿里云智能客服(云小蜜)的 TableQA 产品中。并且,为满足不同场景下的训练和交付需求,表格管理、数据配置、模型训练和效果干预等功能已全部完成产品化,基本做到知识梳理低成本、问答构建高速度、模型训练无标注,满足各个场景的交付运维需求。
由于数据结构清晰、易于维护,表格 / SQL 数据库是各行各业应用最普遍的结构化数据,也是智能对话系统和搜索引擎等的重要答案来源。传统表格查询需要专业技术人员撰写查询语句(如 SQL 语句)来完成,因门槛高,阻碍了表格查询的大规模应用。表格问答技术通过将自然语言直接转换为 SQL 查询,允许用户使用自然语言与表格数据库直接交互,具有很高的应用价值。
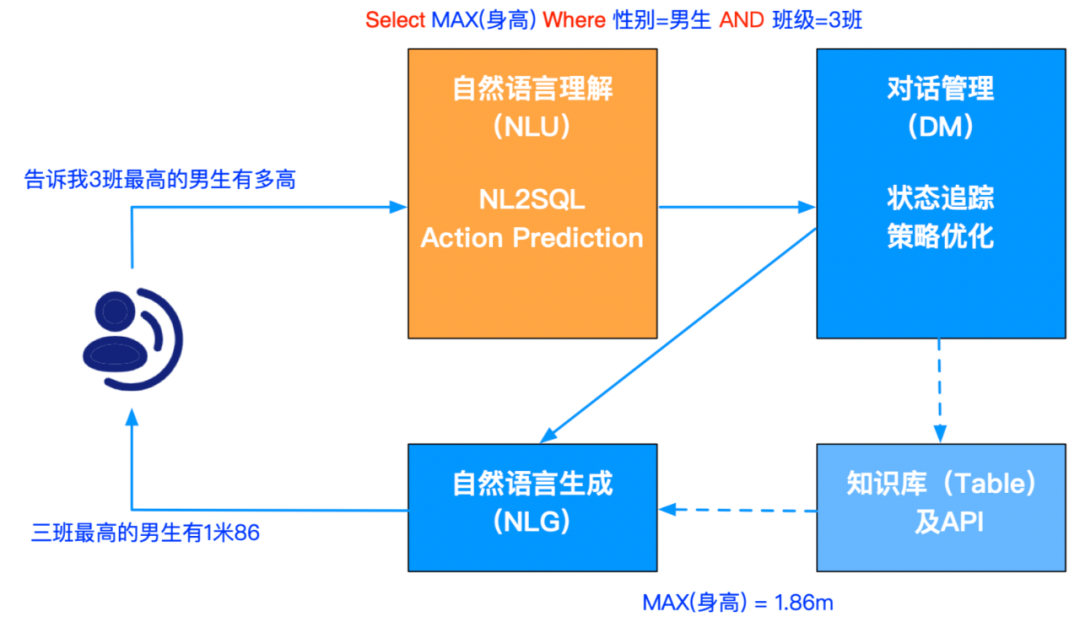
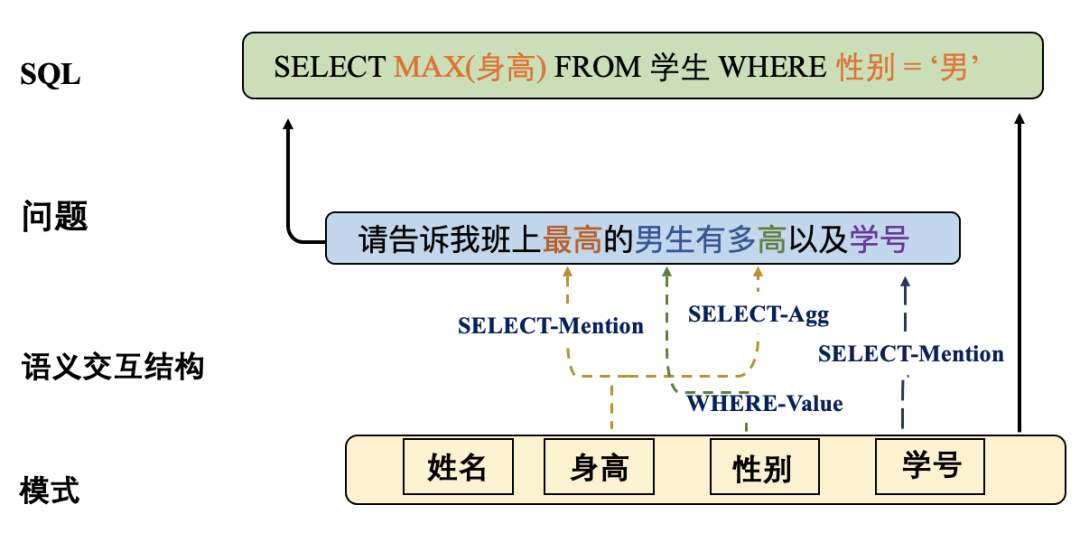
什么是表格问答(TableQA)呢?我们通过一个例子来引入,如下图班级学生信息的 Table,用户可能会问:“告诉我 3 班最高的男生有多高?” 要想解决这个问题,需要先把自然语言转换成一个 SQL 语句,然后用 SQL 语句去查询表格。所以
整个 TableQA 的核心问题就是解析自然语言:把 TEXT 文本转变为 SQL 语句(NL2SQL)
。
![]()
由于表格内容复杂多样,涉及各行各业的专业知识,样本标注难度大,模型迁移能力差,这项任务一直是自然语言处理领域的难题。
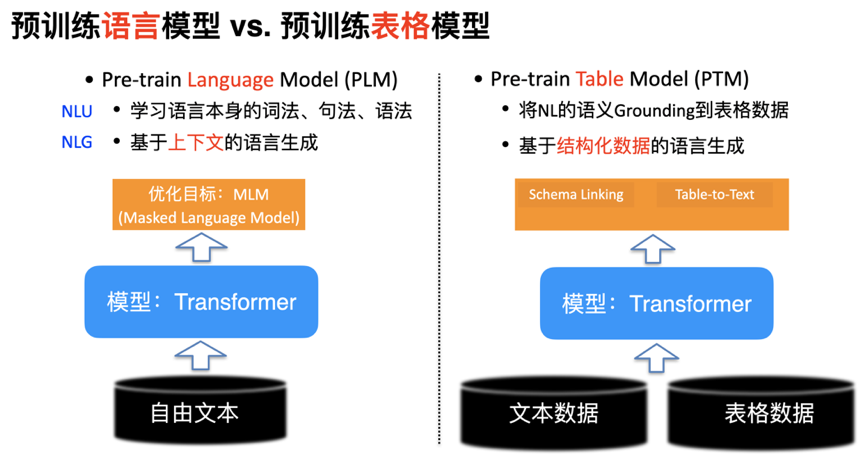
近年来预训练语言模型(BERT、GPT、T5)迅速发展,促进了 NLP 领域各种任务上的进步,例如阅读理解、命名实体识别等任务。但目前的预训练模型基本上在通用文本上进行训练,在一些需要对结构化表格数据进行建模的任务上(如 Text-to-SQL 和 Table-to-Text),需要同时对结构化数据进行表示,如直接采用现有 BERT 等模型,就面临着编码文本与预训练文本形式不一致的问题。
目前,英文场景已有一些针对结构化数据做预训练的探索(GAP,Grappa),但在中文场景该方向还处于空白状态。
基于此,研究者所在的达摩院 Conversational AI 团队发布了
中文首个表格预训练模型 SDCUP
,同时也是
业界最大表格预训练模型(72 层 Transformer,10 亿参数)
,在 WikiSQL、SQuALL 等多个学界 Benchmark 均取得 SOTA 效果。
![]()
项目地址:https://github.com/alibaba/AliceMind
和 BERT、GPT 等预训练语言模型不同,预训练表格模型旨在同时建模自然语言和结构化表格数据,在语言理解的维度希望能够将自然语言的语义 Grounding 至表格的结构内容当中,在语言生成的维度希望能够基于结构化数据生成流畅的文本。
![]()
目前谷歌、微软、亚马逊等公司都在加快对相关技术的布局。如下图所示,按照目标下游任务的不同,预训练表格模型可以分为三大类:
单轮、多轮和生成
。
单轮模型旨在提升下游的 Text-to-SQL 语义解析任务,代表工作有耶鲁的 Grappa 和亚马逊的 GAP;
多轮模型旨在提升基于表格的对话式语义解析任务(CoSQL),代表工作有微软的 SCORE 和 Element AI 的 PICARD;
生成模型旨在提升 Table-to-Text 和 TableQA 的 Response Generation 生成的效果,代表工作有 Intel 的 TableNLG 和 HIT 的 TableGPT。
目前,Conversational AI 团队在单轮、多轮、生成三个方向均有布局。本文
主要介绍单轮表格预训练的工作,同时也是中文社区第一个表格预训练模型
,多轮和生成的工作敬请关注我们后续的技术文章。
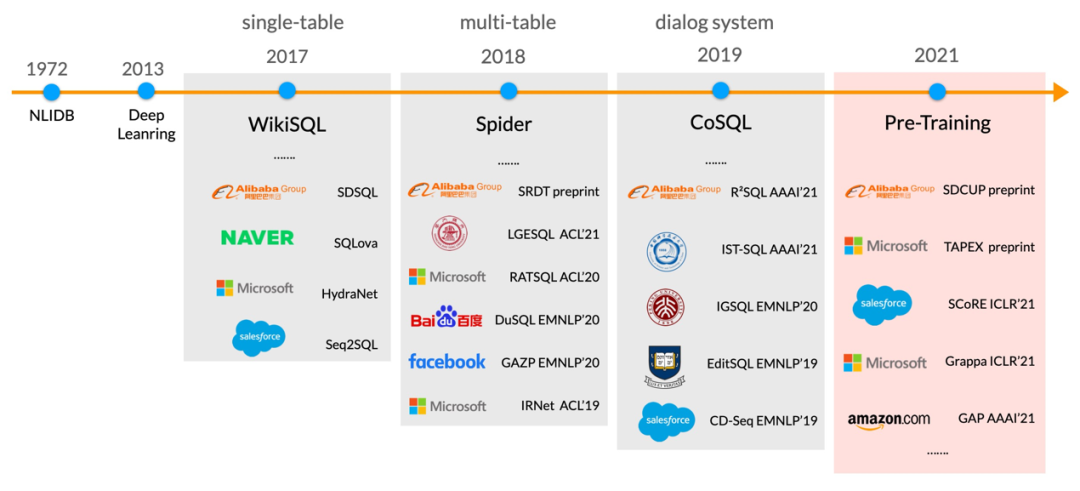
表格问答技术在金融、政务、教育、医疗等场景均有广泛应用前景,因此受到了学术界和工业界的高度关注。以 Text-to-SQL 解析任务为例,自从 2017 年 Salesforce 发布 WikiSQL 数据集以来,就一直受到业界的持续关注和投入,SQL 解析的准确率已经从 2017 年的 35% 提升到 2021 年的 91%。另外,业界也在持续构建更加复杂、更加符合真实场景的数据集,从单表到多表、从单轮到多轮,为该方向的发展不断注入活力。
![]()
团队除了在 WikiSQL/Spider/CoSQL 三个学术界数据集取得 SOTA 效果之外,也构建了该领域中文的单轮、多轮、生成的数据集,并且将相关技术应用于阿里云智能客服的表格问答模块,从产研结合的角度推动该领域的发展。
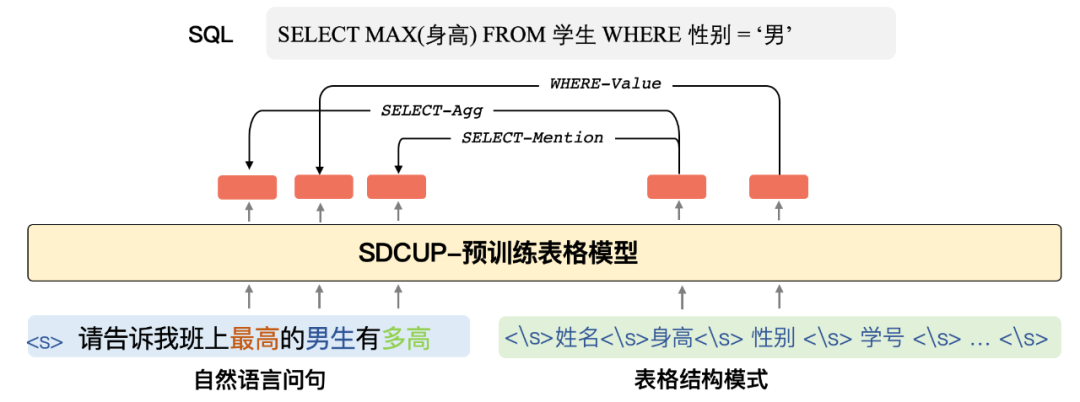
预训练表格模型最终的目标是为了提升下游 Text-to-SQL 任务的效果,如下图所示,在自然语言和表格的 schema 之间,存在这一个复杂的语义交互结构(Schema Linking),对于该结构的识别和建模已经成为 Semantic Parsing 任务中的重要瓶颈。然而,业界已有的表格预训练模型没有显式建模自然语言问题和表格数据之间的语义交互结构。
![]()
因此,团队提出了
基于模式依存的表格预训练模型
,为了提升模型对于不同表格模式下的鲁棒性,还进一步提出了基于模式知识扰动的表格预训练模型;此外,为了减轻数据噪音对模型的影响,团队还提出了
基于课程学习的表格预训练模型
。
对于预训练表格模型来说,最关键的问题在于找到自然语言问题和模式之间的关联,又称模式链接问题。所以在预训练模型的训练目标中应该显式地引入这种模式链接结构,如图所示,团队引入了模式依存的方法,通过模型来预测问题中的哪些词应该和模式中的哪些项进行链接,并且这种链接关系对应 SQL 中的什么关键词。通过这种显示的关系建模,能够得到更好的问题和模式表征,从而提升下游 TableQA 模型的性能。
![]()
他们参考语义依存分析的方法对 Schema Dependency 任务进行建模,首先使用全连接网络分别获取每个节点作为父亲节点和作为孩子节点的语义表示,然后使用双仿射网络预测每个边存在的概率和该边关系类型的概率:
![]()
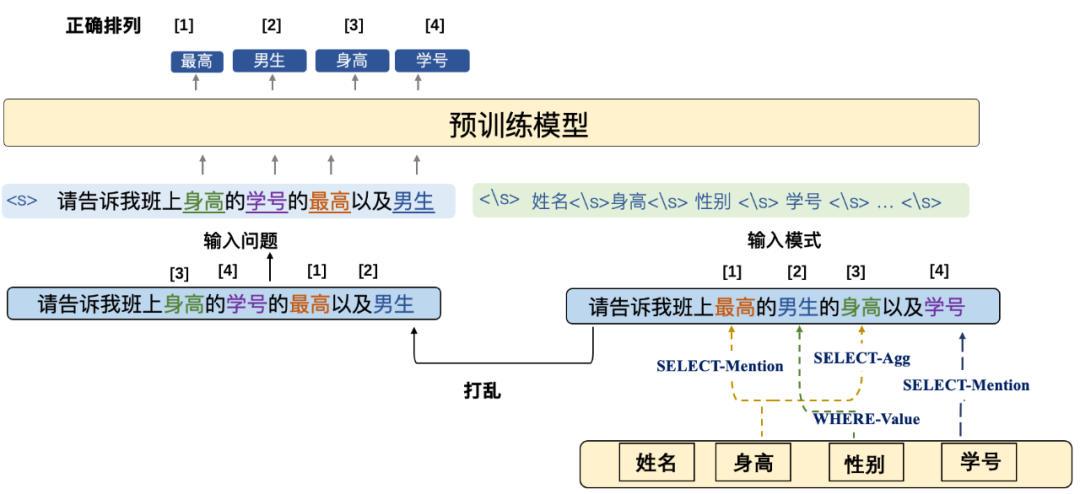
与预训练语言模型相比,表格预训练模型在模式存在的环境下找到合适的模式表征也至关重要,如下图所示,通过扰动问题中涉及到模式链接的词汇,然后通过预训练模型来恢复。
![]()
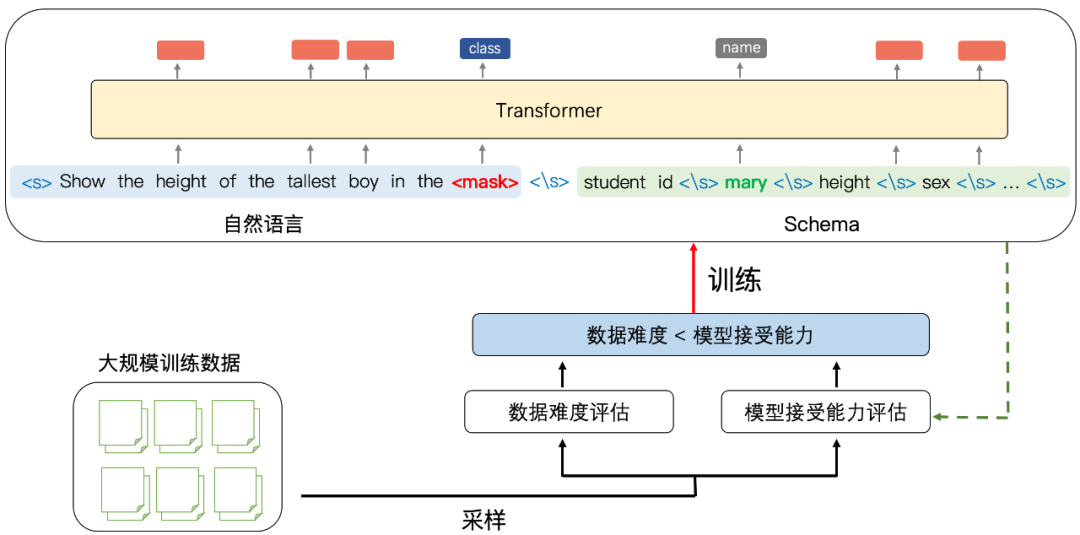
预训练模型依赖大规模的数据进行训练,而数据存在难度不同、噪声程度不同等特性。如何更好地利用数据成为训练预训练模型的关键。因此团队提出使用课程学习来克服多样数据带来的影响。
课程学习是一种模仿人类的学习方式,即从简单到复杂,从干净到冗余的学习过程。类比到深度学习模型中,模型也需要一种合适的学习策略,先学习哪些数据、再学习哪些数据,对模型能力的提升极为重要。如果当前模型学习的数据过于复杂,则容易造成欠拟合,如果过于简单,容易造成过拟合,所以需要一种自动的手段筛选当前数据是否符合模型当前期待的复杂程度。基于这个思想,他们的方案包含两个评估模块:
其一,
数据难度评估模块
:评估当前数据的难易程度,设置 d = |I|,其中 d 代表困难程度,I 代表预训练模型的输入(包含自然语言 + 表格模式),即假设输入的问题长度和模式长度越长,最终可能生成的 SQL 语句更加复杂,对应当前数据难度越高;
其二,
模型接受能力评估模块
:除了对数据本身进行打分之外,我们还需要对模型当前的接受能力,或者学习能力进行评估,一般来说,模型训练越久,其接受能力越强。所以将模型的接受能力定义为:
![]()
其中 d 为数据难度,t 为训练的步数,T 为最大训练步数。
最终,从大规模数据中采样得出具体数据时,如果当前数据的难度小于模型的接受能力,则改数据用来进行训练,反之则放回训练集。随着不断的迭代,所有的数据将渐进式地完成输入。
![]()
最终的表格预训练数据包含 2.8 亿条 < Text, SQL, Table> 三元组,共 350 GB。为评测表格预训练模型的质量,团队在学术界已有的英文数据集进行验证,其中
WikiSQL 数据集
是 Salesforce 在 2017 年提出的大规模标注 Text-to-SQL 数据集,也是目前规模最大的 Text-to-SQL 数据集,它包含 24,241 张表格、80,645 条自然语言问句及相应的 SQL 语句。
微软 SQuALL 数据集
则增大了该任务的预测难度,每个 cell 可能包含多个实体或含义,测试集使用的表格都是训练阶段没有见过的。目前这两个数据集已经成为学术界评测预训练表格模型最通用的 Benchmark 数据。
同时,团队进一步构建了表格问答中文 Benchmark 数据集 TaBLUE,在基于模板构建的数据基础之上,由人工改写对应的文本,使其更加符合真实的表格问答场景,最终单轮的评测数据包含金融、政务、医疗和教育四个行业,共有 4W 高质量标注 < Text,SQL > 数据。
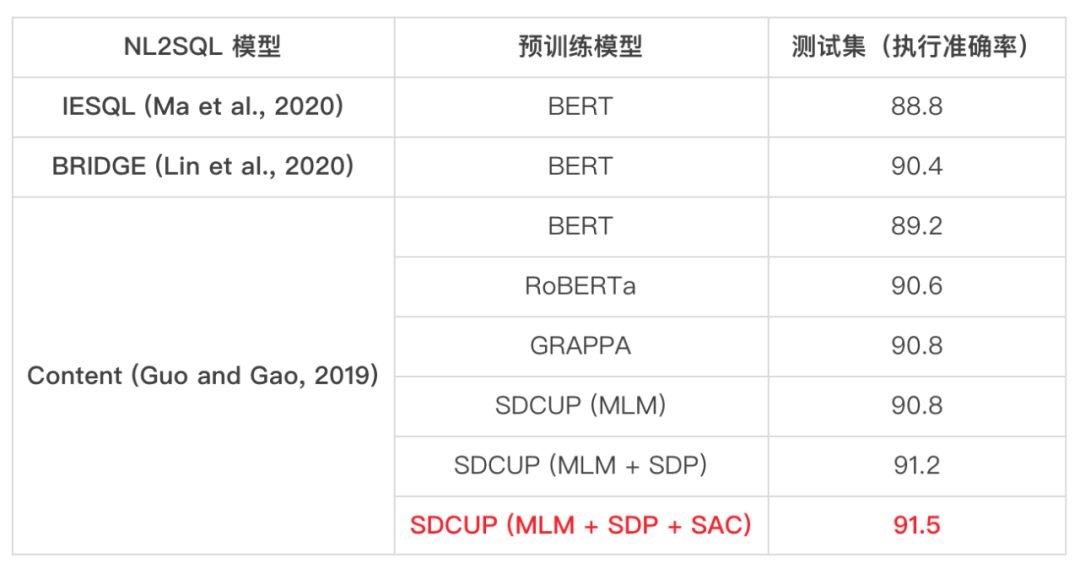
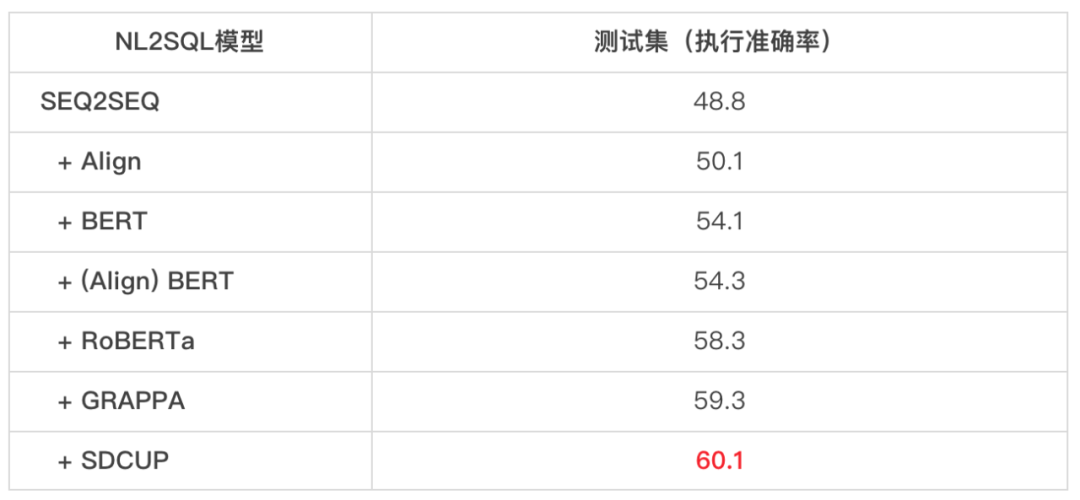
在耶鲁大学的 WikiSQL 数据集和微软构建的 SQuALL 数据集上,SDCUP 模型也取得了 SOTA 的效果,并且相比学术界已有的表格预训练模型有较显著提升。
![]()
SDCUP 在耶鲁大学 WikiSQL 数据集上取得业界最优效果
![]()
SDCUP 在微软 SQuALL 数据集上取得业界最优效果。
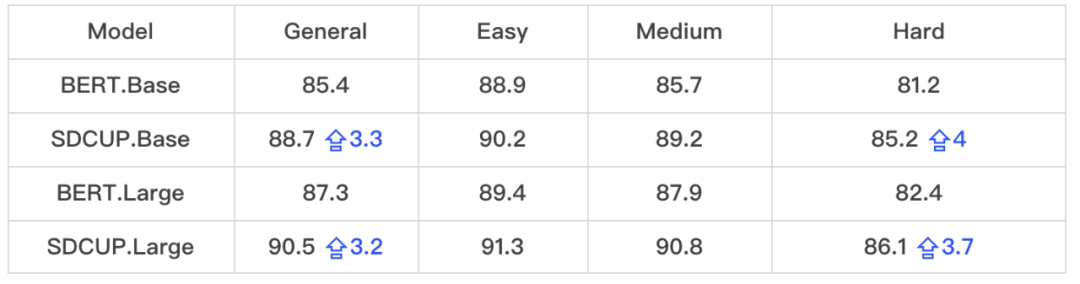
在 TaBLUE 数据集上,SDCUP 的 base 和 large 模型相比同参数规模的 BERT 模型分别提升 3.3 和 2.9 个百分点,并且随着数据难度的增大提升幅度也逐渐增大,体现出 SDCUP 模型对于复杂 NL2SQL 数据具有更好的建模能力。
![]()
本文详细介绍了中文首个表格预训练模型——SDCUP 背后的数据构建和模型训练等技术细节,以及相关表格问答技术的产品化和业务落地情况。如何建模自然语言和结构数据之间的语义关联是自然语言处理领域备受关注的课题,本文所提出的 Schema Dependency 系列方法可以视为该领域下新的探索方向。
除了在中英文 NL2SQL 任务中取得 SOTA 效果之外,团队也在探索如下方向:
超大规模预训练表格理解模型;
超大规模预训练表格生成模型;
端到端开箱即用的问答系统。
[1] Yu T, Zhang R, Polozov A, et al. SCoRe: Pre-Training for Context Representation in Conversational Semantic Parsing[C]//International Conference on Learning Representations. 2020.
[2] Hui B, Geng R, Ren Q, et al. Dynamic Hybrid Relation Exploration Network for Cross-Domain Context-Dependent Semantic Parsing[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(14): 13116-13124.
[3] Shi P, Ng P, Wang Z, et al. Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(15): 13806-13814.
基于Python,利用 NVIDIA TAO Toolkit 和 Deepstream 快速搭建车辆信息识别系统
NVIDIA TAO Toolkit是一个AI工具包,它提供了AI/DL框架的现成接口,能够更快地构建模型,而不需要编码。
DeepStream是一个用于构建人工智能应用的流媒体分析工具包。它采用流式数据作为输入,并使用人工智能和计算机视觉理解环境,将像素转换为数据。
DeepStream SDK可用于构建视觉应用解决方案,用于智能城市中的交通和行人理解、医院中的健康和安全监控、零售中的自助检验和分析、制造厂中的组件缺陷检测等
12月14日19:30-21:00,本次分享摘要如下:
介绍 TAO Toolkit 的最新特性;
介绍 NVIDIA Deepstream 的最新特性;
利用 TAO Toolkit 丰富的预训练模型库,快速训练模型;
直接利用 TAO Toolkit 的预训练模型和 Deepstream 部署应用;
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com