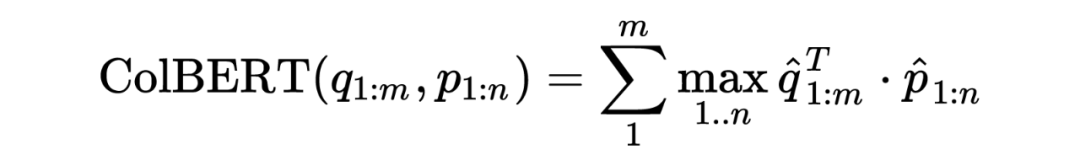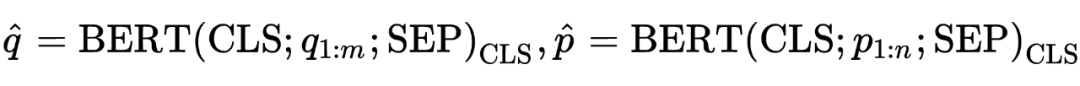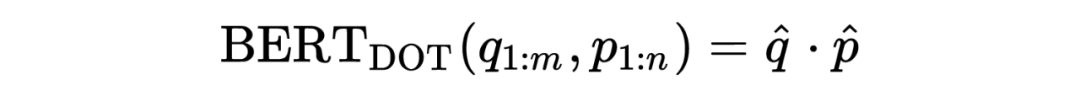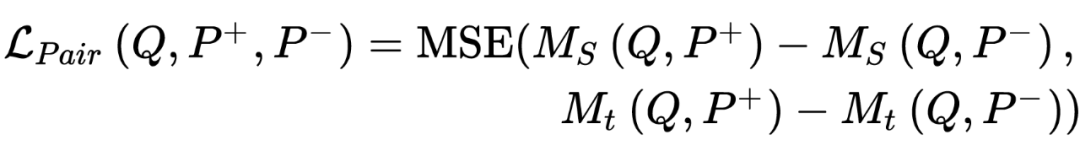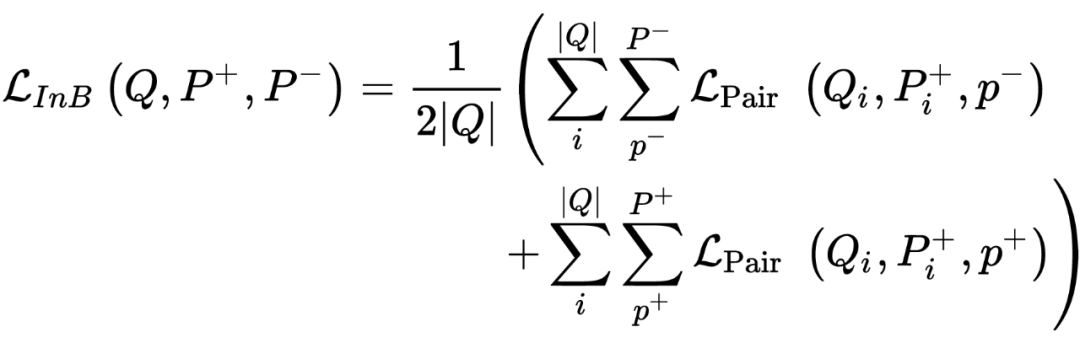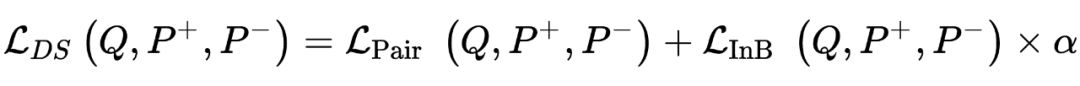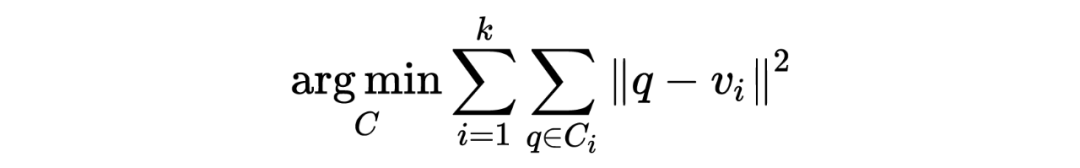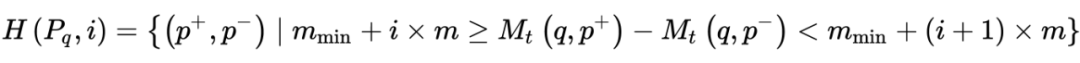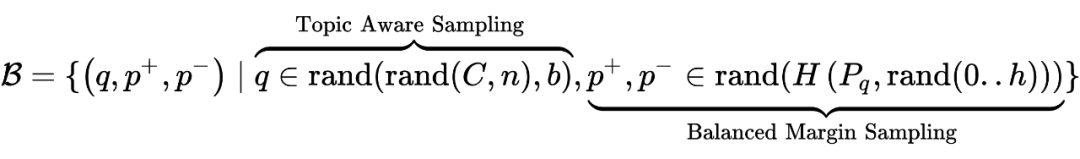©PaperWeekly 原创 · 作者 | Maple小七
单位 | 北京邮电大学
研究方向 | 自然语言处理
论文标题:
Efficiently Teaching an Effective Dense Retriever with Balanced Topic Aware Sampling
SIGIR 2021
https://arxiv.org/abs/2104.06967
https://github.com/sebastian-hofstaetter/tas-balanced-dense-retrieval
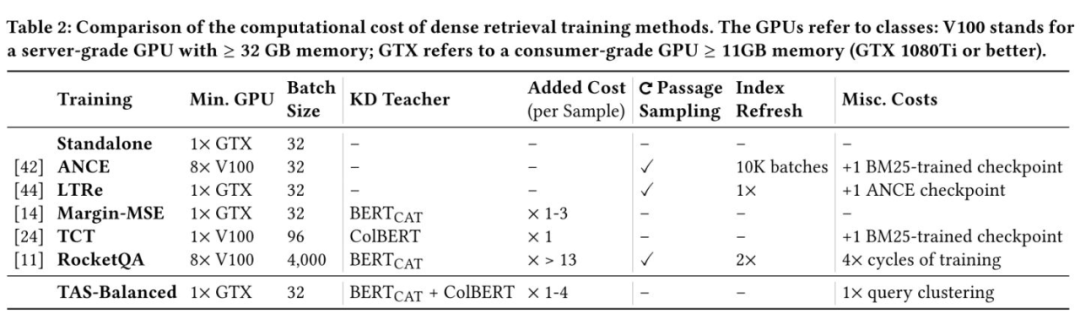
基于 BERT 的稠密检索模型虽然在 IR 领域取得了阶段性的成功,但检索模型的训练、索引和查询效率一直是 IR 社区关注的重点问题,虽然超越 SOTA 的检索模型越来越多,但模型的训练成本也越来越大,以至于要训练最先进的稠密检索模型通常都需要 8×V100 的配置。而采用本文提出的 TAS-Balanced 和 Dual-supervision 训练策略,我们仅需要在单个消费级 GPU 上花费 48 小时从头训练一个 6 层的 DistilBERT 就能取得 SOTA 结果 ,这再一次证明了当前大部分稠密检索模型的训练是缓慢且低效的。
绪言
在短短的两年时间内,当初被质疑是 Neural Hype 的 Neural IR 现在已经被 IR 社区广泛接受,不少开源搜索引擎也逐渐支持了基于 BERT 的稠密检索(dense retrieval),基本达到了开箱即用的效果。其中,DPR 提出的
是当前最主流的稠密检索模型,然而众所周知的是,
的可迁移性远不如 BM25 这类 learning-free 的传统检索方法,想要在具体的业务场景下使用
并取得理想的结果,我们通常需要准备充足的标注数据进一步训练检索模型。
因此,如何高效地训练一个又快又好的
一直是 Neural IR 的研究热点。目前来看,改进
主要有两条路线可走,其中一条路线是改变 batch 内的样本组合,让模型能够获取更丰富的对比信息:
然而,这三种策略都在原始的
的基础上增加了额外的计算成本,并且实现都比较复杂。除此之外,我们也可以利用知识蒸馏(knowledge distillation)为模型提供更优质的监督信号:
优化模型的监督信号: 我们可以将表达能力更强但运行效率更低的
或
当作 teacher model 来为
提供 soft label。
在检索模型的训练中,知识蒸馏的损失函数有很多可能的选择,本文仅讨论 pairwise loss 和 in-batch negative loss,其中 in-batch negative loss 在 pairwise loss 的基础上将 batch 内部其他 query 的负样本也当作当前 query 的负样本,这两类蒸馏 loss 的详细定义后文会讲。
本文同样是在上述两个方面对
做出优化,在训练过程方面,作者提出了 Balanced Topic Aware Sampling(TAS-Balanced) 策略来构建 batch 内的训练样本;在监督信号方面,作者提出了将 pairwise loss 和 in-batch negative loss 结合的 dual-supervision 蒸馏方式。
Dual Supervision
越来越多的证据表明知识蒸馏能够带来稠密检索模型性能的提升,本文将
提供的 pairwise loss 和
提供的 in-batch negative loss 结合起来为
提供监督信号,下面先简单介绍一下 teacher model 和 student model。
是当前应用最为广泛的排序模型,它简单地将 query 和 passage 的拼接作为
的输入序列,然后对
输出向量做一个线性变换得到相关性
打分:
是一个经典的多向量表示模型,它将 query 和 passage 之间的交互简化为 max-sum 来克服
无法缓存 passage 向量的问题,其基本思路是首先对 query 和 passage 分别编码
然后计算每个 query term 和每个 passage term 的点积相似度,按 doc term 做 max-pooling 并按 query term 求和获取 query 和 passage 的相似度:
虽然理论上
可以对 passage 建立离线索引,但存储 passage 多向量表示的资源开销是非常大的,并且该存储成本随着语料库的 term 数量呈线性增长,再加上 max-sum 的操作也会带来额外的计算成本,因此这里我们将
当作
的 teacher。
DPR 提出的
仅使用二元标签和 BM25 生成的负样本训练模型,
首先将 query 和 passage 独立编码为单个向量:
在检索阶段,
首先对 query 编码,然后利用 faiss 做最大内积检索,下表展示了在单个消费级 GPU 上 6 层 DistilBERT 在 800 万 passage 集合上的检索速度。
2.1 Dual-Teacher Supervision
如果仅看监督信号的质量,
提供的 in-batch negative loss 当然是最优质的。然而,
虽然在表达能力上比
更强,但它实际上很少用于计算 in-batch negative loss,因为
需要单独编码每个 query-passage 样本对,所以其计算开销随着 batch size 二次增长,而
解耦了 query 和 passage 的表示,因此它的开销是随着 batch size 线性增长的,其 in-batch negative loss 的计算效率要高得多。
因此这里我们只让
提供 pairwise loss,具体来说,我们首先利用训练好的
对训练集中所有的 query-passage 样本对打分,然后计算
的蒸馏损失,蒸馏损失的具体形式有很多选择,这里作者选择了 Margin-MSE loss 作为 pairwise loss:
我们同时让
提供 in-batch negative loss:
in-batch negative loss 中的
其实也可以替换成别的 loss,作者在后续实验中也尝试了一些看起来更有效的 listwise loss,然而实验结果表明 Margin-MSE loss 依旧是最佳的选择。因此,作者最终提出的蒸馏 loss 是 pairwise loss 和 in-batch negative loss 的加权平均,在后续实验中,作者设加权系数
:
Balanced Topic Aware Sampling
在原始的
的训练中,我们首先随机地从 query 集合
中采样
个
,然后再为每个
随机采样一个正样本
和一个负样本
组成一个 batch:
其中
表示从集合
无放回地采样
个样本。由于训练集是非常大的,每个 batch 中的
几乎都是没有相关性的,但是当我们计算 in-batch negative loss 时,query 不仅和自身的
交互,也和别的 query 对应的
交互,然而,由于
对模型来说大概率是简单样本,因此它所能提供的信息增益是非常少的,这也导致了每个 batch 所能提供的信息量偏少,使得检索模型需要长时间的训练才能收敛。
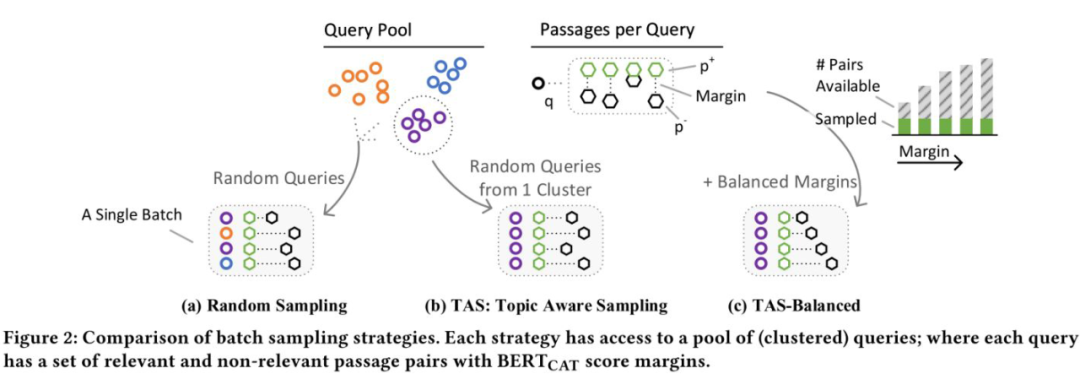
针对这个问题,作者提出了 Topic Aware Sampling(TAS)策略来构建 batch 内的训练样本,具体来说,在训练之前,我们先利用 k-means 算法将 query 聚类到 k 个 cluster 中:
其中 query 的表示
由基线模型
提供,
为
的聚类中心,这样,每个 cluster 中的 query 都是主题相关的,在构建 batch 的时候,我们可以先从 cluster 的集合
中随机抽样
个 cluster,然后在每个 cluster 上随机抽样
个 query
:
在后续的实验中,作者为 40 万个 query 创建了
k=2000
个 cluster,并设 batch size 大小为 b=32,组建 batch 时随机抽样的 cluster 数量为 n=1,这样,每个 batch 中的样本都来自于同一个 cluster。如下图所示,相比于在整个 query 集合上随机抽样,TAS 策略生成的 batch 内部的 query 有更高的主题相似性。
3.2 TAS-balanced
在组建 batch 的时候,我们还需要为每个采样到的 query 配置正负样本对
。不难想到,几乎所有 query 对应的
都比
少得多,如果用独立随机抽样的方式获取
和
,那么组成的
的 margin(也就是 )大概率是很大的,因此大部分
对模型来说是简单样本,因为模型很容易将
和
分开。
因此,我们可以在 TAS 策略的基础上进一步均衡 batch 内正负样本对的 margin 分布以减少 high margin(low information)的正负样本对。具体来说,针对每个 query,我们首先计算它对应的样本对集合的最小 margin 和最大 margin,然后将该区间分割为
个子区间,在为 query 配置
时,我们首先从这
个子区间中随机选择一个子区间,然后从 margin 落在该子区间内的
集合中随机采样并组成一个训练样本:
这样,在构建一个 batch 的时候,我们首先需要采样一个 cluster,然后采样 b
个 query,接下来为每个 query 采样一个 margin 子区间,最后在该子区间上采样一个正负样本对,这整套流程就是所谓的 TAS-balanced batch sampling:
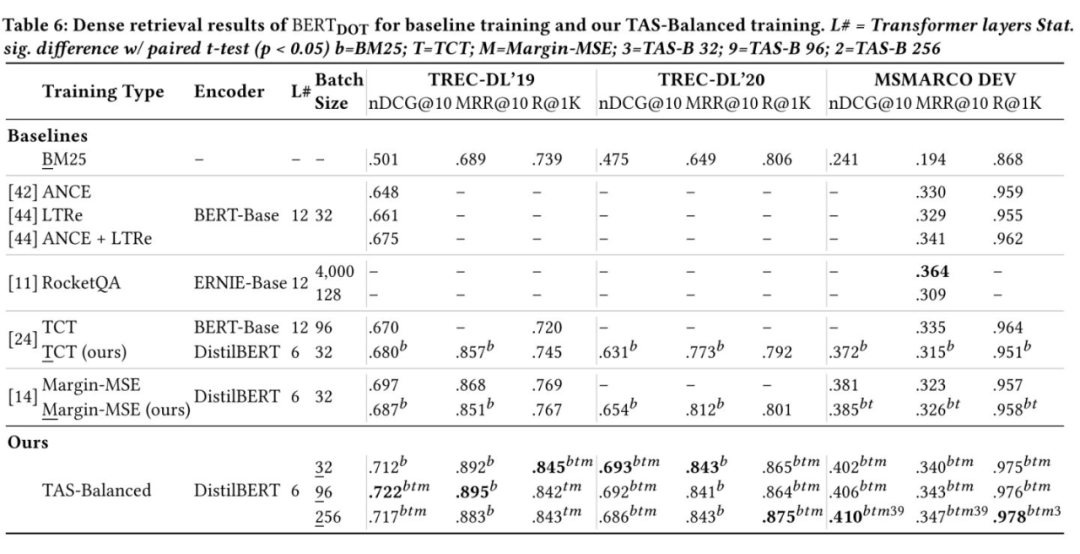
需要注意的是,TAS-balanced 策略不会影响模型的训练速度,因为 batch 的构建是可以并行处理或者预先处理好的。TAS-balanced 策略组建的 batch 对模型来说整体的难度更大,因此为模型提供了更多的信息量,即使采用较小的 batch size,模型也能很好地收敛。如下表所示,我们可以在消费级显卡上(11GB 内存)高效地训练
而不需要昂贵的 8×V100 的配置,因为该方法不需要像 ANCE 那样重复刷新索引,也不需要像 RocketQA 那样进行超大批量的训练。
作者选择 MSMACRO-Passage 官方提供的 4000 万正负样本对作为检索模型的训练集,并选择 MSMACRO-DEV(sparsely-judged,包含 6980 个 query)和 TREC-DL 19/20(densely-judged,包含 43/54 个 query)作为验证集。同时
和
均采用 6 层的 DistilBERT 初始化,且没有使用预训练的检索模型。
Results
4.1 Source of Effectiveness
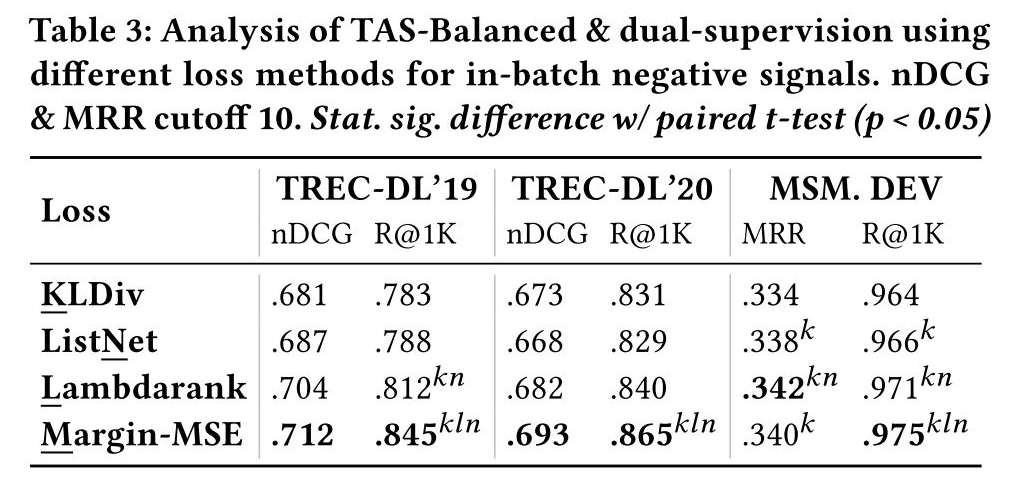
首先我们对作者提出的 Dual-supervision 做消融实验,如下表所示。对于基于 pairwise loss 的知识蒸馏,Margin-MSE loss 的优越性已经被之前的论文证明,所以这里仅讨论 in-batch negative loss 的有效性。作者对比了基于 listwise loss 的 KL Divergence、ListNet 和 Lambdarank,实验结果表明这些损失的效果都不如 Margin-MSE loss,尤其是在 R@1K 上面。
为什么 pairwise 的 Margin-MSE 比 listwise loss 更好呢?因为 Margin-MSE 不仅仅是让模型去学习 teacher 所给出的排序,同时还学习 teacher score 的分布,由于 batch 内部样本的 order 实际上是有偏的,它并不能准确刻画样本间的真实距离,因此比起学习 order,学习 score 分布其实是一种更精确的方式。另外,由于 teacher 和 student 在训练阶段所使用的损失是一致的,这也会让 student 更容易学习到 teacher 的 score 分布。
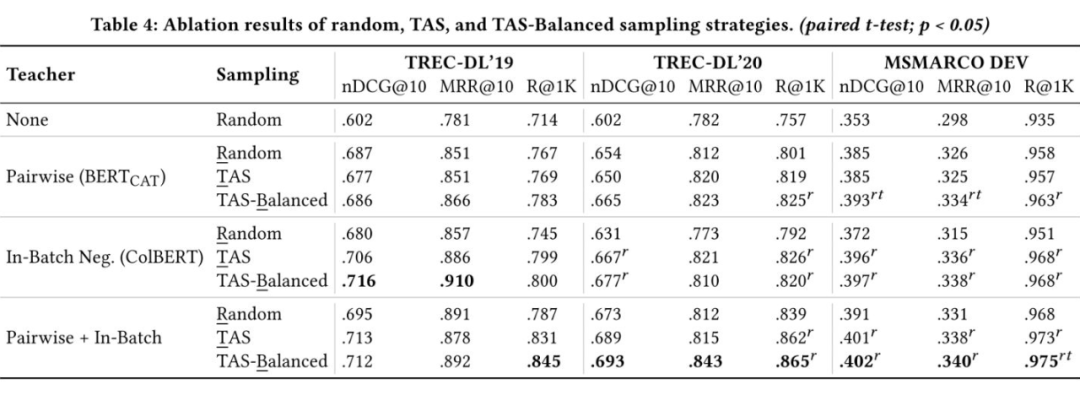
接下来我们对 TAS-Balanced 策略做消融实验,如下表所示。总体来说,TAS-balanced 策略加上 Dual-supervision 蒸馏可以在各个数据集上取得最优性能。值得关注的是,在单独的 pairwise loss 的监督下使用 TAS 策略其实并不能带来明显的提升 ,这是因为 TAS 是面向 in-batch negative loss 设计的,使用 pairwise loss 训练时,batch 内的样本是没有交互的,因此 TAS 也就不会起作用。而 TAS-balanced 策略会影响正负样本对的组成方式,因此会对 pairwise loss 产生一定的影响。
4.2 Comparing to Baselines
下表对比了作者的模型和其他模型的性能,对比最后三行,我们可以发现一个有趣的现象:增大 batch size 在 TREC-DL 这类 densely-judge 的数据集上没有带来提升,但在 MSMACRO-DEV 这类 sparsely-judge 的数据集上会带来持续的提升。 因此作者猜想增大 batch size 会导致模型在 sparsely-judge 的 MSMACRO 上过拟合,RocketQA 的 SOTA 表现可能仅仅是因为它的 batch size 够大。
4.3 TAS-Balanced Retrieval in a Pipeline
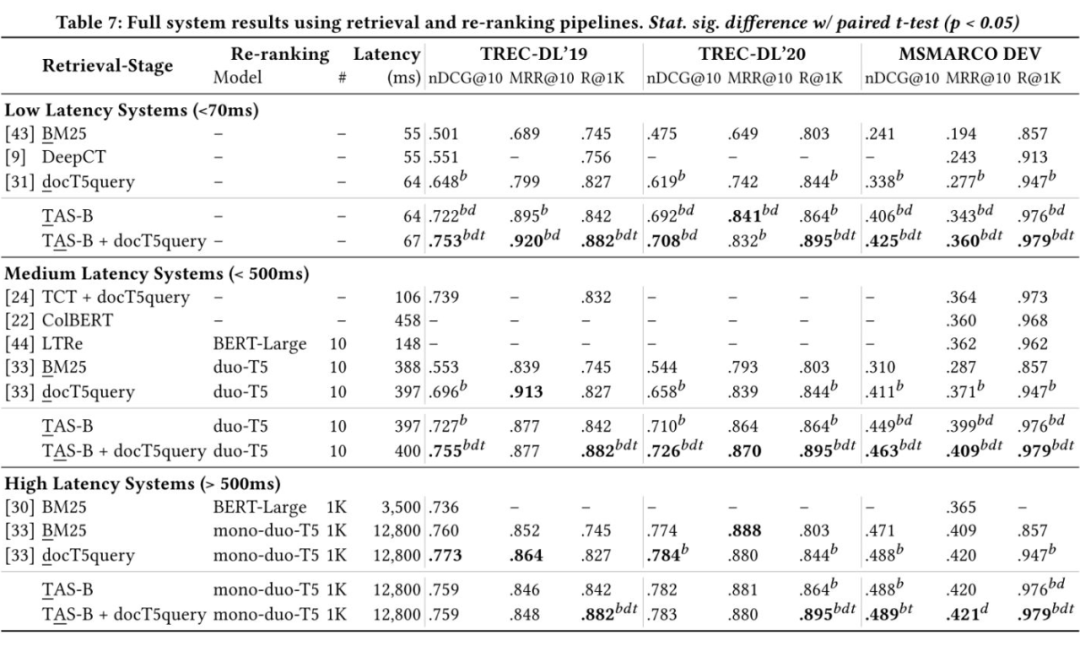
为了进一步证明方法的有效性,作者尝试将 TAS-Balance 训练的检索模型应用到召回-排序系统中。众所周知,稠密检索和稀疏检索是互补的,且融合稀疏检索几乎不会影响召回速度,因此作者考虑将稀疏检索的 docT5query 的检索结果和 TAS-balanced 稠密检索模型的结果融合,然后使用最先进的 mono-duo-T5 排序模型对检索结果做重排。
选择不同的召回模型、排序模型和不同大小的候选集,我们可以得到不同延迟水平的检索系统。如上表所示,作者提出的模型在各个延迟水平上均取得了优异的表现。值得注意的是,在高延迟系统中,排序模型 mono-duo-T5 是在 BM25 的召回结果上训练的,这实际上会导致训练测试分布不一致 的问题,所以 TAS-B+mono-duo-T5 甚至没能超越 BM25+mono-duo-T5,为了取得更好的性能,我们应该先训召回模型,然后在召回模型的给出召回结果上训练排序模型,这其实也间接反映了当前的排序模型泛化性不足的问题。
Discussion
本篇论文最大的亮点是 TAS-Balanced 策略的高效性,使用作者的模型,我们仅需要在单个消费级 GPU 上从头训练 48 小时就能取得 SOTA 结果,极大地降低了检索模型的训练成本,这在之前是无法想象的。实际上,比起 NLP 社区,IR 社区更加强调模型和数据的 Efficiency,这一课题在将来也一定会受到持续的关注。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧