

近年来,预训练模型在自然语言处理领域蓬勃发展,旨在对自然语言隐含的知识进行建模和表示,但主流预训练模型大多针对英文领域。中文领域起步相对较晚,鉴于其在自然语言处理过程中的重要性,学术界和工业界都开展了广泛的研究,提出了众多的中文预训练模型。文中对中文预训练模型的相关研究成果进行了较为全面的回顾,首先介绍预训练模型的基本概况及其发展历史,对中文预训练模型主要使用的两种经典模型Transformer和BERT进行了梳理,然后根据不同模型所属类别提出了中文预训练模型的分类方法,并总结了中文领域的不同评测基准,最后对中文预训练模型未来的发展趋势进行了展望。旨在帮助科研工作者更全面地了解中文预训练模型的发展历程,继而为新模型的提出提供思路。
1 引言
自然语言处理(NaturalLanguageProcessing,NLP)是计 算机利用人类定义的算法对自然语言形式的输入进行加工处 理的过程,旨在让计算机可以像人类一样理解和生成语言,具 备如人类一样的听、说、读、写、问、答、对话、聊天等的能力,并 利用已有知识和常识进行推理分析.自然语言处理技术的发 展经历了从基于规则到基于统计的过程.随着深度学习的发 展,图像、文本、声音、视频等不同形式的信息载体被自然语言 处理技术突破,大量的神经网络被引入自然语言理解任务中, 如循环神经网络1、卷积神经网络2、注意力 机制3等.在特定的自然语言处理任 务中,神经网络可以隐性地学习到序列的语义表示与内在特 征,因此,神经网络成为了解决复杂自然语言处理任务最有效 的方法.随着计算力的不断增强,深度学习在自然语言处理 领域中不断发展,分布式表示占据了主导地位,不仅在指定任 务中可以端到端地学习语义表示,而且可以在大规模无标注 的文本上进行自主学习,能更灵活地运用在各种下游任务中. 然而,早期在有监督数据上训练浅层模型往往存在过拟合和 标注数据不足等问题,在训练深层模型参数时,为了防止过拟 合,通常需 要 大 量 的 标 注 数 据,但 有 监 督 的 标 注 数 据 成 本较高,因此模型主要利用网络中现存的大量无监督数据进行 训练.在此背景下,预训练技术被广泛地应用在自然语言处 理领域.其中,最经典的预训练模型是 BERT [4]模型,在多个 自然语言处理任务中取得了最好结果(StateoftheArt,SOG TA).此后出现了一系列基于 BERT 的预训练模型,掀起了 深度学习与预训练技术的发展浪潮。
随着国内外研究者在预训练模型方面的深入研究,目前 已有很多关于预训练模型的综述,但缺少专门针对中文领域 的相关综述.当前,中文预训练模型蓬勃发展并取得一定的 成绩,因此,对现有研究成果进行全面的分析和总结非常必 要.本文期望能为中文预训练相关领域的学者提供参考,帮 助科研工作者了解目前的研究现状和未来的发展趋势.本文 第2节概述预训练模型的基本情况;第3节主要介绍两种基 本模型,即 Transformer和 BERT;第4节根据不同模型的所 属类别提出典型的中文预训练模型的分类方法,并汇总了中 文预训练模型的相关资源;第5节梳理了中文领域的不同评 测基准;最后总结全文并展望未来.
2 预训练模型
2.1 预训练模型发展史
从预训练语言模型的发展时间来看,可以将其分为静态 预训练模型和动态预训练模型.2013年,Mikolov等[5]在神 经网络语言模型(NeuralNetworkLanguageModel,NNLM) 思想的基础上提出 Word2Vec,并引入大规模预训练的思路, 旨在训练具有特征表示的词向量,其中包括 CBOW 和 SkipG Gram 两种训练方式.相比 NNLM 模型,Word2Vec可以更 全面地捕捉上下文信息,弥补 NNLM 模型只能看到上文信息 的不足,提高模型的预测准确性,Word2Vec极大地促进了深 度学习在 NLP中的发展.自 Word2Vec模型被提出以来,一 批训练词向量的模型相继涌现,例如,Glove [6]和 FastText [7] 等模型均考虑如何得到文本单词较好的词向量表示,虽然对 下游任务性能有所提升,但其本质上仍是一种静态的预训练 模型.
2018年,Peters等[8]提出的 ELMo模型将语言模型带入 动态的预训练时代.ELMo模型采用双层双向的 LSTM [9]编 码器进行预训练,提取上下文信息,并将各层词嵌入输入特定 下游任务中进行微调.该模型不仅可以学习到底层单词的基 础特征,而且可以学到高层的句法和语义信息.然而,ELMo 模型只能进行串行计算,无法并行计算,模型训练的效率较 低;此外,该模型无法对长序列文本进行建模,常出现梯度消 失等问题.而 后,OpenAI提 出 了 GPT(GenerativePreGtraiG ning)[10]模 型.与 ELMo模 型 不 同,GPT 采 用 Transformer 深度神经网络,其处理长文本建模的能力强于 LSTM,仅使用 Transformer解码器进行特征提取,在机器翻译等生成式任务 上表现惊人,但这一特点也导致 GPT 只利用到了当前词前面 的文本信息,并没有考虑到后文信息,其本质上依旧是一种单 向语言模型.为了解决 GPT等模型单向建模的问题,2018年, Devlin等[4]提出了 BERT 模型,该模型是第一个基于 Transformer的 双 向 自 监 督 学 习 的 预 训 练 模 型,在 英 文 语 言 理解评测基准[11]榜单中的多个任务上达到了SOTA 结果,此 后出现了一大批基于 BERT的预训练模型,大幅提升了下游 自然语言处理任务的性能.中文预训练模型虽然起步较晚, 但发展迅速,已经取得了一定成果,本文第4节将对其进行重 点介绍.
**2.2 研究中文预训练模型的原因 **
首先,中文和英文分别是世界上使用人数最多和范围最 广的两种语言,然而在自然语言处理领域,英文预训练模型较 为普遍,例如,以 BERT 为首及其后出现的大量预训练模型 均是在单一语料英文数据集上进行训练,此外模型的设计理 念也更适用于英文,比如分词方式及掩码方式等.其次,中文 和英文语言本质上存在差异,它们的主要区别是,中文文本通 常由多个连续的字符组成,词与词之间没有明显的分隔符. 如果使用英文预训练模型去处理常见的中文任务,效果往往 不佳.因此,为了推动中文领域自然语言处理技术和预训练 模型在多语言任务方面的发展,构建以中文为核心的预训练 模型势在必行.
3 Transformer和 BERT
自2021年以来,中文预训练模型进入井喷式的发展阶 段,其架构主要基于 Transformer和 BERT 两种基础模型,本 节主要介绍这两种模型. 图1为典型的 Transformer架构,该架构由6个结构相 同的编码器和解码器堆叠而成.单个编码器由堆叠的自注意 力层和前馈神经网络组成,解码器由堆叠的自注意力层、掩码 注意力层 和 前 馈 神 经 网 络 组 成.有 关 Transformer的 详 细 细节介绍请参考文献[14].
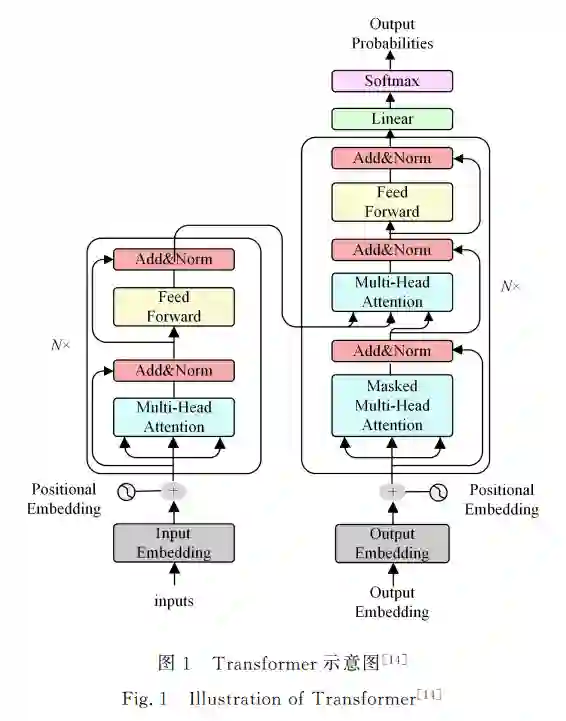
BERT
BERT [4] (Bidirectional Encoder Representations from Transformers)是由谷歌提出的一种面向自然语言处理任务 的无监督预训练语言模型,由 Transformer的双向编码器表 示.BERT的架构如图2所示.
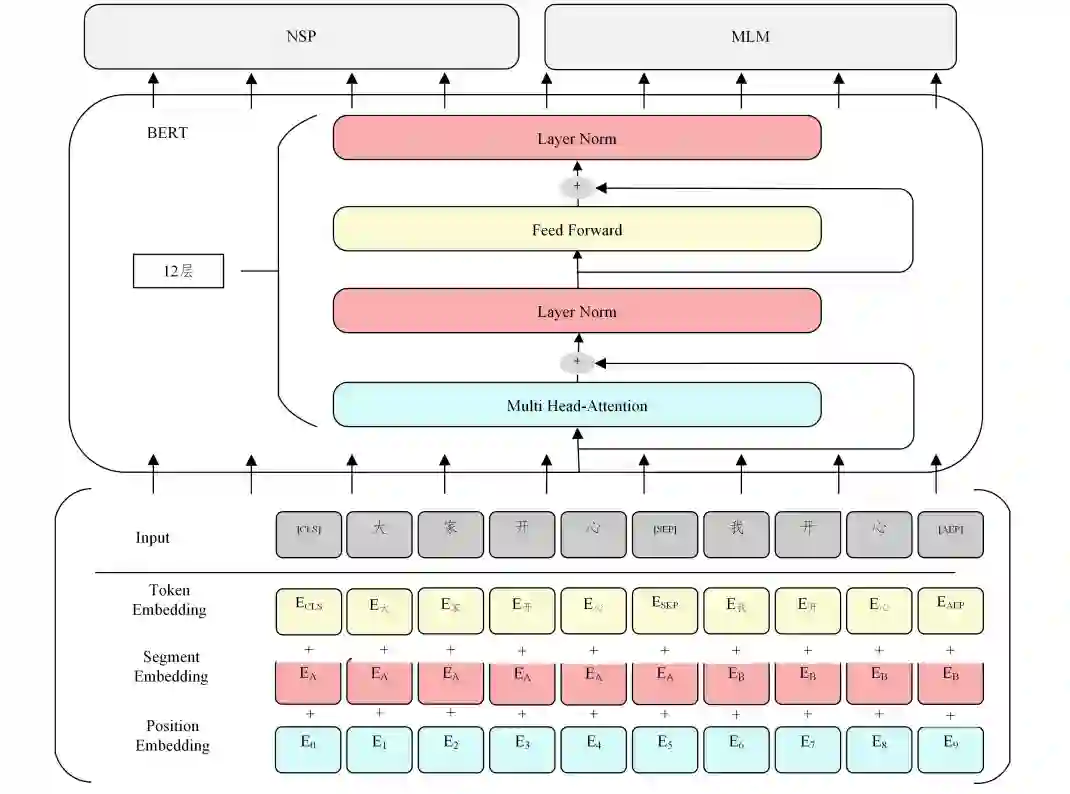
图2 BERT示意图[4]
4 中文预训练模型分类
**在自然语言处理领域,继 Transformer和 BERT 出现之 后,涌现出大量的预训练模型,这些模型主要针对英文领域, 中文领域的研究起步较晚.但在近两年,中文预训练模型受 到广大学者的关注并取得了一定的研究成果.为了阐明现有 的中文预训练模型,本节主要从以下6个方面对现有的预训练 模型进行分类,图3展示了典型的中文预训练模型的分类图. (1) 预训练模型的方法改进,主要包括掩码方式的转变、 位置编码的转变、LN 层的位置变化、MoE 层的使用、多粒度训练和其他改进. (2) 融入外部信息的预训练,主要包括命名实体、知识图 谱、语言学知识和特定知识.(3) 关于多模态融合的预训练模型. (4) 侧重于高效计算的预训练,主要包括数据处理阶段、 预训练阶段以及技术优化. (5) 指特定领域的预训练,主要包括对话系统和其他领域 的预训练模型. (6) 介绍一些其他变体,主要侧重于典型的英文预训练模 型开源的中文版本.
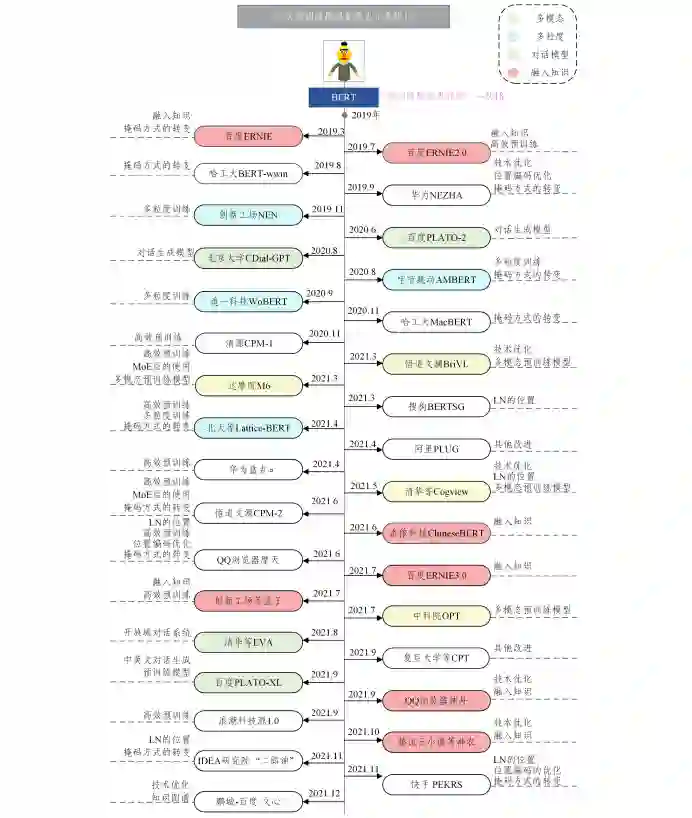

图3 中文预训练模型分类图
5. 中文领域的评测基准
5.1 为什么建立中文领域的评测基准
首先,从使用人数上看,中国人口占世界人口的五分之 一,人数庞大,因此中文是世界上使用人数最多的语言;其次, 从语言体系上看,中文与英文差异较大;最后,从数据集角度 出发,中文领域公开可用的数据集较少,此前提出的中文预训 练模型在英文评测基准上评估,无法完全体现出模型性能. 当下预训练模型的发展极其迅速,英文领域的评测基准已步 入成熟阶段,而中文领域的缺失必然会导致技术落后,因此中 文领域的评测基准必不可少.本节主要介绍4种不同的评测 基准.

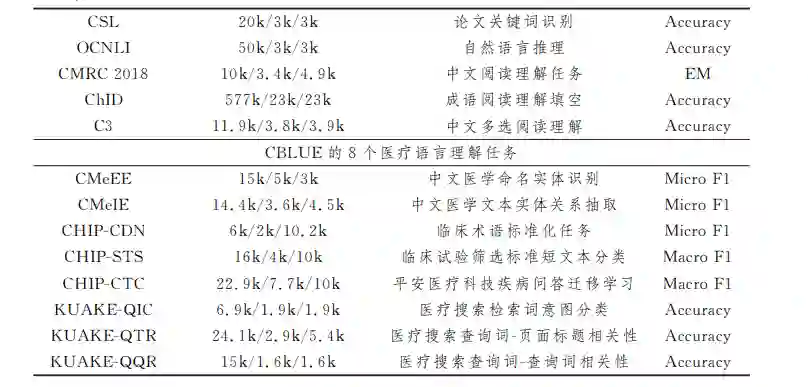
6 研究趋势与展望
中文预训练模型已在多个领域实现商业化落地,并展现出一定的市场潜力,取得了长足发展,但也存在较多挑战,例 如预训练模型规模和性能之间的平衡问题;如何构建更加通 用型的预训练模型;如何突破现有多模态和轻量化模型的瓶 颈;如何构建融入更多中文特色的预训练模型等.本文主要 从以下几个方面对未来进行展望.
6.1 规模随着以 BERT和 GPT等为代表的大规模预训练模型的 出现,逐渐掀起了预训练模型朝大规模方向发展的浪潮.大 量的研究表明,模型参数量越大,训练数据量越多的预训练模 型表现更出色.中文领域存在众多大规模预训练模型,如源 1.0参数 2457亿,训练数据集达5000GB;ERNIE3.0Titan 参数2600亿;中文多模态模型 M6参数量已经扩展至十万亿 级别.目前预训练模型还未达到模型的性能极限,增大模型 参数量和训练数据仍是提高模型性能最有效的手段,探索超 大规模预训练模型的道路还将继续,也需要更加注重模型的 创新性、训练的低碳化和应用的高效性. 然而,训练超大规模的模型仍存在很大挑战.首先,使用 最大 GPU 也不可能在内存中拟合所有参数;其次,算法优化 不足会耗费极长的训练时间;最后,搭建超大规模模型会带来 巨大的成本,让学术界和小型科技公司望而却步.如何在模 型性能和成本之间取得平衡也是当前学者探索的另外一条道 路,如探索轻量化的预训练模型.近期腾讯提出的“神农”、澜 舟科技提出的“孟子”及IDEA 研究院提出的“二郎神”等轻量 化模型,仅以十亿左右的参数量就在部分任务上达到了 SOG TA 结果,因此探索轻量化模型势在必行.
6.2 融入外部信息预训练模型在部分任务上已无限接近人类,甚至超越人 类,然而,其对知识的掌握依旧不足,如何让预训练模型真正 理解并运用知识是一个值得长期研究的课题,尤其是中华民 族上下五千年形成的文化知识颇多,比如“常识性知识”和“特 定领域的知识”等.特定领域的知识可以帮助模型挖掘不同 领域特有的知识,如果能够将特定领域的行业知识与模型结 合起来训练,不仅可以将预训练模型更广泛地应用到不同的 下游任务,在各行各业中实现良好的产业落地,而且可以与脑 科学、心理学、神经学等其他学科融合,更好地发展人工智能, 服务人类生活. 除了融入知识信息之外,还可以从中文字形和字音等方 面考虑.因为中文语言的特殊性,其字符的符号也包含一些额外信息,这些额外信息能增强中文自然语言的表现力,如 ChineseBERT [46]模型中提出将中文字形和拼音信息融入预 训练模型中,以此增强模型对中文语料的建模能力,但这一方 向的研究还相对较少,仍有待完善.
6.3 多模态领域现实世界离不开语言,语言离不开语音和视觉信息,类似 于人的感觉器官:眼、耳、嘴,任何一样的缺失都会影响生活. 当前,互联网音视频资源占比较大,纯文本信息只能覆盖互联 网资源的一小部分,更加丰富的音视频信息并没有被充分利 用,因此预训练模型必然朝着多模态的趋势发展.目前,多模 态预训练模型的研究大多只考虑了两种模态,图像文本或者 视频文本,而音频信息大多被忽视.中文预训练模型起步虽 晚,但成绩斐然.中科院自动化所提出了全球首个图文音(视 觉G文本G语音)三模态的预训练模型 OPT [51],该模型同时具 备跨模态理解与生成的能力.通过上述分析可知,多模态的 研究拥有很大的发展空间.
本文主要围绕中文预训练模型的研究现状进行概述.从模型规模上看,中文预训练模型的发展正处于两条 道路上.一是朝着超大规模预训练模型的方向发展;二是寻 求轻量化模型的发展.从外部信息来看,大多数的预训练模 型都融入了各种知识,预训练与先验知识的深度融合刻不容 缓.从高效训练上看,现有模型都在不断地探索更加高效的 训练方式.从多模态的角度上看,中文多模态预训练模型的 发展正处于上升阶段,正朝着更多模态、更加通用的方向发 展.从特定领域的模型来看,预训练模型可应用于多种领域, 具有较大的发展潜力.综上所述,中文预训练模型虽然取得 了不可忽视的成绩,但还有更大的发展空间,未来将朝着更大 规模、更加高效、适用更多领域的方向发展.


