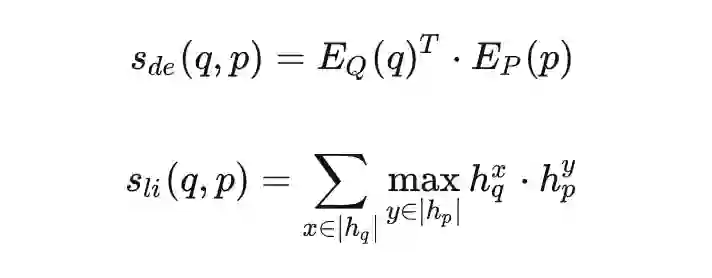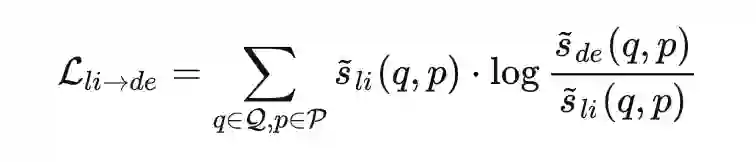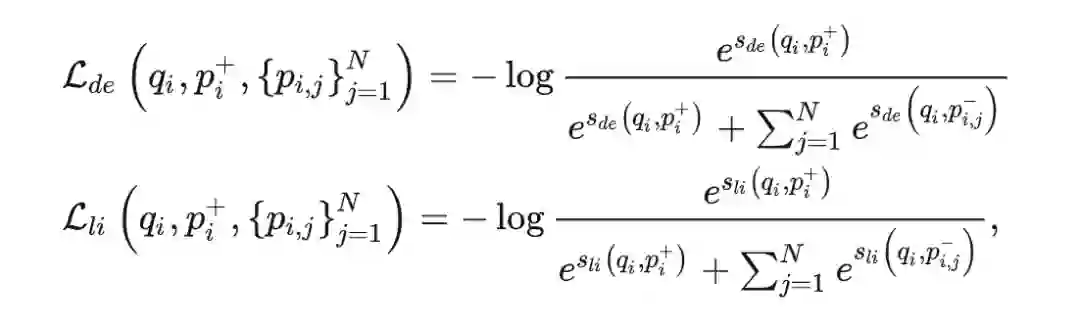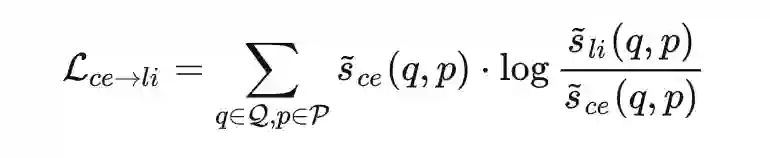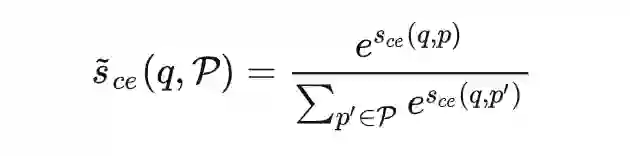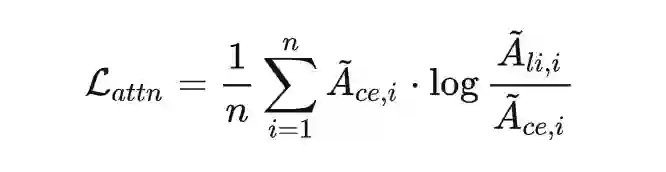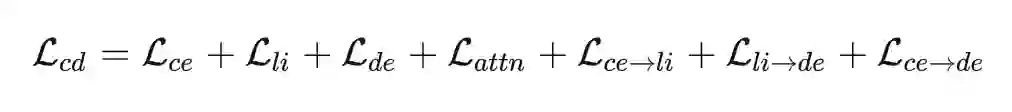![]()
©PaperWeekly 原创 · 作者 | Maple小七
单位 | 北京邮电大学
研究方向 | 自然语言处理
![]()
ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval
论文链接:
http://arxiv.org/abs/2205.09153
Introduction
由无论是在工业界还是学术界,
知识蒸馏 (Knowledge Distillation, KD)
都是一个很常见的模型压缩和涨点刷分手段,以 Hinton 范式为代表的传统知识蒸馏通常会假设 teacher 和 student 有着相同的模型结构,其中 teacher 通常有着更多的模型层数和更大的隐层维度。在知识蒸馏的过程中,蒸馏损失的设计通常与任务相关,但其基本思想是最小化 student 和 teacher 预测结果的差异。
一些早期的针对大规模预训练语言模型的知识蒸馏工作,比如 DistilBERT、TinyBERT 和 MobileBERT,通常会在最小化模型输出结果差异的基础上,加入额外的
隐层特征一致性损失
和
注意力分布一致性损失
,从而提升 teacher 模型的知识转化率,得到性能更优的 student 模型。
然而,在针对稠密检索模型的知识蒸馏的相关研究中,虽然目前已经有很多工作尝试过将表达能力更强的交互模型 (Cross-Encoder) 或延迟交互模型 (ColBERT) 蒸馏到推理速度更快的双塔模型 (Dual-Encoder) 中,实验结果也充分证明了知识蒸馏对于双塔模型训练的有效性,但是这些工作均采用的是
跨结构知识蒸馏 (cross-architecture paradigm)
,即 teacher (Cross-Encoder) 和 student (Dual-Encoder) 的模型结构有较大差异。
另外,模型结构的天然差异也导致了目前的工作均采用了仅蒸馏模型顶层 logits 输出的蒸馏损失,而没有考虑蒸馏 teacher 和 student 模型的隐层特征或注意力分布。
基于此,一个自然的问题是,
当 teacher 和 student 的模型结构存在差异时,传统的知识蒸馏的效果是否会打折呢?如果会的话,我们应该如何去设计一个更有效的知识蒸馏范式呢?
针对这个问题,本文提出了两个面向稠密检索模型的蒸馏策略:
交互蒸馏 (Interaction Disitllation) 和级联蒸馏 (Cascade Distillation)
,如果将这两个蒸馏策略结合起来,就得到了该论文标题中提到的名词:
动态自蒸馏 (self on-the-fly distillation)
。由于是度厂出品,采用该蒸馏策略的训练得到的模型被命名为
ERNIE-Search
,ERNIE-Search 在 MARCO 和 NQ 检索数据集上均取得了 SOTA 性能(虽然没出几天就被超越了)。
Methodology
在之前的工作中,Cross-Encoder 和 ColBERT 是两类常见的 teacher 模型结构,虽然前者表达能力更强,但由于其计算复杂度过高,人们通常采用样本间无交互的 MSE 或 MarginMSE 损失进行知识蒸馏,而后者与 Dual-Encoder 的接近程度更高,因此可以采用基于批内负样本的对比损失蒸馏策略。关于这部分背景知识更详细的介绍,读者可以参考 TAS-B 中针对多 teacher 知识蒸馏的讲解。
从
数学层面上来讲,Cross-Encoder 是完全可以被 Dual-Encoder 所拟合的(可参考特征式匹配与交互式匹配有多大差距?
中给出的数学证明)。
但由于归纳偏差的存在,Cross-Encoder 中存储知识的结构与 Dual-Encoder 是完全不一样的,比如 Dual-Encoder 对于语义相关性的建模就是简单的点积,对语义相关性有着更强的连续性先验,而 Cross-Encoder 对于语义相关性的建模是蕴含在 token 级交互信息中的,我们无法知晓 Cross-Encoder 内部具体是通过什么机制来建模相关性的。
2.1 Interaction Distillation
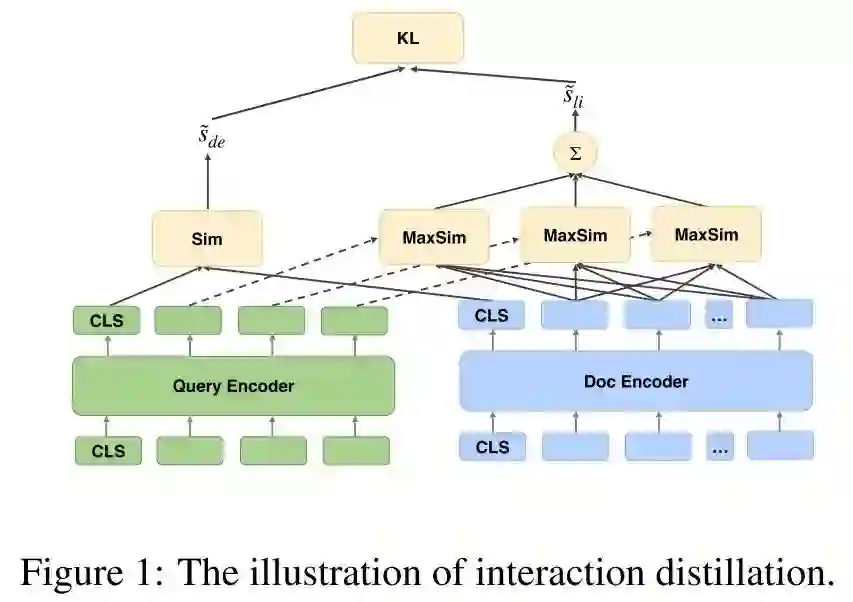
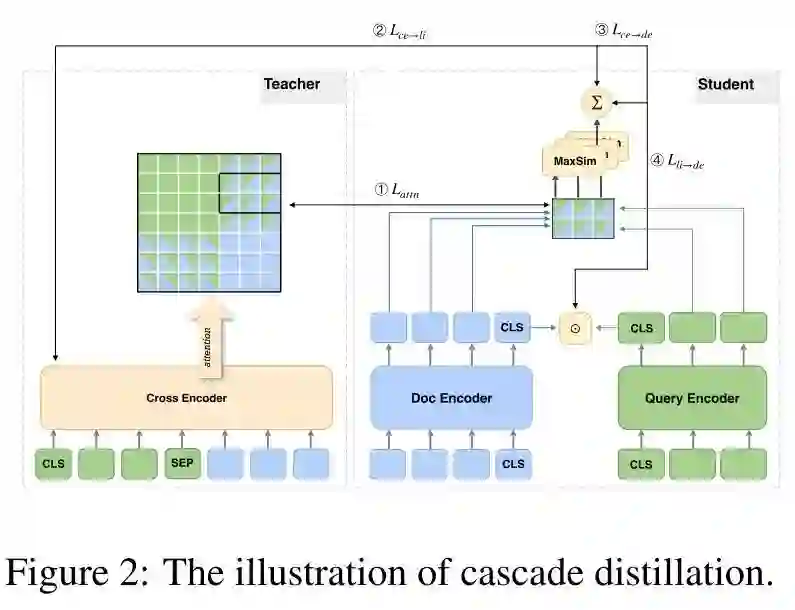
既然我们难以将 Cross-Encoder 中的知识完美迁移到 Dual-Encoder 当中,那如果我们从一开始就让 Cross-Encoder 和 Dual-Encoder 共享同一套模型结构和模型参数呢?据此,本文提出了一种新的蒸馏方式:Interaction Distillation,该方式的核心思想就是将 teacher 和 student 集成到同一个模型中,共享同一套参数,从而有效避免了 teacher 和 student 表示知识的方式不一致的问题。
作者发现,当我们将 ColBERT 作为 teacher 时,这一思路有一种很简单的实现方式。如上图所示,由于 ColBERT 和 Dual-Encoder 的相关性建模均发生在顶层,我们可以自然而然地共享它们的底层参数,当输入的 query 和 document 均被编码为低维稠密向量后,我们可以分别计算 Dual-Encoder 的 Dot-Product 相关性和 ColBERT 的 MaxSim 相关性打分:
![]()
本文提出的 Interaction Distillation,其实就是让这里的
和
分布尽量一致,这里作者选择采用 KL 散度来衡量分布的一致性:
![]()
但是训练模型光有一致性损失还不够,当我们共享 Dual-Encoder 和 ColBERT 参数时,
仅仅是一个正则项而已,我们依旧需要引入监督信号用于 Dual-Encoder 和 ColBERT 打分的训练:
综上,作者提出的 Interaction Distillation 实际上就是将 ColBERT 的 MaxSim 打分作为了一个辅助信号来引导 Dual-Encoder 的训练,这一结构有效地避免了 Dual-Encoder 和 ColBERT 内部知识表示不一致的问题。另外,这一结构也不需要像传统的知识蒸馏那样,需要先训好一个 teacher,再训 student,该结构可以通过一次正反向传播同时训练 teacher 和 student。
在知识蒸馏的相关研究中,人们发现当 teacher 和 student 的模型尺寸差异过大的时候,student 的性能反倒会下降。也就是说,BERT-xxlarge→BERT-small 的效果通常比 BERT-largeBERT-small 的效果差。这一现象虽然匪夷所思但也不是完全没有道理,就好比大学教授给小学生上课,很多在 teacher 眼中理所应当的知识,在 student 眼中可能就不知所云了。
因此,本文在 Interaction Distillation 的基础上,进一步提出了 Cascade Distillation。顾名思义,该策略的思想就是将 ColBERT 当作助教(teacher assistant),将 Cross-Encoder 当作教师,执行如下的两阶段蒸馏策略:Cross-Encoder→ColBERT→Dual-Encoder。
那么 Cross-Encoder 蒸馏 ColBERT,是不是也可以采用上面提到的 Interaction Distillation 策略呢?很遗憾,作者并没有想到一个可以兼容这两者的结构,因为 Cross-Encoder 和 ColBERT 的结构有着本质的区别,若将底层的编码器换成交互式结构,那么 ColBERT 顶层的 late inteaction 结构是没有意义的。因此,作者提出的 Cascade Distillation,本质上其实就是额外引入 Cross-Encoder 的蒸馏损失来进一步辅助 Dual-Encoder 的训练,使得知识可以从 Cross-Encoder 逐步传递到 Dual-Encoder。
首先,我们计算 Cross-Encoder 的打分和 ColBERT 打分的 KL 散度:
![]()
另外,作者认为除了蒸馏 Cross-Encoder 的分数分布,Cross-Encoder 的 token 级交互信息也是很重要的知识来源,因此作者提出了一种蒸馏注意力分布的一致性损失:
![]()
![]()
这里的
和
分别表示的是 Cross-Encoder 和 ColBERT 顶层的注意力分布,的计算表示为,下标表示第个注意力头,和分别表示 query 和 passage 的长度。
最后,我们将之前的 Interaction Distillation 结合进来,就有了如下的损失函数:
其中
、
和
为对应模型的监督损失,
、
和
为蒸馏损失,注意这里还额外包括了传统的 Cross-Encoder 到 Dual-Encoder 的蒸馏损失:
![]()
这里列出的公式可能比较冗长,下面的图示会更直观一些:
另外,作者还借鉴了 SimCSE 和 R-Dropout 的思想,提出了针对双塔式模型的 Dual Regularization 正则项,其具体策略就是对 passage 做两次随机采样 dropout mask 的前向传播,得到 passage 的两个表示,然后分别和 query 计算打分得到
和
,并最小化这两个打分分布的双向 KL 散度。作者将该正则项运用到了 Dual-Encoder 和 ColBERT 上,并加到了之前的损失之中。
Experiments
3.1 Setup
作者在 MARCO 和 NQ 数据集上评测了模型的表现,其中 Dual-Encoder 的热启模型采用了 ERNIE 2.0-Base,Cross-Encoder 采用了 ERNIE 2.0-Large。另外作者采用了一套比较复杂的多阶段训练流程,大致可以分为一下三步:首先,在通用语料库上进行 coCondenser 预训练;然后,在下游任务上使用 PAIR 提供的训练数据和策略进行 Interaction Distillaion 训练;最后,在第二步得到的模型基础上,采用 Cascade Distillation 对模型做进一步的微调。
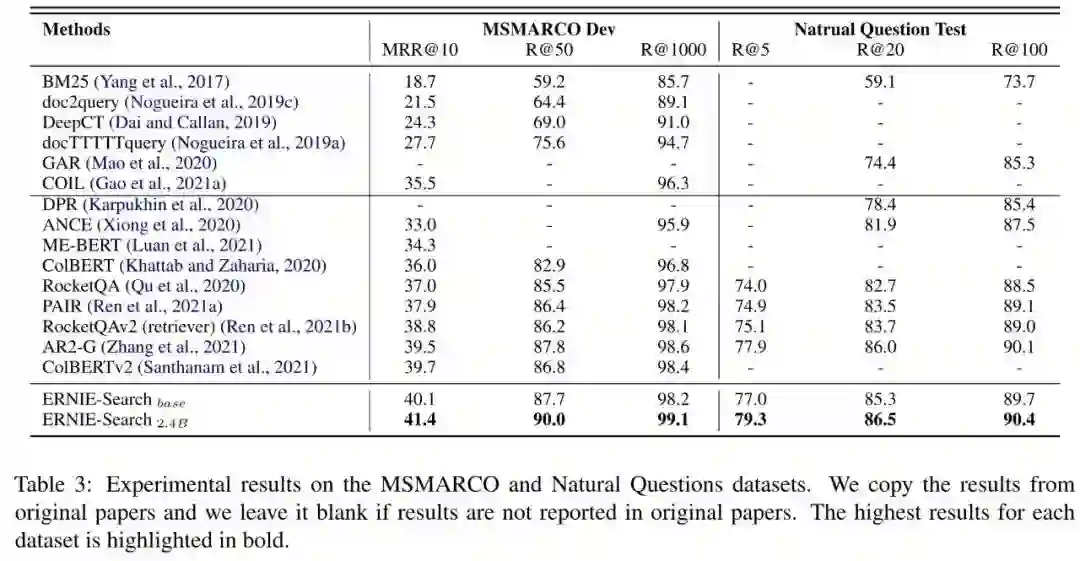
实验结果如下表所示,ERNIE-Search 在 MARCO Dev 数据集上的 MRR@10 突破了 40,取得了 SOTA 结果,当我们将参数量增大到 24 亿时,指标还会有进一步的提升,但是单看指标我们无法得知模型的增益来自于什么地方。
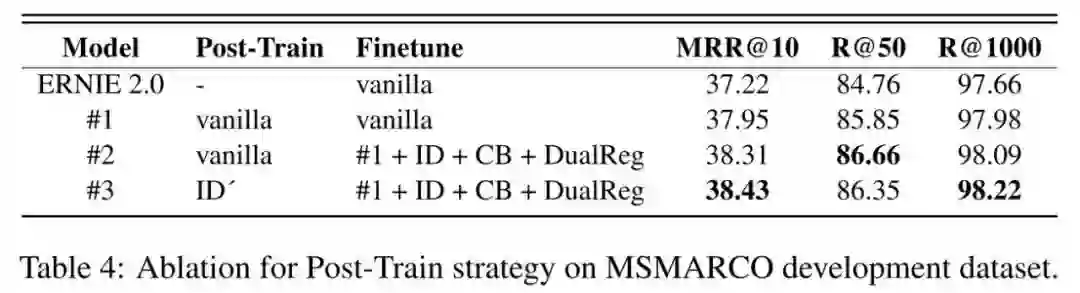
作者首先对 Post-Train 策略进行了消融实验,如下图所示,Vanilla Post-Train 表示 coCondenser 预训练,Vanilla Finetune 表示 DPR 原始的对比损失训练,ID 表示 Interaction Distillation,CB 表示 PAIR 中的 Cross-Batch 策略,ID' 表示 ID+CB,DualReg 表示前文提到的 Dual Regularization。该消融实验主要表明了将 ID' 策略加到 Post-Train 中是有效的,但需要注意这里作者并没有去掉 CB 策略单独对比 ID 策略。
![]() 3.3.2 Interaction Distillation
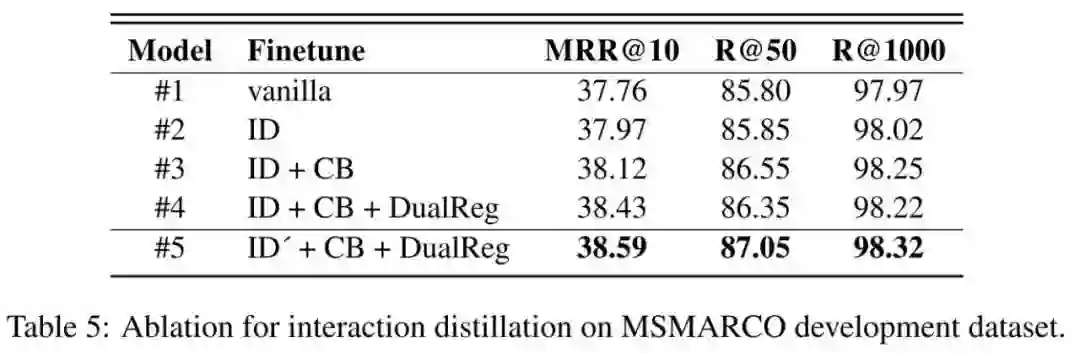
接下来,作者对 Interaction Distillation 策略进行了消融实验,如下表所示,可以看出作者提出的 Interaction Distillation 策略和 Dual Regularization 策略都能带来一定的性能提升,但是 ID 策略本身涨点并不显著,反倒是 CB 和 DualReg 看起来更有效。
3.3.2 Interaction Distillation
接下来,作者对 Interaction Distillation 策略进行了消融实验,如下表所示,可以看出作者提出的 Interaction Distillation 策略和 Dual Regularization 策略都能带来一定的性能提升,但是 ID 策略本身涨点并不显著,反倒是 CB 和 DualReg 看起来更有效。
![]()
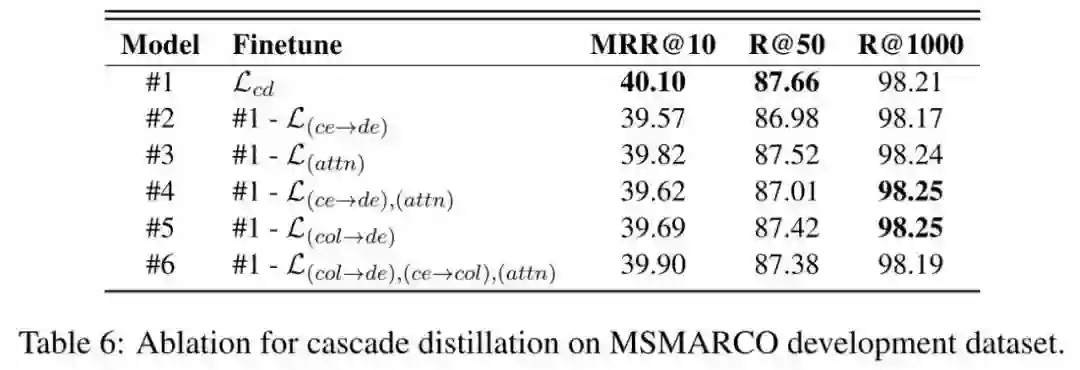
3.3.3 Cascade Distillation
最后,作者对最终的损失函数进行了消融实验,可以发现,去掉任何一个损失都会导致性能下降。但是去掉
性能下降最为严重,说明 Cross-Encoder 直接蒸馏 Dual-Encoder 在实践中其实是很有效的,而去掉作者提出的 Cascade 损失和 Attention Map 损失 ,MRR@10 仅下降了 0.2pp。
![]()
总结
总体来说,虽然本文的出发点较好,但损失设计和训练流程过于复杂,消融实验也做得不够诚恳,SOTA 性能的主要来源可能更多还是来自于 coConderser 预训练,PAIR 的微调策略以及 Large 版 Cross-Encoder 的使用,交互蒸馏和级联蒸馏的实用价值并没有满足本人的预期。
另外值得一提的是,本文的模型结构实际上和度厂之前发布的 RocketQAv2 很相似,即联合训练 Dual-Encoder 和 Cross-Encoder,而本文可以看作是在 RocketQAv2 的基础上加上了额外的 ColBERT 损失,但整体提升并不是很显著,有暴力调参的嫌疑。
因此,虽然本文的 Motivation 在于 Cross-Encoder 和 Dual-Encoder 的知识存储结构和表达能力存在较大差异,直接蒸馏 logits 可能会存在知识迁移效率低的情况,但实际上,在最终的实验结果中,作者提出的策略仅仅产生了不到 1pp 的波动,说明这个凭空假设的问题可能并不严重。所以,在做具体的模型优化工作的时候,还是要从具体的 badcase 入手,发现模型存在的具体问题,并提出针对性的解决策略,才是更好的模型迭代的方向。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()