超越 BERT 和 GPT,微软亚洲研究院开源新模型 MASS!
▲点击上方 雷锋网 关注


在序列到序列的自然语言生成任务中完胜 BERT!
文 | 杨鲤萍
雷锋网 AI 科技评论按:自 2018 年以来,预训练无疑是自然语言处理(NLP)领域中最热门的研究课题之一。通过利用 BERT、GPT 和 XLNet 等通用语言模型,该领域的研究者们在自然语言理解方面已经取得了许多重大的突破。然而,对于序列到序列的自然语言生成任务,这些主流的预训练方法并没有带来显著的改进,对此,微软亚洲研究院提出了一个全新的通用预训练方法——MASS,在该任务中可以得到比 BERT 和 GPT 更好的效果。
BERT 和 XLNet 在自然语言理解任务(例如:情感分类、自然语言推理和 SQuAD 阅读理解)方面取得了巨大成功。然而, NLP 领域除了自然语言理解任务之外,还存在很多序列到序列的语言生成任务,例如机器翻译、文本摘要生成、对话生成、问答、文本风格转换等。对于这些任务,使用编码器-注意力-解码器框架是主流方法。
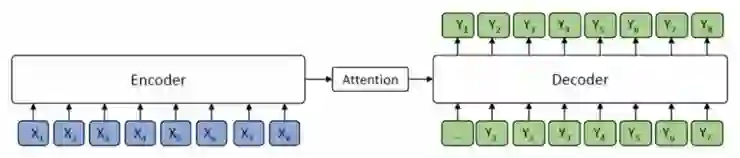
图 1 编码器 - 注意力 - 解码器框架
如图 1 所示,编码器将源序列 X 作为输入并将其转换为隐藏表示的序列,然后解码器通过注意力机制从编码器中抽象出隐藏表示的序列信息,并自动生成目标序列文本 Y。
BERT 和 XLnet 通常是对一个编码器进行自然语言理解的预训练;而 GPT 则是对一个解码器进行语言建模的预训练。当利用 BERT 和 GPT 进行序列到序列的语言生成任务时,我们通常需要对编码器和解码器分别进行预训练。在这种情况下,编码器 - 注意力 - 解码器框架和注意力机制并没有得到联合训练。然而,注意力机制在这类任务中极为重要,一旦缺失便会导致 BERT 和 GPT 无法达到最佳性能。
针对序列到序列的自然语言生成任务,微软亚洲研究院的机器学习小组提出了一种新的预训练方法,即掩蔽的序列到序列预训练(MASS:Masked Sequence to Sequence Pre-Training)。MASS 随机掩蔽一个长度为 k 的句子片段,并通过编码器 - 注意力 - 解码器框架预测这一被掩蔽的片段。
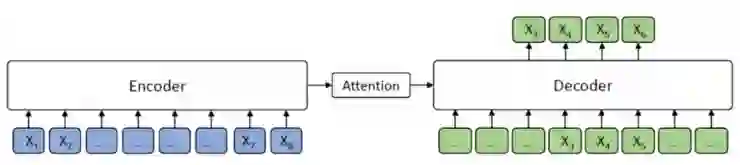
图 2 MASS 框架
如图 2 所示,编码器端的第 3-6 个标记被掩蔽,而在解码器端,仅有被掩蔽的标记被预测出来,而其他标记则被掩蔽。
MASS 预训练具有以下优势:
解码器端的其他标记(在编码器端未被掩蔽的标记)被掩蔽,从而推动解码器提取更多信息以帮助预测连续句子片段,促进编码器-注意力-解码器结构的联合训练;
为了给解码器提供更多有用的信息,编码器被强制提取未被掩蔽的标记的含义,这可以提高编码器理解源序列文本的能力;
解码器被设计用以预测连续的标记(句子片段),这可以提升解码器的语言建模能力。
MASS 有一个重要的超参数 k(被掩蔽的片段的长度)。通过调整 k 值,MASS 可以将 BERT 中掩蔽的语言建模和 GPT 中的标准语言建模结合起来,从而将 MASS 扩展成一个通用的预训练框架。
当 k = 1 时,根据 MASS 的设计,编码器端的一个标记被掩蔽,而解码器端则会预测出该掩蔽的标记,如图 3 所示。解码器端没有输入信息,因而 MASS 等同于 BERT 中掩蔽的语言模型。
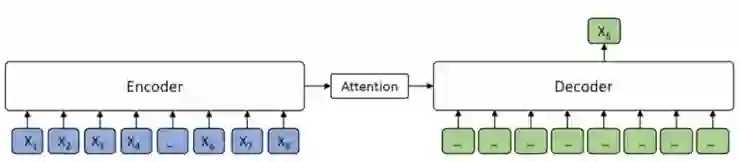
图 3 k = 1时,编码器端一个标记被掩蔽,而解码器端则会预测出该掩蔽的标记
当 k = m(m 是序列的长度)时,在 MASS 中,编码器端的所有标记都被掩蔽,而解码器端会预测所有的标记,如图 4 所示。解码器端无法从编码器端提取任何信息,MASS 等同于 GPT 中的标准语言模型。
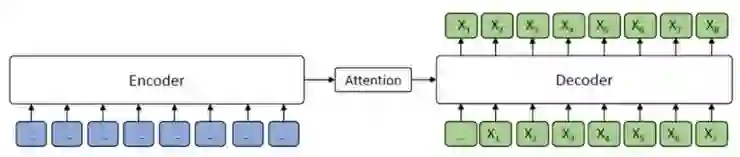
图 4 k = m 时,编码器端的所有词都被掩蔽,而解码器端会预测所有的标记,等同于 GPT 中的标准语言模型
不同 k 值下 MASS 的概率公式如表 1 所示,其中 m 是序列的长度,u 和 v 分别是掩蔽片段的起始和终止位置,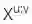

表 1 在不同 k 值下 MASS 的概率公式
研究人员通过实验来分析了在不同 k 值下的 MASS 性能,如图 5 所示:
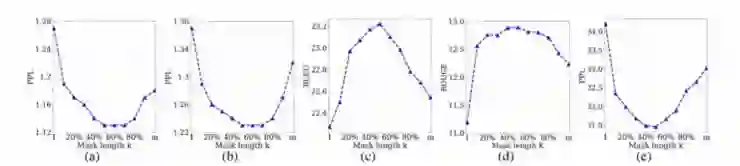
图 5 在训练前和微调阶段的各种掩蔽长度 k 下 MASS 的表现,其中包括 a) 英语句子预训练模型的PPL b) WMT13 英语-法语翻译的法语句子 c) WMT13 无监督英语-法语翻译的 BLEU 值 d) 文本摘要生成的 ROUGE 值 e) 对话生成的PPL
当 k 等于句子长度的一半时,下游任务可以达到其最佳性能。掩蔽句子中一半的词可以很好地平衡编码器和解码器的预训练部分。如果预训练更偏向编码器端(k = 1,即 BERT)或更偏向解码器端(k = m,LM / GPT),则无法实现最优的性能,这也表现出了 MASS 在序列到序列的语言生成任务中的优势。
预训练
值得注意的是,MASS 仅需要无监督的单语数据进行预训练(例如 WMT News Crawl Data、Wikipedia Data 等)。MASS 支持跨语言任务(例如机器翻译)和单语任务(例如文本摘要生成、对话生成)。在对英语-法语翻译等跨语言任务进行预训练时,研究人员可以在一个模型中同时进行英语-英语和法语-法语的预训练,并使用附加的语言嵌入向量来区分语言。在无监督的机器翻译、低资源机器翻译、文本摘要生成和对话生成四个领域,研究人员对 MASS 进行了微调,以验证其有效性。
无监督机器翻译
关于无监督机器翻译任务,研究人员将 MASS 与之前的方法进行了比较,包括以前最先进的方法 Facebook XLM。XLM 使用了由 BERT 创建的掩蔽预训练语言模型,以及标准语言模型来分别预训练编码器和解码器。
结果如表 2 所示,MASS 在 WMT14 英语-法语、WMT16 英语-德语和英语-罗马尼亚语的六个翻译方向上的表现都优于 XLM,并取得了最新的最优结果。
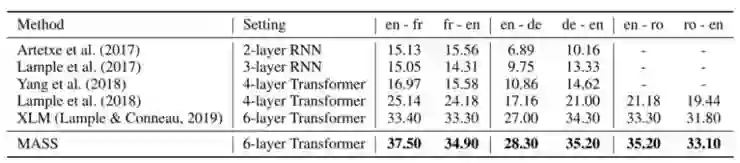
表 2 MASS 与之前关于无监督机器翻译方法之间的比较;英语-法语翻译报道在 newstest2014 上,其它的在 newstest2016 可以找到;由于 XLM 在编码器和解码器中使用 MLM 和 CLM 的不同组合,因此报告上显示的是每个语言对上 XLM 的最高 BLEU 值
低资源机器翻译
低资源机器翻译是指使用有限的双语训练数据来进行机器翻译。研究人员模拟了 WMT14 英语-法语,WMT16 英语-德语和英语-罗马尼亚语翻译(分别为 10K,100K 和 1M 双语数据)的低资源情景。
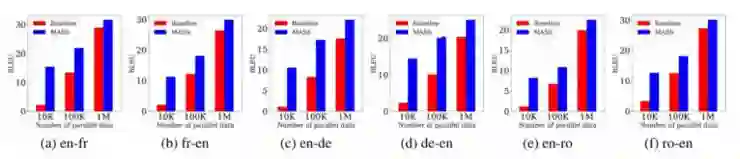
图 6 MASS 与低资源机器翻译方法之间的比较
图 6 显示 MASS 在不同数据规模上的表现,均比不用预训练的基线模型有不同程度的提升,并随着监督数据越少,提升效果越显著。
文本摘要生成
研究人员将 MASS 与 BERT+LM(编码器用 BERT 预训练,解码器用标准语言模型 LM 预训练)、DAE(去噪自编码器)进行了比较。从表 3 中可以看出,MASS 的表现都优于 BERT+LM 和 DAE。
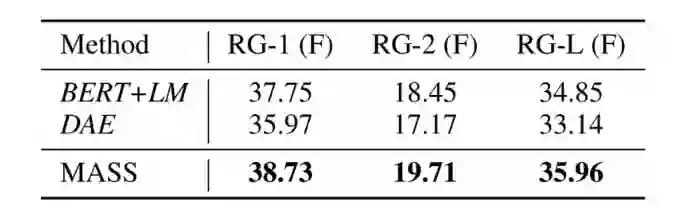
表 3 文本摘要生成任务中,MASS 和两种预训练方法之间的比较
对话生成
研究人员将 MASS 和 BERT+LM 进行了比较。表 4 显示 MASS 实现了比 BERT+LM 更低的 PPL。
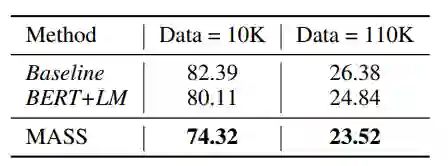
表 4 MASS 与 BERT+LM 之间的比较数据
MASS 连续在序列到序列的语言生成任务上实现显著增益,Facebook 的研究者表示,期待今后在自然语言理解任务中测试 MASS 的性能,并希望在未来的工作中,将 MASS 的应用领域扩展到包含语音、视频等其它序列到序列的生成任务中。
原文地址
https://www.microsoft.com/en-us/research/blog/introducing-mass-a-pre-training-method-that-outperforms-bert-and-gpt-in-sequence-to-sequence-language-generation-tasks/
MASS 论文
https://www.microsoft.com/en-us/research/publication/mass-masked-sequence-to-sequence-pre-training-for-language-generation/
GitHub 开源地址
https://github.com/microsoft/MASS

推荐阅读
▎5G手机价格或降至1000元;华为向印度政府提议签无后门协议;苹果确认收购 Drive.ai
▎魅族回应手机无法拨打120 ;百度资讯调整搜索来源;联邦快递拒投递华为手机







