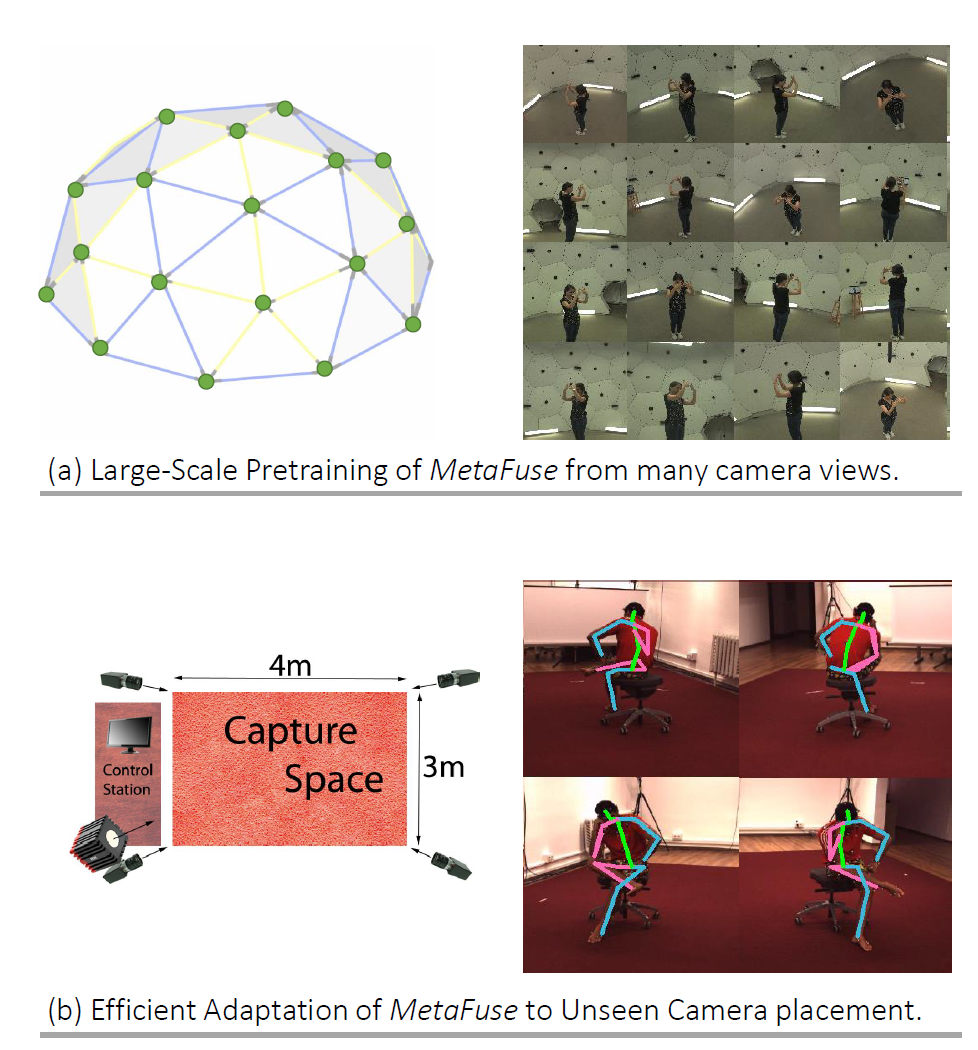
CVPR 2020 | MetaFuse:用于人体姿态估计的预训练信息融合模型

本文是 CVPR 2020入选论文《MetaFuse: A Pre-trained Fusion Model for Human Pose Estimation》的解读。
作者 | PKU CVDA
编辑 | 丛 末

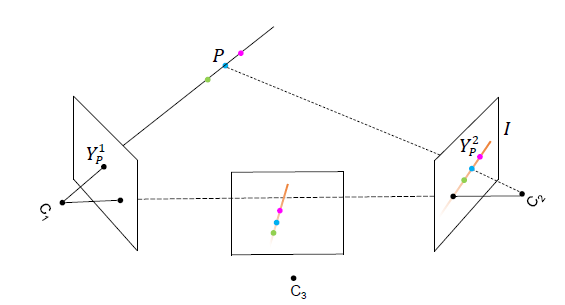
 ,在另一个相机2中,对应的像素点必定位于一条直线 I(Epipolar Line)上。因此,我们可以将直线 I 对应的特征信息,融合到该点
,在另一个相机2中,对应的像素点必定位于一条直线 I(Epipolar Line)上。因此,我们可以将直线 I 对应的特征信息,融合到该点
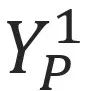 中。具体公式如下所示:
中。具体公式如下所示:
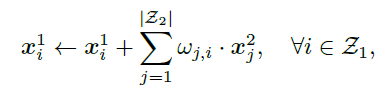

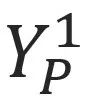 在视角2中对应的线段 I。将视角2切换为视角3时,可以通过对线段 I 进行合适的仿射变换,得到视角3中对应的极线。受此启发,假设存在一个通用的融合模型 ωbase,它用于连接视角1中单个像素和视角2中的所有像素。那么对于视角1的其他像素而言,可以通过对 ωbase 进行仿射变换,得到对应的融合权重。
在视角2中对应的线段 I。将视角2切换为视角3时,可以通过对线段 I 进行合适的仿射变换,得到视角3中对应的极线。受此启发,假设存在一个通用的融合模型 ωbase,它用于连接视角1中单个像素和视角2中的所有像素。那么对于视角1的其他像素而言,可以通过对 ωbase 进行仿射变换,得到对应的融合权重。
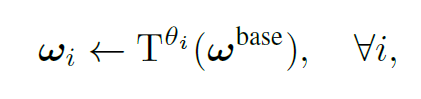

-
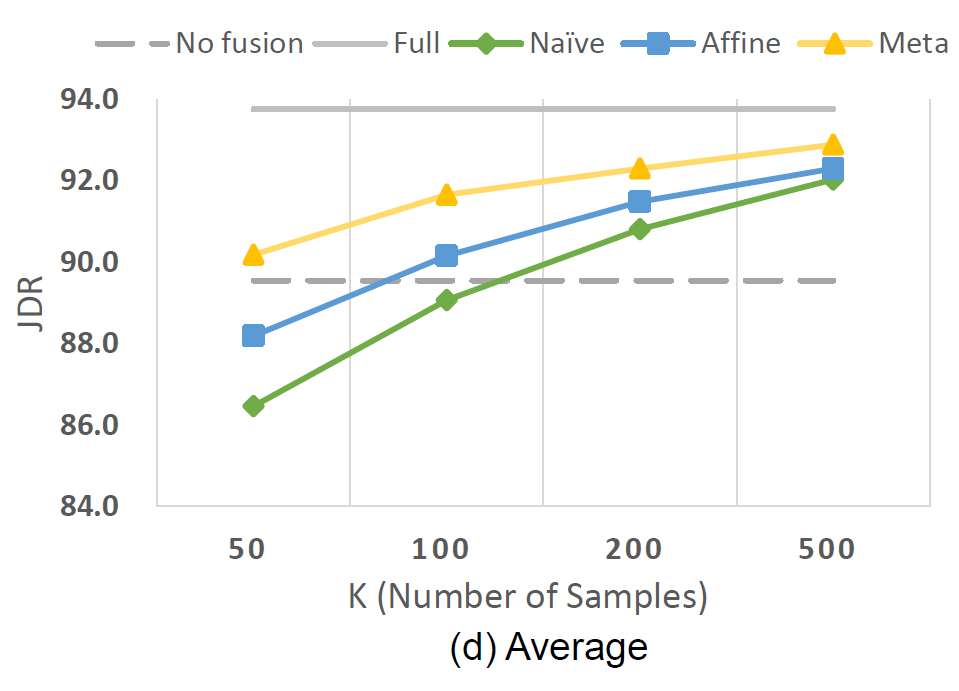
No Fusion,不进行视角间的信息融合; -
Full Fusion,使用所有目标数据,进行 NaiveFuse 的训练; -
使用少量数据训练 NaiveFuse; -
AffineFuse,使用常规梯度下降方法训练参数分解后的模型,并使用少量数据微调; -
MetaFuse,使用元学习来训练参数分解后的模型,并使用少量数据微调。
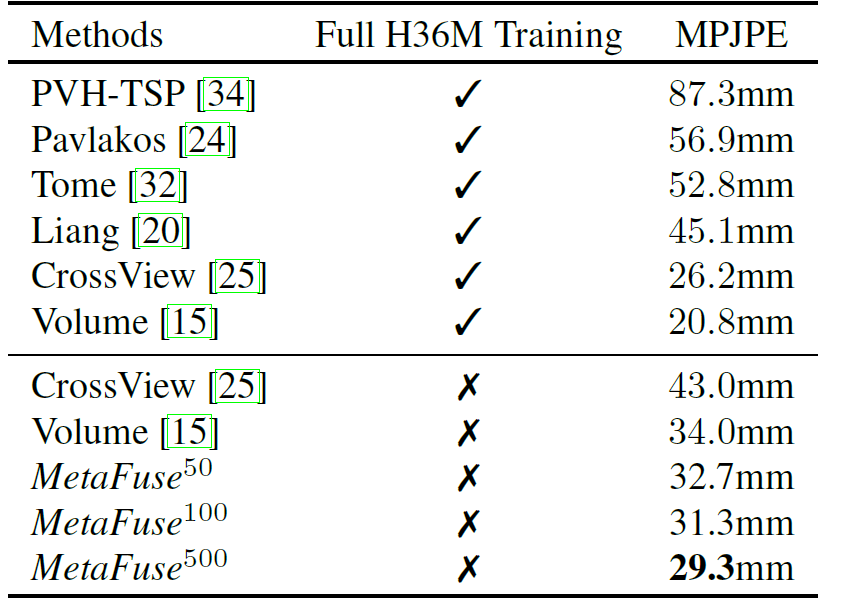
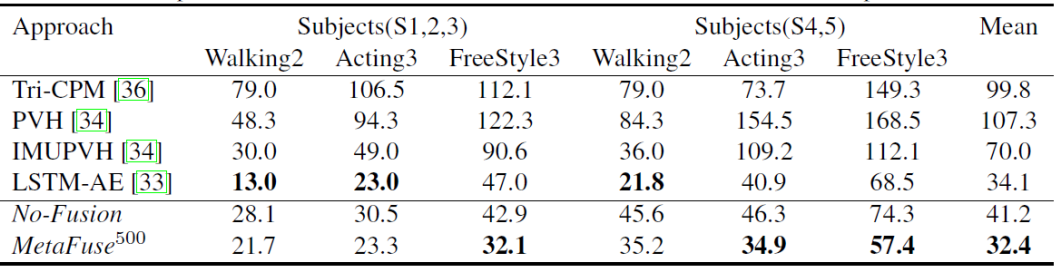

总结
 点击“阅读原文” 查看 CVPR 系列论文解读
点击“阅读原文” 查看 CVPR 系列论文解读
登录查看更多
相关内容
专知会员服务
34+阅读 · 2020年3月21日
专知会员服务
30+阅读 · 2020年1月2日
Arxiv
11+阅读 · 2018年5月21日


相关VIP内容
专知会员服务
34+阅读 · 2020年3月21日
专知会员服务
30+阅读 · 2020年1月2日
相关资讯
相关论文
Arxiv
11+阅读 · 2018年5月21日