学界 | SphereReID:从人脸到行人,Softmax 变种效果显著
AI 科技评论按:本文作者范星,首发于知乎专栏,AI科技评论获授权转载。
本文主要是介绍自己做的一个工作:SphereReID: Deep Hypersphere Manifold Embedding for Person Re-Identication(https://arxiv.org/abs/1807.00537),用了 Softmax 的变种,在行人重识别上取得了非常好的效果,并且端到端训练,网络结构简单。在 Market-1501 数据集上达到 94.4% 的准确率(并且不需要 re-ranking 和 fine-tuning)。
另外,也介绍了一种新的学习率调整策略,可以有效地提升网络训练效果,同时并不局限于行人重识别任务,自己用在关键点检测上也取得了不错的效果,仅仅通过改变学习率测率就可以涨两个点的样子。
在过去一年中,人脸识别领域取得了非常多的进展,识别率到了一个非常高的水平,一个很重要的原因,是大家重新审视了 Softmax Cross-entropy 这个古典的损失函数,来了一场损失函数的文艺复兴,提出了各种各样的变种,并且效果取得了巨大的提升。这股风主要在人脸领域刮,而我是做行人重识别的,自然也会想到在行人上面也深挖一下 Softmax,于是就有了这篇文章。就我所知,这是第一个利用 Softmax 变种将行人特征映射到一个超球面上进行重识别的工作。
人脸中的 Softmax 变种
传统的 Softmax Loss
传统的 Softmax Loss 被广泛用于分类问题,可以很好地区别不同类的样本,是最基本的最常用的损失函数之一。其公式如下:
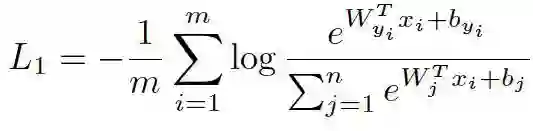
其中 x 是网络最后一层(不包括分类层)输出的特征,经过一个全连接的分类层,即乘以权重 W 并加上偏置 b,输出 score,然后经过一个 Softmax 函数再算交叉熵。
Softmax 可以有效区分类间差异,但是对于类内的分布没有很好的约束,因此监督效果不够。
Large-Margin Softmax
论文:W. Liu, Y. Wen, Z. Yu, and M. Yang,「Large-Margin Softmax Loss for Convolutional Neural Networks,」in ICML, 2016.
最后分类层的每个神经元乘以权重的过程,可以分解为如下形式:
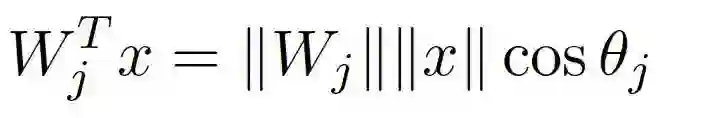
即神经元的权重向量的模和特征向量的模相乘,再乘以两个向量夹角的余弦值,这是简单的向量点积的基本定义公式。对上面的右边的公式进行重解释,解释为特征向量到神经元向量的点积,到哪个特征向量点积大最后就划分到哪个类别。
原始的余弦值不加额外约束,即只要到正确类别的点积更大即可正确划分。这篇文章作者认为不仅要分对,还要有 Margin,更好地分开来,所以替换掉里面的余弦值,用一个新的变换来替代:

可以用 m 来控制 Margin 的大小,当 m 等于 2 的时候,和原始的余弦值函数比,人为地添加了一定的 Margin 来强制约束两个类分得更开:
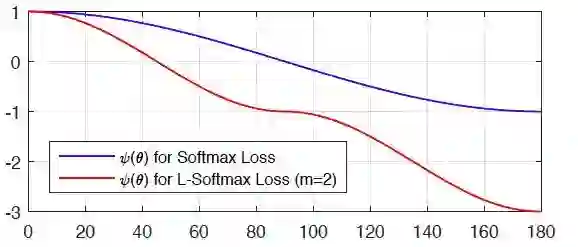
这是用在 MINIST 手写数字识别上的效果,新的损失得到的特征更加紧凑:

Angular Softmax
论文:W. Liu, Y. Wen, Z. Yu, M. Li, B. Raj, and L. Song,「SphereFace: Deep Hypersphere Embedding for Face Recognition,」in CVPR, 2017.
还是用新的余弦值映射函数来替代原始的余弦值函数,增加 Margin,并且对分类权重向量的权重做了归一化,消除了不同类别的权重的模的不同带来的差异,而更加依赖于权重向量和特征向量的角度。而我们新的 Margin 就是用来约束角度的,角度的区分度的优势可以更好地体现出来:

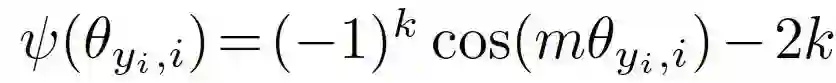
Additive Cosine Margin
论文:H. Wang et al.,「CosFace: Large Margin Cosine Loss for Deep Face Recognition,」CVPR. 2018.
论文:F. Wang, W. Liu, H. Liu, and J. Cheng. "Additive margin softmax for face verification". In arXiv:1801.05599, 2018
这两篇大约同时挂出来,都是讲的余弦值上加 Margin。
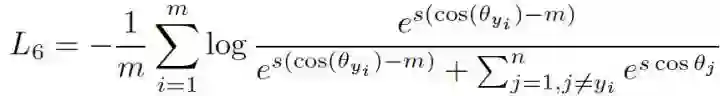
前面提到的用替代余弦函数来取代原始余弦函数添加 Margin 的做法,有一个缺点是替代函数的选取以及使用替代函数会比较复杂,并且 Margin 不太好控制,夹角不同时约束变化不同。并且引入用来替代函数实现也复杂,所以提出来直接在余弦值上添加一个 Margin:
这样做简单直接多了。
Additive Angular Margin
论文:J. Deng, J. Guo, and S. Zafeiriou,「ArcFace: Additive Angular Margin Loss for Deep Face Recognition,」ArXiv e-prints, Jan. 2018.
直接修改余弦值增加 Margin,Margin 对 score 的影响不是线性的,权重向量和特征向量之间夹角不同,约束强度也不一样。所以想到了直接对角度进行约束,提出了:
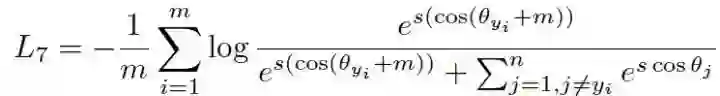
可以看到,直接在角度那里添加 Margin 约束。
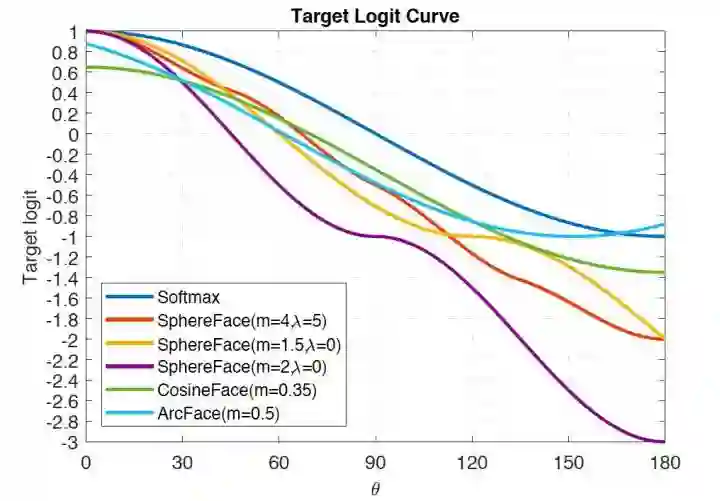
一个直观的几种变种的 Margin 约束强度如下图所示:
SphereReID
损失函数
受人脸对于 Softmax 重新解释,添加几何意义,看作向量夹角接近的方法的启发,我们也在行人重识别上采用来类似的做法,不把特征映射在普通的欧式空间,而是映射到球面上,这样分类的几何意义就非常清晰了:
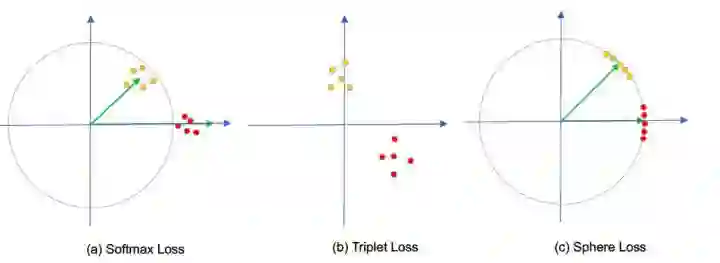
图 a 是原始的 Softmax 损失,绿色是分别是类别 1 和类别 2 的分类层神经元,分别输出属于类别 1 和类别 2 的 score,黄点和红点分别是落在空间中的不同类别的样本。可以看到,原始的 Softmax 在空间的分布比较随意。回顾一下,输出的 score 为:
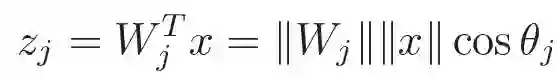
而 z1=z2 就是两个类别的临界面,约束类别 1 的样本的 score 满足 z1>z2,类别 2 的样本的 score 满足 z2>z1 即可正确进行分类,但是实际上特征分布并不够理想。
图 b 是行人重识别度量学习中常用的 Triplet Loss 的分布,Triplet Loss 要满足正样本对见的距离比负样本对之间的距离更小,并小于一个设定的阈值:

Triplet Loss 使用的是相对约束,对于特征的绝对分布没有添加现实的约束,所以还经常将 Triplet Loss 和 Softmax Loss 结合起来,效果也会进一步提升。
图 c 则是本文的 Sphere Loss,将特征映射到一个高维球面上,具体的公式如下:
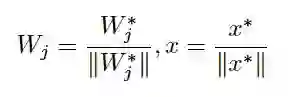
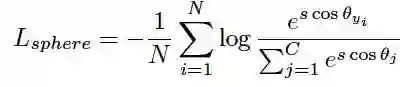
将权重向量和特征向量都进行归一化消除模的影响,并引入一个温度参数 s,控制 softmax 的温度(即曲线的波动程度)。
这样做以后,如下图所示:图 a 原始的 softmax 是比较点积,对于样本 x,如果
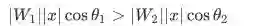
则分到第 1 类,反之分到第 2 类,分类结果不仅和角度有关,还和向量的模有关。
而图 b 中归一化以后,只需要比较两个角度的大小,如果
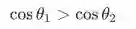
则分到第 1 类,反之分到第 2 类,只由角度决定,清晰简单多来,全部映射到一个超球面上了:
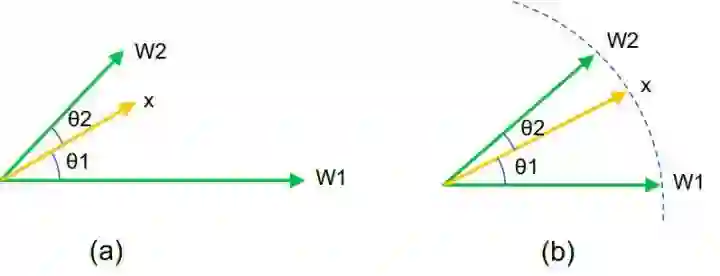
网络结构
我们还设计来一个网络使用该损失函数用于行人重识别任务。
设计的网络结构如下:基础网络(本文使用来 ResNet-50)抽取特征,然后全局平均池化、BN、Dropout、FC 再 BN,然后用 L2 归一化,得到最终的特征,然后计算损失。如下图:
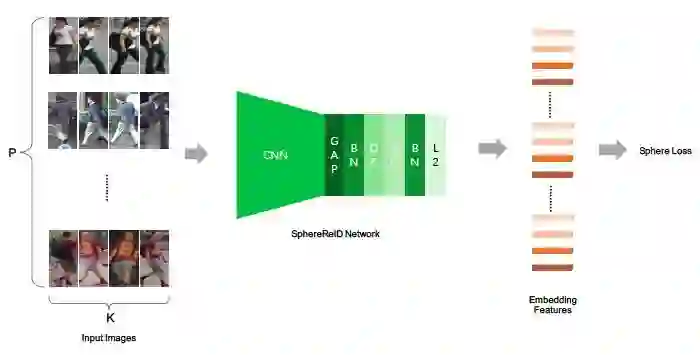
数据供应部分,使用了类似 Batch Hard 的方式,每次输入 P 个人的 K 张图片。
Warming-up 策略
此外,文章还提出了一种新的 Warming-up 学习率策略。直接上学习率曲线如下:
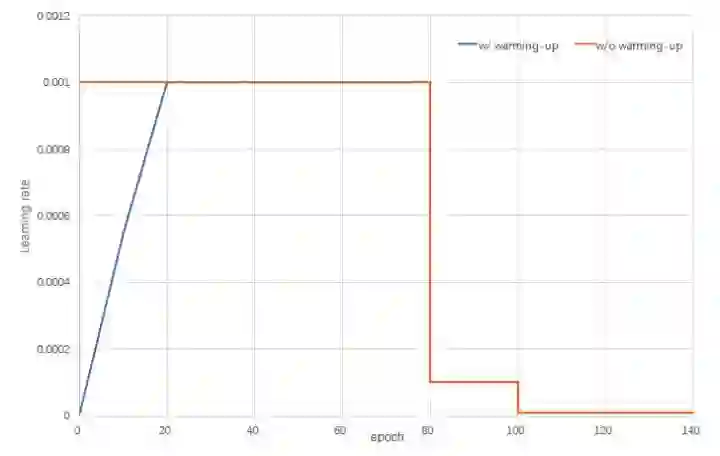
核心就是先用小的学习率,然后逐渐增大学习率到想要的值。
背后的动机在于:网络在一开始的时候是未良好初始化的,Base Model 的权重是在 ImageNet 上训的,而不是用于 ReID,而新添加的层则是随机初始化的。所以一开始网络并不能很好的提取特征,使用较大的学习率很容易梯度爆炸(比如在 Batch Hard Triplet Loss 中特别明显),可以使用梯度裁剪来缓和梯度过大的问题,但是这样认为裁剪影响梯度的正常传播,最后训练的效果会受到一定的影响。
所以提出了一开始用较小的学习率,warming-up,让网络先渐渐地缓慢到达一个良好初始化的状态,再增大到预期的大学习率进行正常训练。
实验结果证明,这种策略可以有效地提升训练效果,并且不需要额外的修改或计算量。并且,通过在其它任务上地实验,比如关键点检测,发现该 warming-up 方法也能有效提高最终准确率。
结果
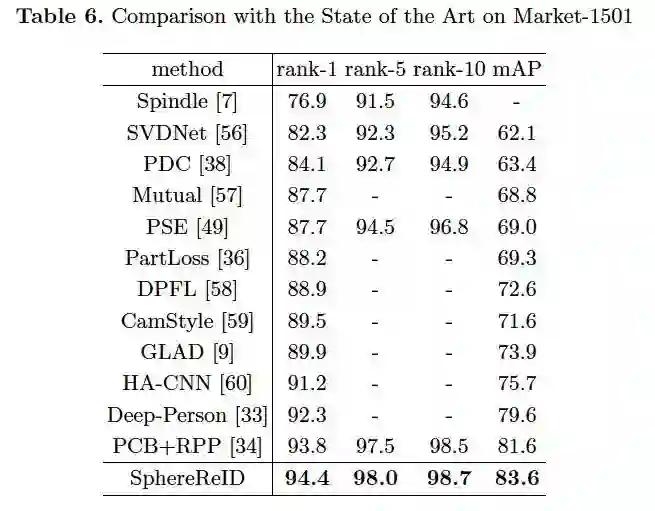
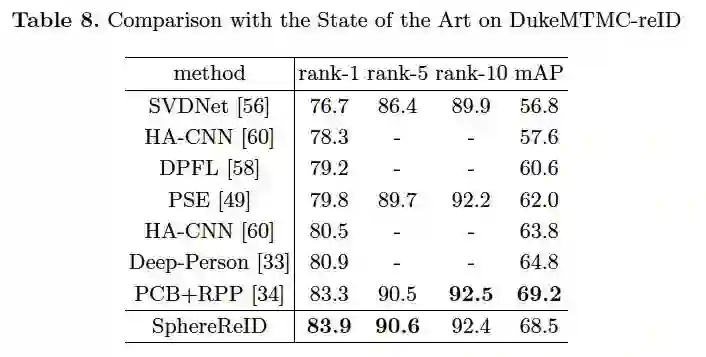
最后单模型仅用一个单损失函数,end-to-end 地训练,就可以达到 state-of-the-art,不需要 re-ranking 或 fine-tuning。其中在 Market-1501 上达到了 94.4%,在 DukeMTMC-reID 上达到了 83.9% 的 top-1 准确率,并且具有单模型单损失端到端特征向量小实现简单等优点。
总结展望
SphereReID 是 Softmax 重发现在行人重识别上的第一个工作,取得了很好的效果,并且有端到端训练、实现简单、原理清晰、效果显著等优点,说明了该思想的有效性。而本文的方法,在未来还有很多可以值得进一步探索和提升的地方:
添加 Margin,本文没有添加 Margin,未来可以探索添加 Margin,进行更好的约束,进一步提升效果;
Softmax 变种并不太容易训练,希望有更多的研究可以解决训练的问题;
Warming-up 学习率策略不一定局限于 ReID,在关键点检测上也有效,可能可以应用到其它更多的领域;
从人脸到行人重识别,效果确实不错,Softmax 的变种也可能被用在更多的领域,等待进一步的探索;
从特征提取层面入手和从损失函数入手,行人重识别准确率已经被提得很高,不过一些细化的问题和更难的一些场景仍需探索;
点击文末阅读原文查看 AI 影响因子。
┏(^0^)┛欢迎分享,明天见!




