论文 | 用于密集对象检测的 Focal Loss 函数

论文:Focal Loss for Dense Object Detection
原文链接:https://arxiv.org/abs/1708.02002
目前最先进的目标检测系统是基于两个阶段的机制。第一个阶段生成一个稀疏的候选区域集合,第二个阶段使用卷积神经网络对候选区域进行分类处理。最典型的例子例如R-CNN系列框架。
另一种目标检测系统的解决思路是在一个阶段完成目标检测的任务。例如YOLO,SSD。这些系统的比两阶段的要快,但是在准确度方面有所下降。
本文进一步推进了上述的研究,提出了一种一阶段的目标检测系统。首次在COCO数据集上达到了最先进两阶段目标检测系统(例如FPN,Faster R-CNN)的性能。为了达到这个目的,我们把训练阶段的类别不平衡性视为一阶目标检测系统精度的瓶颈,并提出了了解决这个瓶颈的全新的损失函数。在此基础上,我们设计了一个名为RetinaNet的一阶目标检测模型。
2.1 Cross entropy
二分类问题中loss的定义如下:
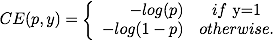
上式中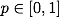

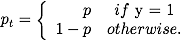
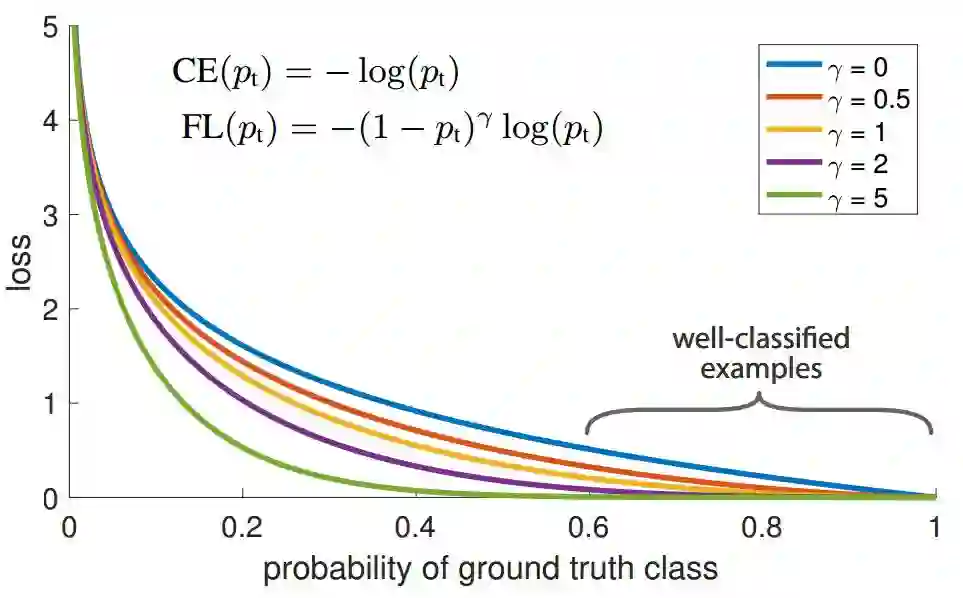
CE loss 如下图中的蓝色曲线所示,这个loss的一个显著特征是,即使是很容易的分类情况下,也会产生较大的loss。当把这些大量的loss加起来的时候,将会产生较大的影响。
2.2 Balanced Cross Entropy
常用的解决类别不平衡的方法是引入一个额外的参数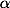
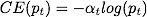
2.3 Focal Loss Definition
正如实验所示,在密集目标检测系统中,训练过程中,遇到的类别失衡将会对交叉熵损失函数产生较大影响。容易分类的负样本将会占据主要的损失以及梯度。尽管
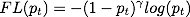
Focal loss 在 cross entropy 的基础上增加了一个调节因子,
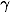
当一个样本被错分类,
值很小的时候,调节因子,
的值很小,因此不会对loss产生影响。当
值很大,趋近于1的时候,调节因子的值趋近于0,因此对于正确分类的样本的loss值被缩小了。
的时候,FL 等于 CE。当
增加时候,调节因子的影响相应的增加,实验中
取得了最好的实验效果。
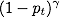


在实验中,我们使用了
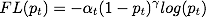
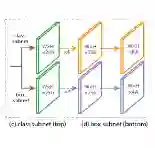
为了验证使用的Focal Loss function,作者设计了一种RetinaNet,如下图所示:
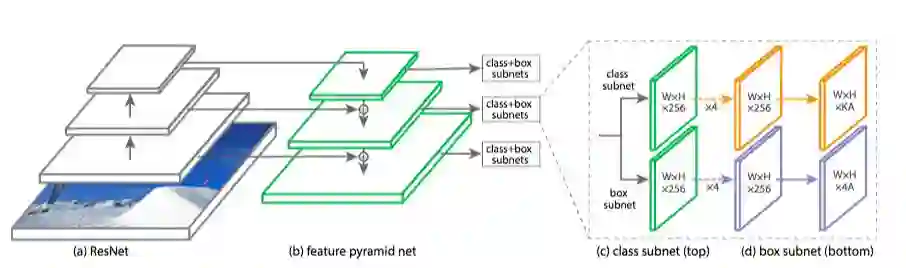
RetinaNet 网络架构包含一个backbone 网络和两个subnetwork。Backbone网络在底层使用了ResNet,用来生成卷机特征,在此之上有一个Feature Pyramid Network(FPN)。Backbone外接两个subnetwork,一个用来分类,一个用来生成目标位置信息。
我们在COCO数据集上进行了目标检测的实验,并将测试结果与近期最先进的方法进行比较。其中包括一阶模型和二阶模型。下表列出了测试结果:
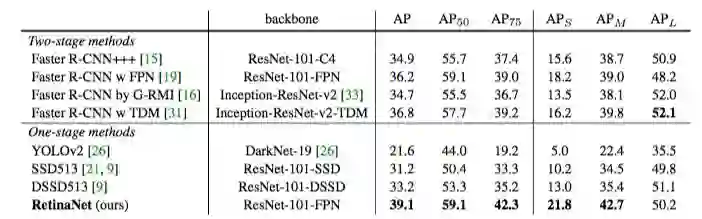
这是Retina-101-800模型的测试结果,训练过程中采用scale filter , 训练时间是之前模型的1.5倍,但是AP值提升了1.3。对比当前最先进的一阶模型,我们的模型AP值提升了5.9%(39.1 vs 33.2)。对比当前最先进的二阶模型,Faster R-CNN w TDM,我们的模型也取得了2.3%的优势(39.1 vs 36.8)。
本文中,我们将类别不平衡视为一阶目标检测系统的性能瓶颈,为了解决这个问题我们对CE(交叉熵损失)提出了改进,提出了focal loss。实验结果显示,基于focal loss 的RetinaNet ,相对比与之前的目标检测系统,有较大改进。
版权声明:转载文章和图片均来自公开网络,版权归作者本人所有,推送文章除非无法确认,我们都会注明作者和来源。如果出处有误或侵犯到原作者权益,请与我们联系删除或授权事宜。