
编者按:近年来,基于人体姿态引导的图像生成算法受到越来越广泛的关注。该项技术不仅可以辅助图像/视频编辑、行人重识别(Re-ID),也为时尚领域的服饰设计、虚拟试衣等应用提供了支持。本文介绍了人体姿态引导下基于语义转换的无监督人物图像生成算法,能够有效保持人体和衣物的原有属性,提高图像的视觉质量。此外,该算法同时可以应用于衣物纹理转换、时尚图像编辑等任务中,让图像中的人物不仅可以随意变换姿势,还能够变换服装的款式和纹理,成为百变先生/小姐。
今天为大家介绍无监督下基于人体姿态引导人物图像生成[1]的一篇工作,由北京大学和京东人工智能研究院合作完成,入选CVPR2019 Oral。基于人体姿态引导的人物图像生成,是指给定源人物图像和目标人体姿态,生成目标姿态下的人物图像,同时保持源人物图像的外观特征。在该任务中,由于输入和输出图像的空域非对应性和几何形变,导致难以直接刻画输入图像和输出图像的映射关系;无监督条件下真实图像监督的缺乏,使这一映射关系的构建更加困难。基于上述原因,当前无监督式方法生成的人物图像质量不太理想,主要表现在未能正确保持输入图像的原有衣物属性,包括纹理、衣物款式、人体形态结构等方面。现有模型虽然尝试使用将输入图像和输出图像的直接映射关系分解(如按照前景背景分解、按照形状和外观分解),以简化对映射关系的建模过程,但是由于未对人体结构进行精细化分解,导致输出图像中人体结构的形状不完整,以及衣物属性未能保持。
为了解决上述问题,该文提出了基于语义转换的无监督人物图像生成算法,以人体语义图为引导,完成目标姿态下的人体图像生成。一方面,语义图不包含纹理信息,简化了无监督下输入输出的形状映射关系学习;另一方面,人体语义的引导对保持衣物的原始属性(款式、纹理等)提供了先验知识。具体来讲,该文将人物图像生成分解为两部分:人体语义转换和人体外观生成,如图1所示。在人体语义转换模块(HS)中,根据输入图像的人体语义图和目标姿态,预测输出图像的人体语义图,其中,输入图像的人体语义图由现有人体语义分解器得到;在人体外观生成模块(HA)中,根据预测的输出图像人体语义图和输入图像,在对应语义位置渲染输出人物图像的纹理,得到最终的输出图像。
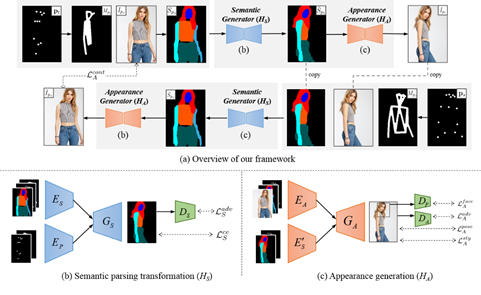
图1 基于语义转换的无监督人物图像生成算法框架
人体语义转换
人体语义转换模块旨在根据输入图像的人体语义图和目标姿态,生成输出人体语义图,以正确预测人体每一个语义结构的形状和边界。由于没有外观信息,不同外观下的人物图像可能共享相同的人体语义图。根据这一特点,该文算法可在训练集中搜寻成对的人体语义图,它们满足:(1)处在不同的姿态;(2)具有相同的语义信息。利用这些成对的数据,该文以监督式的方法对语义转换模块进行预训练。在训练过程中的损失函数主要包括交叉熵函数和对抗损失函数。其中,交叉熵损失函数用来监督转换后的语义图生成,对抗损失函数能使生成的语义图在视觉效果上更加真实。
人物外观生成
在上一阶段预测的输出图像人体语义图的引导下,外观生成模块对每一个语义结构进行纹理渲染,以更好地保持人物图像的外观属性。由于没有真实图像的监督,人体外观生成的训练基于循环生成对抗网络(CycleGAN)的训练思想。在外观生成模块的训练中,损失函数主要包括以下几个部分:
- 对抗损失函数:使生成的人物图像更加接近真实自然图像
- 人体姿态损失函数:约束生成的人物图像姿态和目标姿态一致
- 内容一致损失项:即Cycle consistency损失
- 语义引导的风格损失项:通过限制相同语义部分高维特征的Gram矩阵距离,约束相同语义部分的纹理迁移。
- 人脸损失项:通过人脸上的节点定位人脸区域,对人脸部分设置独立的判别器,提升人脸部分的重建效果。
端到端训练方式
在该文算法中,语义引导的风格损失项本质是在鼓励网络学习相同语义间的图像映射,因此图像生成的最终效果很大程度上依赖于语义图的质量。然而由于在语义转换模块的学习中,并没有真实人体语义图作为监督,搜寻到的相似对偏差可能导致语义转换生成过程不稳定,因此本文采用端到端的联合训练纠正语义转换模块中的偏差,使生成结果达到最佳。
算法分析
图2对该文算法进行了分析,和Baseline相比,引入语义信息有效提升了网络的学习效果。此外,该文算法既可以分阶段训练(TS-Pred以预测语义图为外观生成的输入,TS-GT以真实语义图为外观生成的输入),也可以端到端训练(E2E),实验结果显示端到端训练的方式能够纠正语义转换模块中的错误,如第1行中人物的发型,第2行中人物的袖长。

图2 算法分析
该文同时分析了不同损失函数设置对图像生成的影响,如图3所示,其中,(a)为基于mask的风格损失,(b)为基于图像块的风格损失,(c)中没有使用针对人脸的判别器。该文提出的语义引导的风格损失能够有效保持衣物属性,同时重建出自然的人脸。

图3 不同损失函数设置对生成图像的影响
实验结果
该文算法可以运用在三个任务上:基于人体姿态引导的人物图像生成,衣物纹理迁移和时尚图像编辑。 图4展示了人体姿态引导的人体图像生成算法在DeepFashion数据库[8]上的效果,比较的方法包括PG2[2],Def-GAN[3],UPIS[4],和V-Unet[5],其中PG2,Def-GAN为监督式算法,而UPIS,V-Unet是无监督算法。在无监督的情况下,本文的工作不仅能够生成更加真实的图像,也同时能够保持衣物的原有属性,如衣物的纹理(第1,2,4行),衣物的类型(3,5行)。

图4 人体姿态引导的图像生成 同时,本文的工作可以应用在衣物纹理的迁移之中,如图5所示,将人物A和人物B的衣物互换,和Image analogy[6]和Neural doodle[7]相比,该文算法能够生成自然真实的结果,同时实验结果也表明该文模型能够本质上学习到对应语义区域之间的映射,

图5 衣物纹理迁移 此外,该文算法也可以作为时尚图像编辑的支撑,通过改变人体语义图,可以将人物的衣服款式做出相应变化。如下图,无袖T恤可通过编辑语义图改为长袖(第1行),裙装可以改为裤装(第2行)。

图6 时尚图像编辑
以上是无监督场景下的训练结果,有监督情况下的生成质量更高。
该团队日前开源了有监督场景下的工作[9]。基本采用了基于语义转换的思路,并且由于更强的监督信息,生成的图像更加逼真,并且能保持更多的图像细节。
图7展示了有监督下的生成结果,在细节区域(如衣物纹理、头发、人脸)的生成上大大改善。该工作首先优化了生成网络中的卷积模型,提出用tree-dilation block替代传统的res-block。由于引入多尺度、大感受野的信息,在面部、衣服细节上都有了明显改善。最终的生成图像尽可能地保留了源图像中的细节。图8表明,该方法相对于目前的主流方法,对细节部分的把握更胜一筹。该工作目前已在Github上开源: https://github.com/AIprogrammer/Down-to-the-Last-Detail-Virtual-Try-on-with-Detail-Carving

图7有监督人物图像生成,面部、头发、衣物部分细节明显改善

图8有监督人像生成算法对比
参考文献
[1] Sijie Song, Wei Zhang, Jiaying Liu, Tao Mei. Unsupervised Person Image Generation with Semantic Parsing Transformation. CVPR 2019. [2] Liqian Ma, Xu Jia, Qianru Sun, Bernt Schiele, Tinne Tuytelaars, and Luc Van Gool. Pose guided person image generation. NeurlPS, 2017. [3] Aliaksandr Siarohin, Enver Sangineto, St´ephane Lathuili`ere, and Nicu Sebe. Deformable gans for pose-based human image generation. CVPR, 2018. [4] Albert Pumarola, Antonio Agudo, Alberto Sanfeliu, and Francesc Moreno-Noguer. Unsupervised person image synthesis in arbitrary poses. CVPR, 2018. [5] Patrick Esser, Ekaterina Sutter, and Bj¨orn Ommer. A variational u-net for conditional appearance and shape generation. CVPR, 2018. [6] Aaron Hertzmann. Image analogies. Siggraph, 2001. [7] Alex J. Champandard. Semantic style transfer and turning two-bit doodles into fine artworks. arXiv preprint arXiv: 1603.01768, 2016. [8] Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. CVPR, 2016. [9] Jiahang Wang, Wei Zhang, Weizhong Liu, Tao Mei. Down to the Last Detail: Virtual Try-on with Detail Carving. arXiv preprint arXiv: 1912.06324, 2019.


