CVPR 2019 | 微软亚洲研究院7篇精选论文解读

编者按:计算机视觉顶会CVPR 2019于6月15-21日在加州长滩举行。微软亚洲研究院共有21篇论文入选本届CVPR,覆盖了姿态估计、对象检测、目标跟踪、图像编辑、3D形状生成、高效CNN等多个计算机视觉领域的热门话题,本篇文章选择了其中7篇进行介绍。我们主办的线下CVPR分享会也进行到了第三届,错过的小伙伴可以看这里。
上下文强化的语义分割
Context-Reinforced Semantic Segmentation
Yizhou Zhou, Xiaoyan Sun, Zheng-Jun Zha, Wenjun Zeng
GitHub地址:https://github.com/scenarios/CiSS-Net
图像语义分割任务的主要目标是对给定自然图像进行像素级别的语义分类,从而得到细粒度的场景语义描述。该任务在自动驾驶,医学图像分析等应用扮演着重要角色。
在语义分割任务中,许多工作已经表明了环境上下文(context)的重要性。其中的一个方向是利用既有的分割预测结果来进行由粗到细(coarse-to-fine)的语义分割。例如,通过条件随机场(conditional random field)直接对分割结果进行后处理,或者利用循环结构(recurrent architecture)迭代地将前步所得的分割预测作为当前步骤的输入进行再预测。
本文重点探究了如何自适应地利用存在于分割预测图(predicted segmentation map)中的上下文信息。实际上,由于分割预测图中不可避免地存在着如错分区域这样的不可预知的噪声,且无法人为定义分割预测图中哪些信息最有利于帮助分割网络得到更好分割结果,我们认为需要学习一个独立的模块来负责显式地从分割预测图中提取出有效子集作为上下文信息。通过将上下文的提取表述为马尔可夫决策过程,我们可以在不引入新的监督信号的情况下,使用强化学习对该模块进行优化以显示地选择对分割预测具有正面作用的上下文信息。
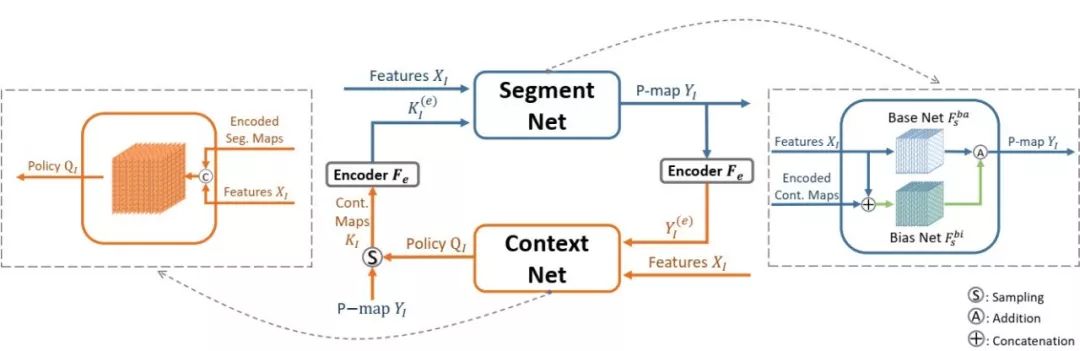
如上图所示,我们迭代地进行分割预测。在第n次迭代中,分割网络(Segment Net)不仅会参考图像的特征图,还会考虑到编码过后的上下文C^n,这里所用到的上下文则是由上下文网络(Context Net)从第n-1次迭代的分割预测图中提取出来的。由于所提取的上下文信息会对之后所有步骤的分割预测产生影响,并且没有相应的标注来指导上下文网络该提取什么样的信息,所以我们将提取上下文视为行动(action),将图像和上一步迭代的分割预测图视为环境(environment),构建出一个马尔可夫决策过程,并通过最大化未来分割的准确率,来间接的指导网络选择最有长期益处的上下文信息。我们使用了A3C(asynchronous advantage actor-critic)算法来端到端地优化上述过程。实验结果表明通过这种context-reinforced的方式选取出来的上下文信息,相对于基准线(baseline)最高可以带来3.9%的性能提升。

如上图所示,我们用白色代表在分割预测图中没有被选择作为上下文的区域。可以观察到,虽然仍然无法定义什么是真正有用的环境上下文,但这些被自适应选择地区域在某种程度上符合人类预期,即上下文网络更倾向于选择那些有场景代表性的语义信息作为上下文。
三角测量学习网络:从单目到立体图像的3D对象检测
Triangulation Learning Network: from Monocular to Stereo 3D Object Detection
Zengyi Qin, Jinglu Wang, Yan Lu
论文地址:https://arxiv.org/abs/1906.01193
3D对象检测旨在定位3D空间中特定类别的对象的三维边界框。当提供有源3D扫描数据时,检测任务相对容易。但主动扫描数据成本很高,且可扩展性受到限制。我们解决了被动图像数据的3D检测问题,这些数据只需要低成本的硬件,适应不同规模的对象,并具有效果较好的语义特征。
由于从2D图像到3D几何图形的二义性映射,单个RGB图像的单目3D检测非常难,添加更多输入图可以为3D推理提供更多信息。多视图几何通过先找到点的密集对应关系,然后三角测量估计它们的3D位置。几何方法处理利用点的局部特征,而不考虑对象级别的语义线索。
具有成对图像的立体数据更适合于3D检测,因为左图像和右图像之间的差异可以揭示空间方差,尤其是在深度维度。虽然研究者们已经对基于深度学习的立体匹配进行了大量的工作,但他们主要关注的是像素级而不是对象级。我们通过适当地放置3D锚点并将区域提议网络(RPN)扩展到3D,可以仅使用单目图像获得不错的结果。
在本文中,我们提出立体三角测量学习网络(TLNet)的立体图像三维物体检测,它无需计算像素级深度图,就可以很容易地集成到基础单目检测器中。这一工作的关键思想是使用3D锚箱在一对立体图像上构建其二投影的对象级几何对应,网络从中学习三角测量锚附近的目标对象。在TLNet中,我们引入了一种有效的特征重新加权策略,通过测量左右一致性来增强信息特征通道。重新加权方案过滤了来自噪声和不匹配信道的信号来促进学习过程,使网络能够更多地关注对象的关键部分。我们首先提出了一个基础单目3D检测器,如下图所示。
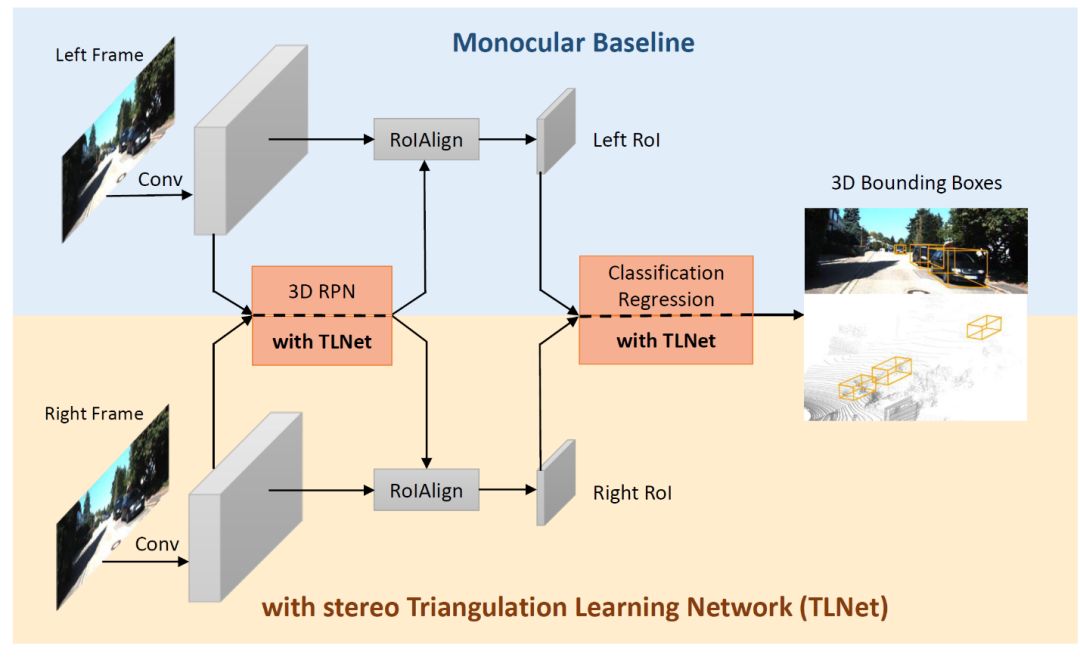
3D检测器概述
结合TLNet,我们证明了在多种情况下,3D物体探测都有显着改进。另外,我们也对TLNet中的特征重新加权策略进行了定量分析,以更好地理解其效果。总之,我们的贡献在三方面:
(1)一种可靠的基础3D检测器,仅以单目图像为输入,具有与目前最先进的立体检测器相当的性能。
(2)三角测量学习网络,利用立体图像的几何相关性定位目标3D对象,表现优于基础模型。
(3)一种功能重新加权策略,可增强特定视图的RoI功能的信息通道,通过将网络注意力聚焦于对象的关键部分而有益于三角测量学习。
SPM跟踪器:用于实时视觉对象跟踪的串并联匹配
SPM-Tracker: Series-Parallel Matching for Real-Time Visual Object Tracking
Guangting Wang, Chong Luo, Zhiwei Xiong, and Wenjun Zeng
论文地址:https://arxiv.org/abs/1904.04452
视觉物体跟踪(Visual Object Tracking,VOT)是视频分析任务中的一个基础而经典的问题。在一段视频里,对于指定的物体,跟踪任务要求算法能持续地给出该物体在后续帧的位置(通常由一个矩形框所表示)。
VOT任务的关键是“能跟住”、“不跟错”。首先,由于姿态变化、相机角度、光照改变等诸多原因,物体的外观在一段视频里是不断变化的。“能跟住”就要求算法在物体的任何外观变化下都能准确地找到物体。其次,目标物体并不总是单独出现的,相似物体的存在会对结果产生比较大的干扰。例如在一群人的画面中跟住某一个人时,我们就希望算法具有区分不同个体的能力,即“不跟错”。在实践中我们发现,“能跟住”和“不跟错”两个要求很难在一个模型中同时被满足。一方面,我们希望模型能够对物体的外观变化不敏感;另一方面,我们又要求模型能区分相似物体外观上的区别。这两者本身就有矛盾的地方。
为了解决这个问题,我们创新性地提出了串并联匹配(Series-Parallel Matching)的结构。整个结构分为两个部分,我们称之为“粗匹配”与“细匹配”。
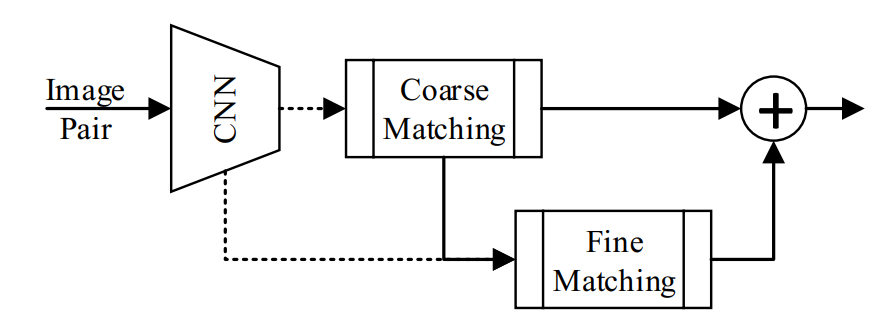
“粗匹配”的任务是找出图中所有和跟踪目标相似的物体,即“能跟住”。这个部分我们采用了 SiamRPN框架。不同的是,为了让模型尽可能地对物体外观变化鲁棒,我们把同一个类别的物体当作正样本对去训练模型。可视化的结果表明,这种训练方式能够使得模型在物体外观变化很大的情况下,仍然准确地找出物体。
“粗匹配”会生成一些候选的框给到“细匹配”模型。这一部分的任务是区分这些相似的物体,即“不跟错”。为了让模型更具有鉴别力,我们采用了关联网络去学习跟踪目标与候选框之间的距离度量。实验结果表明,这个结构比之前的交叉相关方法更加有效。
这两个部分通过串并联的方式结合在一起,得到最后的跟踪结果。它们共享同样的卷积特征,所以处理速度非常快,能够达到120 FPS,远超实时性的要求。我们在 OTB / VOT / LaSOT 等多个测试集上均取得了当时最好的实时跟踪结果,进一步验证了模型的有效性。
使用多投影GAN从未注释的图像集合中合成3D形状
Synthesizing 3D Shapes from Unannotated Image Collections using Multi-projection Generative Adversarial Networks
Xiao Li, Yue Dong, Pieter Peers, Xin Tong
论文地址:https://arxiv.org/abs/1906.03841
三维形体生成是计算机视觉的一个重要问题,传统方法或利用已有的大规模三维形体数据集进行训练,或利用已知视点信息的同一物体的多张多视点照片重建物体的三维形体。然而在大量实际应用场景中,仍然难以获取大量高质量的三维形体数据和具有已知视点信息的同一物体的多视点图像。针对这一问题,我们提出了一种利用未知视点信息、不存在图像间对应关系的二维图像集合进行三维形体生成的方法。
由于这种无标注的二维图像不存在图像间的对应关系,对于某一特定物体而言,我们不具有其多视点的样本。然而我们注意到,大量二维图像作为一个整体,表达了三维形体在不同视点下二维投影图像的统计分布,因此,我们可以利用生成对抗神经网络(GAN)的方法来学习这一统计分布,将单一物体的多视点重建问题转化为利用生成网络学习并产生在多视点下符合条件的二维图像统计分布的问题。
另一方面,由于这种无标注的二维图像没有对应的视点信息,我们依然无法获得针对某一视点的二维图像的统计信息。为了解决这一问题,我们需要训练对应的神经网络来预测图像的视点信息。然而,训练视点预测网络需要视点标注信息或三维形体数据来生成训练数据。为了跳出这一互相依赖的情况,我们提出了一种联合交替训练三维形体生成与视点信息预测的方法,同时解决了二维图像视点信息预测和三维形体生成的问题。
在实际应用中,我们的方法仅需要某一类物体在多个视点下的轮廓图像,不需要对视点信息、视点分布、图像之间的对应关系等的假设,即可产生一个可以生成该类物体的不同几何形体的生成网络。同时,我们的训练过程还会相应地得到一个针对该类物体轮廓图像的视角预测网络。
我们在公开的二维轮廓数据集(Caltech-UCSD Bird, Pix3D-Car)上进行了测试,获得了良好的形体生成和视角预测的效果。我们也在ShapeNet数据集上进行了合成数据测试,并对算法各个模块的作用进行了详细的实验分析。
最后,这一基于多个低维投影来训练高维数据生成网络的方法还可以被推广到其他高维数据的生成上,我们将该方法扩展到材质纹理生成,利用大量在不同光照下的材质图像,我们可以训练神经网络,生成某一特定类型材料的不同纹理材质。
采用有条件的GAN编辑蒙版导向的肖像
Mask-Guided Portrait Editing with Conditional GANs
Shuyang Gu, Jianmin Bao, Hao Yang, Dong Chen, Fang Wen, Lu Yuan
论文地址:https://arxiv.org/pdf/1905.10346.pdf
肖像编辑是计算机视觉领域的一个热门且实用的问题。前人在这方面的工作存在以下问题:或专注于特定的任务(如将闭上的眼睛睁开),或需要大量标注的表情数据(成本昂贵),或生成的人脸质量不高等。我们在论文“Mask-Guided Portrait Editing with Conditional GANs”中提出了一种通用、高质量、可控的人脸肖像编辑方法。
以下是我们的算法总体框架图:
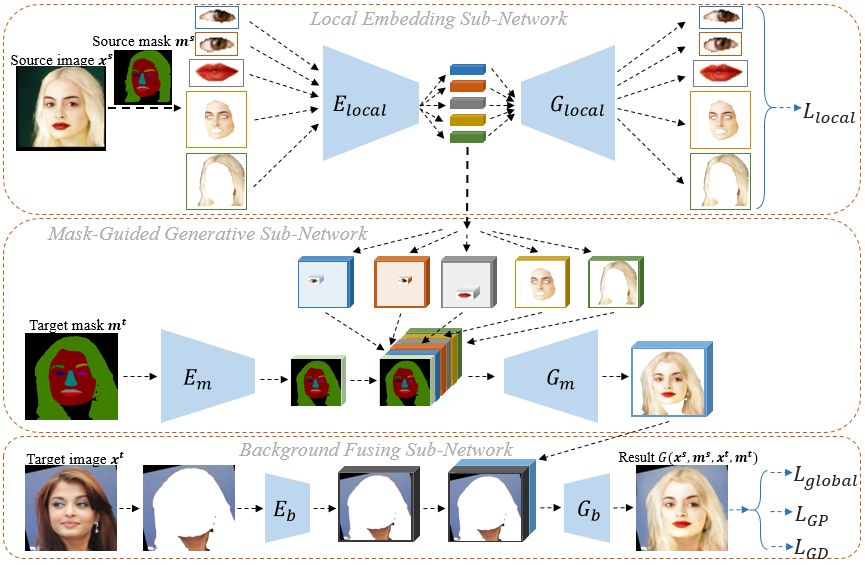
我们的网络主要分为三个部分: Local Embedding Sub-Network, Mask-Guided Generative Sub-Network, Background Fusing Sub-Network。
其中,Local Embedding Sub-Network将人脸的五个区域(左眼,右眼,皮肤,嘴唇,头发)分别进行局部特征编码,用L_local约束在编码解码的过程中尽可能保留局部特征。Mask-Guided Generative Sub-Network将局部特征的编码根据空间位置融合在target mask上,生成没有背景的肖像图。Background Fusing Sub-Network将这个前景肖像图和target mask的背景融合,生成最终的结果。对于最终的结果,我们用L_GD的GAN约束其满足人脸的分布,用L_GP约束其对应到原始的target mask,当source image和target image是同一张图时,我们用L_global约束重建的图片应当和输入完全一致。
我们进行了对比实验来分别验证三个子网络的有效性。具体到人脸肖像编辑的任务上,一方面,我们可以通过修改mask来编辑人脸(下图左),另一方面,我们可以将局部编码迁移到目标人脸(下图右)来使得输入的人脸具有其他的特征。人脸图像编辑、人脸交换、渲染人脸实验证明了该方法具有通用、高质量、可控的特点。此外,由于该方法具有从人脸分割图片到人脸一对多的特性,将其用于人脸图像分割的数据增强也能得到更好的结果。论文也展示了该方法在极端条件下的结果,来证明其具有很好的鲁棒性。

肖像编辑的实验结果
用于高质量图像补全任务的金字塔式上下文编码网络
Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting
Yanhong Zeng, Jianlong Fu, Hongyang Chao, Baining Guo
论文地址:https://arxiv.org/abs/1904.07475
图像补全(image inpainting)要求算法根据图像自身或图像库信息来补全待修复图像的缺失区域,使得修复后的图像看起来非常自然,难以和未受损的图像区分开。根据恐怖谷理论,只要填补内容和未受损区域有细微的不协调,就会非常显眼。因此高质量的图像补全不仅要求生成的内容语义合理,还要求生成的图像纹理足够清晰真实。
目前最好的图像补全的方法主要分为两类:一类是经典的纹理合成方法,核心是从图像的未受损区域采样相似像素块填充待补全区域。另一类是基于神经网络的生成模型,该方法将图像编码成高维隐空间的特征,再从这个特征解码成一张修复后的全图。然而,这两种方法在保证语义合理和纹理清晰的要求上都有其局限性。

不同方法在人脸上的实验结果
通过大量的实验研究和观察讨论,我们提出了以高层语义特征为指导、从深到浅逐层次多次补全的构想,从而让网络在保证语义一致性的同时,为缺失区域生成更丰富清晰的纹理细节,也由此诞生了金字塔式上下文编码网络(Pyramid-Context Encoder Network, PEN-Net)。
PEN-Net 是以 U-Net网络为主干结构搭建的。根据观察,低层特征具有更丰富的纹理细节,高层特征具有更抽象的语义,高层特征可逐层次指导低层特征的补全,PEN-Net的核心是将高层特征图上通过注意力机制计算出的受损区域和未受损区域的区域相似度,应用于下一层低层特征图上的特征补全,补全后的特征图继续指导下一层特征图缺失区域的补全,直到最浅层的像素层。在这个过程中,网络进行了多次的不同层次的特征补全。最终,解码网络将补全后的特征以及具有高层语义的特征结合,生成最后的补全图像,使得补全图像不仅语义合理,补全内容还具有更清晰丰富的纹理细节。

金字塔式上下文编码网络(Pyramid-Context Encoder Network, PEN-Net)
SeerNet: 通过低比特量化预测卷积神经网络特征图的稀疏性
SeerNet: Predicting Convolutional Neural Network Feature-Map Sparsity through Low-Bit Quantization
Shijie Cao, Lingxiao Ma, Wencong Xiao, Chen Zhang, Yunxin Liu, Lintao Zhang, Lanshun Nie, Zhi Yang
论文地址:https://www.microsoft.com/en-us/research/uploads/prod/2019/05/CVPR2019_final.pdf
深度神经网络在图像、语音、语言等领域取得重大突破,很大程度上依赖于更大更深层的网络得以实现。模型大小和计算量的不断增长使得利用最昂贵最高性能的设备(例如TPU、GPU)也难以满足模型推理的低延迟、高吞吐和高能效的需求。
事实上,现在的神经网络模型都构建在密集矩阵的运算之上,无论是对GPU还是TPU而言,都造成了大量的计算力和带宽的浪费。许多算法研究人员已经意识到神经网络存在大量的稀疏性,通过合理的减枝,许多神经网络都能够在减少计算量的基础上维持模型精度。此外,许多超大型、极稀疏的神经网络也在萌芽,例如 Geoffrey Hinton 提出的 Mixture-of-Experts 模型。
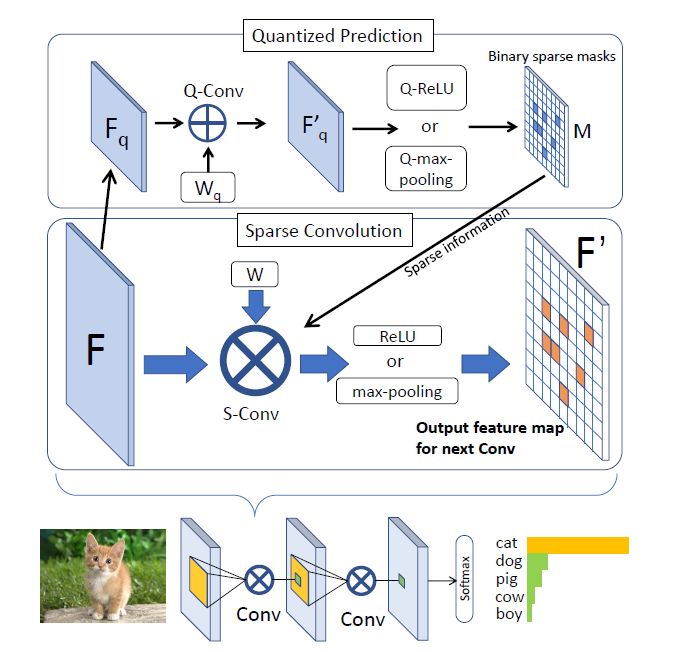
该论文关注的是卷积神经网络中输出特征图的稀疏性。例如,在卷积神经网络中,每个卷积层后通常会连接ReLU层或者Max-pooling层。经过ReLU或Max-pooling层后,卷积层的大部分输出被置为零或丢弃。从计算的角度考虑,如果能够省略零值输出和丢弃输出所对应的先导卷积计算,则可以大大减少卷积层的计算量。
该论文提出SeerNet。“Seer”是“预见者/先知”的意思。文如其名,我们利用极低比特网络以极低的代价预测输出特征稀疏性,通过稀疏的高精度计算加速神经网络计算。SeerNet可以直接应用于预训练好的模型,无需对原始模型做任何修改或重训练。
下图概述了本文的核心思想。对于每层卷积神经网络,首先使用量化后的低比特(例如4比特,2比特,1比特)网络预测输出特征的稀疏分布,然后利用稀疏分布信息引导原始精度的模型推理,即只进行有效输出(非零输出)所对应的卷积计算。
通过针对硬件优化的稀疏算法设计,本文基于CPU在卷积层上取得了最高5.79x的加速,在端到端的模型推理中取得了1.2x-1.4x的加速。同时,由于新型的AI硬件对混合精度的计算提供了更好的支持,SeerNet会有更大的用武之地,例如NVIDIA最新发布的Turing架构支持16/8/4-bit 混合精度张量计算单元,Xilinx和Altera的FPGA提供了任意精度整数计算的支持。这些硬件平台对低比特操作的支持可以降低预测过程的额外开销,同时,定制的算法和体系结构可以最大化地加速稀疏计算。
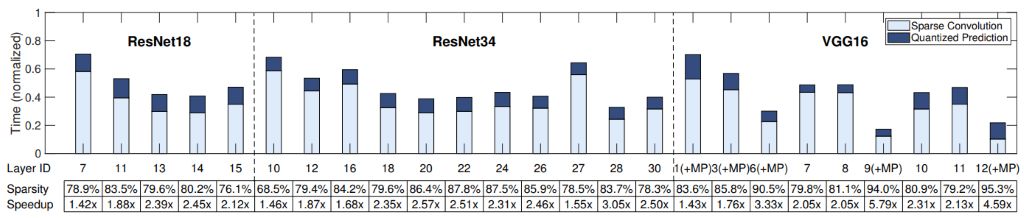
SeerNet在ResNet和VGG的不同层取得的稀疏性和加速
微软亚洲研究院全部被接受论文列表如下:
A Skeleton-bridged Deep Learning Approach for Generating Meshes of Complex Topologies from Single RGB Images
Context-Reinforced Semantic Segmentation
Deep Exemplar-based Video Colorization
Deep High-Resolution Representation Learning for Human Pose Estimation
Deep Incremental Hashing Network for Efficient Image Retrieval
Deeper and Wider Siamese Networks for Real-Time Visual Tracking
Deformable ConvNets v2: More Deformable, Better Results
Densely Semantically Aligned Person Re-Identification
Face Parsing with RoI Tanh-warping
Group Sampling Networks for Scale Invariant Face Detection
Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting
Learning Trilinear Attention Sampling Network for Fine-grained Image Recognition
Mask-Guided Portrait Editing with Conditional GANs
Relational Knowledge Distillation
S4Net: Single Stage Salient-Instance Segmentation
SeerNet: Predicting Convolutional Neural Network Feature-Map Sparsity through Low-Bit Quantization
Single Image Reflection Removal Exploiting Network Enhancement and Missaligned Training Data
SPM-Tracker: Series-Parallel Matching for Real-Time Visual Object Tracking
Structured Knowledge Distillation for Semantic Segmentation
Synthesizing 3D Shapes from Unannotated Image Collections using Multi-projection Generative Adversarial Networks
Triangulation Learning Network: from Monocular to Stereo 3D Object Detection
点击“阅读原文”,即可下载全部论文。

你也许还想看:



感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。




